はじめに
コンテスト内容
コンテスト内容はこちらを参照して下さい。というか、わざわざこんな記事を読もうと思ってくれた方であれば、改めて説明を記載する必要はない気がしますが、、、一応概要を簡単に抜粋しておきます。
| 課題 | (開発)車両前方の画像および全方位の点群データから、3D物体検出を行うアルゴリズムを作成 (実装)開発したアルゴリズムを、RISC-Vを搭載したプラットフォームに実装 |
|
| 提供データ | 車両前方の画像データ 車両全方位の点群データ 物体のラベル付けされた3Dバウンディングボックスとカテゴリ |
|
| 認識対象 | 乗用車、歩行者 |
|
| 実装方法 | RISC-Vを実装し、RISC-Vコアを物体追跡の処理の中で使用 | |
| プラットフォーム | Ultra96ボードに加え、任意のFPGAボード、RISC-V搭載ボードを対象とする |
|
| 最終提出物 | ソースコード、エリアレポート、実装アプローチ、処理性能等 |
|
| 評価方法 | 審査により、完成度(定性)、精度(定量)、動作速度(定量)の総合点で評価 |
|
参加しようと思った経緯
コンテストの概要を一見して、まともに課題をこなして、最終提出物まで至れる気は正直しませんでした。これだけ広い技術領域を一人でカバーできる人ってどれほどいるんでしょうか?(チームで参加して、技術領域を相互補完するというのが前提?)
ただ、課題で取り扱っている技術・デバイスは、個人的に興味がある部分が多く、かつ、これでもかとばかりに充実されたリファレンス情報を見て、例え最終提出まで至らなくても、コンテストに参加して、色々触ってみるだけでも勉強になりそうだと思い、やってみることにしました。
ソフトウェアのリファレンス環境、ハードウェアのリファレンス環境、オンラインセミナーに、KV260ボードの提供まで、結構至れり尽くせりのサポートがあります。
このような背景を鑑み、オープンソースでライセンス料がかからない「RISC-V(リスク・ファイブ)」をテーマに掲げ、これまでのソフトウェアを中心としたAI技術開発に加え、RISC-Vチップを搭載したハードウェア・ソフトウェア(ネットワークモデル及び、システム最適化)を含めたシステム開発を課題として設定し、AIハードウェアも視野に入れた人材育成・スタートアップ育成、さらにはこれら技術を活用した産業育成を図るべく、今回のコンテストを実施します。本コンテストでは、ソフトウェア、ハードウェアのリファレンス環境を始め、各種サポートも充実させていきます。それらも参考に、エッジコンピューティング分野への挑戦のきっかけとしてご参加いただけますと幸いです。
開発環境
- メモリ48GB (WSL2 32GB / Windows11 16GB)
- GPU GeForce GTX 1660 Ti
- Ubuntu 20.04.5 LTS (GNU/Linux 5.10.102.1-microsoft-standard-WSL2 x86_64) (Windows11)
- Vitis/Vivado/Petalinux 2022.1
- Vitis-AI v2.5
KV260のハードウェア構築
ハードウェアリファレンスからの環境構築
下記ブログでハードウェア環境の構築について、丁寧に解説して頂いていたので、基本的にはこちらに沿って、環境構築を試みました。
- WSL2上でのVitis環境構築
- KV260用のSDイメージの作成
- KV260用のVitisプラットフォームの作成
- KV260プラットフォームにRISC-Vを組み込む
KV260プラットフォームにRISC-Vを組み込むの5.24までは手順通りにやって、うまくいったのですが、Vitisアクセラレータを組み込んだ後のビルドでエラーが発生し、うまく行きませんでした。一つ目の問題点としては、初めの環境では、WSL2 8GB / Windows11 8GBのメモリ容量でコンパイルを実行していたため、メモリ不足でビルドエラーが発生していたようです。Ubuntu上でのスワップ領域拡張 or メモリ増設で、メモリ不足によるエラーは回避できたのですが、また、別のエラーが発生し、これは未解決のままです。(この時のエラーログを残せていないので、この情報を記載したところで、誰の参考にもならないと思いますが、、、)
そこで、ダメ元で上記のハードウェアリファレンスで公開されているスクリプトをそのまま実行してみたところ、エラーなくビルドが完了しました。結果的にはハードウェア環境の構築はできたのですが、自分で手を動かさずに、スクリプトを実行しただけでの環境構築となってしまったので、ハードウェアの変更やデバッグに備え、少し実施内容を振り返ってみました。
madrid@Madrid-desktop:~/AIEDGE6/sd_aiedge$ ls
aiedge.bin aiedge.xclbin pl.dtbo shell.json
ハードウェア環境構築の内容確認
スクリプトを実行しただけで、ハードウェアプラットフォームが完成してしまい、何がどのように作成されたものなのか、ろくにイメージができていない状態だったので、全体像を理解しやすそうな資料を探したところ、下記が比較的わかりやすいと感じました。
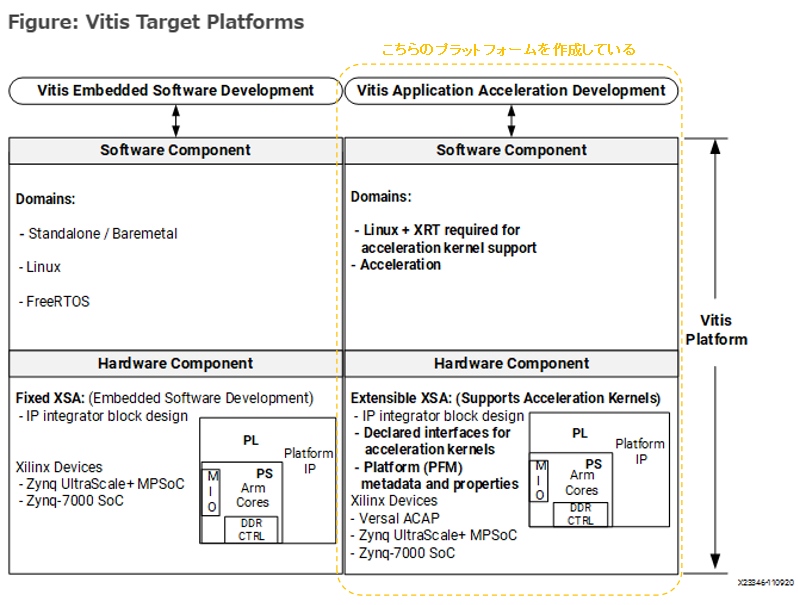
上記に記載してあったVitis Acceleration Kernel Flowと、スクリプト上での実行手順との対応を、自分の理解を記載してみました。(誤解している部分はあるかもしれません。)
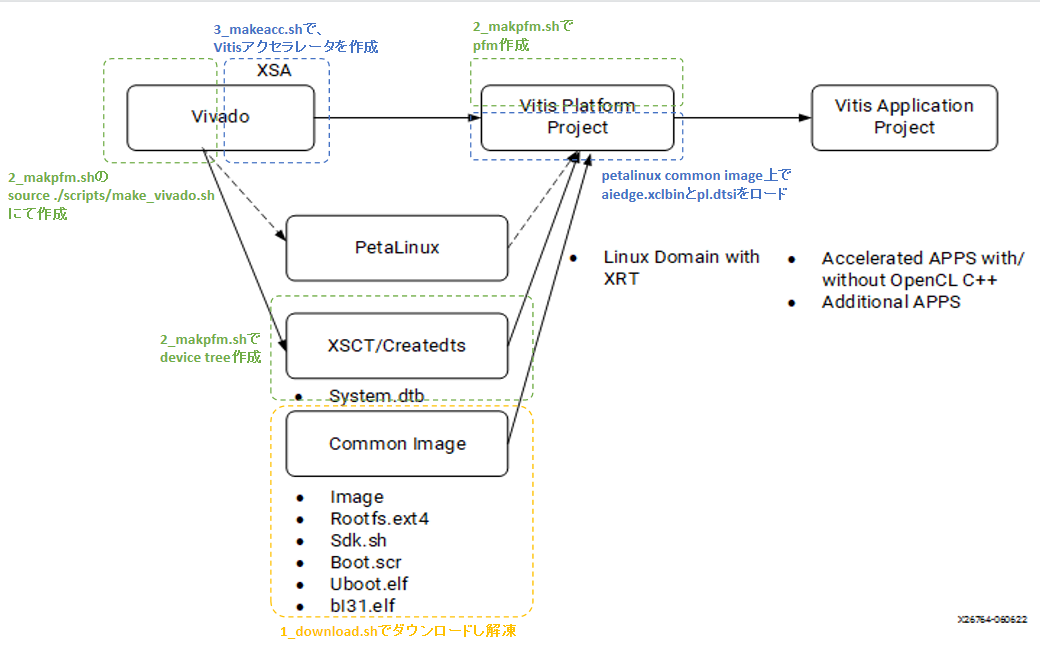
HWブロック図の確認
スクリプトによって作成されたハードウェアプラットフォームの構成が、どのようになっているか把握したかったため、プロジェクトファイルより、ブロック図を開いて確認しました。
madrid@Madrid-desktop:~/AIEDGE6$ source /tools/Xilinx/Vivado/2022.1/settings64.sh
madrid@Madrid-desktop:~/AIEDGE6$ vivado ./vitis/aiedge/link/vivado/vpl/prj/prj.xpr &
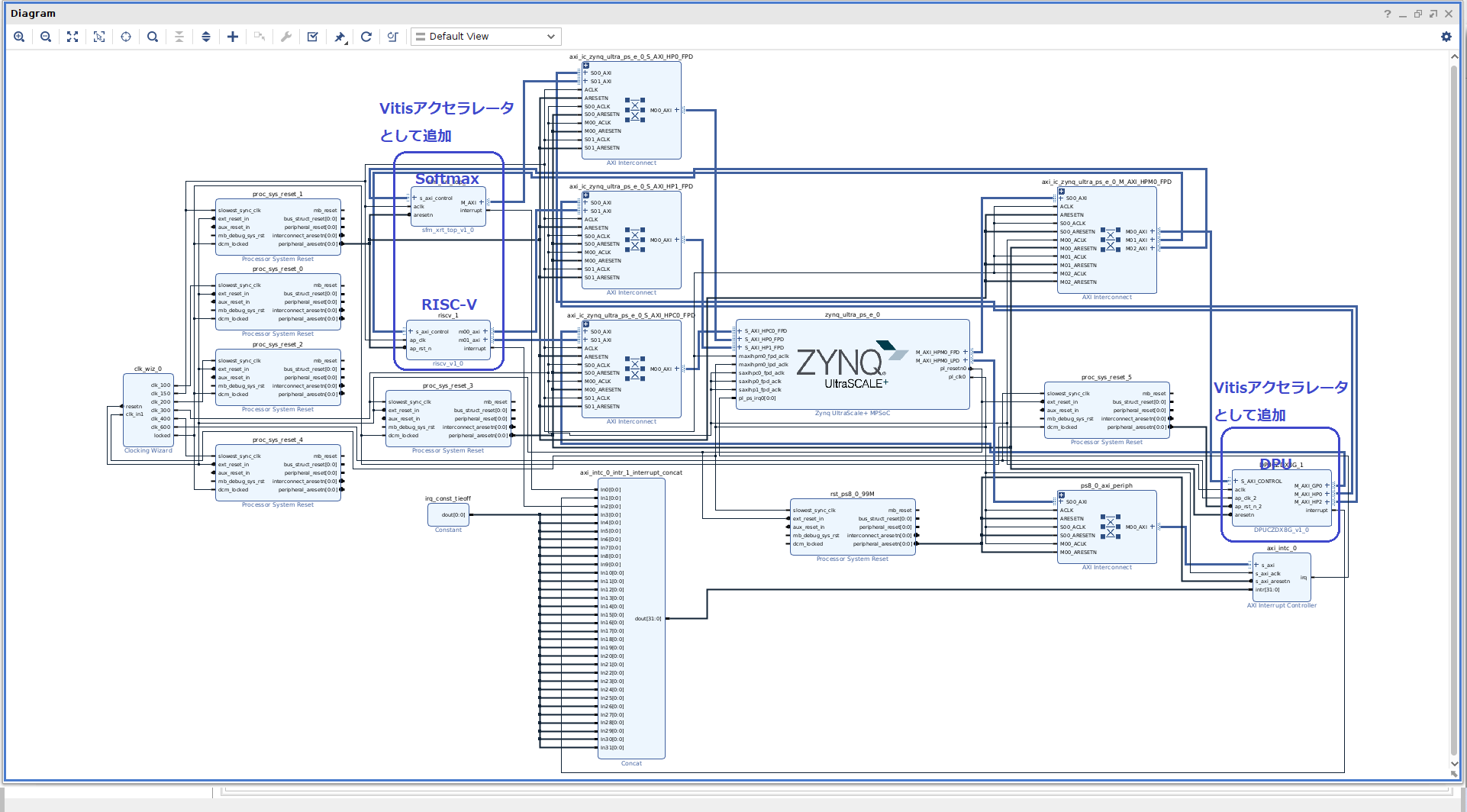
青枠で囲ったように、DPU、Softmax、RISC-Vが追加されていることが分かります。
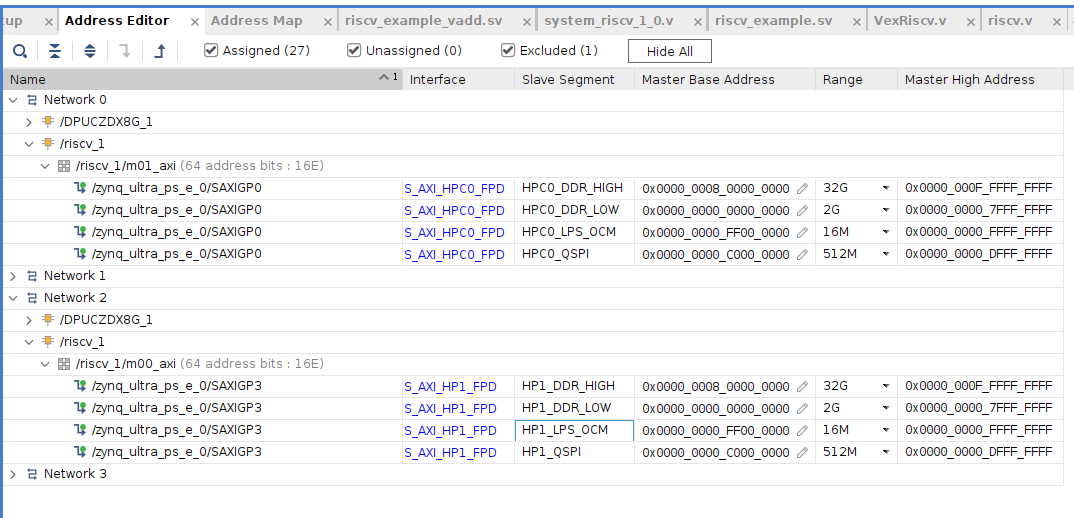
PSからRISC-Vへどのようにアクセスするかがよく分からないものの、アドレスマップを確認してみたところ、m00_axi, m01_axiともにPSにつながっていることが分かります。DDRもマッピングされているように見え、PSとRISC-Vとでマッピングが共有されている状態なんでしょうか?
MNIST実行時のエラー発生
