失敗から学ぶRDBの正しい歩き方を読み、データベースに対してインデックスをどの状況で付与するべきかを学んだのでアウトプットしたいと思います。
インデックスって何?
データベースにおけるインデックスは、データベースの検索性能を上げるために付与させる、索引だと考えてもらっても構いません。
インデックスを貼るメリット
具体的にインデックスを貼ることで、特定のレコードを取得したい際に、その場所させわかっていれば無駄なデータベースの検索を済まなくてよくなることができます。
インデックスを貼るデメリット
更新処理に関するパフォーマンスが低下します。
具体的に該当インデックスの付与されているカラムの更新処理を走らせた場合に、インデックスに対しても更新処理が行われるため、
レコード数 × インデックスの更新処理時間
の書き込み作業の余分な負荷が起きます。
また、インデックスのデータのために,ディスク領域を用意しておくことが必要です。
以上が、無闇にインデックスはつけてはいけな理由になります。
次に、いつ(When) インデックスを付与していけばいいかを説明していきます。
基礎的な概念とindexの必要性
PostgreSQLでは、B-tree、Hash、GiST、SP-GiST、GIN、BRINといった複数の種類のインデックスを使用可能です。
一般的に、PostgreSQLではデフォルトのB-treeが使用されます。
PostgreSQLにおけるB-treeにおいて
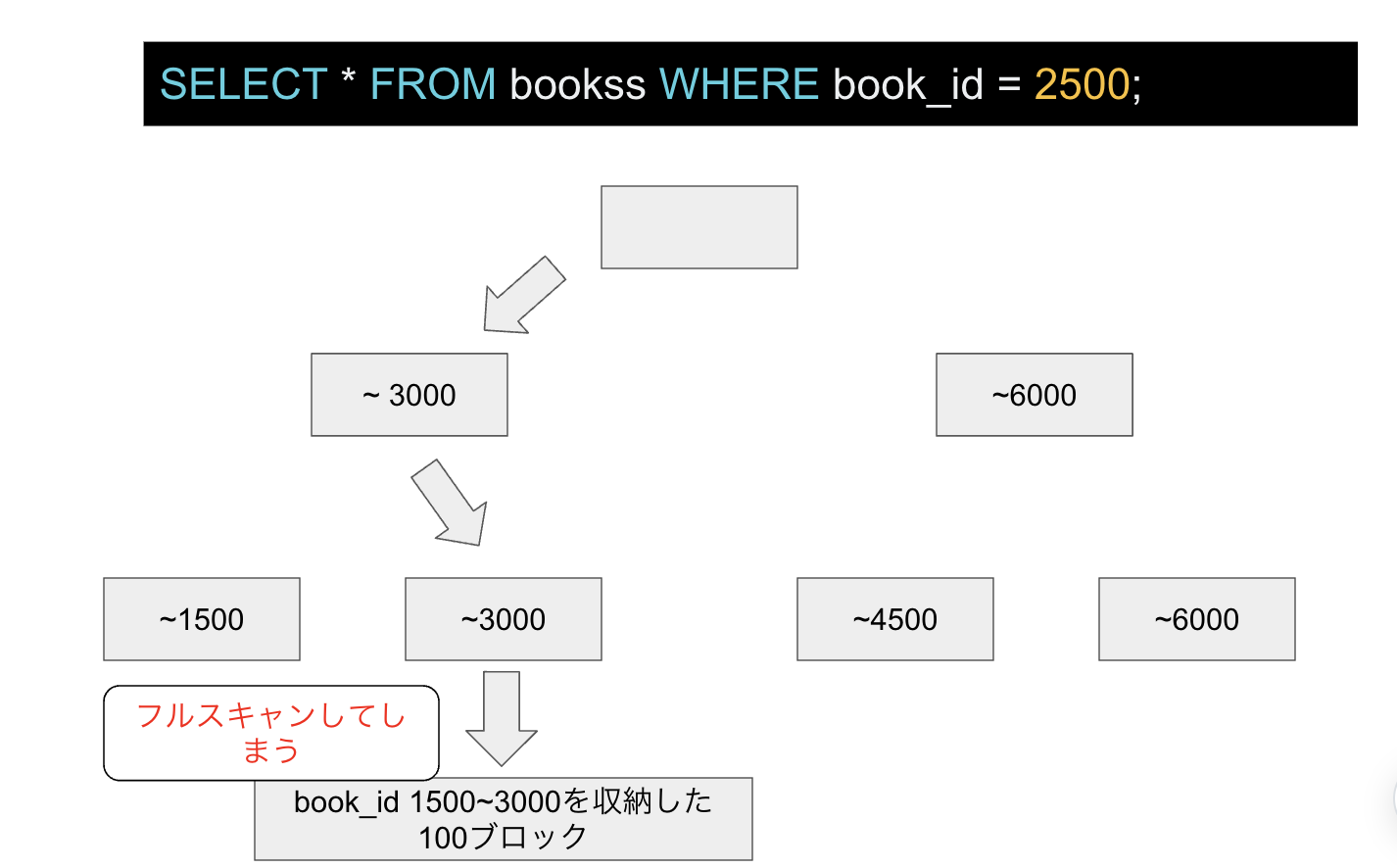
SELECT * FROM bookss WHERE book_id = 2500;
のSQL文が読み込まれた際に以下のようにして対象のデータが検索されます。
)
そして上記の図のようにbook_id=1500~3000のデータを100個のブロック(1ブロックに15のレコードが存在)に振られる他場合、この100ブロックをフルスキャンしないといけなくなり、検索効率が悪くなってしまいます。
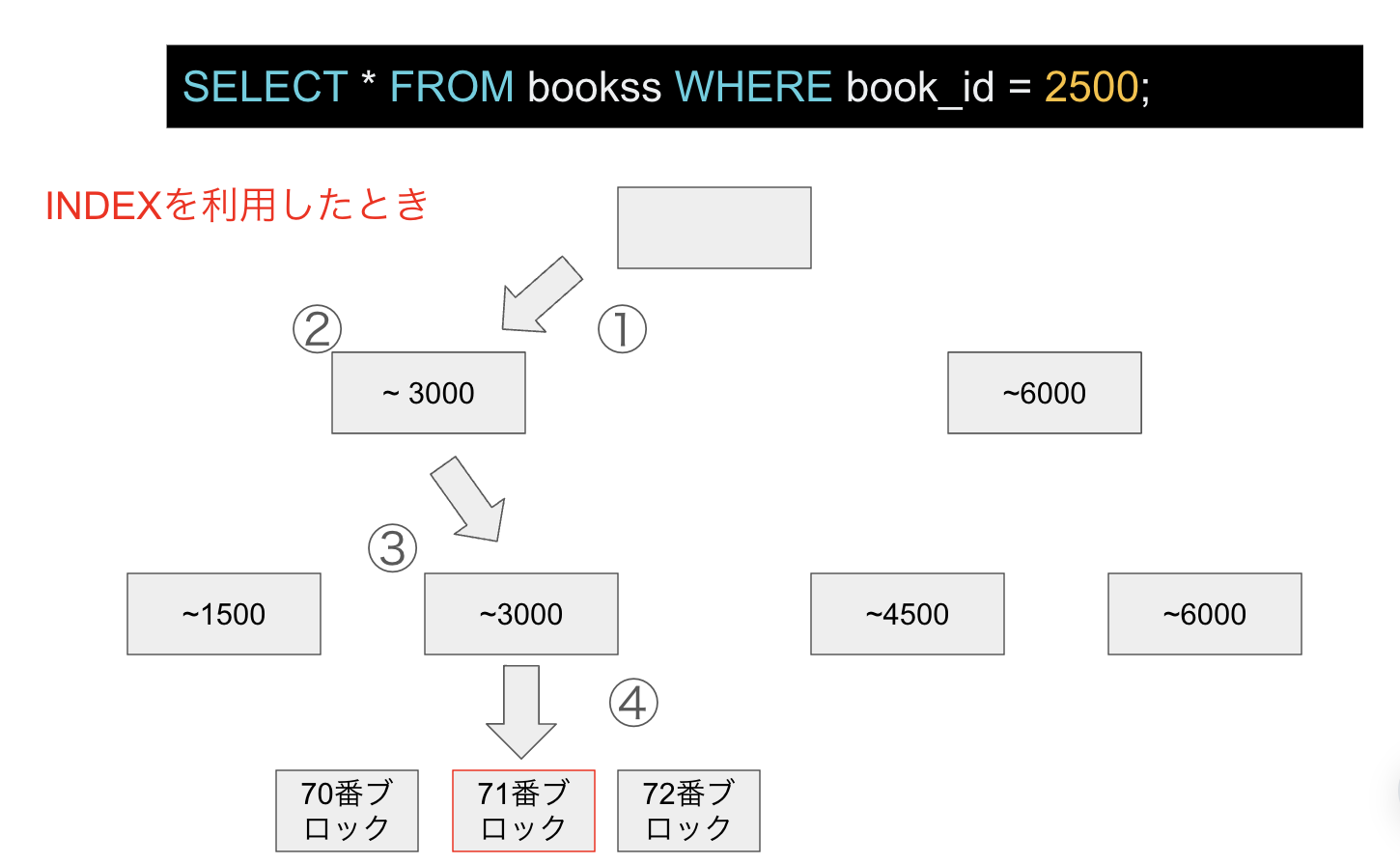
