ここまででQuick Walkthrough部分は終了。
初回と2回目はこちら。
また、全てまとめた&多少の修正を加えたものがmlrパッケージチュートリアル - Quick Walkthrough編にあります。
ベンチマーク試験
ベンチマーク試験では、1つ、あるいは複数の性能指標に基いてアルゴリズムを比較するために、異なる学習手法を1つあるいは複数のデータセットに適用する。
mlrではbenchmark関数に学習器とタスクをリストで渡すことでベンチマーク試験を実施できる。benchmarkは通常、学習器とタスクの対に対してリサンプリングを実行する。タスクと性能指標の組み合わせに対してどのようなリサンプリング手法を適用するかは選択することができる。
ベンチマーク試験の実施
小さな例から始めよう。線形判別分析(lda)と分類木(rpart)をsonar.taskに適用する。リサンプリング手法はホールドアウト法を用いる。
以下の例ではResampleDescオブジェクトを作成する。各リサンプリングのインスタンスはbenchmark関数によって自動的に作成される。インスタンス化はタスクに対して1度だけ実行される。つまり、全ての学習器は全くおなじ訓練セット、テストセットを用いることになる。なお、明示的にResampleInstanceを渡しても良い。
もし、データセットの作成を無作為ではなく任意に行いたければ、makeFixedHoldoutinstanceを使うと良いだろう。
lrns = list(makeLearner("classif.lda"), makeLearner("classif.rpart"))
rdesc = makeResampleDesc("Holdout")
bmr = benchmark(lrns, sonar.task, rdesc)
$> Task: Sonar-example, Learner: classif.lda
$> [Resample] holdout iter 1: mmce.test.mean=0.314
$> [Resample] Aggr. Result: mmce.test.mean=0.314
$> Task: Sonar-example, Learner: classif.rpart
$> [Resample] holdout iter 1: mmce.test.mean=0.257
$> [Resample] Aggr. Result: mmce.test.mean=0.257
bmr
$> task.id learner.id mmce.test.mean
$> 1 Sonar-example classif.lda 0.3142857
$> 2 Sonar-example classif.rpart 0.2571429
もしmakeLearnerに学習器の種類以外の引数を指定するつもりがなければ、明示的にmakeLearnerを呼び出さずに単に学習器の名前を指定しても良い。上記の例は次のように書き換えることができる。
## 学習器の名前だけをベクトルで指定しても良い
lrns = c("classif.lda", "classif.rpart")
## 学習器の名前とLearnerオブジェクトを混ぜたリストでも良い
lrns = list(makeLearner("classif.lda", predict.type = "prob"), "classif.rpart")
bmr = benchmark(lrns, sonar.task, rdesc)
$> Task: Sonar-example, Learner: classif.lda
$> [Resample] holdout iter 1: mmce.test.mean=0.329
$> [Resample] Aggr. Result: mmce.test.mean=0.329
$> Task: Sonar-example, Learner: classif.rpart
$> [Resample] holdout iter 1: mmce.test.mean= 0.3
$> [Resample] Aggr. Result: mmce.test.mean= 0.3
bmr
$> task.id learner.id mmce.test.mean
$> 1 Sonar-example classif.lda 0.3285714
$> 2 Sonar-example classif.rpart 0.3000000
printの結果は各行がタスクと学習器の1つの組合せに対応している。ここでは分類のデフォルトの指標である平均誤分類率が示されている。
bmrはBenchmarcResultクラスのオブジェクトである。基本的には、これはResampleResultクラスのオブジェクトのリストのリストを含んでおり、最初のリストはタスク、その中のリストは学習器に対応した並びになっている。
実験を再現可能にする
一般的にいって、実験は再現可能であることが望ましい。mlrはset.seed関数の設定に従うので、スクリプト実行前にset.seedによって乱数種を固定しておけば再現性が確保できる。
もし並列計算を使用する場合は、ユースケースに合わせてset.seedの呼び出し方を調整する必要がある。例えば、set.seed(123, "L'Ecuyer")と指定すると子プロセス単位で再現性が確保できる。mcapplyの例(mclapply function | R Documentation)を見ると並列計算と再現性に関するもう少し詳しい情報が得られるだろう(訳注:こちらのほうが良いかも?R: Parallel version of lapply)。
ベンチマーク結果へのアクセス
mlrはgetBMR<抽出対象>という名前のアクセサ関数を幾つか用意している。これにより、さらなる分析のために情報を探索することができる。これには検討中の学習アルゴリズムに関するパフォーマンスや予測などが含まれる。
学習器の性能
先程のベンチマーク試験の結果を見てみよう。getBMRPerformancesは個々のリサンプリング毎の性能指標を返し、getMBRAggrPerformancesは性能指標の集約値を返す。
getBMRPerformances(bmr)
$> $`Sonar-example`
$> $`Sonar-example`$classif.lda
$> iter mmce
$> 1 1 0.3285714
$>
$> $`Sonar-example`$classif.rpart
$> iter mmce
$> 1 1 0.3
getBMRAggrPerformances(bmr)
$> $`Sonar-example`
$> $`Sonar-example`$classif.lda
$> mmce.test.mean
$> 0.3285714
$>
$> $`Sonar-example`$classif.rpart
$> mmce.test.mean
$> 0.3
今回の例ではリサンプリング手法にホールドアウト法を選んだので、リサンプリングは1回しか行っていない。そのため、個々のリサンプリング結果に基づく性能指標と集約値はどちらも同じ表示結果になっている。
デフォルトでは、ほぼすべてのゲッター関数ネストされたリストを返す。リストの最初のレベルはタスクで分類されており、二番目のレベルは学習器での分類になる。学習器またはタスクが1つしかない場合は、drop = TRUEを指定するとフラットなリストを得ることもできる。
getBMRPerformances(bmr, drop = TRUE)
$> $classif.lda
$> iter mmce
$> 1 1 0.3285714
$>
$> $classif.rpart
$> iter mmce
$> 1 1 0.3
大抵の場合はデータフレームの方が便利だろう。as.df = TRUEを指定すると結果をデータフレームに変換できる。
getBMRPerformances(bmr, as.df = TRUE)
$> task.id learner.id iter mmce
$> 1 Sonar-example classif.lda 1 0.3285714
$> 2 Sonar-example classif.rpart 1 0.3000000
予測
デフォルトでは、BenchmarkResultは学習器の予測結果も含んでいる。もし、メモリ節約などの目的でこれを止めさせたければkeep.pred = FALSEをbenchmark関数に指定すれば良い。
予測へのアクセスはgetBMRPredictions関数を使う。デフォルトでは、ResamplePredictionオブジェクトのネストされたリストが返ってくる。性能指標の場合と同様に、ここでもdrop及びas.df引数を使うことができる。
getBMRPredictions(bmr)
$> $`Sonar-example`
$> $`Sonar-example`$classif.lda
$> Resampled Prediction for:
$> Resample description: holdout with 0.67 split rate.
