はじめに
都内でひっそり見習いエンジニアをしている@noshishiです。
addしてcommitするプログラムの作成を通じて、Gitを内部から理解しようという記事です。
記事が長くなったため、理解編と開発編の二つに分割して投稿します!
前書き
昨年末、Gitの記事を書いて、理解できたなら作れるのではと思いったったのがこの記事の出発点です。
これを機に新しいプログラミング言語にも触れてみて、いろいろ学べたらと思いRustで今回挑戦しました。
(この時は、新たなことを同時に取り組み絶望すること知る由もない著者でした。軽い気持ちで手を伸ばした自分をしばきたいです。。。)
実際に作成した(継続開発中ですが)リポジトリは、こちらです。
※一応ローカルでの一直線の開発はできそうな程度までは作成できました。コードのしょぼさはご容赦ください。
この記事だけでは説明しきれない部分があることをご容赦ください。
もちろん、間違い等あれば、ぜひコメントいただけると幸いです。
また、開発編ではRustを使用しますが、この理解編ではPythonを使用します!
Gitの内部を知る
最初にGitのデータの扱い方について、公式ドキュメントをもとに紐解いていきます。
Gitのコマンド体系は非常に複雑です。
一方で、Gitのデータの扱い方は非常にシンプルです!
リポジトリの実態
リポジトリは、Gitの管理下である大元のディレクトリのことを指しますが、initあるいはcloneで作成されたdirectoryの中にある.gitというフォルダがリポジトリの実態になります。
実際にprojectという空のフォルダをGitの管理下に置いてみましょう。
$ pwd
/home/noshishi/project
$ ls -a
# 何もありません
$ git init
Initialized empty Git repository in /home/noshishi/project/.git/
$ ls -a
.git
この.git配下は、以下のような構成になっています。
.git
├── HEAD
├── (index) // initの段階では作成されません!
├── config
*
├── objects/
└── refs/
├── heads/
└── tags/
Gitのリポジトリのパス種類は一見すると分かりにくいですよね。ディレクトリパスには/を付けていますので、参考に頂けばと思います。また、今回説明しない部分については省略しています。
(@tenmyoさん、ご提案ありがとうございます!)
オブジェクト
Gitにおけるバージョン管理は、オブジェクトと呼ばれるファイルデータで管理しています。
