この記事で最終的に何ができる?
あれこれ読んで, なーんだやりたかったことと違うじゃん…みたいなことあると悲しくなるので, 最初に何ができるか見てから記事を読むか判断してください.
- google colabでGPU利用で機械学習

- 多機能なplot機能

- iPhoneでハイパーパラメータの確認
 - iPhoneで実行中のデータの可視化
- iPhoneで実行中のデータの可視化
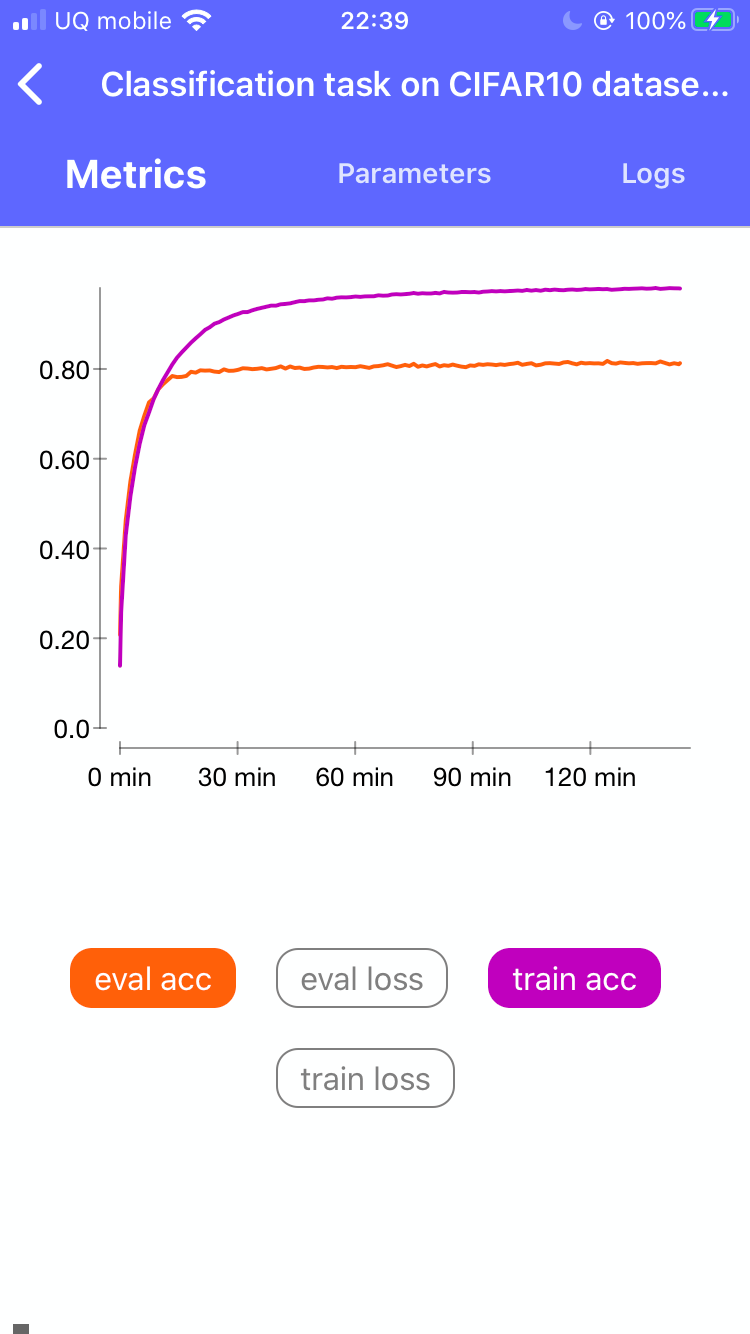 - iPhoneで実行中の出力の確認
- iPhoneで実行中の出力の確認

内容
手元に使い物になるGPUがないとき, Google Colabを使うという手があります.
そこで, 今回はGoogle Colabを便利に使うための環境を構築します.
要求内容
- 原則は
.ipynbでなく.pyで作る
- スマートフォンでリアルタイムで結果を見れるようにする
- Tensorboardで可視化する
1は, .ipynb形式だと他ファイルのimportが面倒なのとlocalで回すときにjupyterを使わなければならないのを回避したいということです.
機械学習フレームワークとしてPyTorchを使います.
基本手順
最初に手順を説明します.
- まずはlocalで実行するときと全く同じようにコードを書く
- スマートフォンで結果を見れるようにhyperdashを, webで結果を見れるようにtensorboardを導入し, その部分のコードを追加する
- これらのファイルをGoogle Driveにアップロードする(または1で最初からGoogle Driveをlocalにマウントして作成)
-
.pyファイルを実行するための実行スクリプトexec.ipynbを作成・実行する
hyperdashを使うとlogやパラメータ, グラフをリアルタイムでスマートフォンで見ることが出来ます.