$> Predict: test
$> Stratification: FALSE
$> predict.type: prob
$> threshold: M=0.50,R=0.50
$> time (mean): 0.01
$> id truth prob.M prob.R response iter set
$> 1 123 M 0.99913258 8.674247e-04 M 1 test
$> 2 104 M 0.60017708 3.998229e-01 M 1 test
$> 3 28 R 0.06915618 9.308438e-01 R 1 test
$> 4 89 R 0.81537712 1.846229e-01 M 1 test
$> 5 158 M 0.93669911 6.330089e-02 M 1 test
$> 6 140 M 0.99998749 1.251482e-05 M 1 test
$> ... (70 rows, 7 cols)
$>
$>
$> $`Sonar-example`$classif.rpart
$> Resampled Prediction for:
$> Resample description: holdout with 0.67 split rate.
$> Predict: test
$> Stratification: FALSE
$> predict.type: response
$> threshold:
$> time (mean): 0.01
$> id truth response iter set
$> 1 123 M R 1 test
$> 2 104 M M 1 test
$> 3 28 R M 1 test
$> 4 89 R R 1 test
$> 5 158 M M 1 test
$> 6 140 M M 1 test
$> ... (70 rows, 5 cols)
head(getBMRPredictions(bmr, as.df = TRUE))
$> task.id learner.id id truth prob.M prob.R response
$> 1 Sonar-example classif.lda 123 M 0.99913258 8.674247e-04 M
$> 2 Sonar-example classif.lda 104 M 0.60017708 3.998229e-01 M
$> 3 Sonar-example classif.lda 28 R 0.06915618 9.308438e-01 R
$> 4 Sonar-example classif.lda 89 R 0.81537712 1.846229e-01 M
$> 5 Sonar-example classif.lda 158 M 0.93669911 6.330089e-02 M
$> 6 Sonar-example classif.lda 140 M 0.99998749 1.251482e-05 M
$> iter set
$> 1 1 test
$> 2 1 test
$> 3 1 test
$> 4 1 test
$> 5 1 test
$> 6 1 test
IDを通じて特定の学習器やタスクの結果にアクセスすることもできる。多くのゲッター関数はIDを指定するためのlearner.ids引数とtask.ids引数が用意されている。
head(getBMRPredictions(bmr, learner.ids = "classif.rpart", as.df = TRUE))
$> task.id learner.id id truth response iter set
$> 1 Sonar-example classif.rpart 123 M R 1 test
$> 2 Sonar-example classif.rpart 104 M M 1 test
$> 3 Sonar-example classif.rpart 28 R M 1 test
$> 4 Sonar-example classif.rpart 89 R R 1 test
$> 5 Sonar-example classif.rpart 158 M M 1 test
$> 6 Sonar-example classif.rpart 140 M M 1 test
デフォルトのIDが嫌なら、makeLearnerやmake*Task関数のid引数を通じて設定できる。さらに、学習器のIDを簡単に変更するための関数としてsetLearnerId関数も用意されている。
ID
ベンチマーク試験における学習器、タスク、性能指標のIDは、以下のように取得できる。
getBMRTaskIds(bmr)
$> [1] "Sonar-example"
getBMRLearnerIds(bmr)
$> [1] "classif.lda" "classif.rpart"
getBMRMeasureIds(bmr)
$> [1] "mmce"
フィット済みモデル
デフォルトではBenchmarkResultオブジェクトはフィット済みモデルも含んでいる。これは、benchmark関数を呼び出す際にmodels = FALSEを指定することで抑制できる。フィット済みモデルはgetBMRModels関数を使うことで確認できる。この関数が返すのは(おそらくネストされた)WrappedModelオブジェクトのリストである。
getBMRModels(bmr)
$> $`Sonar-example`
$> $`Sonar-example`$classif.lda
$> $`Sonar-example`$classif.lda[[1]]
$> Model for learner.id=classif.lda; learner.class=classif.lda
$> Trained on: task.id = Sonar-example; obs = 138; features = 60
$> Hyperparameters:
$>
$>
$> $`Sonar-example`$classif.rpart
$> $`Sonar-example`$classif.rpart[[1]]
$> Model for learner.id=classif.rpart; learner.class=classif.rpart
$> Trained on: task.id = Sonar-example; obs = 138; features = 60
$> Hyperparameters: xval=0
学習器と性能指標
使用された学習器はgetBMRLearnersで、性能指標はgetBMRMeasuresでそれぞれ抽出できる。
getBMRLearners(bmr)
$> $classif.lda
$> Learner classif.lda from package MASS
$> Type: classif
$> Name: Linear Discriminant Analysis; Short name: lda
$> Class: classif.lda
$> Properties: twoclass,multiclass,numerics,factors,prob
$> Predict-Type: prob
$> Hyperparameters:
$>
$>
$> $classif.rpart
$> Learner classif.rpart from package rpart
