はじめに
Unite Tokyo 2019で講演された【Unite Tokyo 2019】中の人がいない!? 音声対話型AIサービスを使ったバーチャルキャラクターの作り方を見ていて、ドコモAIエージェントを使えばLive2Dモデルと簡単に会話できるのでは?と思ったので、やってみました。
2020/8/12よりトライアル環境のAPIが変更されていましたので (詳しくは、デバイス・ユーザ認証について | ドコモAIエージェントAPI – ドキュメントサイトへ) 、更新という形で新たに記事を書いています。
基本的には公式ドキュメントを見れば動かせるようになっていますが、いくつか補足します。
ドコモAIエージェントとは
音声・テキストユーザーインターフェースをパッケージ化した対話型AIのASPサービス。
Live2Dとは
2Dイラストを変形させて立体的に表現することを可能にするソフトウェア。
モーフィング(滑らかに変形して別の状態に変更させる)によって実現する。
手順
基本的には公式ドキュメント( https://docs.sebastien.ai/documents/ )をみて進めていきます。
2020/1現在の手順で進めていますが、今後手順は変更する恐れがありますので公式ドキュメントをみながら補足としてこちら記事を見ることをお勧めします。
ドコモAIエージェントAPIとUnityを連携
SDKの取得
公式ドキュメント( https://docs.sebastien.ai/documents/ )のUnityのダウンロードをクリックします。

GitHub( https://github.com/docomoDeveloperSupport/speak-unity-sdk )からReleasesにある最新のUnity用のSDKをダウンロードしてください。
「SpeakSDK.unitypackage」がSDKになります。
READMEにも記載があるようにユーザーズガイドに沿って、サンプルアプリを動かしてみることにします。
本SDKの利用方法は下記ユーザーズガイドをご確認ください。
Speak Unity SDK User's Guide
サンプルアプリの取得
GitHub( https://github.com/docomoDeveloperSupport/speak-unity-sample )からリポジトリをCloneするかダウンロードして取得します。
READMEに記載されている動作条件に合うように環境を整えます。
Unityのバージョンが異なるとうまく動きませんでした。合っているか注意しましょう。