ひとまずハードウェアプラットフォームの構築の概要確認ができたので、次に、Vitis-AIチュートリアルのMNISTを動作させてみることにしました。
手順通りに実行していき、KV260上でMNISTを実行してみるところまでは、スムーズにいったんですが、3.7項のMNISTを実行してみたところ、以下のエラーが発生。
xilinx-k26-starterkit-20221:~/target_kv260$ python3 app_mt.py --model=CNN_kv260.xmodel
Command line options:
--image_dir : images
--threads : 1
--model : CNN_kv260.xmodel
WARNING: Logging before InitGoogleLogging() is written to STDERR
F1122 14:31:22.523355 983 dpu_controller.cpp:44] Check failed: !the_factory_methods.empty()
*** Check failure stack trace: ***
Aborted
xilinx-k26-starterkit-20221:~/target_kv260$
show_dpuをしても、同様のCheck failed: !the_factory_methods.empty()が発生しており、どうもDPUを正常に認識できてなさそうだなあ、、、と思いつつ、色々とググってもそれらしい解決策が見当たらず、ハマりました。しかし、似たような問題で解決策を書いて頂いている記事を見つけ、同様にxrtとzoclをversion指定でインストールしなおしたところ、MNISTが正常に動作することを確認できました。(大変助かりました!)
MNISTの実行結果
xilinx-k26-starterkit-20221:~/target_kv260$ python3 app_mt.py --model=CNN_kv260.xmodel
Command line options:
--image_dir : images
--threads : 1
--model : CNN_kv260.xmodel
-------------------------------
Pre-processing 10000 images...
-------------------------------
Starting 1 threads...
-------------------------------
Throughput=4031.56 fps, total frames = 10000, time=2.4804 seconds
Correct:9892, Wrong:108, Accuracy:0.9892
-------------------------------
PointPaintingのリファレンス環境の実行(ホストPC)
ハードウェアプラットフォームの作成が一段落したところで、次は3D物体検出のリファレンス環境の動作確認をしてみました。KV260でどのように実装するか以前に、3D物体検出がどういうものか?を知るためです。
(開発)車両前方の画像および全方位の点群データから、3D物体検出を行うアルゴリズムを作成
Step2.本コンテストの配布データを用いたリファレンス環境(PointPaintingの学習、推論環境及び、学習済みモデル)を公開しています。
https://github.com/pometa0507/6th-ai-reference2
dockerコンテナ上でjupyter notebookの実行
docker/README.mdに従って、dockerコンテナ上でjupyter notebookを実行してみました。
cd ./docker
docker-compose build
docker-compose up -d
下記のようにコンテナが正常に起動していることが確認できます。
madrid@Madrid-desktop:~/6th-ai-reference2/docker$ docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------------------------------
docker_lab_1 jupyter notebook --ip=0.0. ... Up 0.0.0.0:6006->6006/tcp, 0.0.0.0:8889->8889/tcp
madrid@Madrid-desktop:~/6th-ai-reference2/docker$
デフォルトではポートが8888になっていたのですが、正常に動作しなかったため、以下のようにdocker-compose.ymlを編集し、ポートを8889に変更しています。
docker-compose.yml
madrid@Madrid-desktop:~/6th-ai-reference2/docker$ cat docker-compose.yml
version: '3'
services:
lab:
build:
context: .
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
volumes:
- ../:/work
ports:
- 8889:8889
- 6006:6006
shm_size: '8gb'
madrid@Madrid-desktop:~/6th-ai-reference2/docker$
README.md通り、bashを起動しました。
Dockerをろくに使用したことがなかったので、このコマンドがやっていることの意味があまり分からなかったのですが、labっていうコンテナに入って、bashを起動しているってことなんですね。
madrid@Madrid-desktop:~/6th-ai-reference2/docker$ docker-compose exec lab bash
root@78d30e9dce66:/work#
次は、jupyter notebookをコンテナ上で起動すればよいはずですが、README.mdではそこまで記載されていなかったので、下記を参考に実行しました。jupyter notebookを使うことも含めて、やったことないばかりなので、一々調べないと起動の仕方すら分からない、ってことが多数なんですよね。
jupyter-notebookを起動
root@78d30e9dce66:/work# jupyter notebook --port=8889 --ip=0.0.0.0 --allow-root --NotebookApp.token=''
[I 18:24:02.199 NotebookApp] Authentication of /metrics is OFF, since other authentication is disabled.
