Java 22が2024/3/19にリリースされました。
https://mail.openjdk.org/pipermail/jdk-dev/2024-March/008827.html
The Arrival of Java 22!
LTSではなく正式採用された機能も少ないですが、Gathererは出番も多そうなAPIなのでチェックしておきましょう。
また、非互換性として、Javaソースの直接実行でパッケージとディレクトリの対応が厳しくなっているので注意が必要です。
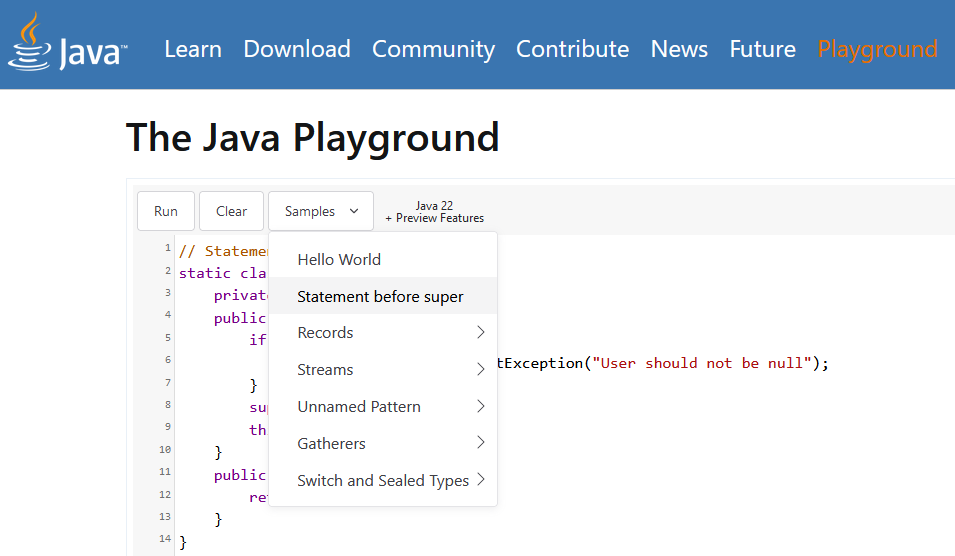
JDKをインストールせずに言語やライブラリの新機能を試したい場合にはJava Playgroundが便利です。
https://dev.java/playground/
Samplesに新機能のサンプルがあります。
資料
詳細はこちら
JDK 22 Release Notes
Java SE 22 Platform JSR 397
OpenJDK JDK 22 GA Release
APIドキュメントはこちら
Overview (Java SE 22 & JDK 22)
追加されたAPIまとめはこちら
https://docs.oracle.com/en/java/javase/22/docs/api/new-list.html
APIの差分はこちら。
https://cr.openjdk.org/~iris/se/22/build/latest/java-se--jdk-21-ga--jdk-22%2B36/
ディストリビューション
MacやLinuxでのインストールにはSDKMAN!をお勧めします
Oracle OpenJDK以外に無償で商用利用できるディストリビューションとしては、次のようなものがあります。
3/19時点でOracle JDKとSapMachineがリリースされて3/22日時点でLiberica JDKやAmazon Correttoもリリースされています。Adoptium TemurinとAzul Zuluも4/11時点でリリースされていました。Microsoft Buildは非LTSはお休みかな。Azul Zuluは非LTS(STS)はサポート購入者だけか
- Oracle JDK ※対外サーバーの運用には有償ライセンスが必要です
- Adoptium Temurin
- Liberica JDK
- Amazon Corretto 22
- SapMachine
- Azul Zulu
アップデートは4月に22.0.1が、7月に22.0.2がリリースされることになります。
JEP
大きめの変更はJEPでまとまっています。
https://openjdk.org/projects/jdk/22/
今回は12個のJEPが取り込まれました。すでにプレビューなどで出ていたものが7つあり、そのうち2つが正式化されました。新たに取り込まれたもの5つで、そのうち3つがPreviewです。
LTSではないですが、複数ファイルのソースコードのプログラムをjavacなしに動かせるよう標準でなっているのは便利そう。あとはStatements before superとStream Gatherersは要チェック。
(リンクを今まではJEPドキュメントに飛ぶようにしていましたが、Qiita内の各記事に飛ぶようにしています)
423: Region Pinning for G1
447: Statements before super(...) (Preview)
454: Foreign Function & Memory API
456: Unnamed Variables & Patterns
457: Class-File API (Preview)
458: Launch Multi-File Source-Code Programs
459: String Templates (Second Preview)
460: Vector API (Seventh Incubator)
461: Stream Gatherers (Preview)
462: Structured Concurrency (Second Preview)
463: Implicitly Declared Classes and Instance Main Methods (Second Preview)
464: Scoped Values (Second Preview)
ツール
ツールに関してはjavaコマンドで複数ソースファイルのプログラムが直接実行できるようになりました。
458: Launch Multi-File Source-Code Programs
458: Launch Multi-File Source-Code Programs
複数のJavaソースコードをjavaコマンドで直接実行できるようになりました。
Jarを読み込む
jarファイルを*を使って一括で読み込めます。
例えば、Jacksonを使うコードがあるとします。Mavenだとこんな感じのdependencyを指定しますね。
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.4</version>
</dependency>
mvn dependency:copy-dependenciesを実行するとtarget/dependencyにライブラリが集まります。
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Main {
public static void main(String[] args) throws JsonProcessingException {
ObjectMapper mapper = new ObjectMapper();
var node = mapper.readTree("""
{
"name": "hello",
"messages": ["hello", "json"]
}
""");
System.out.println(node);
}
}
