内容
PyTorchを勉強し始めました.
手始めにMNISTとFASHION-MNISTを学習させてみます.
< 対象 >
・PyTorchに入門したい人
・ニューラルネットワークの基礎がある人
< 非対象 >
・ニューラルネットワークの理論を知りたい人
・正答率を上げたい人
【実行環境】
Ubuntu 18.04 LTS
PyTorch 1.0.1
NumPy 1.16.3
なお, GPUは使用せずCPUのみで実行しています.
DATASETに関してはこちら.
http://yann.lecun.com/exdb/mnist/
https://github.com/zalandoresearch/fashion-mnist
Architecture
いずれも3層のニューラルネットワークとします.
線形変換の出力を$Z$, 線形変換への入力を$X$, ニューラルネットワークの出力を$Y$としています.
Z_1 = X_1 W_1 \\
X_2 = \text{ReLU}(Z_1) \\
Z_2 = X_2 W_2 \\
Y = \text{Softmax}(Z_2)
Source Code
まずは全体のコードから.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from torchvision import datasets, transforms
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(NeuralNet, self).__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
def forward(self, X1):
Z1 = self.linear1(X1)
X2 = F.relu(Z1)
Z2 = self.linear2(X2)
Y = F.softmax(Z2, dim=-1)
return Y
def mnist_learning(hidden_size=200, lr=0.01, batch_size=32, n_epoch=10, debug=True, fashion=False):
# ----- MODEL SETTING -----
model = NeuralNet(input_size=784, hidden_size=hidden_size, output_size=10)
optimizer = optim.SGD(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.view(784))
])
# ----- PREPROCESS -----
# ----- MNIST -----
if not fashion:
dataloader_train = torch.utils.data.DataLoader(
datasets.MNIST('./data/mnist', train=True, download=True, transform=transform),
batch_size=batch_size,
shuffle=True
)
dataloader_test = torch.utils.data.DataLoader(
datasets.MNIST('./data/mnist', train=False, download=True, transform=transform),
shuffle=False
)
# ----- FASHION-MNIST -----
elif fashion:
dataloader_train = torch.utils.data.DataLoader(
datasets.FashionMNIST('./data/fashion-mnist', train=True, download=True, transform=transform),
batch_size=batch_size,
shuffle=True
)
dataloader_test = torch.utils.data.DataLoader(
datasets.FashionMNIST('./data/fashion-mnist', train=False, download=True, transform=transform),
shuffle=False
)
# ----- SHOW SAMPLE IMAGE -----
if debug:
data_train_0 = dataloader_train.dataset[0]
x_train_0 = data_train_0[0].numpy().reshape(28, 28)
t_train_0 = data_train_0[1]
print("This Is Debug Mode. Show Sample Image...\n")
print("DATA No.0 is {}".format(t_train_0))
plt.imshow(x_train_0, cmap=cm.Greys)
plt.show();
# ----- LEARNING -----
loss_train_list = []
loss_test_list = []
acc_test_list = []
for epoch in range(1, n_epoch+1):
loss_train_batch_list = []
loss_test_batch_list = []
correct = 0
total = 0
# ----- TRAIN -----
model.train()
# ----- batch_sizeごとに処理 -----
for x_train_batch, t_train_batch in dataloader_train:
model.zero_grad() # 勾配の初期化
y_train_batch = model.forward(x_train_batch)
loss_train_batch = criterion(y_train_batch, t_train_batch)
loss_train_batch.backward()
optimizer.step()
loss_train_batch_list.append(loss_train_batch.tolist())
# ----- TEST -----
model.eval()
# ----- batch_sizeごとに処理 -----
for x_test_batch, t_test_batch in dataloader_test:
y_test_batch = model.forward(x_test_batch)
loss_test_batch = criterion(y_test_batch, t_test_batch)
loss_test_batch_list.append(loss_test_batch.tolist())
label_test_batch = y_test_batch.argmax(1).numpy()
t_test_batch = t_test_batch.numpy()
correct += np.sum((label_test_batch - t_test_batch) == 0)
total += 1
loss_train_list.append(np.mean(loss_train_batch_list))
loss_test_list.append(np.mean(loss_test_batch_list))
acc_test_batch = 100 * correct / total
acc_test_list.append(acc_test_batch)
print('EPOCH: {}, TRAIN LOSS: {:.3f}, TEST LOSS: {:.3f}, TEST ACC: {:.3f}'.format(
epoch,
np.mean(loss_train_list),
np.mean(loss_test_list),
acc_test_batch
))
# ----- PLOT -----
plt.plot(loss_train_list)
plt.show()
plt.plot(loss_test_list)
plt.show()
plt.plot(acc_test_list)
plt.show()
if __name__ == '__main__':
mnist_learning(n_epoch=100, lr=0.01)
mnist_learning(fashion=True, n_epoch=100, lr=0.01)
解説
それでは簡単に解説していきましょう.