[W 18:24:02.301 NotebookApp] All authentication is disabled. Anyone who can connect to this server will be able to run code.
[I 18:24:02.303 NotebookApp] Serving notebooks from local directory: /work
[I 18:24:02.303 NotebookApp] Jupyter Notebook 6.5.2 is running at:
[I 18:24:02.303 NotebookApp] http://78d30e9dce66:8889/
[I 18:24:02.303 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[W 18:24:02.305 NotebookApp] No web browser found: could not locate runnable browser.
chromeを起動し
madrid@Madrid-desktop:~/6th-ai-reference2$ google-chrome &
[1] 1223
madrid@Madrid-desktop:~/6th-ai-reference2$
chromeで、http://localhost:8889にアクセスして、Jupyter Notebookを表示しました。
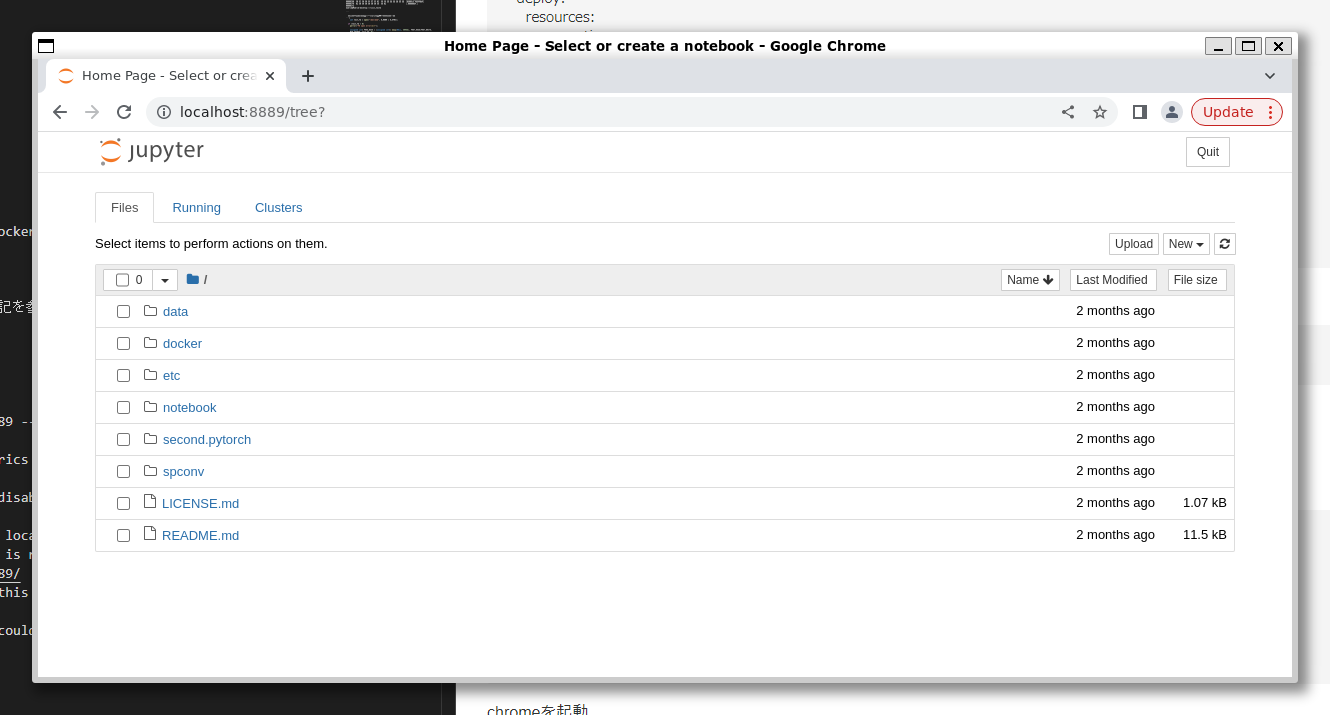
jupyter notebook起動後のリファレンス環境の実行
jupyter notebook起動後は、記載の手順に従って、
1-1_painting.ipynb
1-2_create_Dataset_metadata.ipynb
1-3_train.ipynb
1-4_inference.ipynb
1-5_single_inference.ipynb
を順に実行することで、問題なく3D物体検出を行うことができました。
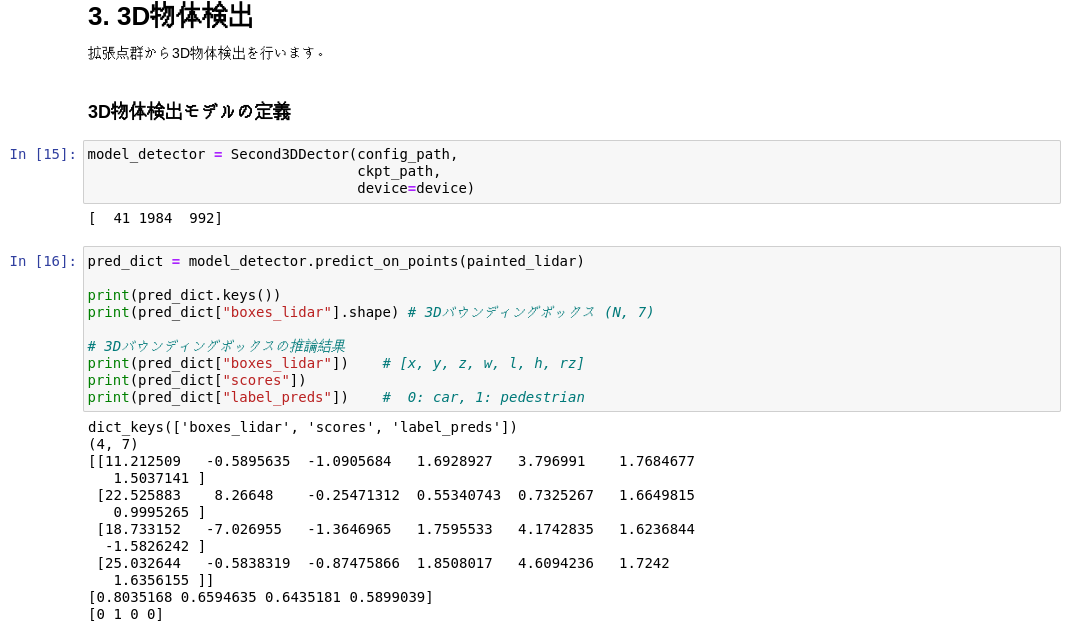
3D物体検出に関する基礎知識が全くない状態だったので、完全に思考停止した状態で、上記作業を実施していました、、、ただ、これだと何も得るものがないので、最低限として1,2を可能な範囲で把握できるように試みました。(理想的には下記の1~4を実行できることなのですが)
- PointPaintingで、点群データ+カメラ画像での3D物体検出をどのように行っているのか?を把握
- 把握した内容を元に、コード上での具体的な実装内容も把握
- PointPainting以外の手法がどういったものがあるのか?を調査し、各手法の性能を把握。
- 各手法の性能・負荷を踏まえ、どれをKV260に実装するのかを判断
PointPainting: Sequential Fusion for 3D Object Detection
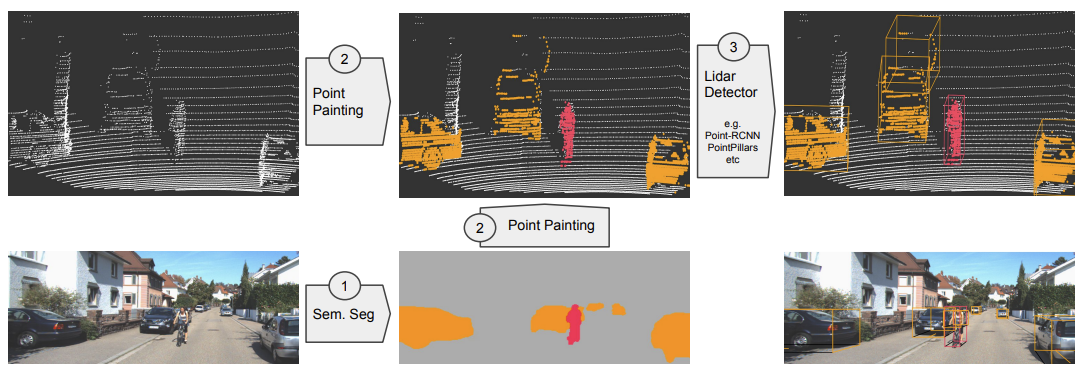
リファレンス環境の説明や下記webを参照すると、以下のような処理を実施していると理解しました。
-
カメラ画像のセマンティックセグメンテーションを実施。ピクセルごとのセグメンテーションスコアを取得する。
deeplabv3を使用しセグメンテーションを実施し、入出力のデータは以下の通り。
入力:画像 (H, W, 3)
出力:セグメンテーションスコア (H, W, C) -
Lidarの点群データのペインティング
セグメンテーションスコアをLidarの点群に投影し、通常の点群データにセグメンテーションスコアを追加したデータを取得する(拡張点群)
入力:class_scores, 点群データ(bin) (x,y,z,intensity)
出力:拡張点群データ(bin) (x, y, z, intensity, C1, C2, C3) -
拡張点群から、Pointpillarsなどの手法を用い、3D物体検出を実施 (Lidar Detector)
PointPaintningについて、なんとなくイメージはついたのですが、点群データから3D物体検出を実施するPointPillarsでどのような処理を実施しているか?がよく分からなかったので、次にその確認をしました。
PointPillars: Fast Encoders for Object Detection from Point Clouds
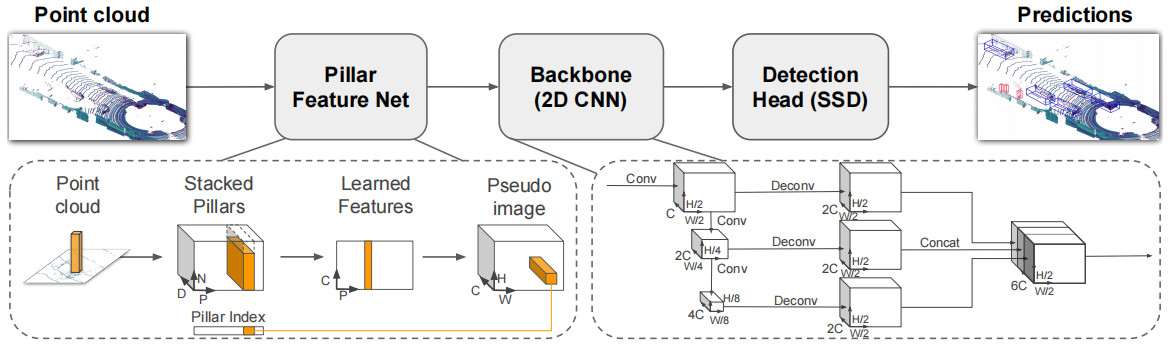
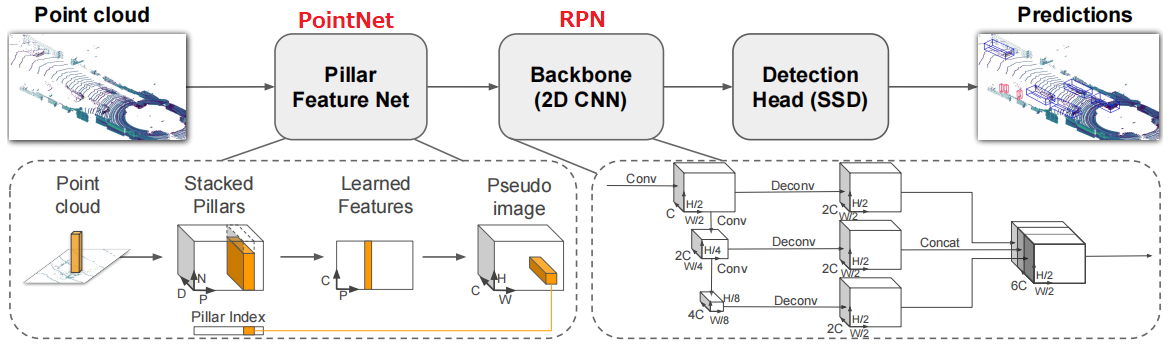
狙いとしては点群の細かい情報量を失わないように情報量をエンコードし、疑似画像に変換する。その疑似画像を2D CNNで使用するような物体検出ネットワークに入力し、物体検出を行う。 この手法の進歩性は従来単純に点群を俯瞰画像といった疑似画像に投影し物体検出CNNに入力するだけでは点群の細かい情報量が失われてしまっていた。そこで点群を画像に投影するためのエンコードネットワークを用いることで点群情報を失わずに物体検出CNN(SSD)に入力データを与え高精度化を達成した。
上記の説明が概略としてはわかりやすかったのですが、Pillar Feature Netで、Point cloudをStacked Pillarsに変換するところから詳細を見ていっても、何をやっているのか?が今一つ分かりませんでした。Xc, Yc, Zc, Xp, Ypのパラメータの説明は記載あるのですが、何を示して、これが追加され9次元になることで、どういう意味があるんでしょうか?
3D point clouds bounding box detection and tracking
Each point in the cloud, which is a 4-dimensional vector (x,y,z, reflectance), is converted to a 9-dimensional vector containing the additional information explained as follows:
Xc, Yc, Zc = Distance from the arithmetic mean of the pillar _c _the point belongs to in each dimension.
Xp, Yp = Distance of the point from the center of the pillar in the x-y coordinate system.
Hence, a point now contains the information D = [x,y,z,r,Xc,Yc,Zc,Xp,Yp].
また、PointPillarsの入力は通常の点群データで、(x,y,z,intensity)の4つのパラメータが想定されているようですが、セグメンテーションスコアを追加した拡張点群だと、どのように処理が変化するのか?もよく分かりませんでした、、、
6th-ai-reference2/pointpainting.config
おそらくこのあたりのコンフィグファイルで設定をしているのだろうとは思ったのですが。
KV260でPointPillarsのサンプルを実行
ホストPC上でPointPaintingのリファレンス環境の実行を一通り完了したので、次はKV260上でPointPaintingを実行してみようと思い、Vitis-AIでサンプルプログラムを探してみました。
下記のように、PointPainitng, PointPillarsのサンプルプログラムを見つけたのですが、この取り組みをしている段階では、PointpaintingとPointPillarsの違いすらよく分かっていない残念な状態だったため、とりあえずPointPillarsのサンプルプログラムを実行してみることにしてしまいました。

モデルの準備・変換
モデルについては、PointNet用とRPN用のモデルを準備する必要があるようです。
Important:
./test_bin_pointpillars.cpp , ./test_performance_pointpillars, ./test_accuracy_pointpillars first param followed must be with 2 model names.
first model name is for PointNet, second model name is for RPN
Valid model name:
PointNet: pointpillars_kitti_12000_0_pt
RPN: pointpillars_kitti_12000_1_pt
PointNetとRPN用のモデルが二つ必要というのは、PointPillarsのネットワーク構成で、PointNet=Pillar Feature NET用モデル、RPN=Backbone用モデルと理解しました。
いずれにせよ、モデルの準備が必要ということで、どのように準備すればよいのか?と疑問に思っていたところ、下記サイトでYOLOv4用のモデルを準備する方法が紹介されていたので、参考にさせていただきました。
