元ネタはこちらIntroduction to optimal changepoint detection algorithms。
変化点検出
変化点検出は、時系列データを分析して、何らかのパラメータが変化した時点を推測する問題だといえます。変化するパラメータとしては様々なものが考えられ、検出方法もいろいろで、Rの変化点検出に関連したパッケージも複数あります。そのうちの一つであるchangepointパッケージは尤度比検定に基づいて平均and/or分散の変化を検出するパッケージです。まずはその考え方をざっと確認しておきます。
単一の変化点
次のような時系列データを考えてみましょう。平均値が時間に依存して変化するようなデータです。
$$
Z_t|\theta_t \sim \mathrm{Normal}(\theta_t, 1)
$$
ただし、$\theta$はある時間の区間(セグメント)においては一定と考えます。データを生成して図示してみましょう。
set.seed(71)
m1 <- c(
rnorm(100, mean = 0, sd = 1),
rnorm(100, mean = 5, sd = 1)
)
plot.ts(m1)
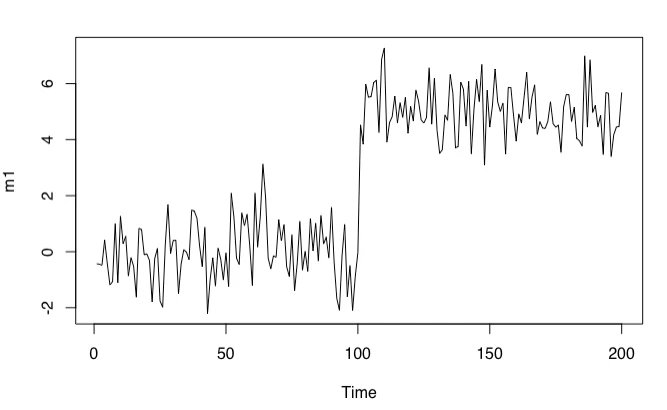
このデータは$t=100$と$t=101$の間で不連続に$\theta$が変化しています。
このような単一の変化点を検出する素朴な方法として、尤度比を用いたものがあります。
すなわち、変化点を仮定することで尤度が上がるのであれば、それは変化点である、と考えるのです。具体的には、変化点を$\tau$として、変化点毎に区切って計算した尤度と、区切らずに計算した全体の尤度の比
$$
\frac{L(z_{1:\tau})L(z_{\tau+1:n})}{L(z_{1:n})}
$$
を最大化するような$\tau$を求めます。この尤度比は、変化点を設定することでどれだけモデルが改善されたかの指標になります。
普通は対数尤度を使いますから、対数尤度を$\ell$とすれば、
$$
\tau = \arg \max (\ell(z_{1:\tau}) + \ell(z_{\tau+1:n}) - \ell(z_{1:n}) )
$$
というような$\tau$を求めるわけです。
複数の変化点
ところで、変化点がただ一つであると事前に確信できるような場面は非常に稀です。したがって、複数の変化点を検出できるような拡張が必要になります。
先程の議論を拡張するために、$k$を変化点の数、${\bf \tau}$を複数の変化点からなるベクトルとみなし、${\bf \tau} = (\tau_0, \tau_1, ...,\tau_{k+1})$とします。変化点の数が2つ増えているように見えますが、これはデータの端点も変化点とみなし、$\tau_0 = 0$、$\tau_{k+1} = n$とするためです。このようにすると、先程の単一変化点に対する尤度比の式を次のように書き換えることができます。対数尤度を負の対数尤度に置き換え、最小化問題にしていることに注意してください。
$$
\min_{\bf \tau} \left(\sum_{i=1}^{2} [-\ell(z_{\tau_i-1:\tau_i})] + \ell(z_{1:n}) \right)
$$
この式にもう少し手を加えます。この式は変化点がそもそも存在することを前提としていますが、普通は変化点があるかどうかは事前には分からないはずです。しかし、モデルに変化点を加えると、尤度は必ず改善してしまいます。そこで、上記の式の定数部分$\ell(z_{1:n})$を変化点がある場合のみ加える罰則項に置き換えます。
$$
\min_{k\in{0, 1}, {\bf \tau}} \left(\sum_{i=1}^{k+1} [-\ell(z_{\tau_i-1:\tau_i})] + \lambda k \right)
$$
ここで追加したペナルティ$\lambda$の大きさ次第で、$k=0$と$k=1$のどちらが選択されるかが決まります。
この式は容易に任意の変化点の個数に対応するように拡張できます。
$$
\min_{k, {\bf \tau}} \left(\sum_{i=1}^{k+1} [-\ell(z_{\tau_i-1:\tau_i})] +\lambda k \right)
$$
ペナルティ項を見るとわかるように、変化点が多いモデルに対してより大きなペナルティを課すような形になっています。
ペナルティの式としては必ずしも$\lambda$を係数とする$k$の定数倍のものを仮定する必要はなく、より一般的に書けば$f(k)$となります。また、ここでは対数尤度を最大化の対象としていますが、分割に応じて値の決まる他の関数を想定することもできます。負の対数尤度のような何らかのコスト関数を$C$とおけば、変化点検出の問題は結局のところ次の形の最適化問題であるとみなすことができます。
$$
\min_{k, {\bf \tau}} \left(\sum_{i=1}^{k+1} [C(z_{\tau_i-1:\tau_i})] +f(k) \right)
$$
changepointを使って変化点を検出する
では実際に変化点検出をしていきましょう。
changepointパッケージでは、主にcpt.mean、cpt.var、cpt.meanvarの3つの関数が変化点検出を担います。それぞれの関数はその名前が示すように以下のような場面で使用します。
-
cpt.mean: 平均だけが変化する場合。 -
cpt.var: 分散だけが変化する場合。 -
cpt.meanvar: 平均と分散が変換する場合。
3つの関数はよく似た引数を持っており、利用方法も似ていますが、引数に指定できる値などがそれぞれ異なります。詳しくはそれぞれの関数のドキュメントを確認してください。
単一変化点の検出
まずは単一の変化点を検出してみましょう。単一の変化点は、デフォルト引数のままでも検出できます(逆に、複数の変化点を検出するためにはmethodの指定が必要です)。先程作成したデータm1を対象に変化点検出をしてみます。
library(changepoint)
m1_amoc <- cpt.mean(m1)
cptから始まる関数は基本的にcptクラスのオブジェクトを返します。これはS4クラスのオブジェクトなので、要素(スロット)には@を使ってアクセスします。また、大抵のスロットに対して同名のアクセサが定義されています。
まずはcpts()を使って検出された変化点を確認してみましょう。
cpts(m1_amoc)
## [1] 100
param.est()を使って変化点で分断された各セグメントでのパラメータ推定値を確認してみましょう。
param.est(m1_amoc)
## $mean
## [1] -0.02011002 5.00973010
変化点もパラメータも正しく推定されました。
また、cptオブジェクトに対してはplot()の総称関数が定義されており、そのままプロットするだけで変化点が可視化されます。
plot(m1_amoc)