$> Type: classif
$> Name: Decision Tree; Short name: rpart
$> Class: classif.rpart
$> Properties: twoclass,multiclass,missings,numerics,factors,ordered,prob,weights,featimp
$> Predict-Type: response
$> Hyperparameters: xval=0
getBMRMeasures(bmr)
$> [[1]]
$> Name: Mean misclassification error
$> Performance measure: mmce
$> Properties: classif,classif.multi,req.pred,req.truth
$> Minimize: TRUE
$> Best: 0; Worst: 1
$> Aggregated by: test.mean
$> Note: Defined as: mean(response != truth)
ベンチマーク結果のマージ
ベンチマーク試験が終わった後で、他の学習器やタスクを追加したくなったらどうすればよいだろうか。このような場合は、mergeBenchmarkResults関数を使えば、複数のBenchmarkResutlオブジェクトをマージすることができる。
先程行った線形判別分析と決定木のベンチマーク試験結果に対し、ランダムフォレストと二次判別分析の結果を追加してみよう。
まず、ランダムフォレストと二次判別分析のベンチマーク試験を行う。
lrns2 = list(makeLearner("classif.randomForest"), makeLearner("classif.qda"))
bmr2 = benchmark(lrns2, sonar.task, rdesc, show.info = FALSE)
bmr2
$> task.id learner.id mmce.test.mean
$> 1 Sonar-example classif.randomForest 0.2428571
$> 2 Sonar-example classif.qda 0.5142857
次に、bmrとbmr2をマージする。BenchmarkResultオブジェクトはリストで渡す。
mergeBenchmarkResults(list(bmr, bmr2))
$> task.id learner.id mmce.test.mean
$> 1 Sonar-example classif.lda 0.3285714
$> 2 Sonar-example classif.rpart 0.3000000
$> 3 Sonar-example classif.randomForest 0.2428571
$> 4 Sonar-example classif.qda 0.5142857
上記の例ではリサンプルdescriptionをbenchmark関数に指定していることに注意してもらいたい。つまり、ldaとrpartはrandamForestおよびqdaとは異なる訓練/テストセットを用いて評価された可能性が高い。
異なる訓練/テストセットを用いて評価を行うと、学習器間の正確な性能比較が難しくなる。もし、他の学習器を使った試験を後から追加する見込みがあるのなら、最初からResampleInstancesを使用したほうが良い。リサンプルをインスタンス化しておけば、同じ訓練/テストセットを後の試験でも使用することができるからだ。
あるいは、BenchmarkResultオブジェクトからResampleInstanceを抽出し、これを他の試験に使用しても良い。例を示そう。
# インスタンスの抽出
rin = getBMRPredictions(bmr)[[1]][[1]]$instance
# インスタンスを用いてベンチマーク試験を行う
bmr3 = benchmark(lrns2, sonar.task, rin, show.info = FALSE)
# 結果をマージする
mergeBenchmarkResults(list(bmr, bmr3))
$> task.id learner.id mmce.test.mean
$> 1 Sonar-example classif.lda 0.3285714
$> 2 Sonar-example classif.rpart 0.3000000
$> 3 Sonar-example classif.randomForest 0.1571429
$> 4 Sonar-example classif.qda 0.2571429
ベンチマークの分析と可視化
mlrはベンチマーク試験を分析する機能も備えている。これには、可視化、アルゴリズムの順位付け、パフォーマンスの差に対する仮説検定が含まれる。
今回はこの機能を紹介するために、5つの分類タスクと3つの学習アルゴリズムを使用する、やや大きなベンチマーク試験を実施する。
例:線形判別分析と分類木、ランダムフォレストの比較
3つのアルゴリズムは線形判別分析、決定木、ランダムフォレストである。これらのデフォルトの学習器IDはやや長いので、以下の例ではもう少し短い別名を設定した。
5つの分類タスクと言ったが、3つは既に紹介したものだ。これに加えて、mlbenchパッケージに含まれるデータをconvertMLBenchObjToTask関数でタスクに変換したものを用いる。
全てのタスクは10分割クロスバリデーションによりリサンプリングを行う。これは、一つのresample descriptionをbenchmark関数に渡すことで行う。これにより、それぞれのタスクに対するリサンプリングのインスタンス化が自動的に実行される。この方法では、一つのタスク内で全ての学習器に対して同じインスタンスが使用されることになる。
タスクの数と同じ長さのリストでリサンプリング手法を指定すれば、それぞれのタスクに異なるリサンプリング手法を適用することもできる。この際渡すのはresample descriptionsでも良いし、インスタンスでも良い。
評価手法は平均誤分類率を主とするが、合わせてbalanced error rate(ber)と訓練時間(timetrain)も算出する。
## 学習器リストの作成
lrns = list(
makeLearner("classif.lda", id = "lda"),
makeLearner("classif.rpart", id = "rpart"),
makeLearner("classif.randomForest", id = "randomForest")
)
## mlbenchパッケージから追加タスクを生成する
ring.task = convertMLBenchObjToTask("mlbench.ringnorm", n = 600)
$> Loading required package: mlbench
wave.task = convertMLBenchObjToTask("mlbench.waveform", n = 600)
## タスクリストの作成
tasks = list(iris.task, sonar.task, pid.task, ring.task, wave.task)
## リサンプリング手法の指定
rdesc = makeResampleDesc("CV", iters = 10)
## 評価指標の指定
meas = list(mmce, ber, timetrain)
