はじめに
GPUが載ってないPCでディープラーニングをやってみたい、という人向けです。
数字画像の判定をやってみます。
事前準備
ColaboratoryでハードウェアアクセラレータにGPUを選択します。
Colaboratoryの使い方については前回の投稿も参考にしてください。
https://qiita.com/norikawamura/items/637c92545e222f16c535
データの準備
MNISTの数字画像(28×28)でもやや大きいので、もっと気軽に動かせるscikit-learnの数字画像(8×8)でやってみます。
import sklearn as skl
from sklearn import datasets
import pandas as pd
dgt = skl.datasets.load_digits()
digits_df = pd.DataFrame(dgt.data)
target_df = pd.DataFrame(dgt.target)
# 特徴量のセットを変数Xに、ターゲットを変数yに格納
X = digits_df.values
y = target_df.values
データの中身を確認します。
データのshapeを見ると以下のようになっています。
y(ターゲット)の方は(~,1)とデータ件数×1列の2次元の配列になっています。
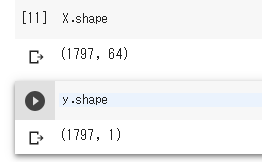
X(画像データ)は(~,64)と、こちらはデータ件数×64画素の2次元の配列になっています。
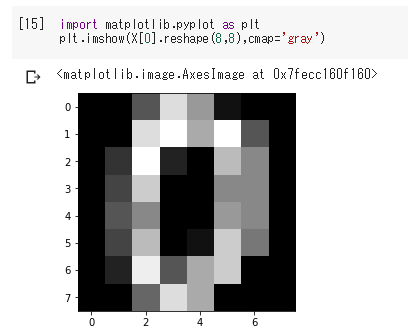
(~,8,8)にreshapeした値をpyplot.imshowで画像として確認できます。
import matplotlib.pyplot as plt
plt.imshow(X[0].reshape(8,8),cmap='gray')
学習データと検証用データに分けます。
特に前回までと違いはありません。
import numpy as np
import keras
# データの順番を入れ替えるためのランダムなNumPy配列
np.random.seed(42)
indices = np.random.permutation(len(X))
val_len = int(len(X) * -0.1)
# 学習用のデータ。全体から100データを省いたもの
X_train = X[indices[:val_len]]
y_train = y[indices[:val_len]]
# テスト用のデータ。全体から100データ取り出したもの
X_test = X[indices[val_len:]]
y_test = y[indices[val_len:]]
# サンプル数、特徴量の次元、クラス数の取り出し
(n_samples, n_features) = X_train.shape
n_classes = len(np.unique(y))
# ターゲットyをkeras用の形式に変換
y_keras = keras.utils.to_categorical(y_train, n_classes)
損失関数のグラフ表示
これも特に前回までと違いはありません。
import matplotlib.pyplot as plt
# 損失関数グラフ
def plotHistory(history):
# 損失関数のグラフの軸ラベルを設定
plt.xlabel('time step')
plt.ylabel('loss')
# グラフ縦軸の範囲を0以上と定める
plt.ylim(0, max(np.r_[history.history['val_loss'], history.history['loss']]))
# 損失関数の時間変化を描画
val_loss, = plt.plot(history.history['val_loss'], c='#56B4E9')
loss, = plt.plot(history.history['loss'], c='#E69F00')
# グラフの凡例(はんれい)を追加
plt.legend([loss, val_loss], ['loss', 'val_loss'])
# 描画したグラフを表示
plt.show()
ニューラルネットワークの定義
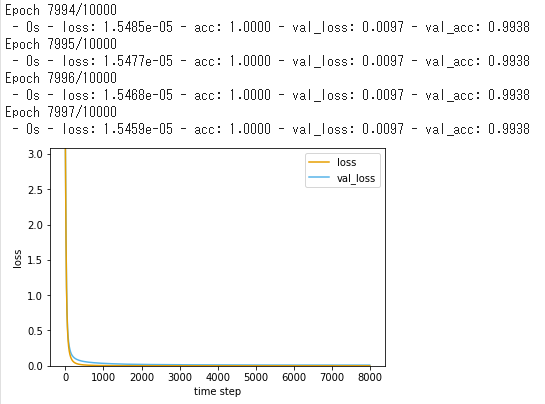
ひとまず、前回までと同じ(※)100個×3層のネットワークでやってみます。
※DropoutをBatchNormalizationにだけ変えてます。
from keras.models import Sequential
from keras.layers import Dense, Dropout, BatchNormalization
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
savefile = 'keras_clf_skldigit.h5'
useSavedModel = False
if useSavedModel == False:
# ニューラルネットワークを定義
model = Sequential()
# 中間層と入力層を定義
model.add(Dense(units=100, activation='relu', input_shape=(n_features,)))
model.add(BatchNormalization())
model.add(Dense(units=100, activation='relu'))
model.add(BatchNormalization())