複数変化点の検出
単一の変化点であれば、探索範囲のなかで1点を決めるだけなのでそれほど計算量はかかりません。しかし、変化点が複数になると、変化点の数と場所の両方を決める必要があるので、検討すべきパターンは爆発的に増大します。極端なことをいえばすべてのデータポイントの間に変化点を置く、置かないの判断が必要になるので、データポイントの数を$n$として$2^{n-1}$の組み合わせがあり得るのです。
したがって、複数の変化点を検出するためには、いかに効率的に組み合わせを探索するかということも重要になってきます。
変化点探索の方法として、changepointパッケージは現状4つの手法をサポートしています。手法はmethod=引数に所定の文字列を指定することで切り替えられます。
- At Most One Change(
AMOC): 単一の変化点を検出します。デフォルトではAMOCなので、複数変化点検出のためには以下の3つの手法のいずれかを指定する必要があります。 - Binary Segmentation(
BinSeg): 解は近似的ですが計算量は$O(n\log n)$であり高速です。 - Segment Neighbourhood(
SegNeigh): 解は正確ですが$O(n^2)$の計算量が必要です。後述のPELTと結果が同じなので、現在これを選択する理由は特にありません。オプションとしても廃止される予定のようです(cf. https://twitter.com/hoxo_m/status/1003108482621440000 )。 - Pruned Exact Liner Time(
PELT): 比較的新しい手法で、ワーストケースでは$O(n^2)$の計算量が必要ですがペナルティが線形であれば$O(n)$で計算できます。高速で精度も高い手法です。
それでは、今回はcpt.var()を用いて、分散の変化を検出してみましょう。
v1 <- c(
rnorm(100, 0, 1),
rnorm(100, 0, 2),
rnorm(100, 0, 10),
rnorm(100, 0, 9)
)
v1_pelt <- cpt.var(v1, method = "PELT")
cpts(v1_pelt)
## [1] 102 200
param.est(v1_pelt)
## $variance
## [1] 0.9475028 3.6395613 85.1997910
##
## $mean
## [1] 0.1012267
plot(v1_pelt)

