はじめに
これは色んなデータストア触ってみる Advent Calendar 2019の11日目の記事となります。
正直、データストアを触ったという感じの記事にはなっていませんが、宜しくご査収ください。
Apache Tinkerpopとは
Apache TinkerPopはグラフ計算のためのフレームワークです。
個々のグラフデータベースの上位の抽象レイヤーとして設計されており、これ一つで、世にある様々なグラフデータベースに対する操作を可能にすることを目標に開発されているようです。
すでにNeo4j、JanusGraph、Amazon NeptuneやAzure Cosmos DBをはじめとする様々なクラウドベースのDBやオープンソースのDBに対応しています。(その他は上記ページを参照のこと)
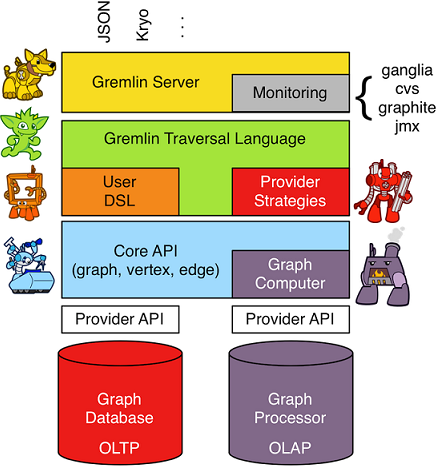
フレームワーク自体は下記の画像のようになっていて、大まかに
- JavaベースのCore API
- グラフトラバーサル言語のGremlin
- クライアントとクエリやデータをやり取りするGremlin Server
から構成されています。
グラフトラバーサル言語・Gremlin
Gremlinは、グラフというデータ構造を操作するのに特化した言語で、リレーショナルデータベースにとってのSQLみたいなものです。
Gremlinのウリは、クエリをシンプルに書けることです。RDBでもグラフを表現することは可能ですが、それに対するクエリをSQLで書くとなるとJOINの数が増えて、複雑なクエリになってしまいます。一方で、GremlinならJOINなしにメソッドチェーンで簡潔にトラバーサルを書くことができ、読む人にはやさしいです。
下記は、単にJOINつきのSQLでのクエリをGremlinで書いたらどうなるかという比較です。
(こういう比較は、データモデルが違うのでフェアでない気がする)
SELECT Products.ProductName
FROM Products
INNER JOIN Categories
ON Categories.CategoryID = Products.CategoryID
WHERE Categories.CategoryName = 'Beverages'
g.V().has("name","Beverages").in("inCategory").values("name")
各言語向けのGremlinライブラリ
Gremlinには、Python、Javascriptなどで本家Gremlinのようにトラバーサルが書けるライブラリが公式で用意されています。
http://tinkerpop.apache.org/docs/current/reference/#gremlin-python
http://tinkerpop.apache.org/docs/current/reference/#gremlin-javascript
http://tinkerpop.apache.org/docs/current/reference/#gremlin-dotnet
基本的に、各プログラミング言語向けのライブラリ(Gremlin-PythonやGremlin-Javascript)は、各言語で書かれたトラバーサルからバイトコードを生成し、それをJVMに送るということをやっているようです。
Amazon Neptuneとの関連で
Amazon Neptuneでは、クエリを書くのにGremlinとSPARQLの二つの言語が使えるのですが、おそらくGremlinを使うことになるのだと思います。見た感じSPARQLは名前だけではなく、コードもSQL風味でいっぱいです。
SELECT DISTINCT ?name
WHERE {
?person v:label "person" .
?person v:age ?age .
?person e:created ?project .
?project v:name ?name .
?project v:lang ?lang .
FILTER (?age > 30 && ?lang == "java")
}
そもそも、Gremlinがプロパティグラフモデル(ノード/エッジ/プロパティ)に基づいている一方で、
SPARQLはトリプルストアモデル(主語/述語/目的語)に基づいているので、概念的にGremlinの方がよりグラフ理論に近いというのもあるでしょう。
おわりに
うすい説明に終始してしまった感があるので、
- グラフアルゴリズム用のAPI
- OLAP用のエンジンとOLTP用のエンジンの違い
- トラバーサル戦略
についても加筆したいと思います。