*を使って一括でjarを指定できます。このとき、シングルクオートで囲む必要があります。
$ java --class-path 'target/dependency/*' json.java
{"name":"hello","messages":["hello","json"]}
Windowsのコマンドプロンプトの場合はダブルクオートで囲む必要があります。
>java --class-path "target/dependency/*" json.java
{"name":"hello","messages":["hello","json"]}
パッケージとディレクトリは対応する必要がある
Java 21までは、パッケージとディレクトリが対応していなくても許してくれていましたが、Java 22ではエラーになります。
C:\Users\naoki\java\jdk>more hello.java
package sample;
public class Main {
public static void main(String[] args) {
System.out.println("hello");
}
}
C:\Users\naoki\java\jdk>jdk-21\bin\java hello.java
hello
C:\Users\naoki\java\jdk>jdk-22\bin\java hello.java
エラー: ソース・ファイルへのパスの終わりがパッケージ名sampleと一致しません: hello.java
言語機能
言語機能の変更としては、_をラムダパラメータやパターンマッチングなどで使えるUnnamed Variables & Patternsが正式機能になっています。また、スーパークラスのコンストラクタ呼び出しの前にステートメントを書けるStatements before superがプレビューとして導入されました。
447: Statements before super(...) (Preview)
456: Unnamed Variables & Patterns
459: String Templates (Second Preview)
463: Implicitly Declared Classes and Instance Main Methods (Second Preview)
447: Statements before super(...) (Preview)
スーパークラスのコンストラクタ呼び出しの前にthisを使わないステートメントが書けるようになりました。
例えばListを2つコンストラクタにとるクラスがあるとします。
class Foo {
Foo(List l1, List l2) {
}
}
このコンストラクタを継承するとき、Listをふたつ渡す必要があります。
class Bar extends Foo {
Bar() {
super(List.of("abc", "def"), List.of("abc", "def"));
}
}
同じものを渡しているので共通化したいですが、superの前でステートメントを実行できないので迂回を考える必要があります。
class Bar extends Foo {
private Bar(List l) {
super(l, l);
}
Bar() {
this(List.of("abc", "def"));
}
}
これを、次のように書けるようになります。
class Bar extends Foo {
Bar() {
var param = List.of("abc", "def");
super(param, param);
}
このように、パラメータの検証や構築、共有がある場合に、自然なコードで書けるようになります。
次のようなフィールドのアクセスをsuperの前に行うとエラーになります。
class Bar extends Foo {
List<String> param;
Bar() {
param = List.of("abc", "def");
super(param, param);
}
}
test.java:11: エラー: スーパータイプのコンストラクタの呼出し前はparamを参照できません
param = List.of("abc", "def");
^
456: Unnamed Variables & Patterns
パターンマッチやラムダ引数、catch句など、構文的に変数を指定しないといけないけどその変数を使わないということがよくあります。
_を使うことで、値を使わないことを明示できます。
Java 21で「Unnamed Patterns and Variables」というタイトルでプレビューに入りましたが、名前が少し変わってそのまま正式化されました。
無名パターン変数
例えば上記のAddExprに対するパターンでleftしか使わない次のような場合を考えます。
case AddExpr(Expr left, Expr right) -> print(left);
このときrightは使っていません。そこで次のように_を使って不要な値であることを明示できます。
case AddExpr(Expr left, Expr _) -> print(left);
ここで、型にもこだわらないのであればvarが使えます。
case AddExpr(Expr left, var _) -> print(left);
そしてこの場合は、varを省略できます。
case AddExpr(Expr left, _) -> print(left);
仕様的には、これは「無名パターン」となっています。
無名変数
パターンマッチだけではなく変数でも_が使えます。
使えるのは次の6か所。
- ローカル変数
- try-with-resource
- for文
- 拡張for文
- catch句
- ラムダ式の引数
一番出番がありそうなところはcatch句になりそうです。例外を捕まえたいけど値は使わないということ多いですね。
try {
Thread.sleep(500);
} catch (InterruptedException _) {}