3つ目の変化点が検出されませんでしたね。一般的に、尤度ベースの手法で80%の検出力を得るには分散比で3程度必要とされているようです。したがって、この結果は想定の範囲内といえます。
カウントデータの変化の検出
残るはcpt.meanver()ですが、この関数はtest.statに指定できる分布の種類が豊富で、Normal以外にGamma、Exponential、Poissonが指定できます。
したがって、例えばポアソン分布に従うカウントデータの平均値の変化を扱うことができます。
p1 <- c(
rpois(100, 1),
rpois(100, 3),
rpois(100, 5)
)
p1_pelt <- cpt.meanvar(p1, method = "PELT", test.stat = "Poisson")
cpts(p1_pelt)
## [1] 100 200
param.est(p1_pelt)
## $lambda
## [1] 1.03 3.02 5.04
plot(p1_pelt)

変化点数の推定
推定される変化点の数は、ペナルティの重さに応じて変化します。
軽いペナルティを設定すれば変化点が多く検出されますし、
v1_manual_5 <- cpt.var(v1, method = "PELT", penalty = "Manual", pen.value = 5)
plot(v1_manual_5)

重いペナルティを設定すれば検出される変化点の数が減ります。
v1_manual_100 <- cpt.var(v1, method = "PELT", penalty = "Manual", pen.value = 100)
plot(v1_manual_100)

最適なペナルティの設定方法というのはまだ研究段階の課題であり、一概に決めることはできません。
では、ペナルティの値を判断して決めるにはどうすればよいのか、ということが問題になります。試行錯誤で決めるのは大変です。
changepointには最適なペナルティの値を探索する仕組みも実装されています。ペナルティにCROPS(Changepoints for a Range Of PenaltieS)を指定し、PELTと組み合わせることで、いくつかのペナルティで同時に変化点検出を実行することができます。このアルゴリズムの効率は高く、計算は高速に行われます。
この方法を使う場合には、pen.value=に探索範囲の上下限をベクトルとして指定します。
v1_crops <- cpt.var(v1, method = "PELT", penalty = "CROPS", pen.value = c(5, 500))
## [1] "Maximum number of runs of algorithm = 14"
## [1] "Completed runs = 2"
## [1] "Completed runs = 3"
## [1] "Completed runs = 4"
## [1] "Completed runs = 6"
## [1] "Completed runs = 8"
## [1] "Completed runs = 11"
この方法で取得したオブジェクトのクラスはcpt.rangeとなっており、パラメータの取得方法が少々異なります。
例えば検出された変化点はcpts.full()関数により行列として一括取得できます。
cpts.full(v1_crops)
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12]
## [1,] 12 37 44 66 71 86 102 200 202 219 238 244
## [2,] 12 24 29 102 200 202 219 238 244 NA NA NA
## [3,] 12 24 29 102 200 202 NA NA NA NA NA NA
## [4,] 24 29 102 200 202 NA NA NA NA NA NA NA
## [5,] 102 200 202 NA NA NA NA NA NA NA NA NA
## [6,] 102 200 NA NA NA NA NA NA NA NA NA NA
## [7,] 200 NA NA NA NA NA NA NA NA NA NA NA
## [8,] NA NA NA NA NA NA NA NA NA NA NA NA
これに対応するペナルティの値は、pen.value.full()で取得できます。
pen.value.full(v1_crops)
## [1] 5.000000 5.108104 5.250567 5.668800 6.402613 9.240260
## [7] 42.023799 457.746450
つまり、このペナルティの値を指定して再度分析をすれば分割の仕方を再現できるわけです。
cpts(cpt.var(v1, method = "PELT", penalty = "Manual", pen.value = pen.value.full(v1_crops)[2]))
## [1] 12 24 29 102 200 202 219 238 244
では、問題であった最適な変化点の数の決定ですが、これには診断プロットを用います。plot()に引数diagnostic = TRUEを指定すると、変化点の数とペナルティの関係が描画されます。
plot(v1_crops, diagnostic = TRUE)

ここではペナルティの減少量が大きく変化しているポイントが重要になります。
変化点を増やすとペナルティが大きく減る、逆にいえばその変化点を減らすために大きなペナルティを設定しないといけないということは、その変化点をモデルに加えることで大きく尤度が上昇するということを意味します。
したがって、適切な変化点の数はペナルティの変化が弱くなる、曲線のひじ(elbow)あたりに存在するということになります。このひじを見つけるのが診断プロットを描画する主な目的です。
今回の例では実際には3つの変化点が存在したわけですが、そのうち理論上検出可能なのは2点まででした。先程示した診断プロットでは確かに変化点2あたりにひじが存在していることが分かると思います。
なお、cpt.rangeオブジェクトから特定の変化点数の場合の図を直接描画するには、plot()にncpts=引数で変化点数を指定してやります。もし対応する変化点数が推測されていなければエラーになります。
plot(v1_crops, ncpts = 2)

おわりに
ここまでざっとchangepointの説明をしましたが、残差の診断やノンパラメトリックな手法など説明していない部分もありますので、詳しくは元ネタ(Introduction to optimal changepoint detection algorithms)の方を確認してみてください。