BTreeeでINDEXを利用したとき
INDEXを利用した際は100ブロックの中の必要な1ブロックを利用するために、4ブロックを取得すれば良くなるため、1枚目のINDEXがない時と比較して単純に計算して25倍以上検索効率が良くなります。
インデックスをどんなタイミングでつければいいか
以下の2つの条件を満たした時に、indexを貼るリターンが見込めます。
1.検索結果がテーブル全体の20%未満
インデックスは少数のレコードを取得する際に最も効果的になります。
テーブル全体の大部分を返すクエリには、インデックスにはあまり効果が見込めないです。
テーブル全体の20%未満かどうかを判断するときにカーディナリティを意識すると良いです。
カーディナリティとは
カーディナリティは列内のユニークな値の多さを指します。カーディナリティが高いということは、その列の各値が一意であることを意味します。逆に、カーディナリティが低いとは、列内で値の重複が多い状態を指します。
以下のような重複が少ないデータはカーディナリティが低いと言えます。
例えばgender列に1 = 男性, 2 = 女性のように2種類のデータしかない場合、カーディナリティは低いと言えます。この場合、データが均等に分布している(50:50)場合は、検索結果がテーブルの50%以上を占めるため、インデックスはあまり効果的ではありません。しかし不均等な分布(例: 男性99%, 女性1%)の場合、少数派のデータ(この場合は女性)を検索するときにインデックスは非常に効果的です。
2.検索対象のテーブルが多い場合
数万から数十万行が目安となってくるらしいです。
1000行程度のテーブルの場合はINDEXから参照するより、テーブルスキャンが効率的なケースが多いとのことです。
例えば、都道府県マスタのような47行しかないようなテーブルにはINDEXは使用しないほうがいいです。
結論
インデックスを付与するときに、付与する際の恩恵が受けられるかどうかを判断することが重要だと考えております。
リターンかコストを比較してインデックスをつけていくことが大事だと思いました。
引用