オブジェクトは、.git/objectsに格納されます。
種類
オブジェクトは4つの種類、blob、tree、commit、tagに分けれられます。
それぞれの中身と対応するデータは、以下のようなものになります。
-
blob... ファイルデータ -
tree... ディレクトリデータ -
commit... リポジトリのtreeを管理するメタデータ -
tag... 特定のcommitのメタデータ *今回は説明しません。
例えば、projectリポジトリの中にfirst.txtがある状態のイメージは以下の通りです。
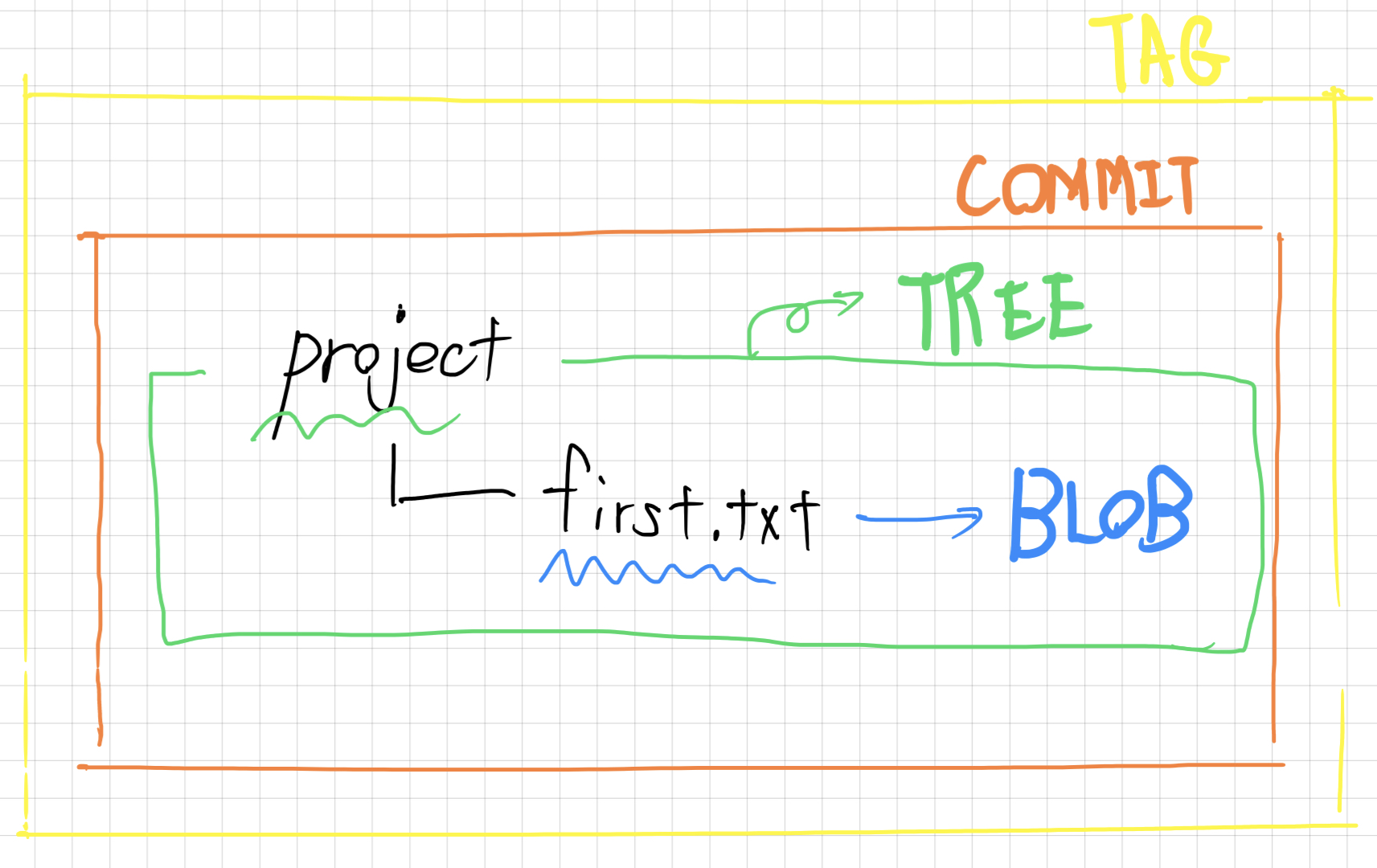
構造
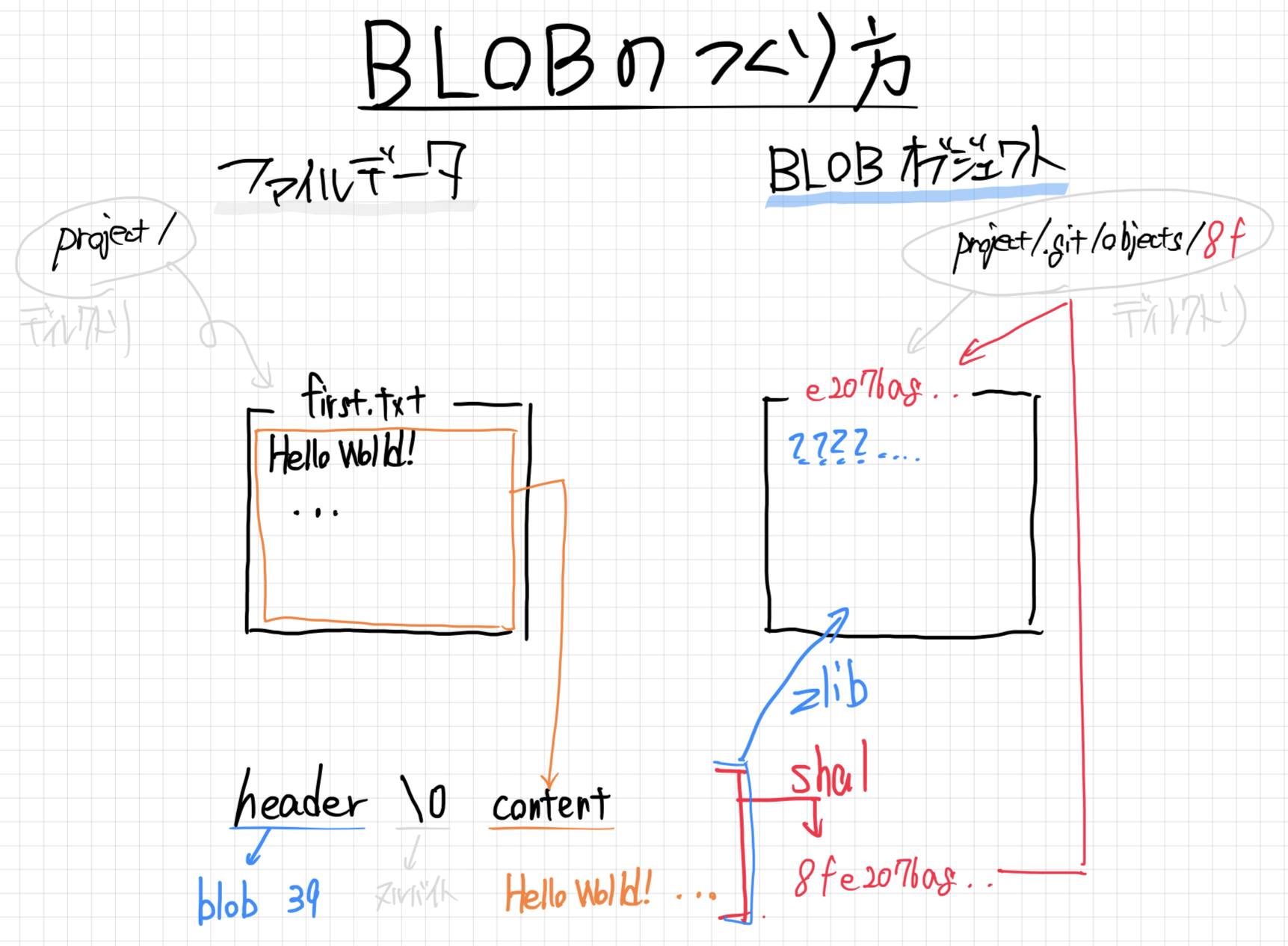
オブジェクトは、ファイルデータなので、普通のファイルと同様にファイル名(パス)とその中に保存されたデータがあります。
ファイル名(パス)
ファイル名は、オブジェクトに格納するデータをsha-11というハッシュ関数に通すことで得られる、40文字の文字列を使って決められます。
具体的には、この40文字のうち、前の2文字をディレクトリのパスにして、残り38文字をファイルのパスにしています。
データ
データは、zlib2によって圧縮されています。
伸張したデータは、headerとcontentの2つで構成されています。
そして、この2つ要素を\0(NULLバイト)で区切っています。
headerは、オブジェクトに応じた文字列と次に続くcontentのサイズを組み合わせです。
contentは、種類にある通り、対応データが扱いやすく整えられて入っています(詳しくは解体の章で説明します)。
(例)blobができる流れのイメージ。
インデックス(ステージングエリア)
addしたときに使用されるインデックスの実態は、.git/indexというファイルです。
構造
インデックスでは、addによってされたファイルをメタ情報と共に格納しています。
格納されているデータは、addされたタイミングの最新のファイルデータのメタ情報を格納しています。
重要なのは、インデックスに記録されるデータは全てファイルデータ単位です。
メタ情報は後ほど詳しく記述しますが、格納形式はindex-formatの通りきっちり定められています。
と言ってもイメージがつかないと思うので、実際にオブジェクトとインデックスを解体してみましょう!
オブジェクトを解体してみる
解体作業に入る前に、blob、tree、commitの全てを作成します。
と言っても、projectの中にファイルを追加して、コミットするだけです。
以下、二つのファイルを作成して、、、
Hello World!