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(NeuralNet, self).__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
def forward(self, X1):
Z1 = self.linear1(X1)
X2 = F.relu(Z1)
Z2 = self.linear2(X2)
Y = F.softmax(Z2, dim=-1)
return Y
ここではNeuralNetをnn.Moduleを継承して定義しています. 簡単に言えば元々あったクラスを引き継いで自分好みにカスタマイズする感じでしょうか. 元々のnn.Moduleはネットワークの構造を何も指定していないので自分で指定する必要があります. ここでは3層のニューラルネットワークにしました.
forwardに関しては,
def forward(self, X):
return F.softmax(self.linear2(F.relu(self.linear1(X))), dim=-1)
というように, もっと簡略化出来ますが, 可読性のために敢えて先のような書き方にしました.
次にMODEL SETTINGを解説します.
# ----- MODEL SETTING -----
model = NeuralNet(input_size=784, hidden_size=hidden_size, output_size=10)
optimizer = optim.SGD(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.view(784))
])
ここでは, 先のNeuralNetに必要な次元を入力して設定しています. optimizerはパラメータの更新の仕方を決めていて, ここではSGD; Stochastic Gradient Decentにしています. criterionは評価関数です. ここでは交差エントロピー誤差にしています. transformは後にdatasetに施す前処理を扱うクラスです. transforms.Composeでその前処理の関数を定めます. transforms.ToTensor()ではdatasetをテンソル型にしてGPUで扱える形にします. transforms.Lambda x: x.view(784)ではdatasetを指定したサイズに整形します. 例を見てみましょう.
>>> x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
>>> x
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> x.view(-1, 1)
tensor([[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9]])
>>> x.view(9)
tensor([1, 2, 3, 4, 5, 6, 7, 8, 9])
つまり, flatten, 1次元ベクトルにしているということになります.
次にPREPROCESSを見ていきましょう.
# ----- PREPROCESS -----
# ----- MNIST -----
if not fashion:
dataloader_train = torch.utils.data.DataLoader(
datasets.MNIST('./data/mnist', train=True, download=True, transform=transform),
batch_size=batch_size,
shuffle=True
)
dataloader_test = torch.utils.data.DataLoader(
datasets.MNIST('./data/mnist', train=False, download=True, transform=transform),
shuffle=False
)
# ----- FASHION-MNIST -----
elif fashion:
dataloader_train = torch.utils.data.DataLoader(
datasets.FashionMNIST('./data/fashion-mnist', train=True, download=True, transform=transform),
batch_size=batch_size,
shuffle=True
)
dataloader_test = torch.utils.data.DataLoader(
datasets.FashionMNIST('./data/fashion-mnist', train=False, download=True, transform=transform),
shuffle=False
)
if, elifではMNISTを扱うか, FASHION-MNISTを扱うかを定めている分岐に過ぎないのでMNISTに絞って見ていきましょう.
ここでは, './data/mnist'からdatasetを取り出します. download=Trueとすることで, datasetがない場合にweb上からdownloadします. transform=transformの部分で先の前処理を行うインスタンスを渡します. batch_size, shuffleはそのままです.
では, このdata_loaderはどう扱うのでしょうか? 少し見ていきましょう. まずはDataLoaderのinitializeを見てみます.
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=default_collate,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None):
必ずdatasetを第一引数に渡します. datasetが指定されていないのに読み込みも何もないですからね. あとはoptionを指定できるようになっています. これを見るとdatasetのdataにはdataloader.dataset.dataでアクセス出来ます.
>>> data = datasets.MNIST('./data/mnist', train=True, download=True, transform=transform).data
>>> data
tensor([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
...,
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8)
>>> data.shape
torch.Size([60000, 28, 28])
SHOW SAMPLE IMAGEに関してはdebug用にtrain dataの一番最初の画像とラベルを表示するようにしただけなので解説は特にありません.
LEARNINGで学習をしていきましょう.
# ----- LEARNING -----
loss_train_list = []
loss_test_list = []
acc_test_list = []
for epoch in range(1, n_epoch+1):
loss_train_batch_list = []
loss_test_batch_list = []
correct = 0
total = 0
# ----- TRAIN -----
model.train()
# ----- batch_sizeごとに処理 -----
for x_train_batch, t_train_batch in dataloader_train:
model.zero_grad() # 勾配の初期化
y_train_batch = model.forward(x_train_batch)
loss_train_batch = criterion(y_train_batch, t_train_batch)
loss_train_batch.backward()
optimizer.step()
loss_train_batch_list.append(loss_train_batch.tolist())
# ----- TEST -----
model.eval()
# ----- batch_sizeごとに処理 -----
for x_test_batch, t_test_batch in dataloader_test:
y_test_batch = model.forward(x_test_batch)
loss_test_batch = criterion(y_test_batch, t_test_batch)
loss_test_batch_list.append(loss_test_batch.tolist())
label_test_batch = y_test_batch.argmax(1).numpy()
t_test_batch = t_test_batch.numpy()
correct += np.sum((label_test_batch - t_test_batch) == 0)
total += 1
loss_train_list.append(np.mean(loss_train_batch_list))
loss_test_list.append(np.mean(loss_test_batch_list))
acc_test_batch = 100 * correct / total
acc_test_list.append(acc_test_batch)
print('EPOCH: {}, TRAIN LOSS: {:.3f}, TEST LOSS: {:.3f}, TEST ACC: {:.3f}'.format(
epoch,
np.mean(loss_train_list),
np.mean(loss_test_list),
acc_test_batch
))
transformによりfor文でiterationを回すと自動的にbatchごとに処理されるようになっています. すなわち, for文内一回の処理はbatch_sizeの単位の処理を書くことになります. 長くなるので簡単に解説します.