KV260向けにVitisプラットフォームを作成してDPUを動かす その2
各サンプルプログラムのモデルは、AI-model-zooで提供されているようなので、こちらからPointPillars用のモデルをダウンロードしました。
Vitis-AI/model_zoo/model-list at v2.5
PointPillars用のmodel.yamlを参照し、KV260用のPointNet, RPNモデルをダウンロードしました。
https://github.com/Xilinx/Vitis-AI/blob/v2.5/model_zoo/model-list/pt_pointpillars_kitti_12000_100_10.8G_2.5/model.yaml
- name: pointpillars_kitti_12000_0_pt
type: xmodel
board: zcu102 & zcu104 & kv260
download link: https://www.xilinx.com/bin/public/openDownload?filename=pointpillars_kitti_12000_0_pt-zcu102_zcu104_kv260-r2.5.0.tar.gz
checksum: 813e685ed438751770257d3caa1ea3d2
- name: pointpillars_kitti_12000_1_pt
type: xmodel
board: zcu102 & zcu104 & kv260
download link: https://www.xilinx.com/bin/public/openDownload?filename=pointpillars_kitti_12000_1_pt-zcu102_zcu104_kv260-r2.5.0.tar.gz
checksum: 326422a85ca42ab276490e590b68b2c5
tar.gzをそれぞれ解凍したところ、以下のようなファイルが格納されていることを確認。
xilinx-k26-starterkit-20221:~/pointpillars/pointpillars_kitti_12000_1_pt$ ls -l
total 1564
-rw-r--r-- 1 petalinux petalinux 33 Nov 23 13:03 md5sum.txt
-rw-r--r-- 1 petalinux petalinux 218 Nov 23 13:03 meta.json
drwxr-xr-x 2 petalinux petalinux 4096 Nov 25 13:31 old
-rw-r--r-- 1 petalinux petalinux 213 Nov 23 13:03 pointpillars_kitti_12000_1_pt.prototxt
-rw-r--r-- 1 petalinux petalinux 1581195 Nov 25 13:30 pointpillars_kitti_12000_1_pt.xmodel
xilinx-k26-starterkit-20221:~/pointpillars/pointpillars_kitti_12000_1_pt$
xilinx-k26-starterkit-20221:~/pointpillars/pointpillars_kitti_12000_0_pt$ ls -l
total 1444
-rw-r--r-- 1 petalinux petalinux 33 Nov 23 13:03 md5sum.txt
-rw-r--r-- 1 petalinux petalinux 292 Nov 23 13:03 meta.json
drwxr-xr-x 2 petalinux petalinux 4096 Nov 25 13:30 old
-rw-r--r-- 1 petalinux petalinux 213 Nov 23 13:03 pointpillars_kitti_12000_0_pt.prototxt
-rw-r--r-- 1 petalinux petalinux 1452685 Nov 25 13:29 pointpillars_kitti_12000_0_pt.xmodel
-rw-r--r-- 1 petalinux petalinux 6118 Nov 23 13:03 pointpillars_kitti_12000_0_pt_officialcfg.prototxt
xilinx-k26-starterkit-20221:~/pointpillars/pointpillars_kitti_12000_0_pt$
ただし、このxmodelはDPUのコンフィグレーションが異なるため、そのまま使用できず、別途準備が必要となります。ただし、prototxtファイルはこちらのが必要ということのようです。
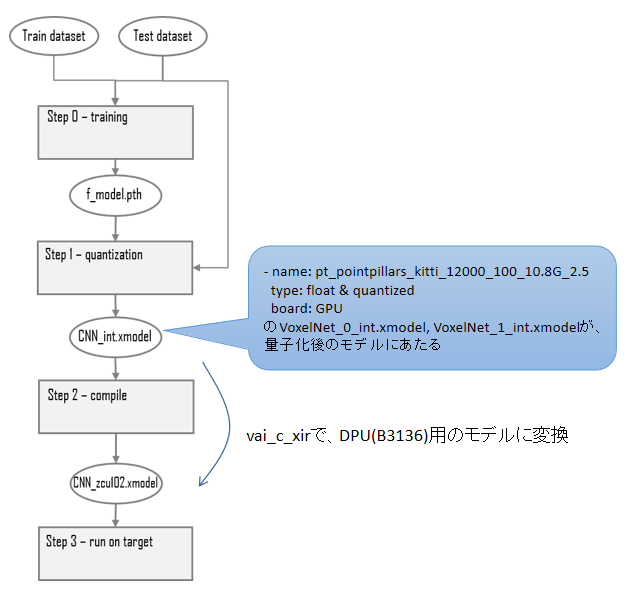
float&quantizedとxmodelのダウンロードURLをmodelzooから取得してファイルをダウンロードします。
model-zooで公開されているxmodelは前回記事で作成したDPUコンフィグレーション向けのものではないため動作しません。動作しないのでxmodel自体は不要なのですが、xmodelと同梱されているprototxtファイルが必要なのでダウンロードします。
今回のDPUのコンフィグレーションに合わせたxmodelファイルを作成するため、GPU用のモデルをダウンロードしました。
- name: pt_pointpillars_kitti_12000_100_10.8G_2.5
type: float & quantized
board: GPU
download link: https://www.xilinx.com/bin/public/openDownload?filename=pt_pointpillars_kitti_12000_100_10.8G_2.5.zip
checksum: c5d1f39ba0ff2120aecae8b326ae0542
解凍後のVoxelNet_0_int.xmodelと、VoxelNet_1_int.xmodelを、今回のDPUコンフィグレーション(B3136)に合わせたモデルとして、変換が必要となります。
madrid@Madrid-desktop:~/Vitis-AI/model_zoo/pt_pointpillars_kitti_12000_100_10.8G_2.5/quantized$ ls
VoxelNet.py VoxelNet_0_int.xmodel VoxelNet_1_int.xmodel bias_corr.pth quant_info.json
モデルの変換方法については、下記を参照し実施しました。
KV260にVitis AIを組み込む(AIEDGEコンテスト対応版)
vitis-aiを起動
madrid@Madrid-desktop:~/Vitis-AI$ ./docker_run.sh xilinx/vitis-ai-gpu:latest
pointpillarsのディレクトリに移動
Vitis-AI /workspace > cd examples/Vitis-AI-Library/samples/pointpillars
vitis-ai-pytorchをactivateします
Vitis-AI /workspace/examples/Vitis-AI-Library/samples/pointpillars > conda activate vitis-ai-pytorch
(vitis-ai-pytorch) Vitis-AI /workspace/examples/Vitis-AI-Library/samples/pointpillars >
下記コマンドにてモデルの変換を実施し、B3136用のモデルが生成されたようです。
Pointpillars用のモデル変換 (長いので折り畳み)
(vitis-ai-pytorch) Vitis-AI /workspace > export ARCH=/workspace/arch.json
(vitis-ai-pytorch) Vitis-AI /workspace > export TARGET=kv260
(vitis-ai-pytorch) Vitis-AI /workspace > cd examples/Vitis-AI-Library/samples/pointpillars
(vitis-ai-pytorch) Vitis-AI /workspace/examples/Vitis-AI-Library/samples/pointpillars > vai_c_xir --xmodel VoxelNet_0_int.xmodel --arch $ARCH --net_name PointPillar --output_dir ./VoxelNet_0_0102/
**************************************************
* VITIS_AI Compilation - Xilinx Inc.