This is first.txt.
def second():
print("This is second.py")
addしてcommitします。
git add -A
git commit -m 'initial'
そうすると、.git/objectsの中身は以下の通りとなりました。
.git/
└── objects/
├── 48/
| └── c972ae2bb5652ada48573daf6d27c74db5a13f
├── af/
| └── 22102d62f1c8e6df5217b4cba99907580b51af
├── da/
| └── f3f26f3fa03da346999c3e02d5268cb9abc5c5
└── f7/
└── f18b17881d80bb87f281c2881f9a4663cfcf84
※これ以後、本文中のハッシュ値は文字数を省略します。3
それぞれの対応するデータとハッシュ値をまとめると以下の通りです。
| ハッシュ値 | オブジェクト | 対応データ |
|---|---|---|
f7f18b1 |
blob |
first.txt |
af22102 |
blob |
second.py |
daf3f26 |
tree |
project direcrtory |
48c972a |
commit |
コミット |
*解体作業は、インタプリタ言語であるPythonを使用し、対話的に進めていきます。
blob
blobは、ファイルデータに対応したオブジェクトです。
イメージはこんな感じです。
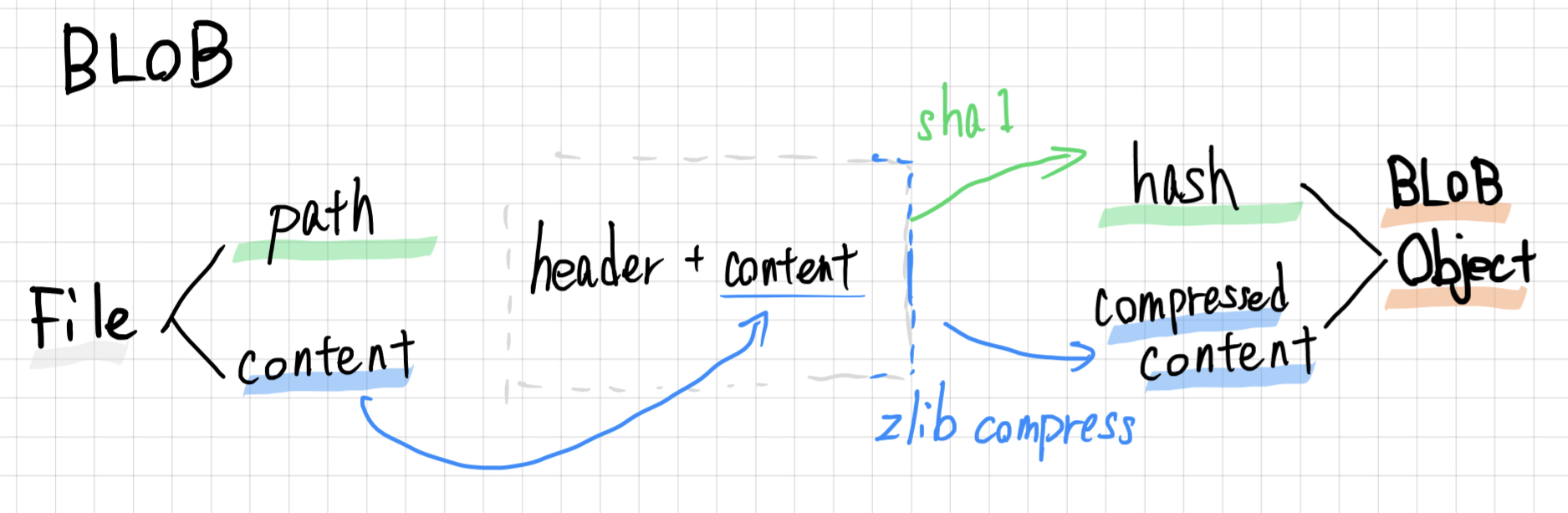
データ
まず、first.txtに対応するf7f18b1を見てみるとしましょう。
と思ったら、失敗してしまいました。
% python
>>> with open('.git/objects/f7/f18b17881d80bb87f281c2881f9a4663cfcf84', 'r') as f:
... contnet = f.read()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xca in position 3: invalid continuation byte
コンテンツが圧縮されているので、コンテンツをそのまま文字列4として読み込もうとすると失敗します
そのため、バイナリのまま読み込みます。
>>> with open('.git/objects/f7/f18b17881d80bb87f281c2881f9a4663cfcf84', 'rb') as f: # binaryで読み込む!
... contnet = f.read()
>>> content
b'x\x01K\xca\xc9OR06d\xf0H\xcd\xc9\xc9W\x08\xcf/\xcaIQ\xe4\n\xc9\xc8,V\x00\xa2\xb4\xcc\xa2\xe2\x12\xbd\x92\x8a\x12=\x00\xfa-\r\x03'
そうすると無事読み込めて、バイト文字列を変数に格納できました。
それでは、公式ドキュメントにあるように、zlibで解凍します。
>>> import zlib
>>> decompressed = zlib.decompress(content)
>>> decompressed
b'blob 31\x00Hello World!\nThis is first.txt.'
>>> decompressed.split(b'\0')
[b'blob 31', b'Hello World!\nThis is first.txt.']
公式ドキュメント通り、blobは、以下の要素で構成されていることがわかりました。
header ... blob 31
Null byte ... \x00 ※\xは16進法表記
content ... Hello World!\nThis is first.txt.
ファイル名
次に確認すべきは、オブジェクトのハッシュ値が本当に正しいかどうかです。
オブジェクトのファイル名は、decompressedをsha1というハッシュ関数で求まった値であるはずなので、確認してみます。
>>> import hashlib
>>> blob = b'blob 31\x00Hello World!\nThis is first.txt.'
>>> sha1 = hashlib.sha1(blob).hexdigest() #表示形式はhex(16進法)
>>> sha1
'f7f18b17881d80bb87f281c2881f9a4663cfcf84'
ばっちり一致しましたね!!
もう一つのファイルはどうか
もう一つのsecond.pyに対応するaf22102も見ておきましょう。
>>> with open('.git/objects/af/22102d62f1c8e6df5217b4cba99907580b51af', 'rb') as f: # binaryで読み込む!