ただし, これは1つのデータのみしか見ることが出来ず, パラメータを変えた場合の比較などが出来ません. また, plotのsmoothingやデータの取得なども出来ないので, ここは本家のtensorboardを使います.
データセットとネットワーク構造
今回はThe CIFAR-10 datasetをCNNで分類するタスクを選びました.
CNNのネットワーク構造はTrain a simple deep CNN on the CIFAR10 small images dataset.をPyTorchに書き換えました.
層の構成は次の通りです.
# network構造
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 32, 32] 896
Conv2d-2 [-1, 32, 30, 30] 9,248
MaxPool2d-3 [-1, 32, 15, 15] 0
Dropout-4 [-1, 32, 15, 15] 0
Conv2d-5 [-1, 64, 15, 15] 18,496
Conv2d-6 [-1, 64, 13, 13] 36,928
MaxPool2d-7 [-1, 64, 6, 6] 0
Dropout-8 [-1, 64, 6, 6] 0
Linear-9 [-1, 512] 1,180,160
Dropout-10 [-1, 512] 0
Linear-11 [-1, 10] 5,130
CNN-12 [-1, 10] 0
================================================================
ソースコード全体
まずはファイル構成を見てください.
.
├── .hyperdash
├── datasets
├── cifar10-cnn-pytorch
├── exec.ipynb
├── log
│ ├── 200304104116
│ │ ├── csv
│ │ │ ├── args.csv
│ │ │ └── results.csv
│ │ ├── model
│ │ │ └── model.tar
│ │ └── tensorboard
│ │ └── events.out.tfevents.1583318478.9998e7dcdb7c.342.0
│ ├── 200304111548
. .
. .
. .
└── src
├── main.py
├── net.py
└── utils.py
args.csvはargparseで指定したハイパーパラメータの保存, results.csvは出力結果の保存, model.tarはcheckpointの保存, tensorboardはtensorboardで描画するために保存するものです.
import os
import datetime
import csv
import torch
import torchvision
import torch.optim as optim
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
from torchsummary import summary
from pathlib import Path
from time import time
from net import CNN
from utils import get_loader, plot_classes_preds, get_args, matplotlib_imshow
def train(train_loader, model, criterion, optimizer, device, writer, epoch,
classes):
"""Train a neural networks.
"""
correct = 0
total = 0
running_loss = 0.0
model.train()
for i, data in enumerate(train_loader):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
writer.add_figure('prediction vs. actuals', plot_classes_preds(model,
inputs,
labels,
classes),
global_step=epoch * len(train_loader))
loss = running_loss / len(train_loader)
return loss, acc
def eval(eval_loader, model, criterion, device):
"""Evaluating a trained network.
"""
model.eval()
correct = 0
total = 0
running_loss = 0.0
with torch.no_grad():
for data in eval_loader:
inputs, labels = data[0].to(device), data[1].to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
loss = running_loss / len(eval_loader)
return loss, acc
def main():
start_time = time()
args = get_args()
if args.checkpoint_dir_name:
dir_name = args.checkpoint_dir_name
else:
dir_name = datetime.datetime.now().strftime('%y%m%d%H%M%S')
path_to_dir = Path(__file__).resolve().parents[1]
path_to_dir = os.path.join(path_to_dir, *['log', dir_name])
os.makedirs(path_to_dir, exist_ok=True)
# tensorboard
path_to_tensorboard = os.path.join(path_to_dir, 'tensorboard')
os.makedirs(path_to_tensorboard, exist_ok=True)
writer = SummaryWriter(path_to_tensorboard)
# model saving
os.makedirs(os.path.join(path_to_dir, 'model'), exist_ok=True)
path_to_model = os.path.join(path_to_dir, *['model', 'model.tar'])
# csv
os.makedirs(os.path.join(path_to_dir, 'csv'), exist_ok=True)
path_to_results_csv = os.path.join(path_to_dir, *['csv', 'results.csv'])
path_to_args_csv = os.path.join(path_to_dir, *['csv', 'args.csv'])
if not args.checkpoint_dir_name:
with open(path_to_args_csv, 'a') as f:
args_dict = vars(args)
param_writer = csv.DictWriter(f, list(args_dict.keys()))
param_writer.writeheader()
param_writer.writerow(args_dict)
# logging using hyperdash
if not args.no_hyperdash:
from hyperdash import Experiment
exp = Experiment('Classification task on CIFAR10 dataset with CNN')
for key in vars(args).keys():
exec("args.%s = exp.param('%s', args.%s)" % (key, key, key))
else:
exp = None
path_to_dataset = os.path.join(Path(__file__).resolve().parents[2],
'datasets')
os.makedirs(path_to_dataset, exist_ok=True)
train_loader, eval_loader, classes = get_loader(batch_size=args.batch_size,
num_workers=args.num_workers,
path_to_dataset=path_to_dataset)