サンプルアプリを開いたら「SpeakSDK.unitypackage」をインポートします。
別ウィンドウが開きますので全てにチェックがついていることを確認して「Import」ボタンを押下します。
ドコモAIエージェントAPIのセットアップ
GitHub( https://github.com/docomoDeveloperSupport/speak-unity-sample )のREADMEにある利用方法から「Agentcraft_speak_sdk_for_unity_tutorial.pdf」をみていきます。
「3.Agentcraftへの登録・エージェント作成」を見てエージェントを新規作成します。
Agentcraft( https://agentcraft.sebastien.ai/ )にログインして、アカウントを作成します。
エージェントはこのようなサンプルを使いましょう。
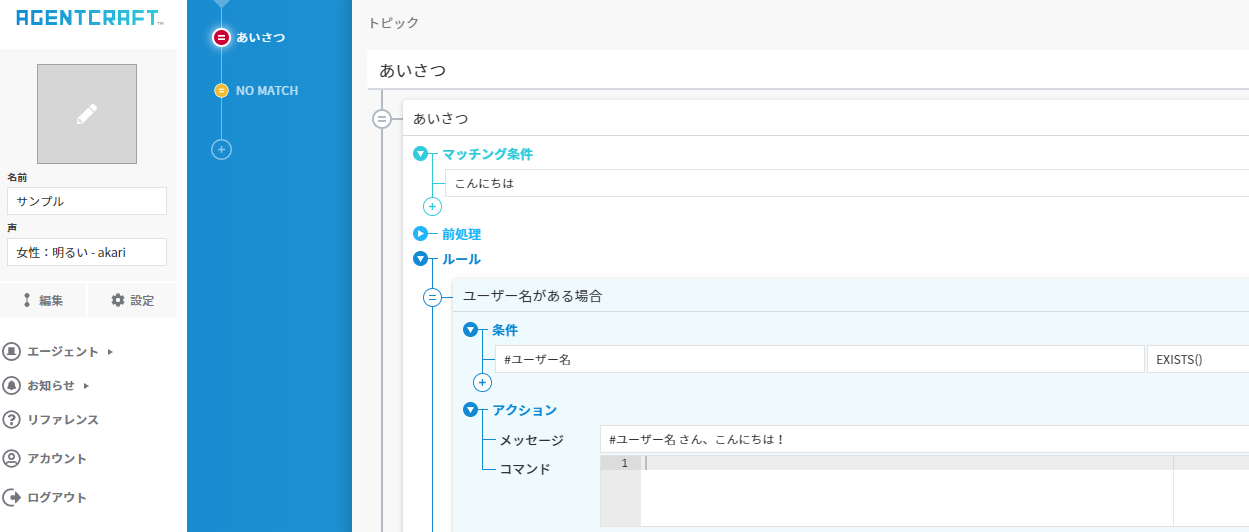
「3.1.Agentcraft利用した認証用トークン作成」を見て認証用トークンを発行します。
今回はトライアル環境で動かしてみるのですが、認証用トークンも必要なので発行します。
Agentcraft( https://agentcraft.sebastien.ai/ )のGUI上で認証用トークンを作成できます。
詳しくは「Agentcraft_speak_sdk_for_unity_tutorial.pdf」を参考人してください。
以前は、デバイスIDをSEBASTIENのUser Dashboard(UDS) ( https://users-v2.sebastien.ai )に登録していましたが、Agentcraftで管理されるようになって楽でいいですね。
「3.2.デバイストークンのセット方法」を見てデバイストークンを設定します。
これでサンプルアプリを動かす準備が整いました。実際に動くかどうか確認してみて音声対話ができてたらOKです。
Live2DモデルをUnityに追加
先ほどのドコモAIエージェントAPIを入れた環境でLive2DモデルをUnityで動かせるようにします。
以下を参考に環境構築をしてください。
Unity初心者がUnityでLive2Dモデルを動かすため環境構築をした
こちらにある桃瀬ひよりのFree版モデルを使います。
mainのSceneにプレハブファイルに追加します。
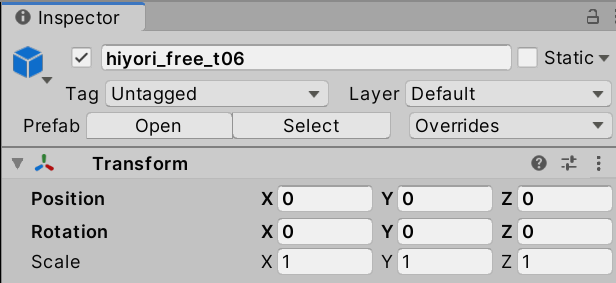
