はじめに
もしあなたが、データ分析基盤 Microsoft Fabricを使って、データ分析を行い、意図した結果をえるためには、データの正規形(Normal Form)を考えてデータを正規系に加工していくことが必要な場合があります。
データの第4正規形は、多値従属性が複数存在するテーブルを分割して、関連エンティティに含まれる関連は一つだけにしたデータ形式ですが、Microsoft Fabricを使って、こうした正規系のデータ形式にするテクニックを紹介したいと思い本記事を執筆しました。
今回は、データの列と行を入れ替えるテクニックについて紹介します。
1.ケーススタディ
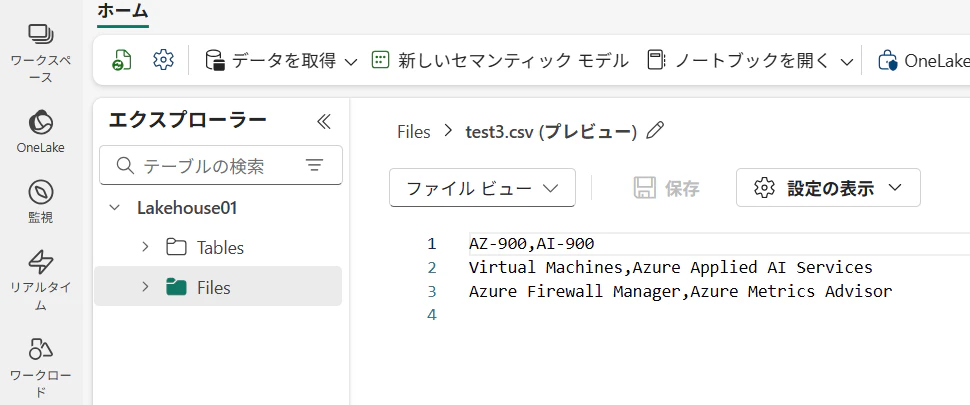
以下のようなデータセットがあるとします。1行目の各列に試験名が入力されており、2行目以降で試験範囲に含まれるサービス・機能名が列挙されているデータセットです。
AZ-900 ,AI-900
Virtual Machines ,Azure Applied AI Services
Azure Firewall Manager,Azure Metrics Advisor
このデータセットに対して、ColumeName列に試験名、Value列にサービス・機能のデータが入り、元のデータセットの列と行を入れ替えるような以下のデータセットに変換することを目標にします。
ColumnName, Value
AZ-900, Virtual Machines
AI-900, Azure Applied AI Services
AZ-900, Azure Firewall Manager
AI-900, Azure Metrics Advisor
2.解決方法
テストデータが入ったCSVファイル(このサンプルではtest3.csv)を例にして、解決する手順を以下に記載します。
1.レイクハウスのエクスプローラーを開いて、Filesのところでメニューを出して、ファイルのアップロードで自分のパソコンにあるファイルをアップロードします。
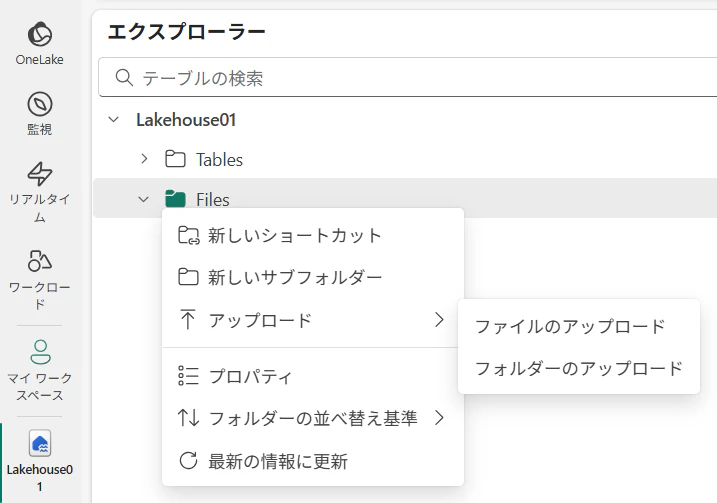
2.アップロードしたファイルの内容を確認します。
