はじめに
- 自己紹介:UbuntuでPythonを書いてデータ分析とか異常検知してます。
- AutoMLの一つであるNAS(Neural Architecture Search)に興味があります。
- 「Neural Architecture Search研究のベストプラクティス」というpaperを翻訳しました。
- https://arxiv.org/abs/1909.02453
- イイネと思ったらぜひフォロー, thumbs-up&拡散をお願いします!
目次
- イントロ
- コードをリリースする時の3項目
- NAS手法を比較する時の8項目
- 詳細をレポートする時の3項目
- まとめ
イントロ
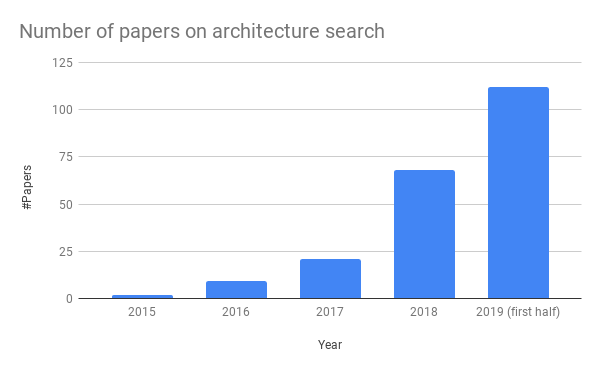
図:NAS論文数の推移
NASはホットトピックですが、AIの他の分野と比べて、実証評価の質は負けています。
再現性を高める為のチェックリストを作りました。
再現性は、分野の持続的な進歩に繋がります!
コードをリリースする時の3項目
①学習パイプラインを公開する
学習パイプラインはNNの構造より精度に寄与する事もある。
・最適化手法
・正則化手法
・学習エポック数
・活性化関数
・学習率調整手法
・Data augmentation手法
なども公開しよう。
②NASのコア部分のコードを公開する
自明。これがないと追試は不可能。
③コードが十分にきれいになるのを待たず、すぐ公開する
「コードが十分にきれいになる」時なんて、永遠に来ない。
NAS手法を比較する時の8項目
①同じデータセット+同じベンチマークを使おう
同じデータセットを使ったとしても、
・探索空間が違う
・最適化手法が違う
・正則化手法が違う
・ハイパラが違う
などの理由で正しく比較できない事がある。
以下のような、一貫したNASベンチマークを使おう!
例1:DARTS (Liu et al., 2019b)と同条件でやる
例2:NAS-Bench-101 (Ying et al., 2019)というベンチマークを使う
②Ablation Studiesをしよう
複数の工夫を適用するなら、一つ抜きで実施してみること。
そうしないと、どれが効いているかわからない。
③同じ評価手法を使おう
自明。
④処理時間-パフォーマンスの関数を作ろう
特定の処理時間におけるパフォーマンスを比較・評価することは非常に大切。
⑤ランダムサーチと比較しよう
baselineと比較することも大事。
探索空間を適切に設計すれば、実はランダムサーチはかなり有効な手法。
⑥結果の評価は何回かやってみよう
確率的手法なので同じ手法&データでやっても同じ結果が返るとは限らない。
NASの実験はお金がかかるけど、最近の手法はそこまででもないから安心。
訳注:CIFAR-10の探索コスト, テストエラー
NAS(Zoph&Le,2016):GPU800台で28日, 2.65%
ENAS(Pham et al., 2019):0.45[GPU台x日], 2.89%
ASNG-NAS(Akimoto et al., 2019):0.11[GPU台x日], 2.83%
⑦tabular benchmarksを使おう
・NAS-Bench-101
・NAS-HPO benchmarks
などのtabular benchmarksは、GPUを使わずにNASの評価ができる!
⑧交絡因子をコントロールしよう
上記の項目以外にも、
・ハードウェア
・ライブラリのバージョン
などで結果に違いが出るので注意しよう。
apples-to-applesで評価すること!
訳注:同じ条件で適切に比較することをapples-to-applesという。
詳細をレポートする時の3項目
①ハイパラ最適化手法をちゃんと書く
「ハイパラ調整まで自動化してこそのNAS」みたいな風潮のせいで、
あいまいにしか書かない人がいるけどNG。
②時間計測はエンドトゥエンドで計測しよう
NASをスタートしてから最終的なNNを返すまでの時間を記録しよう。
例えば、train時に潜在的に学習していたNNをvalidation時に呼び出すモデルで、
validationの時間しか報告しないのはNG。
③実験のセットアップの全てを明示しよう
自明。
まとめ
「再現性は脚光に勝る(Reproducibility is ever more in the limelight)」