Transformは以下のように設定すればGameビューで見えるようになるはずです。
また、Main Cameraを以下のように設定します。
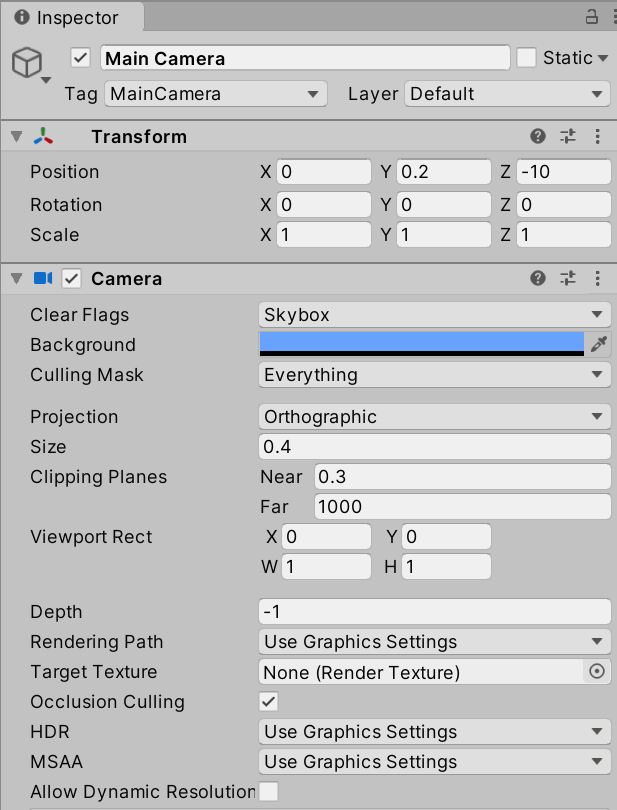
これで環境が整いました。
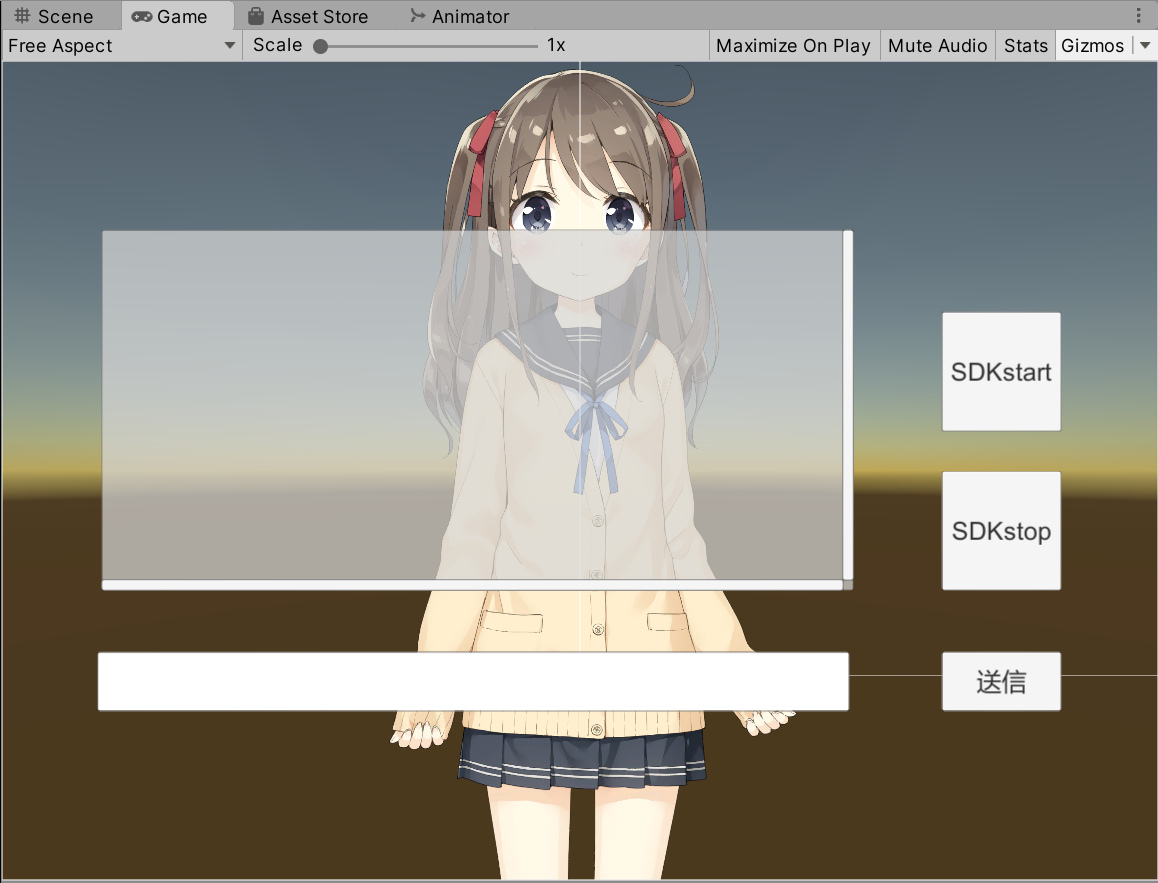
ただこれだとLive2Dのモデルが動かず会話している感がでないので、リップシンクするよう設定します。
[Unity+Live2D]再生する音に合わせてリップシンクするにある「起動時に音声を再生しリップシンクする」のAudio Sourceを作る手前まで手順に従って設定してください。
その後、hiyori_free_t06のCubism Audio Mouth Input (Script)に下記の設定を追加します。
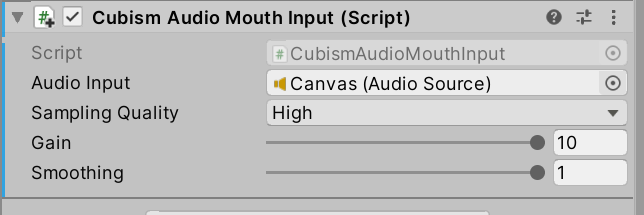
Canvasは下記のCanvasを選択します。
CanvasでドコモAIエージェントAPIに登録した会話の音を再生されるため、CanvasにあるAudioClipの音量を使ってリップシンクします。
これで環境は整いました。
UnityのPlayボタンを押下して、動かしてみましょう。
「SDKstart」を押下した後、マイク入力が可能になるので話しかけてみてください。
「送信」の左にあるブロックに入力して「送信」を押下しても会話ができます。
私の滑舌が残念で、上手く答えてくれないときもありますが、ノンプログラミングで音声入出力をしてくれるのはかなり楽でいいなと思います。
フローチャートで作るので、会話の抜け漏れなく整理して使えそうなのも良さそうです。
ドコモAIエージェントAPIは商用利用は料金が発生します。詳しくは 公式HP( https://docs.sebastien.ai/ )でご確認ください。
感想
UnityEngine.Windows.Speechに定義されている音声認識で同じことをしようとするとコードごりごり書いても実現は難しそうですよね。そう考えるとすごく楽ですね。
フローチャートで会話を作ること自体はAlexaスキルのノンプログラミングサービスに近いものを感じました。
ドコモAIエージェントAPIは、コマンドをJson形式でUnityへ送れるので音声認識と繋げて何かするのにも使えて活用の幅が広がりそうですね。
UnityとAlexa繋がらないかなと思っていたので、それに近しいことができそうな気がしてワクワクしました。