はじめに
本記事では、量子コンピュータのブレイクスルーとされているGoogleの量子誤り訂正の論文を、アマチュアが一般向けに解説します。
この論文は最先端のエンジニアリングの結集な上、量子誤り訂正符号の理論自体が難しいので、理解が追い付かない部分もありますが、ご容赦ください。
まず彼らの2023年の論文をレビューし、その改善版である2024年の論文を解説します。
論文はオープンアクセスなので、誰でも読めます。
量子誤り訂正 とは
古典誤り訂正
一般に、古典(非量子)のコンピュータや、通信、メモリ/ストレージにおいて、自然に生ずる雑音による情報の誤りは不可避です。
これは保持すべき情報の量が増えるほど、課題となります。
例えば誤りの発生確率がわずか$10^{-9}$であったとしても、$10^{9}$ bitsの情報を誤りなく保持することはほぼ確実に不可能であることになります。
現実には、例えば通信においては、誤りの発生確率は$10^{-2,3,4}$が典型的であり、このような誤り率のシステムで情報が誤りなくやりとりできている(ようにみえる)ことは凄いことです。
これを可能にしているのが誤り訂正符号という技術です。
誤り訂正符号として最も簡単なものは、反復符号です。
これは同じ情報を何度もコピーして冗長化する、例えば$0$を$000000$にする符号です。
誤りが起きると、例えば$000001$となります。
訂正したいときは、$0$が多数派なのか$1$が多数派なのかを調べて、多数派に統一します。
$000001 \to 000000$となりますし、$000011 \to 000000$となります。これで元のbitである$0$が推定できます。
ただし誤りが多いとき、$001111 \to 111111$となるので、これは$1$として解釈されてしまいます。
つまり半分以上のbitが誤ると、訂正不能となります。
少し一般化すると、
$000000$と$111111$は、bit反転を6回行うと移りあいます。
このような符号化を符号間距離$d=6$の符号化であるといいます。
誤り訂正が機能するのは、符号間距離$d$の半分未満の誤りまでです。
明らかに、符号のbit桁数を増やす、つまり$d$を増やすと誤り訂正能力が上がりますが、必要なbitが増えていきます。
このような反復符号は扱いが簡単ではありますが、明らかに冗長度に対して訂正能力が弱い(必要なビット数のわりに情報が収容できない)愚直な方法ですので、実用上はもっと賢い符号化を使います。
例えばQRコードも誤り訂正符号が入っていますが、リードソロモン符号という高度な符号が使われています。
誤り訂正符号の良さは、いろいろな尺度がありますが、そのひとつは、符号間距離$d$に対して誤り訂正が機能するぎりぎりの誤り率$p_{th}$が高くとれることです。
つまり、高い"生の"誤り率があっても、誤り訂正で打ち消せるのが、良い符号だということです。
これは誤り訂正閾値などと呼ばれます。
符号は、その符号の元来持つ誤り訂正閾値を下回りさえすれば、符号間距離$d$を増やすことで、指数的に誤り率が下がることが知られています。
逆に、閾値を下回らない場合、"訂正"するほど誤りを増幅してしまいます。
量子誤り訂正
古典の場合と同様に、量子コンピュータでも、その内部で起きる誤りは無視できません。
むしろ古典コンピュータほどデバイスが良くできていないので、誤りは非常に大きいです(今後も大きいと予想されます)。
現在の技術では、その誤り率はおおむね$10^{-2,3}$程度になっています。
量子コンピュータで有用なアプリケーションを動かすには、$10^{6,7}$級の量子ビット数と、$10^{9}$をはるかに超えるゲートが必要と考えられますので、この"生の"誤り率は到底許容されません。
そこで、量子誤り訂正が考案されました。
量子誤り訂正は古典誤り訂正を継承した方法ですが、本質的に異なる部分もあります。が、ここでは深追いしないこととします。
情報を冗長化して表現し、それから誤りを検出して訂正する という基本的な考えは同じです。
量子誤り訂正符号としては、愚直なものはやはり反復符号ですが、Googleらも使用している 表面符号 というのもが効率面で最有力とされています。
表面符号の誤り訂正閾値$p_{th} = 10^{-2}$ = 1 % であることが知られています。
これは先に述べた量子コンピュータの誤り率$10^{-2,3}$と近い値であることがわかります。
つまり表面符号は動いても不思議のない段階にあるということです。
2023年の論文: "Suppressing quantum errors by scaling a surface code logical qubit"
Google Quantum AI. Suppressing quantum errors by scaling a surface code logical qubit. Nature 614, 676–681 (2023). https://doi.org/10.1038/s41586-022-05434-1
この論文では、$d=3$と$d=5$の表面符号が実装され、$d=5$のほうがほんのわずかに誤り率が低いことが示されました。
まずはこの(結論にあたる)結果を味わいましょう。
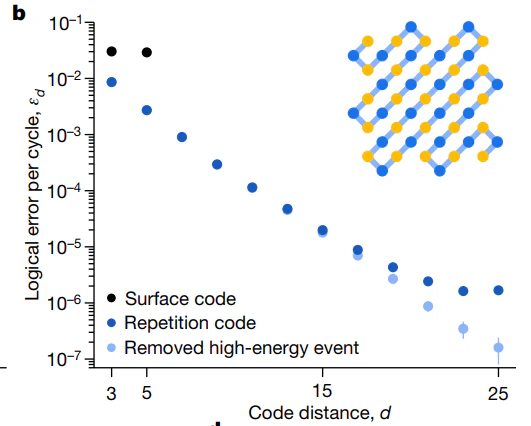
横軸は符号間距離$d$です。縦軸が誤り訂正後の誤り率です。黒マーカーが表面符号です。
$d=3$と$d=5$で、わずかに$d=5$のほうが低いです。視力検査ではありません!