処理もなにもしないのに変数名をeにするかexにするか悩むのもばからしいですね。
ラムダ式でも引数を使わないことがよくあります。
var button = new JButton("押す");
button.addActionListener(_ -> System.out.println("押された"));
ただ、オーバーライドしたメソッドの引数を使わないということも多いですが、引数には使えないようです。
459: String Templates (Second Preview)
String Templatesは文字列に式の値を埋め込める機能で、文字列補間とかインターポレーションと呼ばれます。
Java 21でプレビューとして導入され、もうすこしフィードバックを受けるためそのままSecond Previewになりました。
テンプレートプロセッサ."テンプレート"の形式になります。テンプレートには"""で囲む複数行文字列も使えます。テンプレート内の式は\{~}で書きます。
テンプレートプロセッサには、STR、FMT、RAWが用意されています。STRは標準でimportされているのでそのまま使えます。
プレビュー機能なので、--enable-previewが必要です。javacでは--source 22も必要になります。ソースファイルを直接実行する場合にはjavaでも--source 22が必要です。
% jshell --enable-preview
| JShellへようこそ -- バージョン22
| 概要については、次を入力してください: /help intro
jshell> var a = 123
a ==> 123
jshell> var d = 3.14
d ==> 3.14
jshell> STR."a=\{a} d=\{d}"
$4 ==> "a=123 d=3.14"
変数だけではなく式も扱えます。
jshell> STR."Today is \{new Date()} now"
$1 ==> "Today is Wed Sep 20 05:34:20 JST 2023 now"
FMTはフォーマットに対応したテンプレートプロセッサです。
jshell> import static java.util.FormatProcessor.FMT
jshell> FMT."a=%05d\{a} d=%.3f\{d}"
$9 ==> "a=00123 d=3.140"
RAWでは文字列に変換する前のデータ構造がそのまま返ります。
jshell> StringTemplate.RAW."a=\{a} d=\{d}"
$11 ==> StringTemplate{ fragments = [ "a=", " d=", "" ], values = [123, 3.14] }
テンプレートプロセッサを自分で作ることもできます。StringTemplateが渡されるので適切に文字列などのオブジェクトを作る感じです。
jshell> var UPPER = StringTemplate.Processor.of(st -> {
...> var sb = new StringBuilder();
...> for (int i = 0; i < st.values().size(); ++i) {
...> sb.append(st.fragments().get(i));
...> sb.append(st.values().get(i).toString().toUpperCase());
...> }
...> sb.append(st.fragments().getLast());
...> return sb.toString();
...> })
UPPER ==> java.lang.StringTemplate$Processor$$Lambda/0x00000219c1078298@564718df
jshell> var s = "hello"
s ==> "hello"
jshell> var t = "world"
t ==> "world"
jshell> UPPER."message is \{s} and \{t}"
$15 ==> "message is HELLO and WORLD"
RAWがStringTemplateオブジェクトを返しているように、結果が文字列である必要はありません。
JEPの説明にあるQueryBuilderの例も面白いので見てみてください。
463: Implicitly Declared Classes and Instance Main Methods (Second Preview)
「Unnamed Classes and Instance Main Methods」が名前が変わってSecond Previewになりました。
パブリックスタティックヴォイドメインの呪文から解放されるやつです。
Javaがパブリックスタティックヴォイドメインの呪文から解放される - きしだのHatena
Javaでは単純なハローワールドを書くために次のようなコードが必要でした。
public class Hello {
public static void main(String[] args) {
System.out.println("Hello Java!");
}
}
これが次のように書けるようになります。
void main() {
System.out.println("Hello Java!");
}
プレビュー機能なので、--enable-previewが必要です。javacでは--source 22も必要になります。ソースを直接実行する場合はjavaコマンドでも--source 22が必要です。
>more Hello.java
void main() {
System.out.println("Hello Java!");
}
>java --enable-preview --source 22 Hello.java
ノート: Hello.javaはJava SE 22のプレビュー機能を使用します。
ノート: 詳細は、-Xlint:previewオプションを指定して再コンパイルしてください。
Hello Java!
