やりたかったこと
- RabbitMQ利用の非同期処理ワーカー構成でConsumerがDynamoDBにアクセスする際に、多量のQueueがPublishされてもProvisionedThroughputExceededExceptionを発生させないこと
環境
- RabbitMQ
- DynamoDB
- Python3.5
- Pika==0.10.0
何をやったのか
- ワーカーにおけるQueueのfetchに用する時間、アプリケーションが処理に用する時間、ackを返すのに用する時間を考慮して1秒間の並列数を調整することで処理Queue数を制御した
- RabbitMQの特定Queueの滞留数を監視できるようにした
- 滞留数が閾値を超えた場合に、DynamoDBの特定tableのProvisionedThroughputを調整するようにした
どんな風に考えて、どんな風に構成の変更方針を決めていったのか
ワーカーがProvisionedThroughputExceededException発生させているタイミングはどこか?
多量のQueueがPublishされた時、ワーカーは処理できる限りのQueueを取得し並列処理を行います。DynamoDBには1秒間にリクエストできる上限があり、並列処理数(正確にはその中でDynamoDBのリクエスト数が何回あるかに影響する)がその上限を越えたタイミングにてProvisionedThroughputExceededExceptionが発生しました。
予め上限緩和(お金の力を使って)をできるのであれば、場当たり的に解決することも可能です。しかし想定以上の並列数になってしまった場合に同様の現象が発生することが予想されるので、根本解決には至りません。
Dynamic DynamoDBを利用することで上限をスケールさせるとよいのではないか?
DynamoDBを利用する際に、Dynamic DynamoDBを併用するのはよくある構成だと思います。しかしDynamic DynamoDBにも問題点はあり、負荷がかかっていることを検知するまでのタイムラグと、実際上限緩和が反映されるまでのタイムラグを合わせて10分前後程度になることもあります。
急激な負荷により並列数が上がった場合に、このタイムラグがネックとなり結局はProvisionedThroughputExceededExceptionが発生することとなりました。そこで1秒間に処理する並列数を何かで調整しなければ根本解決にはならないだろうという判断に至りました。
RabbitMQのQueueがどのように処理されていくのか?
今回はClient(非同期処理Worker)がRabbitMQ上の任意Queueから内容を取得して、ackを返してQueueのライフサイクルが終わるケースを採用しています。以下の図のようなフローとなります。
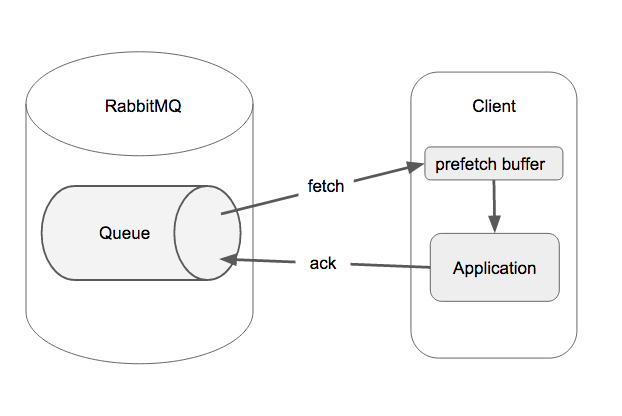
Clientは一旦prefetch bufferに Queue内容を保存し、ApplicationはこのbufferからQueue内容を取得して処理していき、最終的にRabbitMQにackを返す。というフローです。
今回担当したアプリケーション環境では、fetchに5ms程度、Applicationの部分としては300~350ms程度、ackに5ms程度かけていることがサンプルデータを処理した結果から計測できました。
ここでDynamoDBには1秒間にリクエストできる上限の話に戻って、じゃあ秒間いくつQueueを読み込んでリクエストはどの程度なげるのだろうか?ということを考えてみます。
fetchは5msなので秒間200件fetchできることになります、Applicationの部分ではRead2回、Write1回を特定テーブルに向けて行っています。
秒間で200の並列処理が走るとなるとDynamoDBにRead:400/Write:200程度をリクエストすることになり、capacityをそれくらい予め用意しておく必要があることになります。
しかし今回用意したcapacityはRead:60/Write:30です。なるほど、それはエラーでるだろう。ということが把握できました。
秒間処理数を並列数の制御で調整する
把握した情報から、秒間30個のQueueを処理するのが現状だと上限になります。これを並列化の量を制御することで範囲内に調整されるようにならないかを考えていきます。
1Queueの処理時間は310ms~360ms、計算を単純化するために中間の335msとして1つずつQueueを取り出して処理していくような形で考えると、1000msで処理できるのは約3個のQueueとなります。
このことから並列数は10前後になるようにすることで、秒間30個のQueueをさばけるギリギリのラインになるだろうという結論に至りました。
どうやって並列数を調整するのか?
ようやく本題、RabbitMQにおける並列数の調整です。
RabbitMQにはprefetch_countという設定項目があります。これはなにかというと、1度にprefetch bufferにためておけるQueue数の上限値の設定です。ackを返すことで新たなQueueをfetchすることができるようになります。この機能を利用することで、非同期ワーカーの最大並列数をprefetch_countの値までに上限を設けることができるようになります。
prefetch_countは本来、Queue数が増えたのを解消しようとClientを後から追加したようなケースで、すでに既存のClientがprefetch bufferに溜め込んでしまっていた場合、後から追加したClientがfetchするものがなく待機状態になってしまう。もしくは既存のClientが溜め込んでしまったがために、buffer内でずっと待ち続けることになる。みたいな問題を最適化するためにprefetch bufferに溜め込む量を制限する目的で使うことが一般的です。prefetch_countを用いたチューニングはここが詳しく載っています。Some queuing theory: throughput, latency and bandwidth - Messaging that just works
今回はそれを並列数の調整に利用したという形です。
そして先ほど、並列数は10前後になると秒間30個というラインになるだろうと予測をたてましたのでprefetch_countを10に設定することにします。ProvisionedThroughputExceededExceptionが発生することはなくなりました。Queueの処理数も狙ったような27~31/s程度となりました。
31/sの時には早すぎて実はException起きているはずなのですが、DynamoDBのリクエストにretryを数回かけているため、ログとしてはでてきません。そしてretryをかけた分queueの1回のライフサイクルが長くなり、処理速度が一旦27/s程度に一時的に落ちる、その後また30/s前後にあがってくる。ということを繰り返すことでエラーログとしてはでない最も処理できるラインに落ち着かせることになるだろうと判断しています。
スケールする?
さてエラーがでなくなる状態になったのはよいですが、これだけでは絶対的な処理速度がでてきません。エラー出さずに処理速度をスケールさせる方針を考えていきます。
答えは単純でProvisionedThroughputあげて実際に反映されるのを待ってから、RabbitMQでの処理並列数を増やす方針です。
Queueの滞留数を監視し、閾値を超えた場合にアラートを出すとともにDynamoDBのProvisionedThroughputを調整、15分以上アラートが収まらない場合にワーカー数を増やす or prefetch_countの上限を増やすといった形で処理速度を上げるような形をとりました。15分待つのは上限緩和が反映されるタイムラグを考慮しているためです。
まとめ
RabbitMQの処理の流れを考えて、実際どこにどの程度時間がかかっているのかを把握し、prefetch_countという設定値の調整で並列処理数を調整したという話。
設定値の見方変えると活用方法あるものだなーと思え、色々考え方を変えれるよい経験でした。