## ベンチマーク試験の実行
bmr = benchmark(lrns, tasks, rdesc, meas, show.info = FALSE)
bmr
$> task.id learner.id mmce.test.mean ber.test.mean
$> 1 iris-example lda 0.02000000 0.01638889
$> 2 iris-example rpart 0.06666667 0.05944444
$> 3 iris-example randomForest 0.04000000 0.03527778
$> 4 mlbench.ringnorm lda 0.39333333 0.39260730
$> 5 mlbench.ringnorm rpart 0.20000000 0.20181510
$> 6 mlbench.ringnorm randomForest 0.04666667 0.04693192
$> 7 mlbench.waveform lda 0.20333333 0.20148284
$> 8 mlbench.waveform rpart 0.30500000 0.30599541
$> 9 mlbench.waveform randomForest 0.19666667 0.19712404
$> 10 PimaIndiansDiabetes-example lda 0.23045113 0.27682495
$> 11 PimaIndiansDiabetes-example rpart 0.24738551 0.28385125
$> 12 PimaIndiansDiabetes-example randomForest 0.23169856 0.26997037
$> 13 Sonar-example lda 0.26904762 0.26980839
$> 14 Sonar-example rpart 0.28904762 0.29057914
$> 15 Sonar-example randomForest 0.14452381 0.13762710
$> timetrain.test.mean
$> 1 0.0030
$> 2 0.0039
$> 3 0.0428
$> 4 0.0083
$> 5 0.0122
$> 6 0.4084
$> 7 0.0087
$> 8 0.0113
$> 9 0.4533
$> 10 0.0054
$> 11 0.0067
$> 12 0.3676
$> 13 0.0305
$> 14 0.0150
$> 15 0.2739
iris-exampleとPimaIndiansDiabetes-exampleでは線形判別分析が優れいているが、他のタスクではランダムフォレストが良い成績を出しているようだ。一方、訓練時間を見るとランダムフォレストは他の学習器よりも長い時間がかかっている。
パフォーマンスの平均値から何らかの結論を言いたければ、値の変動も考慮に入れる必要がある。リサンプリングの繰り返し全体で値がどのように分布しているかも考慮できれば尚良い。
10分割クロスバリデーションにより、各タスクは10回評価されていることになるが、これは以下の様にして詳細を確認できる。
perf = getBMRPerformances(bmr, as.df = TRUE)
head(perf)
$> task.id learner.id iter mmce ber timetrain
$> 1 iris-example lda 1 0.00000000 0.00000000 0.003
$> 2 iris-example lda 2 0.06666667 0.05555556 0.002
$> 3 iris-example lda 3 0.00000000 0.00000000 0.004
$> 4 iris-example lda 4 0.00000000 0.00000000 0.003
$> 5 iris-example lda 5 0.00000000 0.00000000 0.003
$> 6 iris-example lda 6 0.00000000 0.00000000 0.004
結果を詳しく確認すると、ランダムフォレストは全てのインスタンスで分類木より優れており、線形判別分析は時間の面でほとんどどの場合も優れている事が分かる。また、線形判別分析は時々ランダムフォレストより優れた結果を出している。このサイズの試験結果ならまだ「詳しく確認する」は可能であるが、これよりももっと大きなスケールのベンチマーク試験では、このような判断はずっと難しくなる。
mlrには可視化と仮説検定の仕組みがあるので、より大きなスケールの試験に対してはそれを使おう。
可視化
プロットにはggplot2パッケージが使用される。したがって、要素のリネームや配色変更などのカスタマイズは容易に行える。
パフォーマンスの可視化
plotBMRBoxplotは箱ひげ図またはバイオリンプロットによって、リサンプリングの繰り返しの間に指標がどのような値をとったのかを可視化する。これはつまりgetBMRPerformancesの可視化である。
まずは箱ひげ図でmmceの分布を示す。
plotBMRBoxplots(bmr, measure = mmce)

次にバイオリンプロットの例を示す。
# aes, theme, element_textをggplot2::なしで呼び出すためには
# ライブラリのロードが必要
library(ggplot2)
plotBMRBoxplots(bmr, measure = ber, style = "violin",
pretty.names = FALSE) +
aes(color = learner.id) +
theme(strip.text.x = element_text(size = 6))
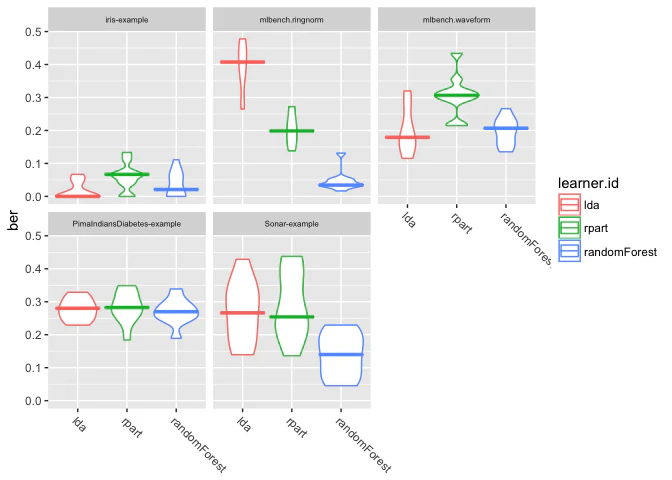
ここでは、指標としてberを使用するとともに、learner.idに基づく色の塗り分けも行っている。また、themeは各パネルのラベル(strip)のフォントサイズを調整している。
pretty.names=FALSEは何かというと、性能指標や学習器のラベルとしてidを使ってくれという指定である。これを指定しなかったときにどのような名前が使われるかは、性能指標であれば指標名$name、学習器ではgetBMRLEarnerShortNameで確認できる。
mmce$name
$> [1] "Mean misclassification error"
getBMRLearnerShortNames(bmr)
$> [1] "lda" "rpart" "rf"
プロットに関してよくある質問は、「パネルのラベルと学習器の名前はどうやったら変更できるのか」といったものだ。例えば、今見せた例で言えば、パネルのラベル名に含まれている-exampleやmlbench.を取り除いたり、学習機の名前を大文字の略称に変更したい、などの思ったのではないだろうか。現状、これを解決する一番簡単なやり方はfactorのlevelを書き換えてしまうことだ。例を示そう。
plt = plotBMRBoxplots(bmr, measure = mmce)
levels(plt$data$task.id) = c("Iris", "Ringnorm", "Waveform", "Diabetes", "Sonar")