... contnet = f.read()
>>> decompressed = zlib.decompress(content)
>>> decompressed
b'blob 44\x00def second():\n print("This is second.py")'
>>> blob = b'blob 44\x00def second():\n print("This is second.py")'
>>> sha1 = hashlib.sha1(test).hexdigest()
>>> sha1
'af22102d62f1c8e6df5217b4cba99907580b51af'
つまり、以下の通りまとめることができます。
header ... blob 44
Null byte ... \x00 ※\xは16進法表記
content ... def second():\n print("This is second.py")
そして、データから導かれたsha1の値(ハッシュ値)も見事一致しました。
(補足)
blob自体には、対応するファイルデータのファイル名を保持していません。
blobの代わりにその名前を管理するオブジェクトが、treeになります。
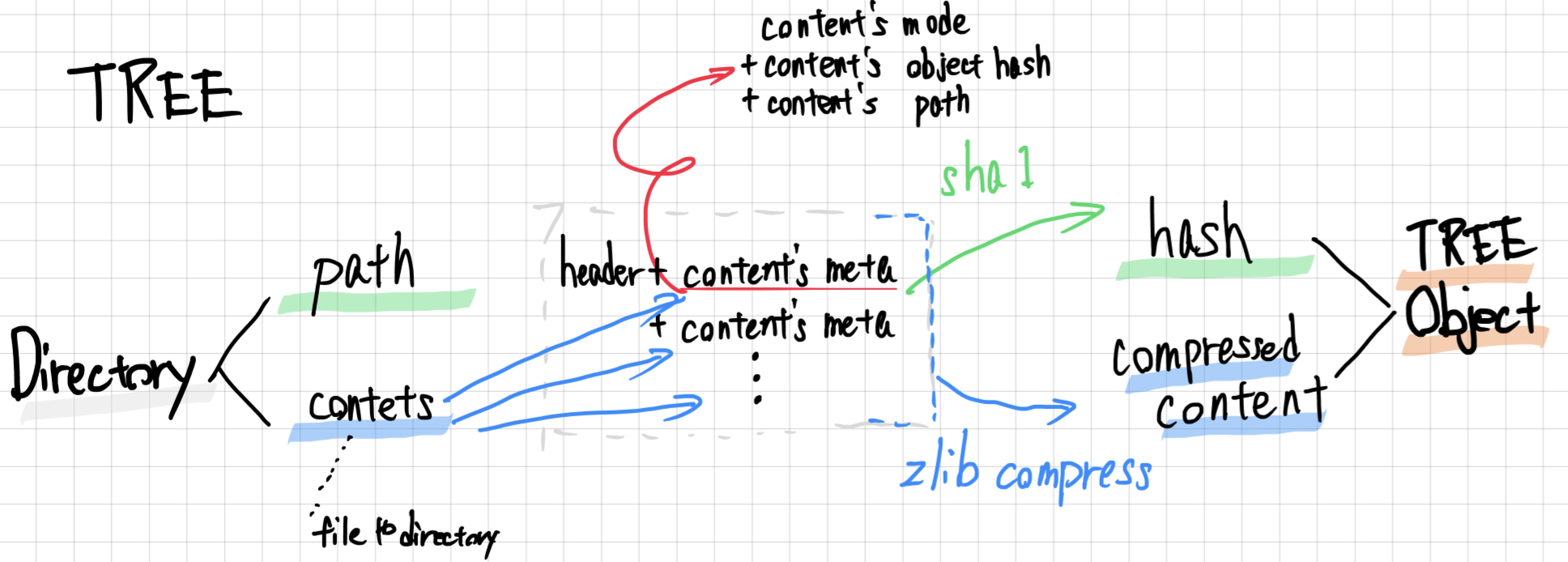
Tree
treeは、ディレクトリデータに対応したオブジェクトです。
イメージはこんな感じです。
blob同様に解凍していきます。
>>> with open('.git/objects/da/f3f26f3fa03da346999c3e02d5268cb9abc5c5', 'rb') as f:
... content = f.read()
>>> decompressed = zlib.decompress(content)
>>> decompressed
b'tree 74\x00100644 first.txt\x00\xf7\xf1\x8b\x17\x88\x1d\x80\xbb\x87\xf2\x81\xc2\x88\x1f\x9aFc\xcf\xcf\x84100644 second.py\x00\xaf"\x10-b\xf1\xc8\xe6\xdfR\x17\xb4\xcb\xa9\x99\x07X\x0bQ\xaf'
>>> decompressed.split(b'\0')
[b'tree 74',
b'100644 first.txt',
b'\xf7\xf1\x8b\x17\x88\x1d\x80\xbb\x87\xf2\x81\xc2\x88\x1f\x9aFc\xcf\xcf\x84100644 second.py',
b'\xaf"\x10-b\xf1\xc8\xe6\xdfR\x17\xb4\xcb\xa9\x99\x07X\x0bQ\xaf']
treeは、複数のコンテンツを持っているので、少し複雑です。
treeは、ディレクトリ内にあるデータのメタ情報であるmode5、pathとそのデータをオブジェクトにした場合のhashを繰り返す形で、構成されています。
ただ、単純に\0で切り分けると、前データのハッシュ値と次のファイルデータのメタ情報がくっついています。
これは、メタ情報とハッシュ値を\0で区切っているためです。
まず、一つ目に格納されたデータを確認していきます。
分割した感じを見るとfirst.txtが格納されていそうですよね。
>>> temp = decompressed.split(b'\0')
>>> temp[1]
b'100644 first.txt'
>>> temp[2]
b'\xf7\xf1\x8b\x17\x88\x1d\x80\xbb\x87\xf2\x81\xc2\x88\x1f\x9aFc\xcf\xcf\x84100644 second.py'
temp[2]をうまく分割するために、20バイトで取り出してみます。
バイト文字列の配列アクセスは、バイト単位で行うことができます。
>>> temp[2][0:20]
b'\xf7\xf1\x8b\x17\x88\x1d\x80\xbb\x87\xf2\x81\xc2\x88\x1f\x9aFc\xcf\xcf\x84'
>>> temp[2][0:20].hex()
'f7f18b17881d80bb87f281c2881f9a4663cfcf84'
>>> temp[2][20:]
b'100644 second.py'
同じことを繰り返すと以下のことがわかりました。
header ... tree 74
Null byte ... \x00 ※\xは16進法表記
content1 ... 100644 first.txt\x00f7f18b1...
content2 ... 100644 second.py\x00af22102...
treeのハッシュの管理については、(余談)Treeのバイトを読み解くで書いています!