publicやclass、staticなどのキーワードが消え、[]という謎の記号も消えました。
プログラムを勉強するときに、まずやりたいことは処理を書くことです。
クラスは書いた処理をうまく構成するための仕組みなので、処理が書けないうちに勉強してもあまり意味がありません。
publicなどアクセス指定はプログラムが大きくなったときに不適切な要素を使ってしまわないための仕組みなので、入門時のサンプルでは不要です。
staticを説明するにはクラスやインスタンスの理解が必要になりますが、処理が書ける前に勉強するには早すぎます。
配列も変数を知らないうちに勉強できるものでもなく、入門時のサンプルで引数argsを使うことはあまりありません。
その結果「よくわからないしきたり」のまま放置されがち、というか放置せざるを得ない状態で「System.out.pritlnというのは~」という説明をすることになりますが、クラス名とファイル名が違うので動かせなくてハマってそこまでたどりつけなかったりもします。
ということで、初期に学習するべきことに集中できるようにするために、次のように制約が緩和されました。
- クラスの定義が不要になる
- mainメソッドはインスタンスメソッドでよくなる
- mainメソッドの引数を省略できる
- mainメソッドがpublicじゃなくてもよくなる
「メソッドも不要でいいのでは?」となると思いますが、現状ではステートメントとメソッドを同レベルで書く仕組みがないため、新たにローカルメソッドのような仕組みが必要になり、「初期に学習するべきことに集中できるようにするため」としては影響範囲が大きいので残されています。
System.outも邪魔ではーという点は、「System.printlnメソッド定義してデフォルトでstatic importすればいいよね」ということを言ってるので、そのうち入ると思います。
このあたりは、次のデザインノートにまとめられています。
https://openjdk.org/projects/amber/design-notes/on-ramp
クラスの定義が不要
クラスを知らなくていいことの他に、クラス名を考えなくていいとかインデントが一段浅くなるとか、中カッコが一組だけになるので間違いが減るとか、いろいろ入門がやりやすくなります。
クラスを省略すると、new Object(){}で囲まれることになりました。
new Object() {
void main() {
System.out.println("Hello Java");
}
}.main();
mainメソッドはインスタンスメソッドでもよくなる
mainメソッドにstaticをつけなくてもよくなります。そして、mainメソッドにstaticをつけなくてもいいということは、そこから呼び出すメソッドなどにもstaticをつけなくていいということになるので、少し大きめのサンプルが書きやすくもなります。
public class Hello {
public void main(String[] args) {
foo();
}
void foo() {
System.out.println("Hello");
}
}
mainメソッドの引数を省略できる / mainメソッドがpublicじゃなくてもよくなる
書かなくてよさそうなものを書かずにすむのですっきりします。
mainメソッドをprivateにすることはできません。protectedは可能です。
「public static void main(String[] args)」を何も見ずに書けるようになったときにJavaに馴染んだ満足感があったので、それがなくなるのは寂しいですが、単なるノスタルジーなのでなくていいと思います。
API
APIの変更としては6つのJEPがありますが、JEPになっていない変更も少しあります。
454: Foreign Function & Memory API
457: Class-File API (Preview)
460: Vector API (Seventh Incubator)
461: Stream Gatherers (Preview)
462: Structured Concurrency (Second Preview)
464: Scoped Values (Second Preview)
小さいもの
JEPになっていないAPI変更で、動きがわかりやすいものを挙げます。
ListFormat
リストをいい感じに文字列にしてくれるAPI
日本語ロケールだと読点で区切られます。
jshell> import java.text.ListFormat
jshell> ListFormat.getInstance().format(List.of("One", "Two", "Three"))
$4 ==> "One、Two、Three"
USロケールを用意します。
jshell> var fUS = ListFormat.getInstance(Locale.US, ListFormat.Type.STANDARD, ListFormat.Style.FULL)
fUS ==> ListFormat [locale: "英語 (アメリカ合衆国)", start: "{0}, ... ree: "{0}, {1}, and {2}"]
そうすると、要素2つのときはandが入ります。
jshell> fUS.format(List.of("One", "Two"))
$6 ==> "One and Two"
要素が3つ以上のときは、最後以外はカンマ区切り、最後の要素の前にandが入ります。
jshell> fUS.format(List.of("One", "Two", "Three"))
$7 ==> "One, Two, and Three"
jshell> fUS.format(List.of("One", "Two", "Three", "Four"))
$8 ==> "One, Two, Three, and Four"
誰得?
