ボットに占いをしゃべらせたい
slack用のボットを作ったので、お試しで投稿させるためにスクレイピングした占いの情報をしゃべらせる。
Gitにレポジトリを作成
手動で、リポジトリを作成する。
今回は、botというリポジトリを作成した。
ローカルのほうscrapyprojectを作成し、初回コミットをする
scrapyのインストール。だいたいこんな感じ
source env3/bin/activate
pip install scrapy
cd /python_projects_folder
scrapy startproject bot
cd bot
gitignoreを作成する
.gitignore
__pycache__
pyc
.idea
project.egg-info
build
git init
git add .
git commit
git remote origin https://github.com/noracorn/bot.git
git push origin master
scraping部分を作成する(spider)
今回はこちらのサイトをスクレイピングさせていただく
fortune.yahoo.co.jp
scrapy genspider uranai fortune.yahoo.co.jp
今回は、射手座、乙女座、蟹座を取得する。
bot/bot/spiders/uranai.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import BotItem
class UranaiSpider(scrapy.Spider):
name = 'uranai'
allowed_domains = ['fortune.yahoo.co.jp']
start_urls = [
'https://fortune.yahoo.co.jp/12astro/cancer',
'https://fortune.yahoo.co.jp/12astro/sagittarius',
'https://fortune.yahoo.co.jp/12astro/virgo',
]
def parse(self, response):
uranai = BotItem()
uranai['sign'] = response.css("#bclst > p > strong::text").extract_first()
uranai['rank'] = response.css("#jumpdtl table table tr")[0].css("td strong::text").extract_first()
uranai['score'] = response.css(
"#lnk01 > div > div > div > div > div > div:nth-child(1) > div > div > p::text").extract_first()
uranai['title'] = response.css(
"#lnk01 > div > div > div > div > div > div.wr.mg10a > div > dl > dt::text").extract_first()
uranai['naiyou'] = response.css(
"#lnk01 > div > div > div > div > div > div.wr.mg10a > div > dl > dd::text").extract_first()
uranai['omajinai'] = response.css(