**************************************************
[UNILOG][INFO] Compile mode: dpu
[UNILOG][INFO] Debug mode: function
[UNILOG][INFO] Target architecture: DPUCZDX8G_ISA1_B3136
[UNILOG][INFO] Graph name: VoxelNet_0, with op num: 11
[UNILOG][INFO] Begin to compile...
[UNILOG][INFO] Total device subgraph number 3, DPU subgraph number 1
[UNILOG][INFO] Compile done.
[UNILOG][INFO] The meta json is saved to "/workspace/examples/Vitis-AI-Library/samples/pointpillars/./VoxelNet_0_0102/meta.json"
[UNILOG][INFO] The compiled xmodel is saved to "/workspace/examples/Vitis-AI-Library/samples/pointpillars/./VoxelNet_0_0102//PointPillar_0102.xmodel"
[UNILOG][INFO] The compiled xmodel's md5sum is 0b4de62313fad7905c9079d3a654249b, and has been saved to "/workspace/examples/Vitis-AI-Library/samples/pointpillars/./VoxelNet_0_0102/md5sum.txt"
(vitis-ai-pytorch) Vitis-AI /workspace/examples/Vitis-AI-Library/samples/pointpillars >
このxmodelをKV260用としてダウンロードしたもの一式と、xmodelのみ差し替えて使用します。
pointpillars用のmodel.yamlを参照し、KV260用のPointNet, RPNモデルをダウンロードしました。
https://github.com/Xilinx/Vitis-AI/blob/v2.5/model_zoo/model-list/pt_pointpillars_kitti_12000_100_10.8G_2.5/model.yaml
モデルの変換フローについて
一連のモデルの変換フローについて、全体像が今一つ分からず、少し調べてみましたが、以下で分かりやすく説明されていました。
Compiling for DPU - Vitis AI 2.5 User Guide
Vitis AI 2.5の公式ユーザーガイドの、DPU向けコンパイルの項目で、XIRベースのコンパイラでのDPU向けのモデル変換が記載されていますが、これは何をやっているかがちょっと分かりづらい。
Vitis-AI-Tutorials/Design_Tutorials/09-mnist_pyt/README.md
こちらも公式のVitis AIのチュートリアルのmnistのページなのですが、Pytorch向けのフローチャートがのっており、分かりやすいです。Vitis 1.4向けなんですが、、、2.5でも同じだろう、多分。
オープンソースのPyTorchモデルをVitis™ AI (1.4)を用いて、So-One KITで動かしてみた
上記で説明されているPytorchのモデル変換フローと、実施した手順を照らし合わせると、以下部分を実施していたようです。
PointPillarsサンプルプログラムの予測実行
PointPillarsのDPU用のモデルの準備ができたので、サンプルプログラムの実行を試してみます。
下記にあるように、まずはホストPC側でビルドを実施し、実行ファイルをKV260にコピーします。
> 1, compile
execute the following command:
sh build.sh
2, copy the compiled executable file and test image to the development board.
run the executable file.
また、サンプルを実行時に読み込ませる画像ファイルと点群データを、適当に学習用データ(train_0.zip)から取り出して、KV260にコピーしておきました。
学習用データ(train_0.zip)
KV260でサンプルプログラムを実行する前に、DPU含むアクセラレータのロードをしていないので、DPUのロードを実行します。
xilinx-k26-starterkit-20221:~/pointpillars$ sudo xmutil loadapp aiedge
aiedge: loaded to slot 0
xilinx-k26-starterkit-20221:~/pointpillars$
KV260上でPointPillarsのサンプルプログラムを実行したところ、以下のように出力されることを確認できました。
xilinx-k26-starterkit-20221:~/pointpillars$ ./test_bin_pointpillars pointpillars_kitti_12000_0_pt pointpillars_kitti_12000_1_pt 0TyydnMdYWU1YD7nw5uCNGs8_1.bin 0TyydnMdYWU1YD7nw5uCNGs8_1.jpg
0 31.369604 3.105865 -2.171492 1.650789 3.900000 1.465484 1.835625 0.798187
xilinx-k26-starterkit-20221:~/pointpillars$
サンプルのコードを確認したところ、ラベル、ボックスの座標、スコアの順に出力しているようです。
auto net = vitis::ai::PointPillars::create(argv[1], argv[2]);
(snip)
auto res = net->run(PointCloud);
(snip)
for (unsigned int i = 0; i < res.ppresult.final_box_preds.size(); i++) {
std::cout << res.ppresult.label_preds[i] << " " << std::fixed
<< std::setw(11) << std::setprecision(6) << std::setfill(' ')
<< res.ppresult.final_box_preds[i][0] << " "
<< res.ppresult.final_box_preds[i][1] << " "
<< res.ppresult.final_box_preds[i][2] << " "
<< res.ppresult.final_box_preds[i][3] << " "
<< res.ppresult.final_box_preds[i][4] << " "
<< res.ppresult.final_box_preds[i][5] << " "
<< res.ppresult.final_box_preds[i][6] << " "
<< res.ppresult.final_scores[i] << "\n";
}
PointPillarsクラスのrunメソッドを確認してみると、vitis::ai::PointPillarsResultを返していて、
vitis::ai::PointPillarsResultの、ppresultを出力しているようです。
ppresultはこんなの。
typedef struct
{
V2F final_box_preds;
V1F final_scores;
V1I label_preds;
} vitis::ai::PPResult;
V2Fって何?、、、と思って、pointpillars.hppを参照してみましたが、要はボックスの座標データを格納する二次元配列のようですね。
using V1F = std::vector<float>;
using V2F = std::vector<V1F>;
using V1I = std::vector<int>;
using V2I = std::vector<V1I>;
ここまで調べてようやく、それっぽい出力データが得られているのかな?と思いましたが、テキスト出力だけでなく、do_pointpillar_displayを使って、予測結果の可視化を行った画像データも出力されているようです。
点群データの方は正常な位置になっているのか?がいまいちわかりませんでしたが、画像データは明らかに違う(笑)
Lidarの点群データの座標→カメラ画像の座標への正常な変換がなされていないためでしょうか?