levels(plt$data$learner.id) = c("LDA", "CART", "RF")
plt
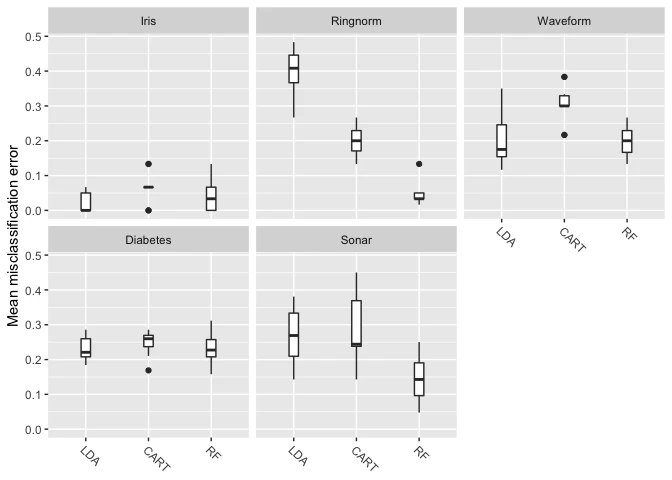
集約結果の可視化
集約された性能指標(getBMRAggrPerformancesで得られるもの)は、plotBMRSummaryで可視化できる。このプロットでは各タスクの性能指標集約値が同一の線上に並べられる(注: ドットプロット)。標準では、benchmarkで指定された最初の指標がプロット対象となる。今回の例ではmmceだ。加えて、各ポイントには縦方向に若干の誤差が加えられる。これはデータポイントが重なった場合にも識別できるようにするためだ。
plotBMRSummary(bmr)

順位の計算と可視化
性能指標の値に加えて、順位のような相対指標があると新しい知見が得られる場合がある。
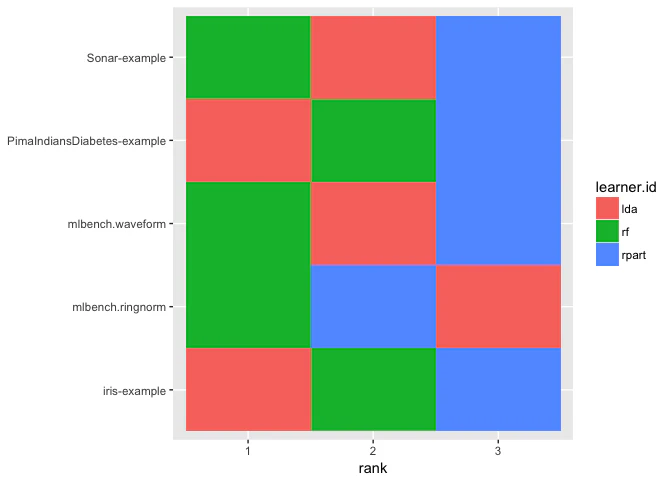
convertBMRToRankMatrix関数は、集約された性能指標のひとつに基づいて順位を計算する。例としてmmceに基づくランキングを求めてみよう。
convertBMRToRankMatrix(bmr)
$> iris-example mlbench.ringnorm mlbench.waveform
$> lda 1 3 2
$> rpart 3 2 3
$> randomForest 2 1 1
$> PimaIndiansDiabetes-example Sonar-example
$> lda 1 2
$> rpart 3 3
$> randomForest 2 1
順位は最高のパフォーマンスを示した、つまりmmceが最も低かった手法に対して小さな値が割り当てられる。今回の例ではLDAがirisとPimaIndiansDiabetesに対して最良の結果を示したが、他のタスクではランダムフォレストが優れていた事がわかる。
plotBMRRanksAsBarChart関数を使うと順位を可視化することができる。pos = "tile"を指定すると、順位・学習器・タスクの関係がヒートマップで図示される。この場合、x軸が順位、y軸がタスク、学習器の種類が色にそれぞれ割り当てられる。
plotBMRRanksAsBarChart(bmr, pos = "tile")
なお、plotBMRSummaryでもオプションにtrafo = "rank"を指定することで、性能指標が順位に変換されるため、同様の情報を含むプロットを作成できる。
plotBMRSummary(bmr, trafo = "rank")

plotBMRRanksAsBarChartはデフォルトでは積み上げ棒グラフを、pos = "dodge"オプションを指定すると通常の棒グラフを描画する。これは各種法が獲得した順位の頻度を確認する場合に適している。
plotBMRRanksAsBarChart(bmr)
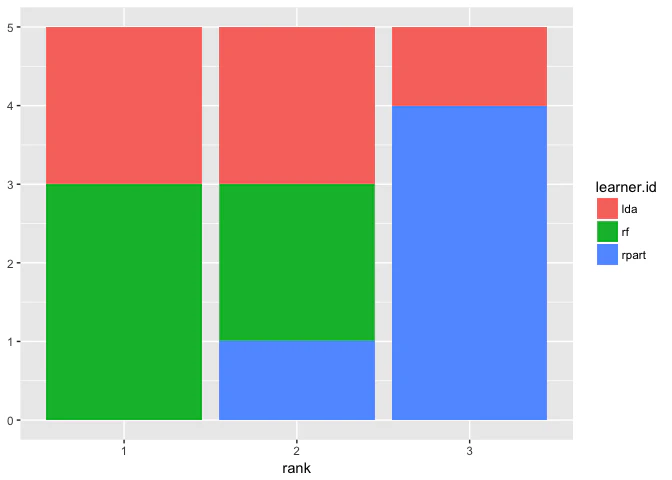
plotBMRRanksAsBarChart(bmr, pos = "dodge")

仮説検定で学習器を比較する
多くの研究者はアルゴリズムの有意性を仮説検定によって示す必要性を感じていることだろう。ベンチマーク試験の結果の比較などに適していると思われるノンパラメトリック検定として、mlrはOverall Friedman testとFriedman-Nemenyi post hoc testをサポートしている。
Friedman testはstatsパッケージのfriedman.test関数に基いており、これは学習器間に差があるかどうかを検定する。一方、Friedman-Nemenyi testは全ての学習器間の組合せについて差があるかどうかを検定する。ノンパラメトリック検定はパラメトリック検定と違い、データの分布に関する仮定を持たなくて済むという利点がある。しかしこれは、妥当な有意水準の元で有意な差を示すためには多くのデータセットが必要であるということを意味していることが多い。
さて、今我々が扱っている例では3つの学習器を比較している。まずは、そもそも学習器間に差があるのかどうかを検定したいのではないだろうか。Friedman testを実行してみよう。
friedmanTestBMR(bmr)
$>
$> Friedman rank sum test
$>
$> data: mmce.test.mean and learner.id and task.id
$> Friedman chi-squared = 5.2, df = 2, p-value = 0.07427
今回の例はチュートリアルなので、計算時間節約のために学習器を評価するタスクは5つしかなかった点に注意してほしい。従って、有意水準として少し甘めのα = 0.1程度を見積もっても良いだろう。この場合帰無仮説は棄却されるので、今度はこの差がどの学習器の間に存在するのかを検定してみよう。
# install.packages("PMCMRplus")
# Friedman testで帰無仮説を棄却できないとNemenyi検定をしてくれないので、
# p.value =で有意水準を引き上げる必要がある。
friedmanPostHocTestBMR(bmr, p.value = 0.1)
$> Loading required package: PMCMR
$> PMCMR is superseded by PMCMRplus and will be no longer maintained. You may wish to install PMCMRplus instead.
$>
$> Pairwise comparisons using Nemenyi multiple comparison test
$> with q approximation for unreplicated blocked data
$>
$> data: mmce.test.mean and learner.id and task.id
$>
$> lda rpart
$> rpart 0.254 -
$> randomForest 0.802 0.069
$>
$> P value adjustment method: none
決定木とランダムフォレストの間の差について帰無仮説を棄却できた。
臨界差ダイアグラム
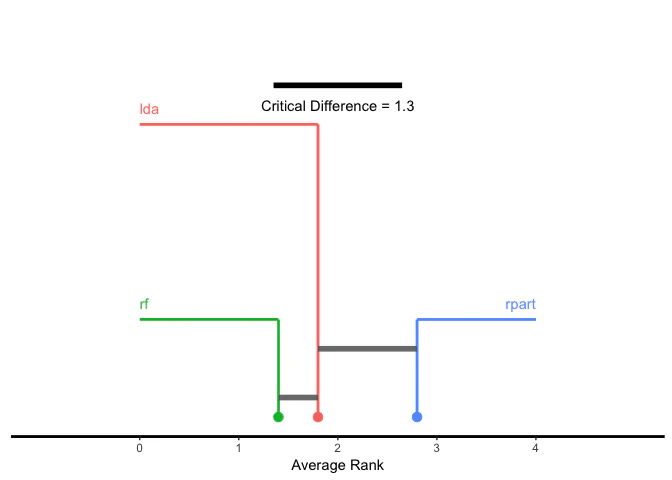
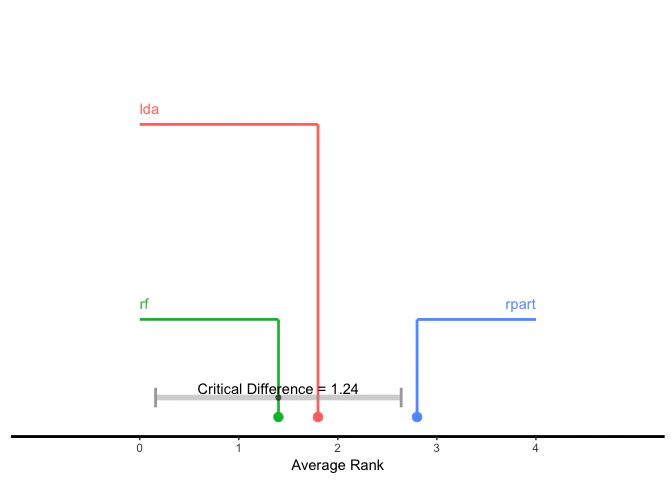
学習器の性能に関する差を可視化する手法として、critical differences diagramが使用できる。検定手法はNemeny検定(test = "nemenyui")またはBonferroni-Dunn検定(test = "bd")が選択できる。
プロットの際、x軸には学習器の平均順位が対応する。
-
test = "nemenyui"を選択した場合、全てのグループ間で比較が行われるため、出力では互いに有意な差が無い学習器がグループとなるような描画が行われる。グループは学習器間をバーで接続することで図示される。従って、バーで接続されていない学習器間には有意な差が存在しており、平均順位が低い方の学習器の方が(選択した有意水準のもとで)優れていると言うことができる。 -