(補足)
treeには、blobだけではなく、treeも格納されることもあります。
つまりディレクトリ内に、ディレクトリがある場合です。
なぜならtreeもblobと同様に自身と対応するデータのディレクトリ名を保持していないためです。
Commit
commitは、リポジトリディレクトリのtreeをメタ情報と共に格納したオブジェクトです。
イメージはこんな感じです。
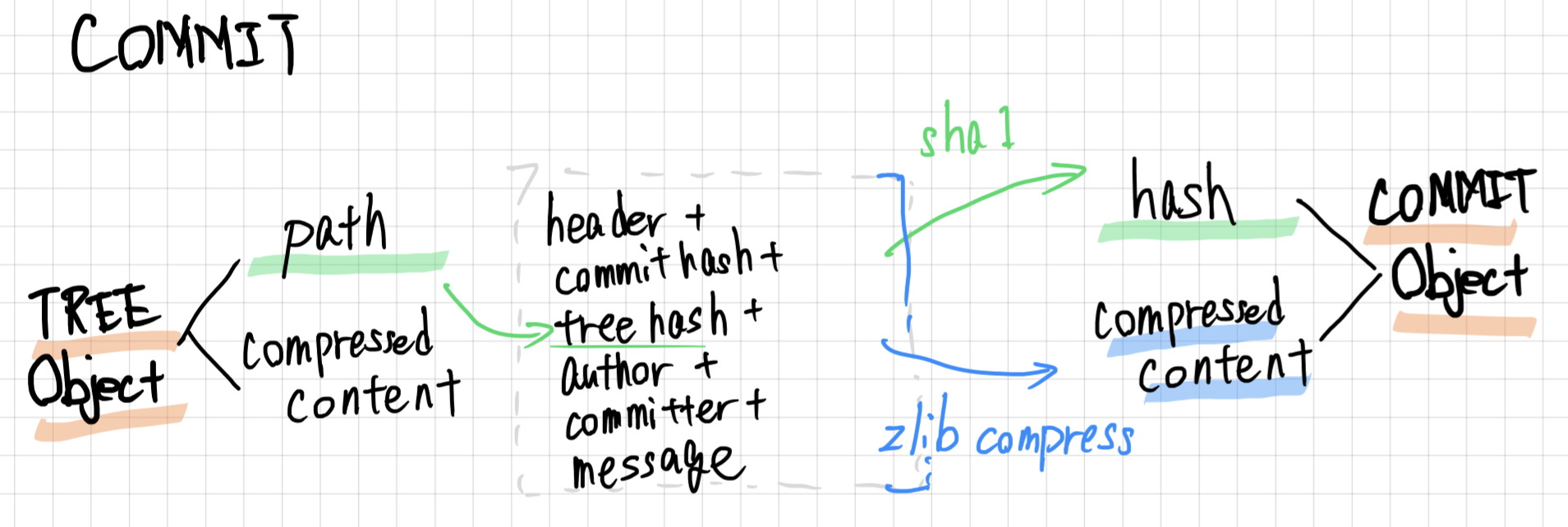
解凍していきます!
>>> with open('.git/objects/48/c972ae2bb5652ada48573daf6d27c74db5a13f', 'rb') as f:
... content = f.read()
>>> decompressed = zlib.decompress(content)
>>> decompressed
b'commit 188\x00tree daf3f26f3fa03da346999c3e02d5268cb9abc5c5\nauthor nopeNoshishi <nope@noshishi.jp> 1674995860 +0900\ncommitter nopeNoshishi <nope@noshishi.jp> 1674995860 +0900\n\ninitial\n'
>>> decompressed.split(b'\0')
[b'commit 188',
b'tree daf3f26f3fa03da346999c3e02d5268cb9abc5c5\nauthor nopeNoshishi <nope@noshishi.jp> 1674995860 +0900\ncommitter nopeNoshishi <nope@noshishi.jp> 1674995860 +0900\n\ninitial\n']
# もう少し分解してみる
>>> header, content = decompressed.split(b'\0')
>>> header
b'commit 188'
>>> content
b'tree daf3f26f3fa03da346999c3e02d5268cb9abc5c5\nauthor nopeNoshishi <nope@noshishi.jp> 1674995860 +0900\ncommitter nopeNoshishi <nope@noshishi.jp> 1674995860 +0900\n\ninitial\n'
>>> content.split(b'\n')
[b'tree daf3f26f3fa03da346999c3e02d5268cb9abc5c5',
b'author nopeNoshishi <nope@noshishi.jp> 1674995860 +0900',
b'committer nopeNoshishi <nope@noshishi.jp> 1674995860 +0900',
b'',
b'initial',
b'']
格納されているデータは、以下の通りです。
header ... commit 188
Null byte ... \x00
tree ... tree daf3f26f3fa03da346999c3e02d5268cb9abc5c5
author ... author nopeNoshishi <nope@noshishi.jp> 167...
committer ... committer nopeNoshishi <nope@noshishi.jp> 167...
message ... initial
先ほどtreeの章で確認したtreeのハッシュ値、リポジトリの所有者やコミットを行った者の情報、そしてメッセージが格納されていることがわかります。
もう少し踏み込んでみてみます。
first.txtを以下の通り編集して、再度addしてcommitします。
Hello World!
This is first.txt.
Version2
git add first.txt
git commit -m 'second'
そうすると、.git/objectsの中身は以下の通りとなりました。
.git/
└── objects/
├── 3f/
| └── f934272 # new tree .. projectリポジトリのバージョン2
├── 37/
| └── 349c9b0 # new commit .. "second"
├── 48/
| └── c972ae2 # old commit .. "initial"
├── af/
| └── 22102d6 # old blob .. second.pyのバージョン1
├── c8/
| └── 843b4db # new blob .. first.txtのバージョン2
├── da/
| └── f3f26f3 # old tree .. projectリポジトリのバージョン1
└── f7/
└── f18b178 # new blob .. first.txtのバージョン1
新しいコミットを見てみると、、、
>>> with open('.git/objects/37/349c9b05c73281008e7b6b7453b595bb034a52', 'rb') as f:
... content = f.read()
...