まずはbatchごとに処理していきます. 各batchでのlossをloss_train,test_batch_listに格納して全てのデータを見終えた段階で平均を取ります. これをそのepochでのlossとするわけです. 次のepochに移るときには当然このlistは初期化することになります. つまり, 平均を取るための仮のlistなわけです. これら平均の値は後にplotするために必要なので, loss_train,test_listに保存します. 当然こちらは初期化したら意味がありません. そういう理由でlistの定義した場所がfor文の外と内で分かれています.
batchごとの処理は簡単です. zero_gradで勾配を初期化し, forwardで順伝播し, criterionで損失関数を計算し, backwardで逆伝播し, stepでパラメータの更新をします.
では, 正答率の計算部分を見てみます.
correct = 0
total = 0
(中略)
label_test_batch = y_test_batch.argmax(1).numpy()
t_test_batch = t_test_batch.numpy()
correct += np.sum((label_test_batch - t_test_batch) == 0)
total += 1
分かりづらいのは下2行目でしょうか. ラベルは出力$Y$の最大値を取ってarray化しているだけです. 教師データ$t$のarray化します.
correct += np.sum((label_test_batch - t_test_batch) == 0) ではその2つのarrayの各要素が等しいような個数をカウントしています.
>>> x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
>>> y = np.array([3, 5, 5, 4, 5, 1, 6, 3, 9, 1])
>>> print(x-y)
>>> print(np.sum((x-y) == 0))
[-2 -3 -2 0 0 5 1 5 0 9]
3
正答率の計算方法でもっとよいものがあればコメント欄にてご教授くださると幸いです.
実行結果
MNIST
This Is Debug Mode. Show Sample Image...
DATA No.0 is 5
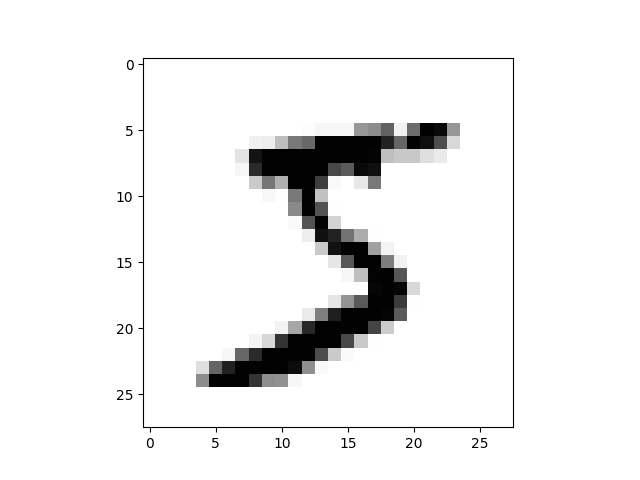



概ね良い感じでしょうか...?
FASHION-MNIST
This Is Debug Mode. Show Sample Image...
DATA No.0 is 9
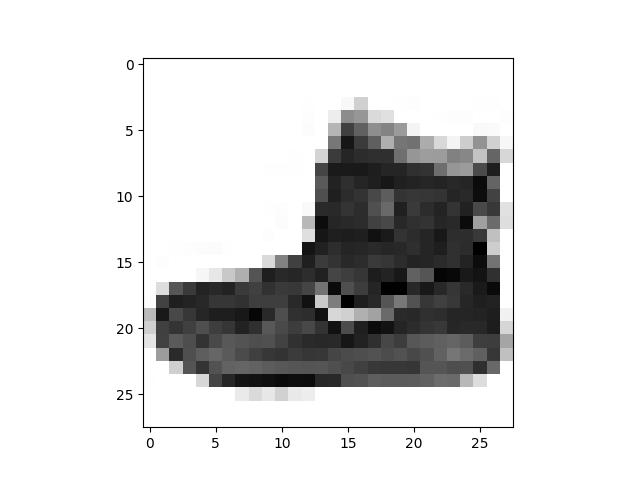



こちらも概ね良い感じでしょうか...?