test = "bd"を選択した場合は、各学習器はベースラインと比較される。すなわち、ベースラインとして選択した学習器から両方向に臨界差(critical difference)の範囲を示すラインが描画される。従って比較はベースラインの学習器との間でのみ可能となる。臨界差の範囲外の学習器は、ベースラインとした学習器に対して優れている(または劣っている)と考えることができる。
ここで臨界差C**Dは次のように計算される値である。
$CD = q_\alpha\sqrt{\frac{k(k+1)}{6N}}$
Nはタスクの数を、kは学習器の数を、qαはスチューデント化された範囲を$\sqrt{2}$で除した値である。詳しくはDamsar (2006)を参照してほしい。
createCritDifferencesData関数は、plotCritDifferencesでプロットを作成するために必要な全ての量を計算する。プロット関数に関する詳細は後ほどあらためて可視化のチュートリアルで触れる予定である。
## Nemeyui test
g = generateCritDifferencesData(bmr, p.value = 0.1, test = "nemenyi")
plotCritDifferences(g) + coord_cartesian(xlim = c(-1, 5), ylim = c(0, 2))
## Bonferroni-Dunn test
g = generateCritDifferencesData(bmr, p.value = 0.1, test = "bd", baseline = "randomForest")
plotCritDifferences(g) + coord_cartesian(xlim = c(-1, 5), ylim = c(0, 2))
プロットの調整
プロットはggplotのオブジェクトなので、これをカスタマイズすることで容易に独自のプロットを作成できる。これは既に見たところだ。一方、getBMRPerformancesやgetBMRAggrPerformancesが返すデータフレームを使って独自のプロットを作成することもできる。以下に例を見よう。
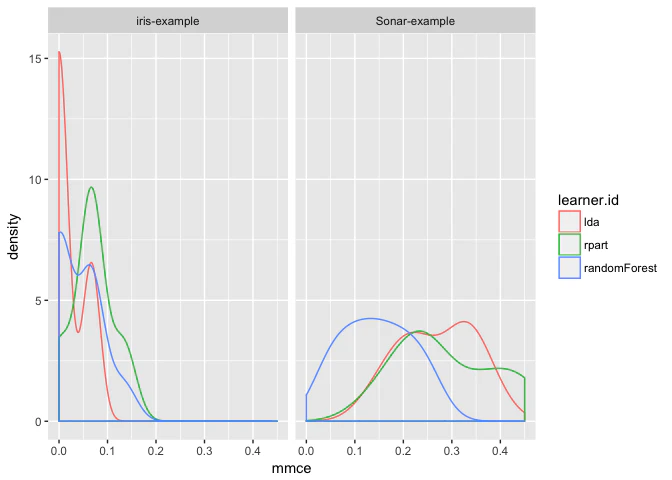
plotBMRBoxplotsでは箱ひげ図を作成したが、密度プロットで性能指標を可視化してみよう(訳注: 原文ではqplotを使用しているが個人的にわかりにくいのでggplotで書き直した。また、strip textのフォントサイズ調整を省略している)。
pref = getBMRPerformances(bmr, as.df = TRUE)
ggplot(data = pref[pref$task.id %in% c("iris-example", "Sonar-example"), ],
aes(x = mmce, colour = learner.id)) +
facet_grid(.~task.id) +
geom_density()
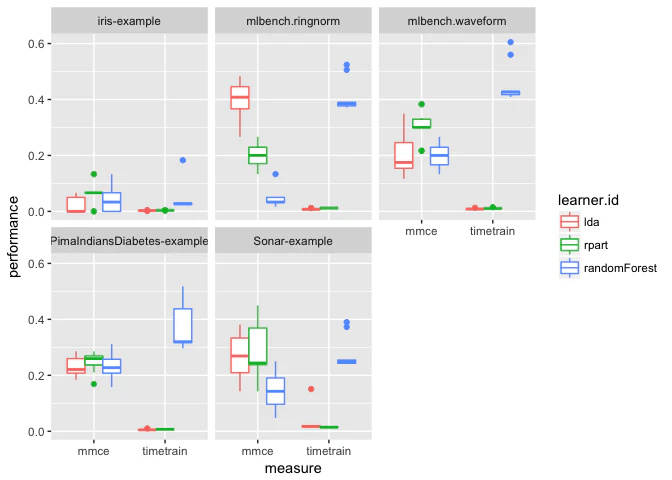
複数の指標を並列に比較したければ、prefをlong formatに変換する必要がある。以下にmmceとtimetrainを箱ひげ図で表示する例を示そう。
(訳注: 原文とは異なり、tidyr、dplyr、ggplotを使用している。パイプ演算子%>%を使えばより簡潔に書き換えることもできるだろう。)
df = tidyr::gather(pref, key = variable, value = value, mmce:timetrain)
df = dplyr::filter(df, variable != "ber")
ggplot(df, aes(x = variable, y = value, color = learner.id)) +
geom_boxplot(position = "dodge") +
labs(x = "measure", y = "performance") +
facet_wrap(~ task.id, nrow = 2)
リサンプリング毎の学習器間のパフォーマンスの関係を調べることが有用な場合もある。ある学習器が例外的に良い成績を出している場合に他の学習器の成績が悪いという様な場合があれば、より深い洞察が得られるだろう。これはまた、学習アルゴリズムにおいてアンサンブルを構築する際にも便利な場合がある。以下では、GGallyパッケージのggpairs関数を使って、Sonarデータセットで学習を行った場合のmmceの散布図行列を作成する例を見てみよう。
(訳注:ここも書き換えている)
pref = getBMRPerformances(bmr, task.id = "Sonar-example", as.df = TRUE)
df = tidyr::gather(pref, key = variable, value = value, mmce:timetrain)
df = dplyr::filter(df, variable == "mmce")
df = tidyr::spread(df, key = learner.id, value = value)
GGally::ggpairs(df, 4:6)

その他のコメント
- 教師あり学習については、
mlrはBenchmarkResultオブジェクトを使用して学習アルゴリズムを比較するためのプロットをさらにいくつか提供している。以下のページに例がある。 - このセクションの例では「生の」学習アルゴリズムを用いたが、通常はもっと事は複雑である。少なくとも、大抵の学習アルゴリズムは調整すべきハイパーパラメータを持っている。信頼性のある性能指標の推定値を得るためには、nested resampling、すなわち、内側のループでハイパーパラメータをチューニングしつつ外側のループで性能指標を推定するといった作業が必要になる。さらに、補完やスケーリング、外れ値除去、次元削減、特徴量選択などの前処理を組み合わせたい場合もあるだろう。これらの全ての作業は
mlrのラッパー機能を使用すると容易に実行できる。より詳しい話はチュートリアルのAdvancedパートで説明する。 - ベンチマーク試験を行っていくと、すぐに多量の計算量が必要となるはずだ。
mlrはこの問題に対応するため、並列計算の機能をいくつか提供している。
並列化
(訳注: この部分は特に理解が浅いので適当な訳になっている可能性があります)
Rはデフォルトでは並列化を行わない。parallelMapパッケージをmlrと合わせて使うことで、mlrが既にサポートしている並列化機能を容易に有効化できる。parallelMapは主要な並列化バックエンドの全てで動作する。例えばparallelを使用したローカルでのマルチコアを利用した並列化、snowパッケージを用いたソケットやMPIによるクラスタ、BatchJobsパッケージを使用した一時的なSSHクラスタやハイパフォーマンスコンピューティング(SLURMやTorque/PBS、SGEやLSFなどのスケジューラによる)などが含まれる。
実際に行う作業は、parallelStart*関数によりバックエンドを選択するだけだ。並列実行可能とマークされたループは自動的に並列化される。また、スクリプトの実行が終わったらparallelStopを呼び出すのを忘れないようにしよう。
library(parallelMap)
parallelStartSocket(2)
$> Starting parallelization in mode=socket with cpus=2.