>>> decompressed = zlib.decompress(content)
>>> decompressed
b'commit 235\x00tree 3ff9342727caf81397740327aa406c1cc6d4408e\nparent 48c972ae2bb5652ada48573daf6d27c74db5a13f\nauthor nopeNoshishi <nope@noshishi.jp> 1675174139 +0900\ncommitter nopeNoshishi <nope@noshishi.jp> 1675174139 +0900\n\nsecond\n'
格納されているデータは、以下の通りです。
header ... commit 188
Null byte ... \x00
tree ... tree daf3f26f3fa03da346999c3e02d5268cb9abc5c5
parent ... parent 48c972ae2bb5652ada48573daf6d27c74db5a13f
author ... author nopeNoshishi <nope@noshishi.jp> 167...
committer ... committer nopeNoshishi <nope@noshishi.jp> 167...
message ... second
以前のバージョンのcommitのハッシュ値を格納していました。
(補足)
blobとtreeとの構造の違いは、実際にリポジトリにあるデータそのものを格納しているのではなく、リポジトリであるディレクトリのtreeを起点に、メタ的なデータを格納している点です。
キーバリューストア
ここまでくるとなんとなく察しがつく方もいらしゃると思います。
commitを紐解けばtreeが、treeを紐解けばblobが読み解けることになります。

バージョンの流れは、commitが前のcommitのハッシュ値を知っているので、履歴がわかる。
今回のコミットした履歴を表すとこんなイメージです。

つまり、Gitはオブジェクトのハッシュ値を起点として、ファイルのバージョンを管理しているということになります。
ちなみに公式では、Gitのことをアドレス(ハッシュ)ファイルシステムと呼称しています。
ハッシュ関数自体が不可逆変換のため、ハッシュ値から元のデータに復元できませんが、ハッシュ値がそもそもオブジェクトの中身に依存して決まる以上、バリューバリューストアとも言えるかもしれませんが(笑)
まとめ
Gitのようなバージョン管理システムがない世界において、今のファイルを残したまま、同じファイルで新しい作業を進めたいとなったとき、みなさんはどうするでしょうか?
おそらく、一つの方法として、ファイルをコピーして別のフォルダにしまっておくということを考えた方もいるかもしれません。
実は、この一見してヘンテコな管理方法をこそがGitを支えるバージョン管理に近い形になります。
Gitは、OSのファイルシステムを巧みに活用した、ストレージシステムだと考えることができます。
インデックスを解体してみる
ベールに包まれたインデックス(ステージングエリア)ですが、これもオブジェクト同様に非常にシンプルな設計になっています。
(一方で、解析には少しばかり癖があります。インデックスの解体に、数十時間を吸われました、、、、)
2回目のコミットを終えた、.git/indexを解体していきます。
仕様
解体するにあたってindexの設計仕様を把握します。
公式ドキュメント内のIndex formatを参照にすると以下の仕様であることがわかりました。
インデックスのフォーマット
ヘッダー
- 4 bytes インデックスヘッダー *DIRCという文字列
- 4 bytes インデックスバージョン *基本的にVersion2が多いと思います
- 32 bits インデックスのエントリー数 *エントリーは各ファイルのメタ情報のこと
エントリー
- 32 bits 作成時間
- 32 bits 作成時間のnano単位
- 32 bits 変更時間
- 32 bits 変更時間のnano単位
- 32 bits デバイスID
- 32 bits inode番号
- 32 bits パーミッション(mode)
- 32 bits ユーザーID
- 32 bits グループID
- 32 bits ファイルサイズ
- 160 bits `blob`のハッシュ値
- 16 bits ファイル名のサイズ *ファイル名の文字列のバイト数
- ? bytes ファイル名 *ファイル名によって可変
- 1-8 bytes パディング *エントリーによって可変
... エントリの数だけ同じことが続く
index
仕様がわかったので、またpythonで読み解いていきます。
indexは圧縮されてないものの、全てのメタ情報をバイトで保存しているためオブジェクト同様にバイナリ形式で読み込みます。
>>> with open('.git/index', 'rb') as f:
... index = f.read()
>>> index
b'DIRC\x00\x00\x00\x02\x00\x00\x00\x02c\xd9 \xf4\x05\xeb\x80\xb2c\xd9 \xf4\x05\xeb\x80\xb2\x01\x00\x00\x06\x00\xb8\'\x07\x00\x00\x81\xa4\x00\x00\x01\xf5\x00\x00\x00\x14\x00\x00\x00(\xc8\x84;M\xb8\x06\xe5\xd6Z\x12\xefV\xbfK\xeeQ\xe7\x15\'\x93\x00\tfirst.txt\x00c\xd6hv\x17\xa5\x05nc\xd6hv\x17\xa5\x05n\x01\x00\x00\x06\x00\xb8\'\x14\x00\x00\x81\xa4\x00\x00\x01\xf5\x00\x00\x00\x14\x00\x00\x00,\xaf"\x10-b\xf1\xc8\xe6\xdfR\x17\xb4\xcb\xa9\x99\x07X\x0bQ\xaf\x00\tsecond.py\x00TREE\x00\x00\x00\x19\x002 0\n?\xf94\'\'\xca\xf8\x13\x97t\x03\'\xaa@l\x1c\xc6\xd4@\x8e\xf2\xe4\xd7:\x95\xc1?\x18\xd3\xe9\x7f\x8fp\x9c$N\xc9dX\xa4'
ところどころ読めそうなところがあります。
元のDIRCやfirst.txt、second.pyが見えていますね!
