1.ファミリを何とかする(その2)
特許の「ファミリ」、すなわち最初の出願を基礎出願とした外国出願や分割出願をまとめたもの、の取り扱いに関して、評価等何らか作業を行おうとするのであれば、まずはどの特許がファミリに含まれるか?を把握しないといけません。
ファミリの情報は日本特許のファミリであれば日本特許庁の運営している「J-platpat」外国特許のファミリであれば欧州特許庁の「Espacenet」をアクセスして取得できます。
しかしながら特許の件数が増えるとファミリを把握するだけで結構手間がかかってしまいます。今回は日本特許のファミリを把握する作業を少しでも容易にできるような処理方法を紹介したいと思います。
2.今回やろうとしていること
2-1.今回やろうとしていることは「J-platpatで表示させた分割出願のページの、登録番号の情報だけを抜き出す」ことになります。
手作業としては「J-platpatをアクセスして出願番号、公開番号、登録番号のいずれかを入力、分割出願のページを表示させ、登録番号を含むテキストデータをコピペする」ここまでは手作業です(ロボットアクセスは禁止されているため)。
プログラムでは、コピペしたテキストデータから登録番号(「登録」の文字列以降の7桁の数値)を抽出する処理をします。
J-platpatをアクセスして番号入力すると、分割出願があれば、分割出願のページを表示させる以下のようなボタンが表示されるはずです。

「分割」ボタンをクリックすると分割出願の情報が表示されますので、表示されたページのテキストデータを以下のプログラムの「特許情報うんたら・・・」の行にペーストしてください。
正確には単にペーストすると改行コードを含むのでエラーになりますので、ExcelでClean関数をかける等改行コードを除いてペーストしてください。
import re
jplt =["特許情報うんたら登録 7654321かんたら登録 7776665うんたら登録 7654321"]
index =0
for item in jplt: #リストjpltの要素の個数だけループする
patinf = jplt[index]
reglist =[]
patinf_mod = patinf.split('登録')#文字列を「登録」で分割しリストpatinf_modに代入
for smpl in patinf_mod:
smpl = smpl.replace(' ', '')#空白削除
regno = re.search('[0-9]{7}', smpl)#登録番号(7桁の数値(0~9))を抽出
if regno is not None:
reglist.append(str(regno.group()))
fm_mbr='\r\n'.join(reglist)#改行を入れて登録番号を結合
print(fm_mbr)
index += 1
上記プログラムを実行すると変数「fm_mbr」にファミリの登録番号だけを抜き出すことができます。
(複数の登録番号が改行コードで区切られて結合した状態でfm_mbrに格納される)

リストjpltの行(「"・・・",」)を増やせば何件でも一度に変換できます。
jplt =["特許情報うんたら登録 7654321かんたら登録 7776665うんたら登録 7654321",
"特許情報うんたら登録 6665554かんたら登録 5554443うんたら登録 6665554"]
2-2.ちょっと困ったこと
上記のプログラムで特許番号の抽出はできるのですが、分割出願のテキストデータで最初に挙げられている登録番号がテキストデータの中でもう1回出てくるのでだぶりが発生します。
だぶったままでは具合が悪いので、だぶり解消のため最初に挙げられた登録番号は代表登録番号として別の変数(fmly_1)に収めて、残りを変数fm_mbrに収めるようにしました。
import re
jplt =["特許情報うんたら登録 7654321かんたら登録 7776665うんたら登録 7654321"]
index =0
for item in jplt: #リストjpltの要素の個数だけループする
patinf = jplt[index]
reglist =[]
patinf_mod = patinf.split('登録')#文字列を「登録」で分割しリストpatinf_modに代入
for smpl in patinf_mod:
smpl = smpl.replace(' ', '')#空白削除
regno = re.search('[0-9]{7}', smpl)#登録番号(7桁の数値(0~9))を抽出
if regno is not None:
reglist.append(str(regno.group()))
fm_1 = reglist[0]
fm_mbr =""
row = 0
for reg in reglist:
if row > 0:
fm_mbr= fm_mbr + reglist[row] +'\r\n'#改行を入れて登録番号を結合
row += 1
print("fm_1",fm_1)
print("fm_mbr",fm_mbr)
index += 1
以下のように抽出できました。
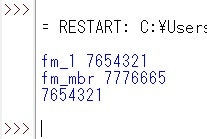
変数fm_mbr内でのだぶりが解消されました。
3.最後に
特許庁ではJ-platpatのアクセスを効率よくするためのAPIを提供していますので、大量に作業するのであればそれを使う方法もあるのですが、ユーザ登録が必要だったりしますので、手早く作業したいときには今回のようなやり方でも良いのかなと思っております。
以上何かのご参考になれば幸いです。