rdesc = makeResampleDesc("CV", iters = 3)
r = resample("classif.lda", iris.task, rdesc)
$> Exporting objects to slaves for mode socket: .mlr.slave.options
$> Mapping in parallel: mode = socket; cpus = 2; elements = 3.
$> [Resample] Aggr. Result: mmce.test.mean=0.02
parallelStop()
$> Stopped parallelization. All cleaned up.
LinuxかmacOSを使用している場合は、parallelStartMulticoreを代わりに使うことができる。
並列化レベル
並列化をきめ細かく制御するために、mlrは異なる並列化レベルを提供している。例えば、ベンチマーク試験は例数が少ないので並列化しなくてよいが、リサンプリングは並列化したいという場合は、parallelStart*関数を呼び出す際にlevel = "mlr.resample"を指定すれば良い。現状、以下の並列化レベルがサポートされている。
parallelGetRegisteredLevels()
$> mlr: mlr.benchmark, mlr.resample, mlr.selectFeatures, mlr.tuneParams, mlr.ensemble
これらの詳細は?mlr::parallelizationで確認してほしい。
自作の学習器と並列化
ローカルで自作の学習器を実装した場合は、現状ではこれをスレーブとしてエクスポートする必要がある。たとえば並列化したリサンプリングで次のようなエラーが出た場合
no applicable method for 'trainLearner' applied to an object of class <自作の学習器名>
parallelStart以後に次の文を実行すれば良い。
parallelExport("trainLearner.<自作の学習器名>", "predictLearner.<自作の学習器名>")
並列化の話はこれで終わりだ!
より詳しい話はparallelMapのチュートリアル(berndbischl/parallelMap: R package to interface some popular parallelization back-ends with a unified interface)かヘルプを参照してもらいたい。
いろいろな可視化
generation関数とplotting関数
mlrの可視化機能は、プロットのためのデータを生成するgeneration関数と、その出力を使ってプロットを作成するplotting関数から成っている。プロット関数はggplot2かggvisパッケージを使ってプロットを作成する(ggvisの方はまだ試験的段階にある)。
可視化機能をこのように分けたことで、ユーザーはgeneration関数を利用して容易にプロットのカスタマイズができるようになっている。plotting関数の中で行われる唯一のデータ変換はデータの成形である。成形されたデータには、plotting関数を呼び出すことで作成されるggplotオブジェクトからアクセスすることもできる。
それぞれの関数は次のように命名されている。
- generate関数は
generateから始まり、次に関数の目的がtitle caseで続き、最後にDataが付け加えられる。すなわち、関数名はgenerateFunctionPurposeDataといった具合になる。generate関数により作成されるオブジェクトはFunctionPurposeDataクラスである。 - plotting関数は
plotに関数の目的が続く形の名前となる。すなわち、plotFunctionPurposeといった具合だ。 -
ggvis用いたプロット関数名は末尾にGGVISを付加する。
例
まず、sonar.taskに対する2クラス分類問題で、分類性能を決定閾値の関数と見立ててプロットする例を示す。対応するgeneration関数はgenerateThreshVsPerfData関数であり、この関数により生成されるThreshVsPerfDataクラスのオブジェクトは$dataスロットにプロットするためのデータを含む。
lrn = makeLearner("classif.lda", predict.type = "prob")
n = getTaskSize(sonar.task)
mod = train(lrn, task = sonar.task, subset = seq(1, n, by = 2))
pred = predict(mod, task = sonar.task, subset = seq(2, n, by = 2))
d = generateThreshVsPerfData(pred, measures = list(fpr, fnr, mmce))
class(d)
$> [1] "ThreshVsPerfData"
head(d$data)
$> fpr fnr mmce threshold
$> 1 1.0000000 0.0000000 0.4615385 0.00000000
$> 2 0.3541667 0.1964286 0.2692308 0.01010101
$> 3 0.3333333 0.2321429 0.2788462 0.02020202
$> 4 0.3333333 0.2321429 0.2788462 0.03030303
$> 5 0.3333333 0.2321429 0.2788462 0.04040404
$> 6 0.3125000 0.2321429 0.2692308 0.05050505
いま作成したオブジェクトをmlrの組み込み関数を使ってプロットするには、plotThreshVsPref関数を用いる。