**ほんの少し誤り率が下がっただけって、なんじゃそれ!**って思うかもしれませんが、、
$d=3$と$d=5$で、使用している量子ビット数が違うわけですから、雑音源の数も違うわけです。
普通に考えれば、$d=3$と$d=5$で、$d=5$のほうがめちゃくちゃ誤ってしかるべきなのです(何も訂正できていなければ)。
それなのに、同等ということ自体が、誤り訂正ができていることを示唆しているのです。
もちろん、$d=5$の誤り訂正のパワーは、実用には全然足りてないということですが。。
必要な量子ビット数は、以下の図からおよそわかります。
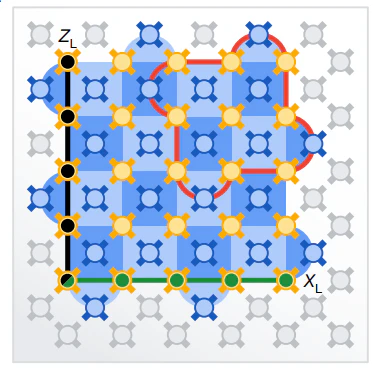
赤線内部の領域が$d=3$の表面符号に使う量子ビットで、全(青)領域が$d=5$の表面符号に使う量子ビットです。
だいたい4倍違いますね。
先の図に戻ります。この図の青色マーカーは、反復符号を示しています。
先に述べたように反復符号は情報の収容効率が悪いので実用性はなく、ベンチマークとして使われています。
反復符号の場合、単に量子ビット数を増やした分だけ$d$が増えるので、この例では$d=25$まで誤り訂正の$d$依存性を観測できています。
反復符号の訂正閾値は$p_{th}=0.5$なので、当然誤り訂正が動きます。
それに不思議はないわけですが、注意していただきたいのは、$10^{-6}$よりもエラーが落ちなくなっている現象です。
このようなエラーの下限を エラーフロア といいます。
ここに何かあるぞ ということです。
Googleは以下のように述べています。

cosmic ray、つまり宇宙線かもしれない ということですね。
この考察はずいぶん話題になりました。
最後に、「この表面符号はいったい何bitを収容できているのか」を伝えます。
たった1量子ビットです。
72量子ビットをも使って、たった1量子ビットです。
しかも、この実験において、量子ビットには何の計算(演算)もさせていません。
ただ、ほっといても自発的に生じてしまうエラーを訂正しただけです。
なかなか先は長そうですね。
これは2024年の論文でも同じなのですが、誤り訂正性能については大幅に改善がありました。
見てみましょう。
2024年の論文: "Quantum error correction below the surface code threshold"
Google Quantum AI. arXiv:2408.13687 [quant-ph], https://arxiv.org/abs/2408.13687
この論文では、生の誤り率をエンジニアリングで下げ、明確に誤り訂正閾値を下回らせた状況を作り出し、かつ符号間距離$d=5$を超えた$d=7$までを動かしたことが書かれています。
どんなグラフになるか、予想できますね?