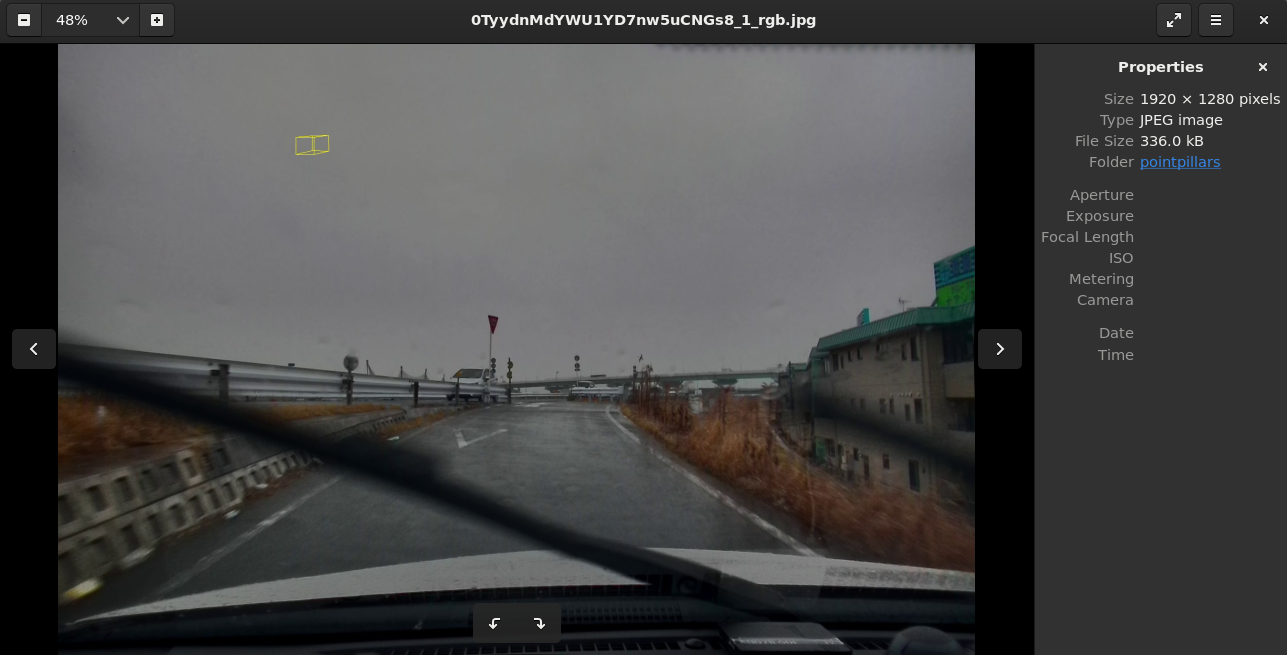
KV260でPointPillarsを実行した結果を可視化
KV260のサンプルプログラムでの、予測結果の可視化がうまくできていないような気がしたので、ホストPC側のリファレンス環境を流用して、可視化ができないか?も試してみました。
コード全体
import copy
import os
import sys
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
%matplotlib inline
import cv2
import torch
from nuscenes.nuscenes import NuScenes
from nuscenes.utils.data_classes import LidarPointCloud
from pyquaternion import Quaternion
from torchvision import transforms
from utils.box_plot import boxes_to_corners_3d, cv2_draw_3d_bbox
from utils.calibration_nuscenes import (get_image_points, lidar_to_cam,
lidar_to_global)
from utils.detector import Second3DDector
from utils.pointcloud_seg import (get_segmentation_score,
map_pointcloud_to_image, overlap_seg)
from utils.vis_pointcloud import (get_figure_data, view_pointcloud,
view_pointcloud_3dbbox)
dataset_path = "../data/3d_labels"
# シーンIDとフレームIDの選択
scene_id = 29
frame_id = 73
# 物体検知モデル
config_path = "../second.pytorch/second/configs/nuscenes/pointpainting.config"
ckpt_path = "../second.pytorch/checkpoints/pointpainting/voxelnet-24000.tckpt"
nusc = NuScenes(version='v1.0-trainval', dataroot=dataset_path, verbose=True)
assert scene_id < len(nusc.scene), \
f"SceneIDの指定値:{scene_id}が総シーン数:{len(nusc.scene)}を超えています。"
target_scene = nusc.scene[scene_id]
print(f"SceneID: {scene_id}")
print(f" 総フレーム数: {target_scene['nbr_samples']}")
print(f"FrameID: {frame_id}")
assert frame_id < target_scene["nbr_samples"], \
f"FrameIDの指定値:{frame_id}がフレーム数:{target_scene['nbr_samples']}を超えています。"
sample_token = target_scene['first_sample_token']
for i in range(frame_id):
sample = nusc.get('sample', sample_token)
sample_token = sample['next']
sample_record = nusc.get('sample', sample_token)
test_key = f"{target_scene['name']}_{frame_id:0>2}"
print(f"test_key: {test_key}")
# LidarとCamのtokenを取得
pointsensor_token = sample_record['data']['LIDAR_TOP']
camera_token = sample_record['data']['CAM_FRONT']
# LidarとCamのレコードを取得
pointsensor = nusc.get('sample_data', pointsensor_token)
cam = nusc.get('sample_data', camera_token)
# inputデータの形式で各メタ情報を取得
cam_path = os.path.join(nusc.dataroot, cam['filename'])
lidar_path = os.path.join(nusc.dataroot, pointsensor['filename'])
cam_ego_pose = nusc.get('ego_pose', cam['ego_pose_token'])
cam_calibration = nusc.get('calibrated_sensor', cam['calibrated_sensor_token'])
lidar_ego_pose = nusc.get('ego_pose', pointsensor['ego_pose_token'])
lidar_calibration = nusc.get('calibrated_sensor', pointsensor['calibrated_sensor_token'])
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# 学習済みのdeeplabv3モデルをロード
model_seg = torch.hub.load('pytorch/vision:v0.6.0',
'deeplabv3_resnet101', pretrained=True)
model_seg.eval()
model_seg.to(device)
print("Segmentation Model Loaded.")
model_detector = Second3DDector(config_path,
ckpt_path,
device=device)
img = Image.open("../data/3d_labels_painted/samples/CAM_FRONT/0TyydnMdYWU1YD7nw5uCNGs8_1.jpg")
plt.figure(figsize=(10, 6))
plt.imshow(img)
# 3Dバウンディングボックスの各頂点座標を取得 (N, 7) -> (N, 8, 3)
kv260_pred_dict = {}
kv260_pred_dict["label_preds"]= np.array([0])
kv260_pred_dict["boxes_lidar"]= np.array([[31.369604, 3.105865, -2.171492, 1.650789, 3.900000, 1.465484, 1.835625]])
kv260_pred_dict["score"]= np.array([0.798187])
print(kv260_pred_dict)
box_corners = boxes_to_corners_3d(kv260_pred_dict["boxes_lidar"])
labels = kv260_pred_dict["label_preds"]
print(box_corners.shape) # 3DBBox各頂点のxyz座標 (N, 8, 3)
# Lidar座標系 -> カメラ座標系 に変換
box_corners_cam = lidar_to_cam(box_corners.reshape(-1, 3),
cam_ego_pose,
lidar_ego_pose,
cam_calibration,
lidar_calibration)
# 点群を画像へ投影し画像上の座標を取得
projection = np.array(cam_calibration['camera_intrinsic'])
box_corners_img = get_image_points(box_corners_cam[:, :3], projection) # (N, 3)
box_corners_img = box_corners_img[:, :2] # (N * 8, 2)
box_corners_img = box_corners_img.reshape(-1, 8, 2) # (N, 8, 2)
print(box_corners_img.shape)
# print(box_corners_img)
name_list = model_detector.target_assigner.classes
label_name_dict = {i : name for i, name in enumerate(name_list)}
print(label_name_dict)
color_dict_label = {0: (253, 141, 60), # car: orange
1: (0, 0, 255), # pedestrian: blue
}
box_colors = [color_dict_label[label] for label in labels]
# 画像をOpenCVで読み込み
img_cv = cv2.imread("../data/3d_labels_painted/samples/CAM_FRONT/0TyydnMdYWU1YD7nw5uCNGs8_1.jpg")
img_cv = cv2.cvtColor(img_cv, cv2.COLOR_BGR2RGB)
# 3Dバウンディングボックス+画像を表示
img_cv_box = cv2_draw_3d_bbox(img_cv, box_corners_img,
box_colors, thickness=2, line_type=cv2.LINE_8)
plt.figure(figsize=(10, 6))
plt.imshow(img_cv_box)
下記のように推論結果を格納する辞書データ部分を、無理やりKV260の出力結果に差し替えて、表示できないか試してみました。
img = Image.open("../data/3d_labels_painted/samples/CAM_FRONT/0TyydnMdYWU1YD7nw5uCNGs8_1.jpg")
plt.figure(figsize=(10, 6))
plt.imshow(img)
# 3Dバウンディングボックスの各頂点座標を取得 (N, 7) -> (N, 8, 3)
kv260_pred_dict = {}
kv260_pred_dict["label_preds"]= np.array([0])
kv260_pred_dict["boxes_lidar"]= np.array([[31.369604, 3.105865, -2.171492, 1.650789, 3.900000, 1.465484, 1.835625]])
kv260_pred_dict["score"]= np.array([0.798187])
Lidar座標系からカメラ座標系の変換について、NuScenesのメタ情報をもとに座標変換をしているようなので、何らかの変更が必要?と思いましたが、詳細よく分からなかったため、そのまま使用しています。(あかん気もする)
# Lidar座標系 -> カメラ座標系 に変換
box_corners_cam = lidar_to_cam(box_corners.reshape(-1, 3),
cam_ego_pose,
lidar_ego_pose,
cam_calibration,
lidar_calibration)
# 点群を画像へ投影し画像上の座標を取得
projection = np.array(cam_calibration['camera_intrinsic'])
box_corners_img = get_image_points(box_corners_cam[:, :3], projection) # (N, 3)
box_corners_img = box_corners_img[:, :2] # (N * 8, 2)
box_corners_img = box_corners_img.reshape(-1, 8, 2) # (N, 8, 2)