plotThreshVsPerf(d)
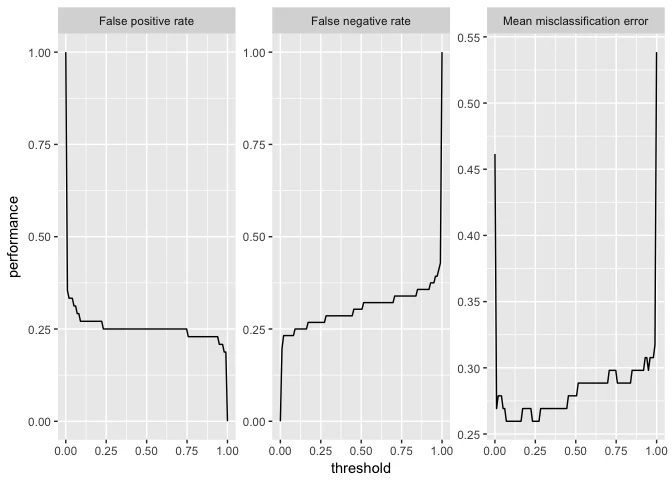
デフォルトでは各パネルのラベルには性能指標の名前が使用される。これは他のplotting関数でも同様である。名前はMeasureクラスのオブジェクトの$nameスロットに格納されている。
fpr$name
$> [1] "False positive rate"
$nameの代わりに$idスロットの値をプロットに使うこともできる。
fpr$id
$> [1] "fpr"
この値を使う場合は、pretty.names = FALSEを指定する。
plotThreshVsPerf(d, pretty.names = FALSE)

プロットのカスタマイズ
組み込みのプロットや、生成データに基いて作成した独自のプロットは簡単にカスタマイズできる。
おそらく、ほとんどの場合ラベルや注釈を変更したいと思うだろう。ggplotオブジェクトに対してこれを行うためには、ylabやlabellerなどの関数を利用する。さらに、生成データやggplotオブジェクトに含まれるデータを変更するという手もある。これは大抵の場合、列名や水準名の変更である。
先程のプロットの軸と各パネルのラベルを変更してみよう。
例えば、次のような変更を施したいとする。
- パネルの表示順序を変更し、
mmceを最初にしたい。 - パネルのラベル名が長いので、例えば
Mean misclassification errorをError rateにしたい。
library(ggplot2)
plt = plotThreshVsPerf(d, pretty.names = FALSE)
plt$data$measure =
factor(plt$data$measure,
levels = c("mmce", "fpr", "fnr"), # 水準の順序の変更
labels = c("Error rate", "False positive rate", "False negative rate")) # 水準名の変更
plt +
xlab("Cutoff") + # x軸ラベルの変更
ylab("Performance") #y軸ラベルの変更
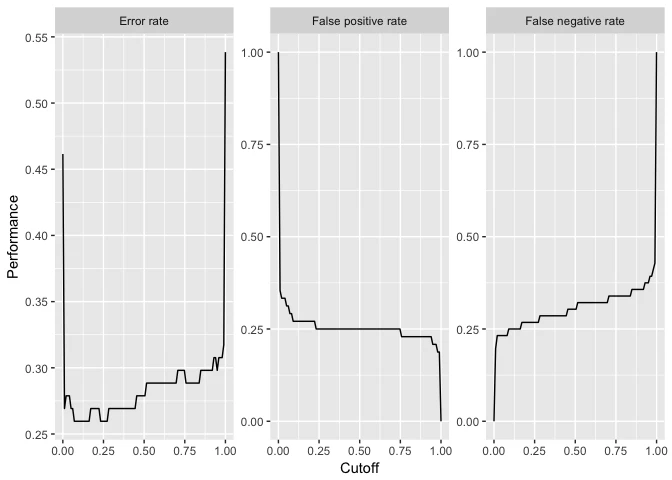
labeller関数はfacet_wrapかfacet_gridと合わせて使う必要があるが、パネルの並べ方を変更したり、軸のリミットに影響を与えたいと考えている場合には便利である。
plt = plotThreshVsPerf(d, pretty.names = FALSE)
measure_names = c(
fpr = "False positive rate",
fnr = "False negative rate",
mmce = "Error rate"
)
plt +
facet_wrap(~measure, labeller = labeller(measure = measure_names), ncol = 2) +
xlab("Decision threshold") + ylab("Performance")

plotting関数を使わずに、generation関数で生成したデータに基いてプロットを作成することもできる。
ggplot(d$data, aes(threshold, fpr)) + geom_line()

generation関数がプロット関数と分かれていることにより、graphicsやlatticeパッケージを用いたプロットを作成する場合にも対応できる。以下にlatticeでplotThreshVsPrefと同様のプロットを作成する例を示そう。
lattice::xyplot(fpr + fnr + mmce ~ threshold,
data = d$data,
type = "l",
ylab = "performance",
outer = TRUE,
scales = list(relation = "free"),
strip = lattice::strip.custom(
factor.levels = sapply(d$measures, function(x) x$name),
par.strip.text = list(0.8)
))

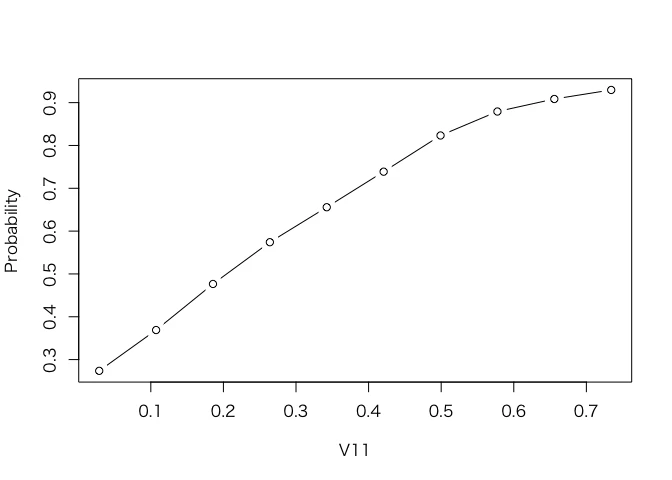
もう一つ、plotPartialDependenceを使ってプロットを作成したのち、ggplotオブジェクトからデータを取り出してgraphics::plotによる伝統的なプロットも作成する例を見てみよう。
sonar = getTaskData(sonar.task)
pd = generatePartialDependenceData(mod, sonar, "V11")
plt = plotPartialDependence(pd)
plt
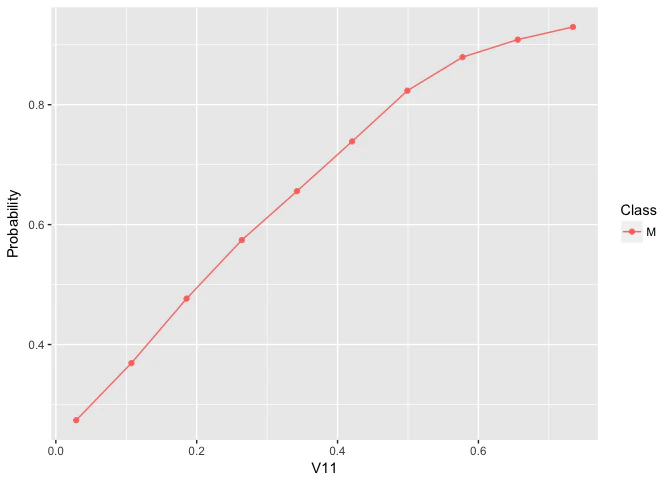
plot(Probability ~ Value, data = plt$data, type = "b", xlab = plt$data$Feature[1])
利用可能なgeneration関数とplotting関数
以下に現在利用可能なgeneration関数およびplotting関数と、その詳細を説明するチュートリアルページへのリンクの一覧を示す。
なお、下記の点に注意してもらいたい。
-
plotTuneMultiCritResultなどはgeneration関数が無いため、ここでは言及していない。 -
plotThreshVsPref及びplotROCCurvesはいずれもgenerateThreshVsPrefDataの結果を扱える。 -
plotPartialDependence及びplotPartialDependenceGGVISは、いずれもgeneratePartialDependenceData及びgenerateFunctionalANOVADataの結果の両方を扱える。