# show some of the training images, for fun.
dataiter = iter(train_loader)
images, labels = dataiter.next()
img_grid = torchvision.utils.make_grid(images)
matplotlib_imshow(img_grid)
writer.add_image('four_CIFAR10_images', img_grid)
# define a network, loss function and optimizer
model = CNN()
writer.add_graph(model, images)
model = torch.nn.DataParallel(model)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=args.lr,
momentum=args.momentum)
start_epoch = 0
# resume training
if args.checkpoint_dir_name:
print('\nLoading the model...')
checkpoint = torch.load(path_to_model)
model.state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch'] + 1
summary(model, input_size=(3, 32, 32))
model.to(args.device)
# train the network
print('\n--------------------')
print('Start training and evaluating the CNN')
for epoch in range(start_epoch, args.n_epoch):
start_time_per_epoch = time()
train_loss, train_acc = train(train_loader, model, criterion,
optimizer, args.device, writer, epoch,
classes)
eval_loss, eval_acc = eval(eval_loader, model, criterion, args.device)
elapsed_time_per_epoch = time() - start_time_per_epoch
result_dict = {'epoch': epoch, 'train_loss': train_loss,
'eval_loss': eval_loss, 'train_acc': train_acc,
'eval_acc': eval_acc,
'elapsed time': elapsed_time_per_epoch}
with open(path_to_results_csv, 'a') as f:
result_writer = csv.DictWriter(f, list(result_dict.keys()))
if epoch == 0: result_writer.writeheader()
result_writer.writerow(result_dict)
# checkpoint
torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict()},
path_to_model)
if exp:
exp.metric('train loss', train_loss)
exp.metric('eval loss', eval_loss)
exp.metric('train acc', train_acc)
exp.metric('eval acc', eval_acc)
else:
print(result_dict)
writer.add_scalar('loss/train_loss', train_loss,
epoch * len(train_loader))
writer.add_scalar('loss/eval_loss', eval_loss,
epoch * len(eval_loader))
writer.add_scalar('acc/train_acc', train_acc,
epoch * len(train_loader))
writer.add_scalar('acc/eval_acc', eval_acc,
epoch * len(eval_loader))
elapsed_time = time() - start_time
print('\nFinished Training, elapsed time ===> %f' % elapsed_time)
if exp:
exp.end()
writer.close()
if __name__ == '__main__':
main()
import os
import argparse
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn.functional as F
from matplotlib import pyplot as plt
def get_loader(batch_size, num_workers, path_to_dataset):
"""Get a train loader and evaluation loader for CIFAR10.
"""
os.makedirs(path_to_dataset, exist_ok=True)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_data = torchvision.datasets.CIFAR10(
root=path_to_dataset,
train=True,
download=True,
transform=transform
)
eval_data = torchvision.datasets.CIFAR10(
root=path_to_dataset,
train=False,
download=True,
transform=transform
)
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
)
eval_loader = torch.utils.data.DataLoader(
eval_data,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers
)
classes = (
'plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship',
'truck')
return train_loader, eval_loader, classes
def images2probs(model, images):
"""
Generates predictions and corresponding probabilities from a trained
network and a list of images
"""
output = model(images)
_, predicted = torch.max(output, 1)
preds = np.squeeze(predicted.cpu().numpy())
probs = [F.softmax(el, dim=0)[i].item() for i, el in
zip(preds, output)]
return preds, probs
def plot_classes_preds(model, images, labels, classes):
"""
Generates matplotlib Figure using a trained network, along with images
and labels from a batch, that shows the network's top prediction along
with its probability, alongside the actual label, coloring this
information based on whether the prediction was correct or not.
Uses the "images_to_probs" function.
"""
preds, probs = images2probs(model, images)
fig = plt.figure(figsize=(12, 48))
for idx in range(4):
ax = fig.add_subplot(1, 4, idx + 1, xticks=[], yticks=[])
color = 'green' if preds[idx] == labels[idx].item() else 'red'
title_str = '%s, %.1f \n(label: %s)' % (
classes[preds[idx]], probs[idx] * 100.0, classes[labels[idx]])
matplotlib_imshow(images[idx])
ax.set_title(title_str, color=color)
return fig
def get_args():
"""Get hyperparameters from command line.
Returns:
args (argparse): Parser for command-line options.