可視化結果
お?それっぽくなりましたが、少しずれていますね。
そもそもの予測結果としてずれているのか、座標系の変換で問題があるのか、、、どちらでしょうか。

RISC-Vでの処理内容の検討
DPUでPointPillarsのサンプルプログラムを動作させ、DPU上での処理について何となくわかってきたので、とりあえず保留として、次はRISC-Vコアの実装に取り組むことにします。課題内容としては、RISC-Vコアでの物体検出の処理が要求されており、以下のようになっています。
実装方法
- RISC-Vコアを物体検出の処理の中で使用すること。
【許可ケース】
- DNN処理コアにおける制御マイコンとしてRISC-Vを使用しFPGAに実装
- DNN向け拡張命令を追加したRISC-VコアをFPGAに実装し、活用
- 計測区間内における処理の一部処理に、FPGA上に実装したRISC-Vコアを使用
- RISC-V搭載SoC K210を搭載したボードを用いて、SoC内のDNNコアと協調し、物体検出処理を実装
最終的には、これらいずれかの処理の実装をしたいと思うものの、そもそもRISC-Vコア上でのプログラムの実行方法すら、よく分からない状態なので、簡単なプログラムの実行に取り組むこととしました。
RISC-Vのプログラムをクロスコンパイル
クロスコンパイルする環境を立ち上げ、簡単なプログラムのコンパイルをやってみようと、基本的には下記を参照し、一連の作業を実施しました。ツールチェインのインストールは、README.mdを参照して実施することで、問題なく完了しました。
GitHub - riscv-collab/riscv-gnu-toolchain
アセンブリとリンカスクリプト
実行するプログラムとしては、下記でサンプルとして使用している、フィボナッチ数列の第10番目の項を再帰で求めるプログラムを使ってみました。
RISC-V 用のクロスコンパイラを使ってみる
RISC-Vクロスコンパイラで生成したバイナリを自作RISC-V上で実行する
ただ、例によって、アセンブリとリンカスクリプトの知識が全くなく、記載内容がよく分からないため、少し勉強が必要でした。
Assembly Programming on KURO-BOX4
RISC-V ASSEMBLY LANGUAGE Programmer Manual Part I
main関数のCファイルを普通にコンパイルしてしまうと、未実装の命令を使った初期化ルーチンが走ってしまうため、それを無効にするのに、下記のようにstart.Sを作成する、とのことです。
.section .text.init;
.globl _start
_start:
call main
.section .text.init;
- セクションとは、プログラム本体やプログラム中で使用する定数、文字列、変数に必要な性質に応じて区別して管理するためのもので、textセクションは、プログラム本体や初期化されて変更する必要のないデータを置くセクションを示しているそう。端的に言うと、書き換え不可の領域。
- initセクションについての情報があまり見当たらなかったのですが、文字通り初期化ルーチンを示しているんでしょうか。
.globl _start
- global or globl命令は、ソースファイル上で宣言したラベルを他のファイルからも利用できるように公開するための命令、ということのようです。つまり、_startというラベルを公開するための命令、ということですね。そして、_startラベルは、main関数をcallするだけ、と理解しました。
Usually, a defined symbol is visible only to partial program, only to the portion where it is
defined. With the .GLOBAL directive its value is made available to other partial programs that
are linked with it.
次に下記は命令を0番地から実行するようにするためのリンカスクリプトとのこと。
OUTPUT_ARCH( "riscv" )
ENTRY(_start)
SECTIONS
{
. = 0x00000000;
.text.init : { *(.text.init) }
.tohost : { *(.tohost) }
.text : { *(.text) }
.data : { *(.data) }
.bss : { *(.bss) }
_end = .;
}
GNU Cを使いこなそう | 株式会社コンピューテックス
https://sourceware.org/binutils/docs/ld.html
リンカースクリプト入門
OUTPUT_ARCH("riscv")
- 出力するアーキテクチャを指定しているようです。今回はRISC-Vなので、riscvとなっています。
ENTRY(_start)
- プログラムのエントリーポイントを指定しているようです。今回の場合、_startをエントリーポイントとして指定しています。
SECTIONS { . = 0x00000000; .text.init : { *(.text.init) }
- SECTIONSコマンドは、各セクションの配置を指定するためのコマンドで、このセクションの先頭のアドレスを0x00000000と指定して、次に.text.initセクションを配置しており、これで、start.S内の.text.initが呼び出されるようになっているのだと思います。
実行ファイルのコンパイル・データ変換
下記コマンドで、start.Sとfib.cのコンパイルを実施。
riscv64-unknown-elf-gcc -march=rv64imad -c -o start.o start.S
riscv64-unknown-elf-gcc -march=rv64imad -c -o fib.o fib.c
次に下記コマンドおよび、先に作成したlink.ldで、上記で生成したfib.o, start.oのオブジェクトファイルをリンクしています。
riscv64-unknown-elf-ld fib.o start.o -T link.ld -o fib.elf
生成した実行ファイルを、バイナリに変換し
riscv64-unknown-elf-objcopy -O binary fib.elf fib.bin
さらにhexファイルに変換に変換しています。
hexdump -v -e '/4 "%08X" "\n"' fib.bin > fib.hex
RISC-Vのプログラム実行の試行錯誤
上記で作成したfib.hexファイルをhexdumpにて出力し、378byteになっていることを確認しました。
fib.hexファイルのダンプ出力(折り畳み)
madrid@Madrid-desktop:~/riscv_test$ hexdump -C fib.hex
00000000 30 38 43 30 30 30 45 46 0a 46 44 30 31 30 31 31 |08C000EF.FD01011|
00000010 33 0a 30 32 31 31 33 34 32 33 0a 30 32 38 31 33 |3.02113423.02813|
00000020 30 32 33 0a 30 30 39 31 33 43 32 33 0a 30 33 30 |023.00913C23.030|
00000030 31 30 34 31 33 0a 30 30 30 35 30 37 39 33 0a 46 |10413.00050793.F|
00000040 43 46 34 32 45 32 33 0a 46 44 43 34 32 37 38 33 |CF42E23.FDC42783|
00000050 0a 30 30 30 37 38 37 31 42 0a 30 30 31 30 30 37 |.0007871B.001007|
00000060 39 33 0a 30 30 45 37 43 36 36 33 0a 30 30 31 30 |93.00E7C663.0010|
00000070 30 37 39 33 0a 30 34 30 30 30 30 36 46 0a 46 44 |0793.0400006F.FD|
00000080 43 34 32 37 38 33 0a 46 46 46 37 38 37 39 42 0a |C42783.FFF7879B.|
00000090 30 30 30 37 38 37 39 42 0a 30 30 30 37 38 35 31 |0007879B.0007851|
000000a0 33 0a 46 42 44 46 46 30 45 46 0a 30 30 30 35 30 |3.FBDFF0EF.00050|
000000b0 37 39 33 0a 30 30 30 37 38 34 39 33 0a 46 44 43 |793.00078493.FDC|
000000c0 34 32 37 38 33 0a 46 46 45 37 38 37 39 42 0a 30 |42783.FFE7879B.0|
000000d0 30 30 37 38 37 39 42 0a 30 30 30 37 38 35 31 33 |007879B.00078513|
000000e0 0a 46 41 31 46 46 30 45 46 0a 30 30 30 35 30 37 |.FA1FF0EF.000507|
000000f0 39 33 0a 30 30 46 34 38 37 42 42 0a 30 30 30 37 |93.00F487BB.0007|
00000100 38 37 39 42 0a 30 30 30 37 38 35 31 33 0a 30 32 |879B.00078513.02|
00000110 38 31 33 30 38 33 0a 30 32 30 31 33 34 30 33 0a |813083.02013403.|
00000120 30 31 38 31 33 34 38 33 0a 30 33 30 31 30 31 31 |01813483.0301011|
00000130 33 0a 30 30 30 30 38 30 36 37 0a 46 46 30 31 30 |3.00008067.FF010|
00000140 31 31 33 0a 30 30 31 31 33 34 32 33 0a 30 30 38 |113.00113423.008|
00000150 31 33 30 32 33 0a 30 31 30 31 30 34 31 33 0a 30 |13023.01010413.0|
00000160 30 41 30 30 35 31 33 0a 46 36 35 46 46 30 45 46 |0A00513.F65FF0EF|
00000170 0a 30 30 30 30 30 30 36 46 0a |.0000006F.|
0000017a
madrid@Madrid-desktop:~/riscv_test$
そして、fib.hexファイルをPSからメモリ(0番地)へ書き込みし、RISC-Vで実行できないか?と考えました。フローイメージは下記のとおりです。
test_riscv.cppコード(折りたたみ)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <time.h>
#include <stdlib.h>
#include <fcntl.h>
#include <dirent.h>
#include <unistd.h>
#include <fcntl.h>
#include <cstring>
#define REG(address) *(volatile unsigned int*)(address)
int pl_resetn_1(){
int fd;
char attr[32];
DIR *dir = opendir("/sys/class/gpio/gpio173");
if (!dir) {
fd = open("/sys/class/gpio/export", O_WRONLY);
if (fd < 0) {
perror("open(/sys/class/gpio/export)");
return -1;
}
strcpy(attr, "173");
write(fd, attr, strlen(attr));
close(fd);
dir = opendir("/sys/class/gpio/gpio173");