仕様に沿って解体していきます。
32bitsは4bytesなので、簡単に引き出すことができます。
>>> index[0:4]
b'DIRC' # インデックスヘッダー -> DIRC
>>> index[4:8]
b'\x00\x00\x00\x02' # インデックスバージョン => 2
>>> index[8:12]
b'\x00\x00\x00\x02' # エントリーの数 => 2
indexではファイル単位でメタデータを管理しているので、first.txt、second.pyの二つがエントリーとして入っていることになります。
この記事の説明において、次の作成時間からグループIDまで、mode以外あんまり重要ではないメタ情報なので、さっくりみるだけにします。
>>> index[12:16]
b'c\xd9 \xf4' # ctime
>>> index[16:20]
b'\x05\xeb\x80\xb2' # ctime nano
>>> index[21:24]
b'\xd9 \xf4' # mtime
>>> index[24:28]
b'\x05\xeb\x80\xb2' # mtime nano
>>> index[28:32]
b'\x01\x00\x00\x06' # dev id
>>> index[32:36]
b"\x00\xb8'\x07" # inode
>>> index[36:40]
b'\x00\x00\x81\xa4' # mode
>>> index[41:44]
b'\x00\x01\xf5' # user id
>>> index[44:48]
b'\x00\x00\x00\x14' # gorup id
ここからがみておきたいポイントです。
まずはファイルサイズです。
# ファイルサイズ
>>> index[48:52]
b'\x00\x00\x00('
>>> index[48:52][0]
0
>>> index[48:52][1]
0
>>> index[48:52][2]
0
>>> index[48:52][3]
40
次にくるファイルのファイルサイズが40bytesであることがわかりました。
次はハッシュ値です。
# hash
>>> index[52:72]
b"\xc8\x84;M\xb8\x06\xe5\xd6Z\x12\xefV\xbfK\xeeQ\xe7\x15'\x93"
>>> index[52:72].hex()
'c8843b4db806e5d65a12ef56bf4bee51e7152793'
ハッシュ値がバージョン2のfirst.txtのものと一致していますね!
そして、ファイル名のサイズ。
# ファイル名のサイズ
>>> index[72:74]
b'\x00\t'
>>> index[72:74][0]
0
>>> index[72:74][1]
9
このサイズ(バイト)が非常に重要で、これがないと次のファイル名を手探りで探すことになってしまいます。
ファイル名は9バイトとわかったので、、、
>>> index[74:83]
b'first.txt'
しっかりもれなくファイル名を抜き出すことができました。
最後にパディングですが、これはエントリーを表現するために使用されたバイト数に依存した形で決まります。
計算方法は、パディングまでのバイトとパディングするXバイトを足したものが、8の倍数となるようなXバイトを求めます。
計算式で表すと、X(パディング)、y(ファイル名サイズ)、a(余り)
(62 + y) / 8 = 商 ... a \\
8 - a = X
今回の場合は、
作成時刻からファイルサイズまで、62バイト
ファイル名が9バイト
(62 + 9) / 8 = 8 ... 7 \\
8 - 7 = 1
パディングのバイト数が1バイトであることがわかりました。
>>> index[83:84]
b'\x00'
>>> index[83:85]
b'\x00c' # ヌルバイトではないものが2バイト目からある!
>>> index[83:86]
b'\x00c\xd6'
ちゃんと次のエントリ作成時刻の部分までのパディングのバイト数が一致していました。
まとめ
実は、addした段階ではまだtreeオブジェクトが作成されていません。
commitを行ったときに、indexをもとにtreeオブジェクトが作成されます。
インデックスは、追加されたファイルデータをblobと紐付け、どのバージョンのファイルをコミットさせるかを管理する重要な要素だったということです。
よくGitは差分ではなくスナップショットであると解説されています。
インデックスが更新されていないファイルデータは、明示的に除外しない限り常に残り続けます。
そして、コミットしたものは全てインデックスを通して復元できるということです。
ファイルをGitのバージョン管理対象にするか否かを握る重要な存在がindex
コマンドの裏で起こっていること
Gitのデータの扱い方がわかったところで、次はコマンドがどのように振る舞うのかを簡単に見ていきます。
コマンドには多くのオプションがあるため、もっと複雑な動作が実現できますが、あくまでもベースのコマンドとして記述します。
add
対象とするファイルデータをインデックスに追加・削除・更新する役割を担います。
追加された場合は、その追加された 瞬間(最新) のファイルデータのblobを作成します。
このコマンドを実現する配管コマンドは、
hash-object、update-indexです。
※配管コマンドについては、配管コマンドの章で紹介します。
commit
作成されたインデックスをもとにリポジトリディレクトリに対応するtreeを作成し、その後commitを作成します。
無事commitが作成されたら、HEADやbranchがポイントするcommitのハッシュ値を変更します。
このコマンドを実現する配管コマンドは、
write-tree、commit-tree、update-refです。
余談
Treeのバイトを読み解く
少しバイトについて調べてみます。
(符号なし)1バイトで表せれる数字の最大値は幾つでしょうか。
2^8 - 1 = 255です。これは、16進法の数を二つで表せる最大の数と一致します。
>>> temp[2][0]
247 #\xf7と一致する数字
上ではさくっとhex()関数を使っちゃいましたが、1バイトづつ見ていくと、、、
>>> hash = ''
>>> for hex in temp[2][0:20]:
... hash += format(hex, 'x')
>>> hash
'f7f18b17881d80bb87f281c2881f9a4663cfcf84'
first.txtに対応するblobのハッシュ値が文字列として獲得できました!
