Scikit-learnの学習メモ
scikit-learnの命名規則
| 文字 | 意味 |
|---|---|
| X | データ |
| y | ラベル |
train_test_split関数
データ(X, y)をトレーニング用・評価用に分割する関数
分割を行う前に擬似乱数を用いてデータセットをシャッフルする。
データポイントはラベルでソートされているので、最後の25%をテストセットにすると,全てのデータポイントがラベル2(1つの値)になってしまうような事態を避けるため。
train_test_split関数でデータ分割
乱数のシード
jupyter_notebook.ipynb
train_test_split( 第一引数: 特徴行列X, 第二引数: 目的変数y, test_size(=0.3): テスト用のデータの大きさの割合, random_state= : データを分割する際の乱数のシード値)
random_state=0とすると、出力が決定的になり、常に同じ結果が得られるようになる。(勉強用)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
pandas.DataFrame
pandas.DataFrame
import pandas as pd
# リファレンス
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
# 例
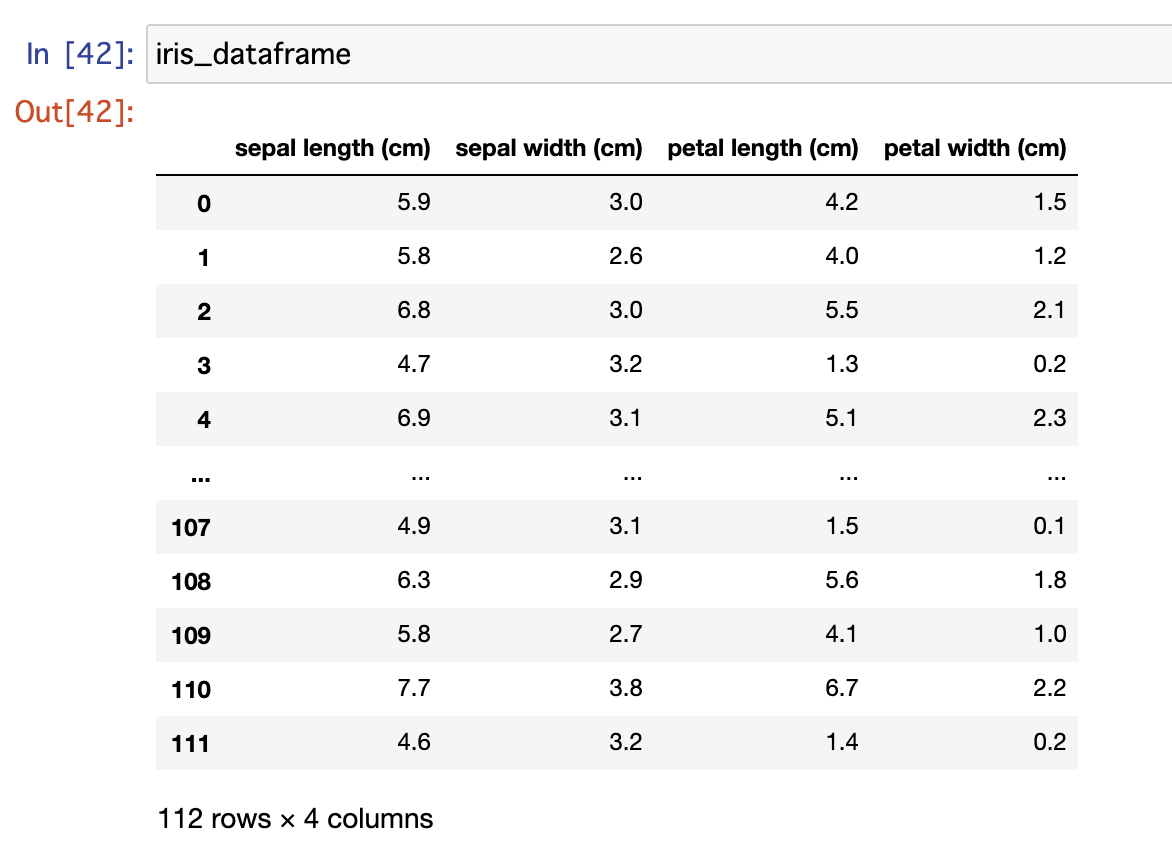
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
出力結果
pandas.plotting.scatter_matrix