まあ、UnicodeのLocal Data Markup Language(LDML)のサポートということらしいです。
https://www.unicode.org/reports/tr35/tr35-general.html#ListPatterns
InetAddress.ofLiteral
InetAddressやInet4Address、Inet6AddressにofLiteralというメソッドが入りました。
getByNameとの違いは、ofLiteralはIPアドレスの文字列表現を解決するだけでホスト名の解決を行わないことです。なのでUnknownHostExceptionが発生しない、つまりtry-catchなどが不要ということにもなります。
あと、getByNameはInetAddressのstaticメソッドなのでIPv4のアドレスやIPv6のアドレスでもInetAddressを返すのに対して、ofLiteralはそれぞれのクラスの型として返すところが違います。
jshell> Inet4Address.getByName("192.168.0.1")
$15 ==> /192.168.0.1
jshell> Inet4Address.ofLiteral("192.168.0.1")
$16 ==> /192.168.0.1
jshell> /v $15
| InetAddress $15 = /192.168.0.1
jshell> /v $16
| Inet4Address $16 = /192.168.0.1
jshell> $15.getClass()
$17 ==> class java.net.Inet4Address
Inet6AddressにIPv4アドレスを渡すなどするとIlligalArgumentExceptionが発生します。
jshell> Inet6Address.ofLiteral("192.168.0.1")
| 例外java.lang.IllegalArgumentException: Invalid IP address literal: 192.168.0.1
| at IPAddressUtil.invalidIpAddressLiteral (IPAddressUtil.java:169)
| at Inet6Address.ofLiteral (Inet6Address.java:534)
| at (#18:1)
Path.resolve
Pathから相対アドレスを取得するresolveに複数の引数が渡せるようになりました。
jshell> var doc = Path.of("/Document")
root ==> \Document
jshell> doc.resolve("Image", "sushi.jpg")
$21 ==> \Document\Image\sushi.jpg
jshell> doc.resolve("..", "Desktop")
$22 ==> \Document\..\Desktop
454: Foreign Function & Memory API
Java 14のForeign-Memory Access APIから始まったPanama ProjectのネイティブアクセスAPIがとうとう正式化されました。
Foreign Memory API
ヒープ外のメモリをアクセスする方法としては、ByteBufferを使う方法やUnsafeを使う方法、JNIを使う方法がありますが、それぞれ一長一短があります。
ByteBufferでdirect bufferを使う場合、intで扱える範囲の2GBまでに制限されたり、メモリの解放がGCに依存したりします。
Unsafeの場合は、性能もいいのですが、名前が示すとおり安全ではなく、解放済みのメモリにアクセスすればJVMがクラッシュします。
JNIを使うとCコードを書く必要があり、性能もよくないです。
ということで、ヒープ外のメモリを直接扱うAPIがJava 14でインキュベータモジュールとして導入され、9バージョン目にして正式化されました。
次のようなコードになります。
import java.lang.foreign.*;
try (Arena session = Arena.ofAuto()) {
MemorySegment seg = session.allocate(100)
for (int i = 0 ; i < 25 ; i++) {
seg.set(ValueLayout.JAVA_INT, i, i);
}
}
Foreign Function API
ネイティブライブラリの呼び出しを行います。
外部メモリのアクセスにはForeign Memory Access APIを使います。
Java 16でForeign Linkerとして1stインキュベータになり、7バージョン目にして正式化されました。
たとえばこんな感じのC関数があって。
size_t strlen(const char *s);
こんな感じでMethodHandleを取り出して。
Linker linker = Linker.nativeLinker();
SymbolLookup stdlib = linker.defaultLookup();
MethodHandle strlen = linker.downcallHandle(
stdlib.find("strlen").get(),
FunctionDescriptor.of(JAVA_LONG, ADDRESS)
);