"""
parser = argparse.ArgumentParser(description='CNN')
parser.add_argument('--batch_size', default=4, type=int, help='')
parser.add_argument('--num_workers', default=2, type=int)
parser.add_argument('--n_epoch', default=2, type=int)
parser.add_argument('--lr', default=0.001, type=float)
parser.add_argument('--momentum', default=0.9, type=float)
parser.add_argument('--no_hyperdash', default=False, action='store_true')
parser.add_argument('--checkpoint_dir_name', default=None, type=str)
parser.add_argument('--no_cuda', action='store_true', default=False)
args = parser.parse_args()
args.device = torch.device('cpu')
if not args.no_cuda and torch.cuda.is_available():
args.device = torch.device('cuda:0')
if torch.cuda.device_count() > 1:
gpu_ids = [id for id in range(len(torch.cuda.device_count()))]
args.device = torch.device(f'cuda:{gpu_ids[0]}')
print('####################')
print('device ===> ', args.device)
print('####################')
return args
def matplotlib_imshow(img, one_channnel=False):
"""Helper function to show an image.
"""
if one_channnel:
img = img.mean(dim=0)
img = img / 2 + 0.5
npimg = img.cpu().numpy()
if one_channnel:
plt.imshow(npimg, cmap='Greys')
else:
plt.imshow(np.transpose(npimg, (1, 2, 0)))
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
"""Click https://keras.io/examples/cifar10_cnn/ for reference.
"""
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, (3, 3), padding=(1, 1))
self.conv2 = nn.Conv2d(32, 32, (3, 3))
self.conv3 = nn.Conv2d(32, 64, (3, 3), padding=(1, 1))
self.conv4 = nn.Conv2d(64, 64, (3, 3))
self.fc1 = nn.Linear(6 * 6 * 64, 512)
self.fc2 = nn.Linear(512, 10)
self.pool1 = nn.MaxPool2d(2, 2)
self.dropout1 = nn.Dropout(p=0.25)
self.dropout2 = nn.Dropout(p=0.50)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool1(x)
x = self.dropout1(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.pool1(x)
x = self.dropout1(x)
x = x.view(-1, 6 * 6 * 64)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return x
ソースコードの実行
from google.colab import drive
drive.mount('/content/drive')
# 以下は1つのセルで実行
# optionは好きな値を設定
%%bash
nvidia-smi
pip install hyperdash
cp -r /content/drive/My\ Drive/Colab\ Notebooks/.hyperdash ~/
cd /content/drive/My\ Drive/Colab\ Notebooks/cifar10-cnn-pytorch/src
python main.py --n_epoch 150 --lr 0.001 --batch_size 64
hyperdashを使えるようにするまで
iPhone等のスマートフォンで結果を見るのにhyperdashを使いました.
tensorboardでもiOSで表示できる人もいるみたいですが, 上手く行きませんでした...
使い方は結構簡単で, 基本先のgithubのページを見れば分かります.
まずはinstallとsignupから.
# pipでinstall
$ pip install hyperdash
# gitアカウントでsign up
$ hd signup --github
あとは, 使い方.
from hyperdash import Experiment
# create
exp = Experiment('Sample')
# record the params
param = exp.param('param', param)
# record the numerical data
exp.metric('data', data)
# clean up
exp.close()
これをgoogle colab上で使うためにはAPI keyを設定する必要があります.
colab上で環境変数を設定すれば良いみたいですが, この辺り詳しくなくて上手く行きませんでした.
なので, local上~/.hyperdashをgoogle driveにuploadしてそれをcolab上で~/にコピーするやり方にしました.
!cp -r /content/drive/My\ Drive/Colab\ Notebooks/.hyperdash ~/
の部分になります.
tensorboardを使えるようにするまで
tensorboardは元々はTensorFlowで使われていたもので, PyTorchではtensorboard Xを経て, 最近公式にサポートされたものです.
smoothingしたり, plotするデータを選んだり, 画像やネットワーク構造まで描画できます.
PyTorchの公式TutorialのVISUALIZING MODELS, DATA, AND TRAINING WITH TENSORBOARDが分かりやすいです.
これも使い方は基本的にTutorialを見れば分かります.
from torch.utils.tensorboard import SummaryWriter
# create
writer = SummaryWriter(log_dir)
# record the image (from tensor, numpy array,...)
writer.add_image(tag, img_tensor)
# record the network architecuture
writer.add_graph(model, input)
# record the image (from matplotlib)
writer.add_figure(tag, figure)
# record the numerical data
writer.add_scalar(tag, scalar_value)
# clean up
writer.close()
tagの部分をloss/train_lossのようにグルーピングすると見るとき分かりやすいです.