model.add(Dense(units=100, activation='relu'))
model.add(BatchNormalization())
# 出力層を定義
model.add(Dense(units=n_classes, activation='softmax'))
# モデルのコンパイル
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.0002), metrics=['accuracy'])
# モデルの学習
early_stopping = EarlyStopping(monitor='val_loss', mode='min', patience=1000)
plotHistory(
model.fit(
X_train
,y_keras
,epochs=10000
,validation_split=0.1
,batch_size=n_samples
,verbose=2
,callbacks=[early_stopping]
)
)
# 学習結果を保存
model.save(savefile)
else:
# 学習済ファイルを読み込んでmodelを作成
model = keras.models.load_model(savefile)
予測結果を確認する。
yが2次元配列(データ数×1列)なので、reshape(-1)で1次元配列にして比較します。
y_test2 = y_test.reshape(-1)
# 結果の表示
result = model.predict_classes(X_test, verbose=0)
print('ターゲット')
print(y_test2)
print('ディープラーニングによる予測')
print(result)
# データ数をtotalに格納
total = len(X_test)
# ターゲット(正解)と予測が一致した数をsuccessに格納
success = sum(result==y_test2)
# 正解率をパーセント表示
print('正解率')
print(100.0*success/total)

これでも結構高い正解率のような気もしますが、画像としての性質を生かしたモデルでないと、100%に近い正解率は出ないようです。
CNNのモデルを使ってみる
MNISTのデータで判定するモデルをちょっと変更しています。
元は「MaxPooling2D」をやっていますが、
元の画像が小さいので、これをコメントアウトし、
代わりに「model.add(Conv2D(128, (3, 3), activation='relu'))」をもう一段入れています。
from keras.models import Sequential
from keras.layers import Dense, Dropout, BatchNormalization
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Flatten
X_train = X_train.reshape(-1, 8, 8, 1)
X_test = X_test.reshape(-1, 8, 8, 1)
savefile = 'keras_clf_skldigit_cnn.h5'
useSavedModel = False
if useSavedModel == False:
# ニューラルネットワークを定義
model = Sequential()
# ニューラルネットワークを定義
model = Sequential()
# 中間層と入力層を定義
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(8,8,1,)))
model.add(Conv2D(64, (3, 3), activation='relu'))
#model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(BatchNormalization())
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(BatchNormalization())
# 出力層を定義
model.add(Dense(units=n_classes, activation='softmax'))
# モデルのコンパイル
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.0001), metrics=['accuracy'])
# モデルの学習
early_stopping = EarlyStopping(monitor='val_loss', mode='min', patience=1000)
plotHistory(
model.fit(
X_train
,y_keras
,epochs=10000
,validation_split=0.1
,batch_size=n_samples
,verbose=2
,callbacks=[early_stopping]
)
)
# 学習結果を保存
model.save(savefile)
else:
# 学習済ファイルを読み込んでmodelを作成
model = keras.models.load_model(savefile)
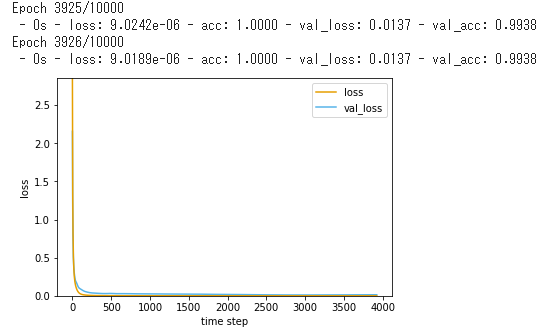

おおむね100%に近い精度が出るようです。
次回
今回のプログラムをTPUを使用する形に変換します。
https://qiita.com/norikawamura/items/dce9225a279874e0b4b2