hashは文字列としては40文字ですが、1文字づつは16進法で計算された値なので、2文字を1バイトで表せれるというのがカラクリでした。
commitは文字列として格納しているのに、treeでは、なぜかハッシュ値が文字列としてではなく、バイトとして直接格納されています。
stackoverflowでもなんでやねんの議論がありました。
HEADとBranch
Branchは、特定のcommitオブジェクトにマーキングする役割があります。
.git/refs/heads/以下に格納されています。
中身を見るのはLinuxコマンドのcatで簡単に見れます。
先ほどはmasterブランチで作業していたので、.git/refs/heads/masterを見てみると、、
% cat .git/refs/heads/master
37349c9b05c73281008e7b6b7453b595bb034a52
直前にコミットしたcommitオブジェクトのハッシュ値が格納されていました。
HEADは、自分がどのcommitオブジェクトをベースにファイルの編集を行なっているかを示しています。
HEADは、直接commitオブジェクトを指すこともできますが、基本的にbranchを経由します。
.git/HEADがその正体です。
今の段階であると以下のようにデータが格納されています。
% cat .git/HEAD
ref: refs/heads/master
masterブランチの格納場所についてのパスが入っていました。
直接コミットを指したい場合(detached head)は、checkoutでHEADを動かします。
% git checkout 37349c9b05c73281008e7b6b7453b595bb034a52
% cat .git/HEAD
ref: 37349c9b05c73281008e7b6b7453b595bb034a52
配管コマンド
Gitをさらにローレベルで操作するために、一つの動作ごとにコマンドが存在します。
(リーナス氏が、私のような凡人のために作ってくれた神のようなコマンドです。)
cat-file
オブジェクトの中身を見ることができるコマンドです。
先ほど頑張ってオブジェクトを解体しましたが、このコマンド一つで解決です。
# オブジェクトタイプを見る
% git cat-file -t af22102d62f1c8e6df5217b4cba99907580b51af # second.py
blob
# オブジェクトを標準出力で見る
% git cat-file -p af22102d62f1c8e6df5217b4cba99907580b51af # second.py
def second():
print("This is second.py")
hash-object
ファイルデータ等をハッシュ化したり、そのまま.git/objectsに格納することができます。
third.rsを作成してみます。
struct Third {
message: String
}
# ハッシュ値を求める
% git hash-object
4aa58eed341d5134f73f2e9378b4895e216a5cd5
# オブジェクトを作成する
% git hash-object -w
4aa58eed341d5134f73f2e9378b4895e216a5cd5
% ls .git/objects/4a
a58eed341d5134f73f2e9378b4895e216a5cd5
update-index
インデックスに、対象ファイルをインデックスに追加します。
ただし、オブジェクトは作成されないので、要注意です。
ls-files
インデックスの中身を簡潔に見ることができるコマンドです。
# 今の段階で見てみる
% git ls-files
first.txt
second.py
# 追加してみてみる
% git update-index --add third.rs
% git ls-files
first.txt
second.py
third.rs
% git ls-files -s
100644 c8843b4db806e5d65a12ef56bf4bee51e7152793 0 first.txt
100644 af22102d62f1c8e6df5217b4cba99907580b51af 0 second.py
100644 4aa58eed341d5134f73f2e9378b4895e216a5cd5 0 third.rs
write-tree
インデックスの内容をもとにtreeを作成します。
リポジトリディレクトリだけではなく、すべてのディレクトリが対象です。
% git write-tree
109e41a859caa3e3b87e8f59744b0b1845efe275
% ls .git/objects/10
9e41a859caa3e3b87e8f59744b0b1845efe275
commit-tree
作成されたリポジトリディレクトリのtreeのハッシュ値を引数に受けて、commitを作成します。
# 親となる`commit`のハッシュ値と先ほど作った`tree`のハッシュ値を入力する
% git commit-tree -p 37349c9b05c73281008e7b6b7453b595bb034a52 -m 'third commit' 109e41a859caa3e3b87e8f59744b0b1845efe275
ddb3c0d94d860ff657e2cdb82f5513f7db2924f1
% ls .git/objects/dd
b3c0d94d860ff657e2cdb82f5513f7db2924f1 # オウジェクトが作成されている。
update-ref
commit-tree しただけでは履歴を追うことができません。
なぜなら、せっかく作ったコミットを誰も参照していないからです。
# git logはHEADが指しているコミットから順に歴史を追うので
# 先ほど作成したコミットはまだ参照されていない。
% git log
commit 37349c9b05c73281008e7b6b7453b595bb034a52 (HEAD -> master)
Author: nopeNoshishi <nope@noshishi.jp>
Date: Tue Jan 31 23:08:59 2023 +0900
second
commit 48c972ae2bb5652ada48573daf6d27c74db5a13f
Author: nopeNoshishi <nope@noshishi.jp>
Date: Sun Jan 29 21:37:40 2023 +0900
initial
# このコマンドでブランチの参照先を変えてあげる
% git update-ref refs/heads/master ddb3c0d 37349c9 # 新 旧
% git log
commit ddb3c0d94d860ff657e2cdb82f5513f7db2924f1 (HEAD -> master)
Author: nopeNoshishi <nope@noshishi.jp>
Date: Thu Feb 2 21:17:24 2023 +0900
third commit
commit 37349c9b05c73281008e7b6b7453b595bb034a52
Author: nopeNoshishi <nope@noshishi.jp>
Date: Tue Jan 31 23:08:59 2023 +0900
second
Gitを作成する上で、addやcommitのような高機能なものをいきなり作るのは難しいです。
そのため、配管コマンドをうまく実装しながら、このコマンドの機能をバイパスに開発編ではaddやcommitを作成します。
最後に
最後まで読んでくださりありがとうございました!
まだまだ荒い解説ですが、皆さんの理解に少しでも貢献できれば幸いです。
次の開発編もみていただけると幸いです。
参考サイト
Gitを作る上で理解しておくといいこと
バイナリ
バイト
ビット演算
n進法と文字列
文字列
文字列解析、圧縮アルゴリズム
ハッシュ関数
ファイルシステム
-
とても有名なSHA系のハッシュ関数の一つです。60ビット(20バイト)のハッシュ値を生成するのが特徴です。ちなみに、sha1のハッシュ値の衝突する可能性は天文学的な確率になるそうです。Gitのhashが衝突するのはどれくらいの確率か ↩
-
データを可逆圧縮するフリーソフトウェアです。メインのDeflateと呼ばれる圧縮アルゴリズムがとても面白いのでぜひみてさい!公式サイト ↩
-
Gitのコマンドでハッシュ値を直接指定する場合あ、よく7文字くらいでのハッシュ値で指定することがあると思います。[2]で述べたように、入力が少ないハッシュ値でも、ほとんどハッシュ衝突しないからこそ特定のオブジェクトを見つけることができるということです。
shellでtabを押して入力を補助を受ける感じと似ています。 ↩ -
圧縮されたデータは文字コードと対応しない形でデータが保存されています。そのため、特定の文字コードとして読み込めません。UTF-8(ユーティーエフエイト)とは? ↩
-
mode(パーミッション)ももちろんバイナリで表現できます。そして、組み合わせが少ないので、特定の組み合わせを計算で表現できるようになっています。アクセス権(パーミッション)の記号表記と数値表記 ↩