"#lnk01 > div > div > div > div > div > div.wr.mg15t.mg10h.mg10b > div > dl > dd::text").extract_first()
yield uranai
bot/bot/items.py
# -*- coding: utf-8 -*-
import scrapy
class BotItem(scrapy.Item):
sign = scrapy.Field()
rank = scrapy.Field()
score = scrapy.Field()
title = scrapy.Field()
naiyou = scrapy.Field()
omajinai = scrapy.Field()
WEB_HOOK_URLは、slackで取得したweb_hook_urlを入れること。
bot/bot/pipelines.py
# -*- coding: utf-8 -*-
import requests, json
WEB_HOOK_URL = "https://hooks.slack.com/services/XXX/YYY"
class BotPipeline(object):
def process_item(self, item, spider):
requests.post(WEB_HOOK_URL, data=json.dumps({
'text': u'今日の{}です。\n総合運は{}です。\n\n{}\n{}\n\n開運のおまじないは、{}\n\n'.format(item['rank'], item['score'],
item['title'],
item['naiyou'], item['omajinai']),
}))
return item
bot/bot/settings.py
# -*- coding: utf-8 -*-
BOT_NAME = 'bot'
SPIDER_MODULES = ['bot.spiders']
NEWSPIDER_MODULE = 'bot.spiders'
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 1
ITEM_PIPELINES = {
'bot.pipelines.BotPipeline': 300,
}
XXX部分は、scrapinghubのプロジェクトのデプロイのところを見て、projectのIDを入れる
bot/bot/scrapinghub.yml
project: XXX
stacks:
default: scrapy:1.3-py3
requirements_file: requirements.txt
ローカルで動作確認する
slackに投稿されることを確認する。
scrapy crawl uranai
scrapinghubにデプロイ
以下の、scrapinghubにアカウントを作って、プロジェクトを作成する。
https://scrapinghub.com/
Code & Deploysのところのメニューから、デプロイ手順を実行する
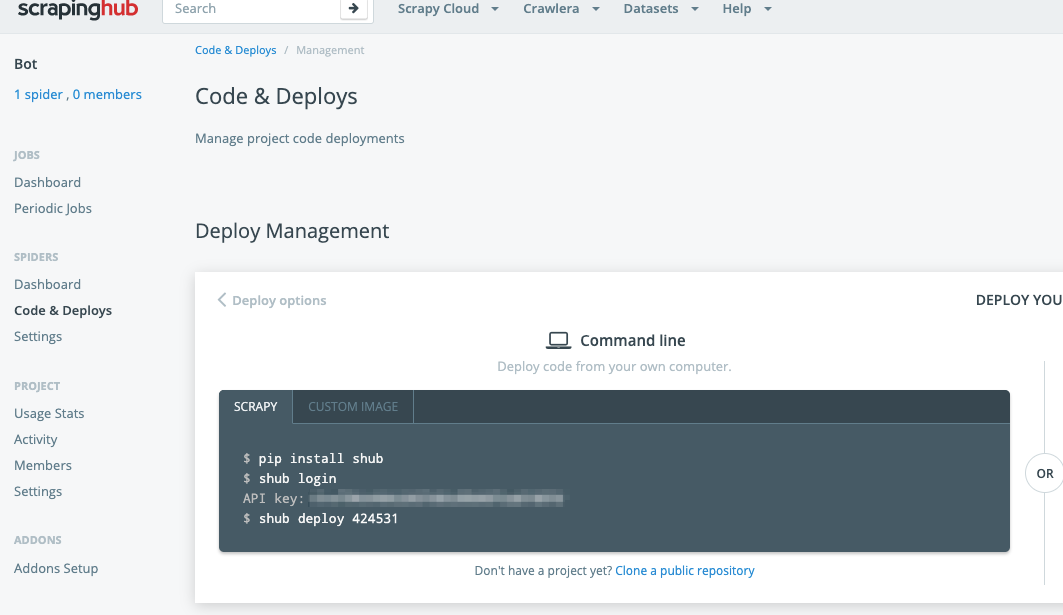
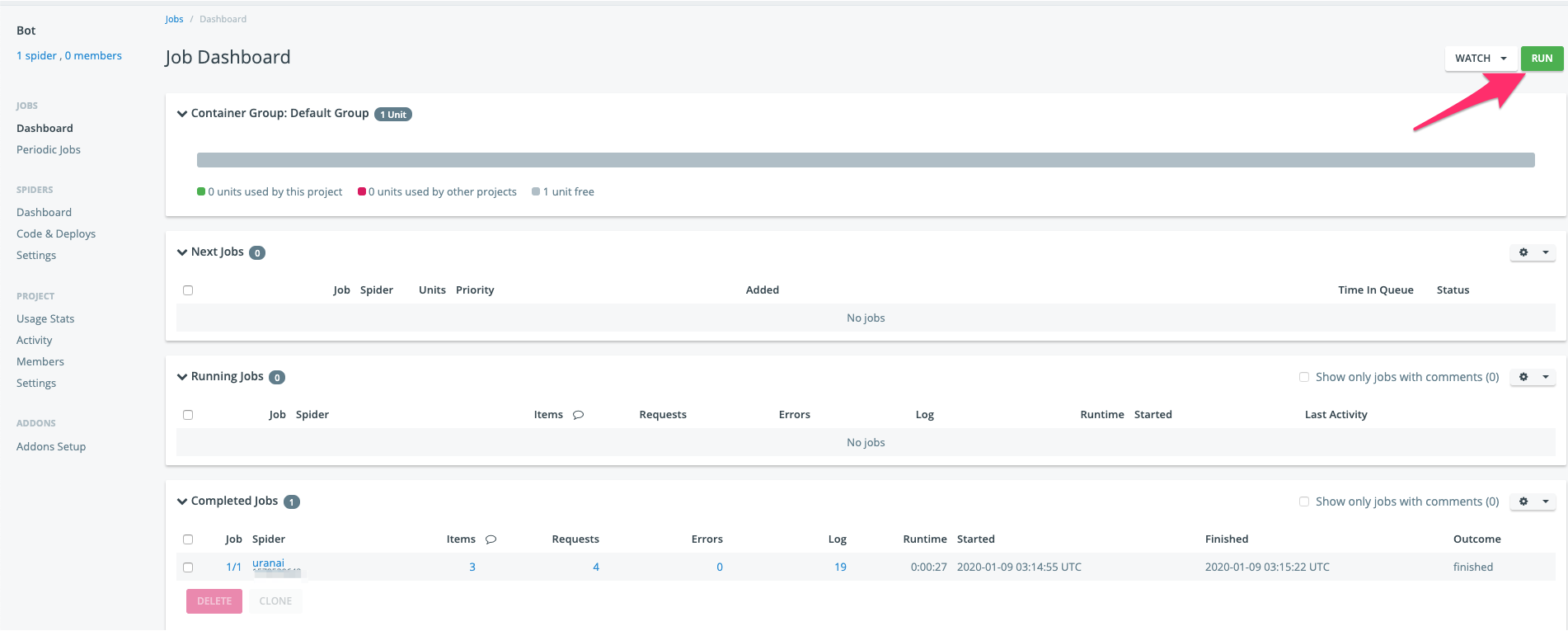
scrapinghubで手動実行で確認する
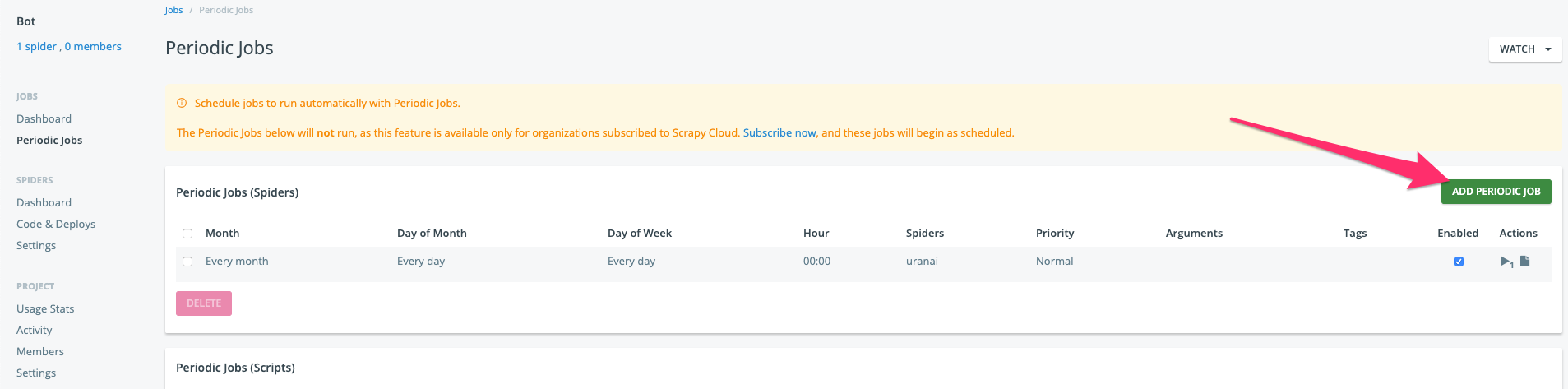
scrapinghubで定期実行で確認する
UTCのため、日本時間と9時間ずれているので、考慮して入れる。