こんな感じで呼び出すようです。
try (Arena arena = Arena.ofConfined()) {
MemorySegment cString = arena.allocateFrom("Hello");
long len = (long)strlen.invoke(cString); // 5
}
457: Class-File API (Preview)
Javaクラスファイルを解析、変更、生成するためのAPIです。まずはプレビューとして提供されます。
ASMやJavassistなど、同様の機能を実装するライブラリがありますが、Javaではjavacという標準のクラスファイル生成ツールがあります。また、内部的にASMを使っている部分もあります。
ただ、ASMのように外部ライブラリを使うと、こういった外部ライブラリの新機能対応は新バージョンがリリースされるまで正式化しません。そうすると、Javaの新機能をJava内部で使いたいとき、そのASMは非公式であるかひとつ前のバージョン対応であるかということになってしまいます。
そこで、Java標準としてクラスファイル操作のAPIを提供するということになりました。
460: Vector API (Seventh Incubator)
AVX命令のような、複数のデータに対する計算を同時に行う命令をJavaから利用できるようになります。
使うためには実行時やコンパイル時に--add-modules jdk.incubator.vectorをつける必要があります。
Java 16でインキュベータとして導入されたPanamaプロジェクトの残る片割れですが、まだ正式化されず7th Incubatorになりました。Project Valhallaのvalue classを使いたいようで、関連JEPがpreviewになるまではIncubatorのままということです。
MemorySegmentにはバイト配列に対してVectorアクセスができていましたが、プリミティブ配列にVectorアクセスできるようになったようです。
基本的な使い方は次のようになります。
import jdk.incubator.vector.*;
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_256;
void vectorComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i += SPECIES.length()) { // SPECIES.length() = 256bit / 32bit -> 8
VectorMask<Float> m = SPECIES.indexInRange(i, a.length); // 端数がマスクされる
// a.lengthが11でiが8のとき最初の3つしか要素がないので [TTT.....]
// FloatVector va, vb, vc;
FloatVector va = FloatVector.fromArray(SPECIES, a, i, m);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i, m);
FloatVector vc = va.mul(va).
add(vb.mul(vb)).
neg();
vc.intoArray(c, i, m);
}
}
利用できるのは次の6つの型です。それぞれに対応するVector型があって、これが基本になります。
| 型 | bit幅 | Vector |
|---|---|---|
| byte | 8 | ByteVector |
| short | 16 | ShortVector |
| int | 32 | IntVector |
| long | 64 | LongVector |
| float | 32 | FloatVector |
| double | 64 | DoubleVector |
ただ、利用するにはVectorSpeciesが必要です。利用したいVectorにSPECIES_*という定数が用意されているので、それを使います。*は一度に計算するbit数ですね。
jshell> FloatVector.SP
SPECIES_128 SPECIES_256 SPECIES_512
SPECIES_64 SPECIES_MAX SPECIES_PREFERRED
MAXではそのハードウェアで使える最大、PREFERREDは推奨ビット数だけど、同じになるんじゃないのかな。ここでは256bitが推奨されて、floatが8個同時に計算できるようになっていますね。
jshell> FloatVector.SPECIES_PREFERRED
$11 ==> Species[float, 8, S_256_BIT]
ハードウェアで使えるbit数は搭載CPUに依存しますが、普通のIntel/AMDであれば256、XEONとか つよつよCPUなら512かな。M1は128でした。ハードウェアでサポートされないbit数を使おうとするとソフトウェア処理になるので遅くなります。
実際のVectorはfrom*というメソッドで取得します。fromArray、fromByteArray、fromByteBufferが用意されています。インキュベータに入る前はfromValuesがあったのですが、なくなってますね。
Vectorを得られたら、用意されたメソッドで計算します。ひととおりの算術命令はあります。
jshell> va.