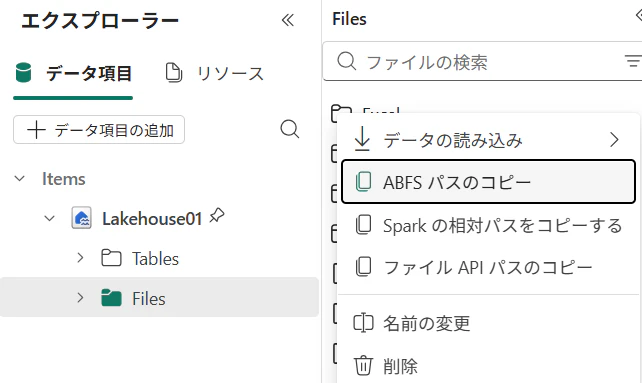
3.この後の手順でレイクハウス上のファイルを読み込ませますが、その時にレイクハウス上のファイルのパスを指定する必要がありますので、ファイルのパスの文字列をコピペしておきます。コピぺをするには、ファイル名のところにカーソルをおき、右クリックして表示したメニューから「ABFSパスのコピー」をクリックします。
4.「ノートブックを開く」をクリックします。
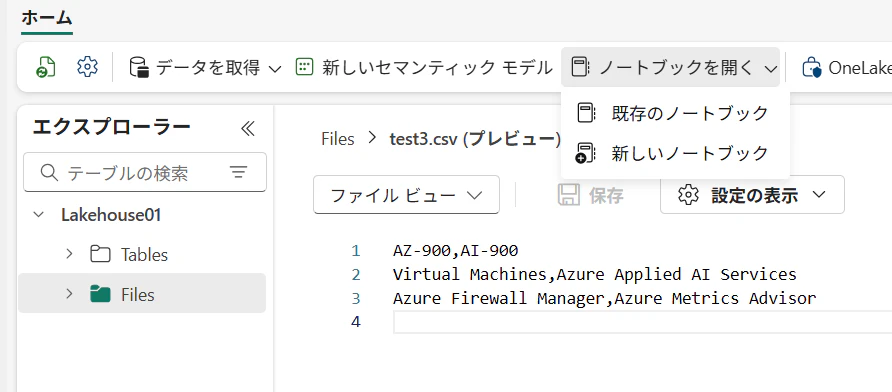
5.ノートブックにPySpark(python)を選択します。
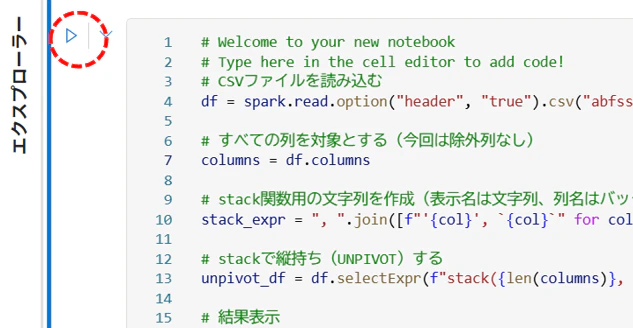
6.ノートブックのコマンド領域に以下のコードを貼り付けます。
df = spark.read.option("header", "true").csv("abfss://{識別子}@onelake.dfs.fabric.microsoft.com/{識別子}/Files/test3.csv")
# すべての列名を取得
columns = df.columns
# stack関数用の文字列を作成(表示名は文字列、列名はバッククォートで囲む)
stack_expr = ", ".join([f"'{col}', `{col}`" for col in columns])
# stackで縦持ち(UNPIVOT)する
unpivot_df = df.selectExpr(f"stack({len(columns)}, {stack_expr}) as (ColumnName, Value)")
# 結果表示
unpivot_df.show(truncate=False)
補足説明
CSVファイルは、3.の手順でコピペしたabfssのパスに置き換えます。
7.コードを実行します。赤丸のアイコンをクリックするとコードが実行されます。
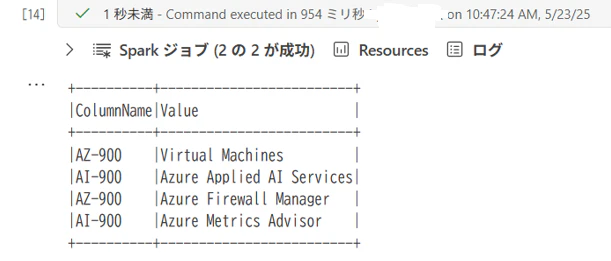
8.上記のコードを実行した例が以下です。
参考
Microsoft社のFabricについての参考ページ
microsoft-fabric
learn.microsoft.com-fabric