if (!dir) {
return -1;
}
}
closedir(dir);
fd = open("/sys/class/gpio/gpio173/direction", O_WRONLY);
if (fd < 0) {
perror("open(/sys/class/gpio/gpio173/direction)");
return -1;
}
strcpy(attr, "out");
write(fd, attr, strlen(attr));
close(fd);
fd = open("/sys/class/gpio/gpio173/value", O_WRONLY);
if (fd < 0) {
perror("open(/sys/class/gpio/gpio173/value)");
return -1;
}
sprintf(attr, "%d", 0);
write(fd, attr, strlen(attr));
sprintf(attr, "%d", 1);
write(fd, attr, strlen(attr));
close(fd);
return 0;
}
unsigned int float_as_uint(float f){
union {float f; unsigned int i; } union_a;
union_a.f = f;
return union_a.i;
}
float uint_as_float(unsigned int i){
union {float f; unsigned int i; } union_a;
union_a.i = i;
return union_a.f;
}
// This program is DMEM[0]+DMEM[1]=DMEM[2]
int main(){
// int uio0_fd = open("/dev/uio0", O_RDWR | O_SYNC);
// unsigned int* DMEM_BASE = (unsigned int*) mmap(NULL, 0x2000, PROT_READ|PROT_WRITE, MAP_SHARED, uio0_fd, 0);
// int uio1_fd = open("/dev/uio1", O_RDWR | O_SYNC);
// unsigned int* IMEM_BASE = (unsigned int*) mmap(NULL, 0x1000, PROT_READ|PROT_WRITE, MAP_SHARED, uio1_fd, 0);
// if (uio0_fd < 0 || uio1_fd < 0) {
// printf("Device Open Error");
// exit(-1);
// }
int test_fd = open("/dev/mem", O_RDWR | O_SYNC);
if (test_fd < 0)
perror("FD open error\n\r");
unsigned int* PROG_BASE = (unsigned int*) mmap(NULL, 4096UL, PROT_READ|PROT_WRITE, MAP_SHARED, test_fd, 0);
if(PROG_BASE == MAP_FAILED)
perror("mmap failed\n\r");
//set RISC-V Instruction
// IMEM_BASE[0] = 0xA0020437; // 0: lui s0,0xA0020000
// IMEM_BASE[1] = 0x00040413; // 4: mv s0,s0
// IMEM_BASE[2] = 0x00042607; // 8: flw fa2,0(s0) # 0xA0020000
// IMEM_BASE[3] = 0x00442687; // C: flw fa3,4(s0)
// IMEM_BASE[4] = 0x00c68753; // 10: fadd fa4,fa2,fa3
// IMEM_BASE[5] = 0x00e42427; // 14: fsw fa4,8(s0) # 0xA0020000
// IMEM_BASE[6] = 0x0000006f; // 18: j 0x18
//TEST start
srand(100);
int all_ok = 1;
unsigned long from = 0xa4000000;
// *(PROG_BASE) &= ~0x80;
// int fp = open("~/riscv_test/fib.hex", O_RDONLY);
int fp = open("/home/petalinux/test_riscv/fib.hex", O_RDONLY);
if (fp < 0)
perror("FP open error\n\r");
char *ptr = (char*)mmap(NULL, 0x180, PROT_READ, MAP_SHARED, fp, 0);
// for (int i=0; i<100; i++)
// printf("%x\n",*(ptr+i));
printf("ptr:%x\n", ptr);
printf("ptr:%x\n", *ptr);
printf("PROG_BASE:%x\n", PROG_BASE);
printf("PROG_BASE_before:%x\n", *PROG_BASE);
memcpy(PROG_BASE, ptr , 0x17a);
printf("PROG_BASE_after:%x\n", *PROG_BASE);
pl_resetn_1();
for(int i = 0; i < 100; i++){
// float a = (rand()%100)/100.0f;
// float b = (rand()%100)/100.0f;
// //set input data
// DMEM_BASE[0] = float_as_uint(a);
// DMEM_BASE[1] = float_as_uint(b);
//reset to launch RISC-V core
// pl_resetn_1();
//wait RISC-V execution completion by waiting some period or using polling
usleep(100);
//get output data
// unsigned int _c = DMEM_BASE[2];
// float c = uint_as_float(_c);
// printf("%f+%f=%f:", a, b, c);
// if (a + b == c){
// printf("OK\n");
// } else {
// printf("NG\n");
// all_ok = 0;
// }
}
// if (all_ok) printf("ALL PASSED\n");
return 0;
}
fib.cコード(折りたたみ)
#include <stdio.h>
#include <string.h>
int fib(int n) {
if(n <= 1) return 1;
return fib(n-1) + fib(n-2);
}
int main() {
// int *out;
// out = (int*) 0x500;
// *out = fib(10);
// printf("%p\n",*out);
// for(;;) {}
memset((void*)0x500, fib(10), 4);
return 0;
}
ベースはこちらのtest.cppを流用させていただきました。こちらでは、uio経由でBRAMをRISC-Vのキャッシュとして使用されているようでしたが、DRAMに/dev/memから無理やり0番地に書き込み、なんとか動かせないか?と試してみました。
RISC-Vのリセットは、下記のようにPSのpl_rstn0からproc_sys_reset_1経由で接続されていたので、pl_rstn0経由でリセット解除をするため、制御方法を調べたところsysfsからGPIO制御することで可能のようです。
KV260では、pl_rstn1はgpio172に接続されているので、pl_rstn0はgpio173を制御すればよいようです。
KV260でVexRiscv動作させた
AR# 68962: Zynq MPSoC PS pl_resetnx ポートの制御アドレスの取得方法
プログラム実行前に、下記コマンドで、gpio173用の仮想ファイルを作成しておきます。
$ echo 173 | sudo tee /sys/class/gpio/export
実行結果
xilinx-k26-starterkit-20221:~$ sudo devmem 0x500
Password:
0xFEFEFEFE
xilinx-k26-starterkit-20221:~$ sudo chmod 777 /dev/mem
xilinx-k26-starterkit-20221:~$ echo 173 | sudo tee /sys/class/gpio/export
173
xilinx-k26-starterkit-20221:~$ cd test_riscv/
xilinx-k26-starterkit-20221:~/test_riscv$ sudo xmutil loadapp aiedge
aiedge: loaded to slot 0
xilinx-k26-starterkit-20221:~/test_riscv$ sudo ./test_riscv
ptr:80056000
ptr:30
PROG_BASE:80057000
PROG_BASE_before:0
PROG_BASE_after:30433830
xilinx-k26-starterkit-20221:~/test_riscv$ sudo devmem 0x0
0x30433830
xilinx-k26-starterkit-20221:~/test_riscv$ sudo devmem 0x500
0xFEFEFEFE
xilinx-k26-starterkit-20221:~/test_riscv$
0x0を読みだすと、fib.hexファイルの先頭データと同じとなっていますので、fib.hexの0x0への書き込みはうまくいってそうですが、計算結果がうまく出力されていないようです、、、考えられる要因としては、以下がありそう。
- RISC-Vのリセットが正常に解除されていない
- RISC-Vのプログラムを0x0からロードできていない
- 何らかの要因でRISC-Vが正常に動作せず、計算が動作していない
- memsetで0x500に正常にライトできていない(そもそも物理アドレスにライトできていない気がする、、、)
原因解析をするために、RISC-VにIntegrated Logic Analyzer(ILA)を埋め込んでデバッグが必要かと考えましたが、このあたりでタイムアップでした、、、
まとめ
- DPUとRISC-Vを含むハードウェアリファレンス環境を構築し、Vitis/Vivadoでのハードウェアプラットフォーム構築方法を確認した。また、リファレンス環境上でMNISTを動かし、正常に動作することを確認。
- ホストPC上でPointPaintingのリファレンス環境を動作させ、PointPaintingやPointpillarsで3D物体検出がどのように行われているか学習した。
- KV260上で、Pointpillarsのサンプルプログラムを動作させ、DPU用のモデル変換や、Vitis AIでのPointpillarsの動かし方などを確認した。
- PSからRISC-Vのプログラムを書き込み、RISC-Vで計算を実施し、その結果をDRAMに書き戻すといったことをやりたかったが、うまく動作させるところまではいかず。
理想的には、
- DRAM経由でPSとRISC-V間のデータ送受信し、PSからRISC-Vのプログラムを書き込み、RISC-V起動。
- KV260のDPU上でPointPaintingの処理実装
- PointPaintingの処理アルゴリズムを把握した上で、一部処理をRISC-Vにオフロードし、並列処理
とかまで行けたらよかったのですが、スキル不足と時間不足でタイムアップです、、、
KV260ボードを提供までして頂いたあげく、最終提出まで至れないのは心苦しいですが、色々と取り組んで貴重な経験になりました。こういった機会を提供して頂いた経済産業省様に、この場を借りて、お礼を申し上げたいと思います。