abs() add( addIndex(
bitSize() blend( broadcast(
byteSize() castShape( check(
compare( compress( convert(
convertShape( div( elementSize()
elementType() eq( equals(
expand( fma( getClass()
hashCode() intoArray( intoMemorySegment(
lane( lanewise( length()
lt( maskAll( max(
min( mul( neg()
notify() notifyAll() pow(
rearrange( reduceLanes( reduceLanesToLong(
reinterpretAsBytes() reinterpretAsDoubles() reinterpretAsFloats()
reinterpretAsInts() reinterpretAsLongs() reinterpretAsShorts()
reinterpretShape( selectFrom( shape()
slice( species() sqrt()
sub( test( toArray()
toDoubleArray() toIntArray() toLongArray()
toShuffle() toString() unslice(
viewAsFloatingLanes() viewAsIntegralLanes() wait(
withLane(
ところで、こういったメソッド呼び出しの内部でAVX命令などを呼び出すのでは遅くなるんではという気がしますが、実際にはJVM intrinsicsという仕組みでJITコンパイラがこれらのメソッド呼び出しをネイティブ関数呼び出しに置き換えます。
461: Stream Gatherers (Preview)
Streamでは、前の値を参照するような処理や、処理順序を前提とした処理が行えません。そのため、前の値にどんどん手を加えてリストを作ったり、移動平均をとったりといったことができませんでした。
そういった、順番を保証して前の値を踏まえた処理が行えるようにするのが、Gathererです。
デザインノートはこちら
https://cr.openjdk.org/~vklang/Gatherers.html
Collectorと同じで自前のGathererを実装するのは大変そうですが、CollectorsのようにGatherersが用意されています。ここでは、Gatherersだけ紹介します。
Streamが使えそうで使えなかった処理に、Streamが使える場合が増えそうです。
JShellを使っていますが、見やすいように改行しているので、そのとおりに入力はできません。試すときは改行せず一行で入力してください。
windowFixed
要素を指定した個数分まとめてListにします。
jshell> IntStream.range(0, 10).boxed()
.gather(Gatherers.windowFixed(3))
.toList()
$1 ==> [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
windowSliding
スライディングウィンドウです。指定した要素分を、要素をずらしながらとっていってListをつくります。
jshell> IntStream.range(0, 10).boxed()
.gather(Gatherers.windowSliding(3))
.toList()
$2 ==> [[0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5],
[4, 5, 6], [5, 6, 7], [6, 7, 8], [7, 8, 9]]
mapConcurrent
指定した個数分、並列に処理を行いながらmapします。このとき並列処理にはVirtualThreadが使われます。
jshell> IntStream.range(0, 10).boxed()
.gather(Gatherers.mapConcurrent(4, n -> n * 2))
.toList()
$3 ==> [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
処理結果としてはmapと同じになります。
jshell> IntStream.range(0, 10).boxed()
.map(n -> n * 2)
.toList()
$4 ==> [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
scan
計算を追加していきます。
jshell> IntStream.range(0, 10).boxed()
.gather(Gatherers.scan(() -> "*", (s, n) -> s + n))
.toList()
$7 ==> [*0, *01, *012, *0123, *01234, *012345,
*0123456, *01234567, *012345678, *0123456789]
fold
処理順を前提としたreduce処理です。
jshell> IntStream.range(0, 10).boxed()
.gather(Gatherers.fold(() -> "*", (s, n) -> s + n))
.toList()
$8 ==> [*0123456789]
reduceではBinaryOperatorをとるので、要素と結果の型が同じになる必要があります。foldはBiFunctionをとるので、値と結果の型が同じである必要はありません。
jshell> IntStream.range(0, 10).boxed().reduce(0, (a, b) -> a + b)
$9 ==> 45
Collectors.reducingと違うのは、parallel streamでも処理順が保証されることです。
jshell> IntStream.range(0, 10).parallel().boxed()
.collect(Collectors.reducing(