pandas.plotting.scatter_matrix
pandas.plotting.scatter_matrix
# 公式リファレンス
pandas.plotting.scatter_matrix(frame, alpha=0.5, figsize=None, ax=None, grid=False, diagonal='hist', marker='.', density_kwds=None, hist_kwds=None, range_padding=0.05, **kwargs)
# iris例
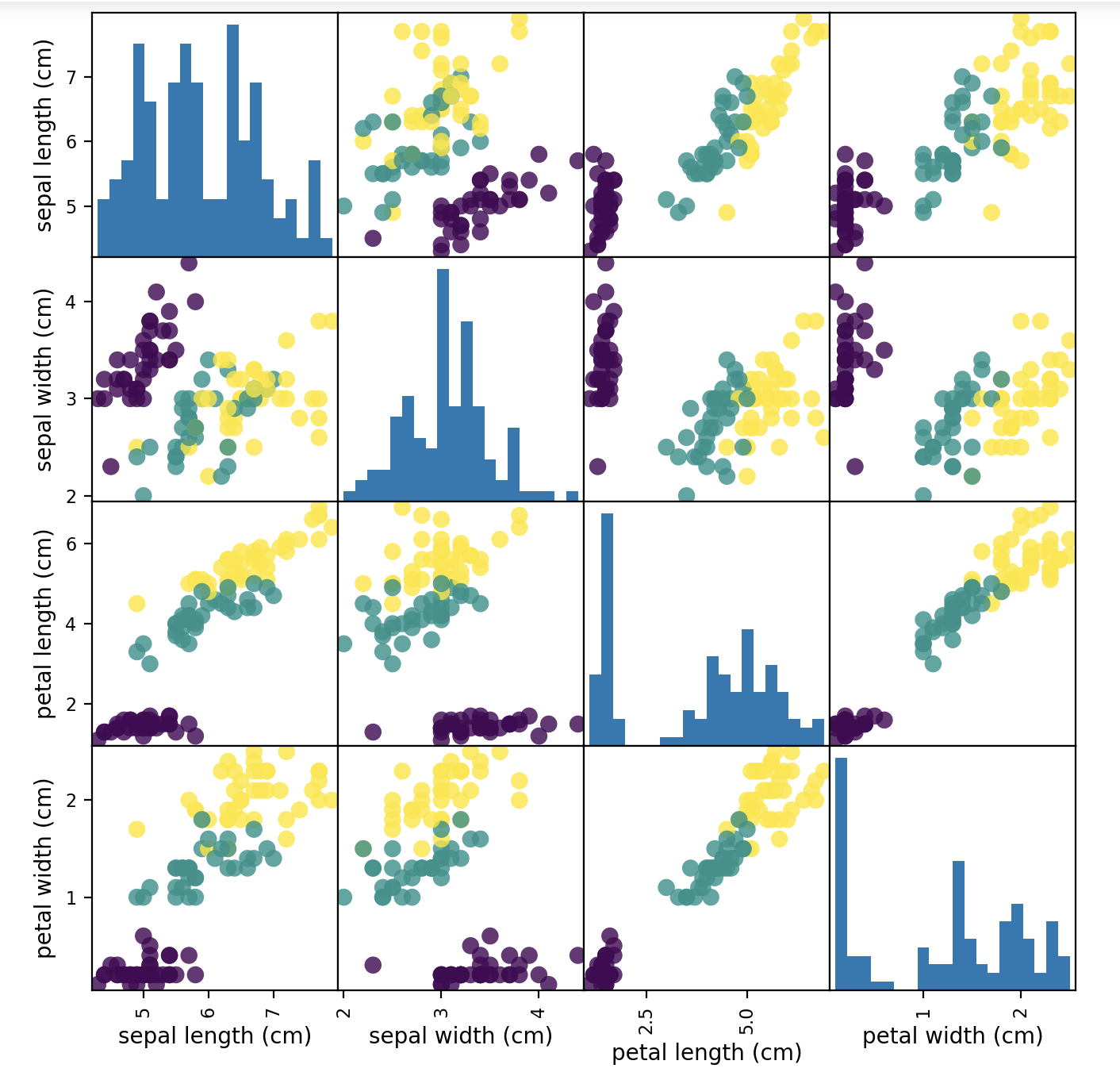
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(8, 8), marker='o',hist_kwds={'bins' : 20}, s=60, alpha=.8)
出力結果
scikit-learnは常に2次元配列
scikit-learn
X_new = np.array([[5, 2.9, 1, 0.2]])
sklearn.neighbors.KNeighborsClassifier
k-最近傍法によるクラス分類
sklearn.neighbors.KNeighborsClassifier
neighbors.KNeighborsClassifier
# 大切なメソッド
.fit(X, y)
# Xを学習データ、yを目標値としてモデルを適合させる
.predict(X)
# 提供されたデータのクラスラベルを予測します。
.score(X, y)
# 与えられたテストデータとラベルの平均精度を返します。