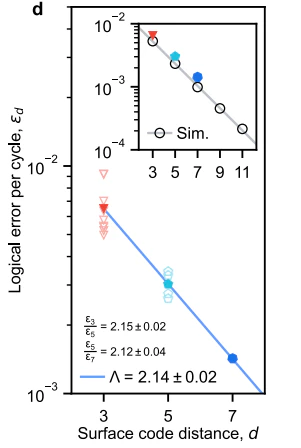
横軸は符号間距離$d$、縦軸は誤り訂正後の誤り率です。
2023年の論文と大きく異なり、$d=3,5$の段階で明確な誤り率低減がみられていますし、それは$d=7$までも続いています。
符号間距離$d$の増加に対する誤り率の低減効果、つまりこのグラフの傾き$\Lambda$は、以下のように誤り訂正閾値と関係しています。
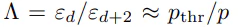
図から、$\Lambda = 2$程度であり、つまり生の誤り率は表面符号の誤り訂正閾値の半分まで下げられていたということが(結果として)確かめられます。
ちなみ、$d=3,5,7$に使われた量子ビット数とレイアウトは以下の図にあります。
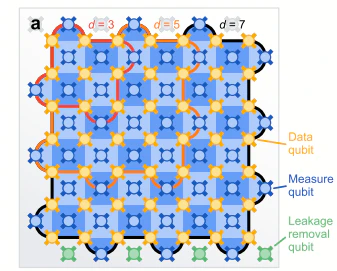
赤が$d=3$,オレンジが$d=5$,黒色が$d=7$です。
また、エラーフロアをみるためのベンチマークとしての反復符号も記載されています。
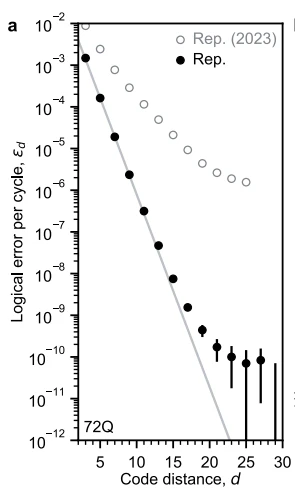
灰色(白抜き〇)は2023論文の結果です。黒(●)が今回の結果です。
あれ? $10^-{6}$に見えた cosmic ray かもしれない エラーフロアが消えており、さらに低い$10^{-10}$でフロアが見えていますね。
以下のように書かれています。

要はcosmic ray かもしれないようなエラーに対して、堅牢となるようデバイスを設計したよということです。
引用元
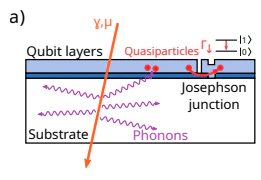
https://arxiv.org/abs/2402.15644
には宇宙線がデバイスを貫く絵が乗っていました。このような状況をなんとか耐えるようにした、ということのようです。
以下のStrongly Gap Engineering qubits (緑) というのが提案手法らしいです。
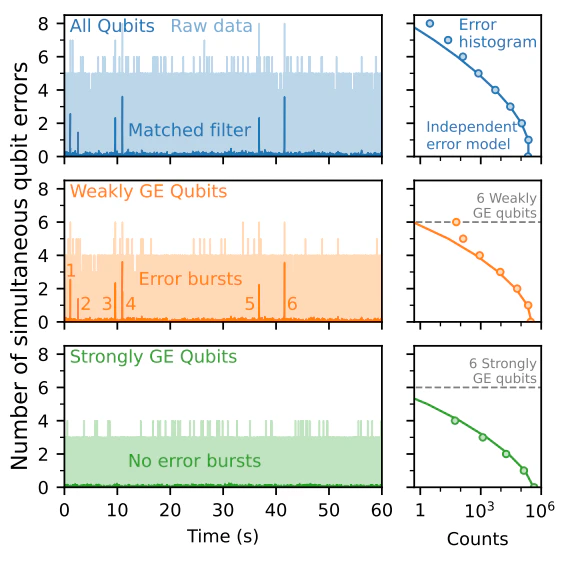
確かに No error bursts とあるので、よさそうですね。
このようなデバイス上の工夫をして、cosmic ray かもしれないようなバーストエラーを抑えたことで、次のエラーフロア(エラーの原因)が浮かび上がってきました。
$10^{-10}$のエラーどまりは、彼らも十分だとは考えていないようです。

原因もいくつか論文で示唆されていますし、今後の改善に大変期待したいです。
最後に、この論文で達成された誤り訂正ありなしを比較してみましょう。
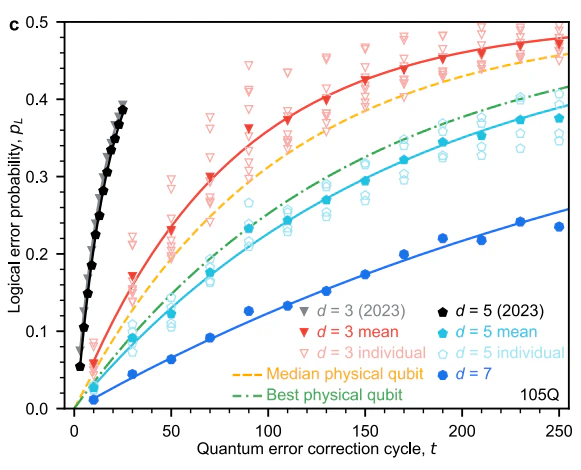
横軸は誤り訂正を何度も繰り返した際の繰り返し数です。縦軸は誤り訂正後の誤り率です。
本当は誤り訂正の繰り返し(訂正したものを再び訂正)をしても誤り率は変わらないであってほしいのですが、さすがにそういうレベルにはまだないようです。
オレンジと緑色が生の量子ビットの場合(誤り訂正なし)で、それ以外が誤り訂正ありの場合です。
$d=5$で誤り訂正ありとなしがおおむね同じになり、$d=7$では誤り訂正の効果が出ています。
繰り返し数に対してはおよそ2倍鈍感になっています。誤り訂正なしよりも、はっきりと良さが出ていますね。
このほか、論文ではリアルタイム復号の実験結果や、スケールアップに向けた課題など、多くの興味深い事項が書かれています。
ぜひ読んでみてください。
アマチュア量子勢の、Kumaでした。
参考