"*", n -> "" + n, (s, t) -> s + t))
$12 ==> "*0*1*2*3*4*5*6*7*8*9"
あと、終端処理が必要になりますね。
jshell> IntStream.range(0, 10).parallel().boxed().gather(Gatherers.fold(() -> "*", (s, n) -> s + n)).findAny().get()
$14 ==> "*0123456789"
462: Structured Concurrency (Second Preview)
Java 19でIncubatorとして含まれていましたが、Java 21から変更なく2nd Previewになりました。
並列処理では、複数の処理を実行するときに、両方が終われば正常終了とか、どちらか片方が終われば終了だとか、どちらか一方でも例外が発生したら終了だとか、同時に行う処理で連動することがあります。
しかし、これを既存のjoinやwaitなどで制御しようとすると、実際にはjoinからwaitへのGo Toを書くようなコードになって、処理が追えなくなります。
そこで導入されるのが構造化並列性といいます。
こんな感じ。詳しくはあとで書きます!(Java 19のときから言ってる・・・)
Response handle() throws ExecutionException, InterruptedException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Subtask<String> user = scope.fork(() -> findUser());
Subtask<Integer> order = scope.fork(() -> fetchOrder());
scope.join() // Join both forks
.throwIfFailed(); // ... and propagate errors
// Here, both forks have succeeded, so compose their results
return new Response(user.get(), order.get());
}
}
SubtaskはSupplierを継承しているので、Supplierとして扱うほうがいいかもしれません。
464: Scoped Values (Second Preview)
2nd Previewになりました。機能的な違いは無いようです。
同じスレッド内で値を共有したいときThreadLocalを使いますが、値の変更が可能であったり子スレッドに値が引き継がれたり少し重いので、より限定された仕組みを提供する、ということのようです。
つまり、値を引数でひっぱりまわすのは面倒なのでグローバル変数的にstaticフィールドを使いたい程度のモチベーションで値を共有化するときに、スレッドセーフのためのThreadLocalは重すぎる、という感じですね。
たとえば次のような処理があります。
void start() {
proc1("test");
}
void proc1(String str) {
System.out.println(str);
proc2(str);
}
void proc2(String str) {
System.out.println(str);
}
これを、全部のメソッドにいちいち引数を設定して値をひきまわるのは面倒なのでフィールドを使おう、という場合。
String str;
void start() {
str = "test";
proc1();
}
void proc1() {
System.out.println(str);
proc2();
}
void proc2() {
System.out.println(str);
}
これは複数スレッドから呼び出されると正しく動かないことがあります。
スレッドセーフにするためにThreadLocalを使っていました。
final ThreadLocal<String> VAR = new ThreadLocal<>();
void start() {
VAR.set("test");
proc1();
}
void proc1() {
System.out.println(VAR.get());
proc2();
}
void proc2() {
System.out.println(VAR.get());
}
しかし、引数を書いて値を持ちまわっていくのめんどいね、くらいのモチベーションで使うにはThreadLocalは重過ぎるので、軽量な値共有手段としてScopedValueが導入されます。
final ScopedValue<String> VAR = new ScopedValue<>();
void start() {
ScopedValue.where(VAR, "test")
.run(() -> proc1());
}
void proc1() {
System.out.println(VAR.get());
proc2();
}
void proc2() {
System.out.println(VAR.get());
}
JVM
JVMの変更として1つJEPが導入されています。
423: Region Pinning for G1
JNIでJava配列などをネイティブに渡すとき、ネイティブ側で直接その配列を扱いたければメモリ上のアドレスを得る必要があります。そのとき、その処理中にGCが走ってオブジェクトが動いてアドレスが変わったり、オブジェクトが回収されたりすると困りますね。
じゃあどうするかというと、G1GCではGCを止めちゃっていたのですが、そうするとネイティブでの処理が終わったときにGCが行われることになります。けれども、ほかのスレッドがまだネイティブ側でなんらかのオブジェクトのアドレスを使っているとなると、そのスレッドが終わるまで待つことになります。運が悪いと結構待つことになってしまいます。
G1GCでは、メモリを領域(Region)に区切って扱います。そこで、ネイティブ側でオブジェクトのアドレスを使うとき、そのオブジェクトが配置されている領域にピンをつけてそこだけGCから外せば、他の領域はGCが行えます。
JDK
サポートプラットフォームなどJDKの変更はありません。