1. はじめに
コロナ自粛の中、東京在住の私は、日々発表される東京都の感染者数に一喜一憂しています。
しかし、その感染者数の数字の増減の根拠がよく分からない!そもそも検査数が日々、大幅に増減していて、また検査にかかる期間も幅があるので、感染者数の増減は、検査数や検査期間によっても左右されているのだと素人ながらに推測してしまいます、
そこで、もう少しわかりやすく数値をグラフ化できないだろうかと思いました。
2. データ取得
東京都 新型コロナウイルス感染症 対策サイト
https://stopcovid19.metro.tokyo.lg.jp/
こちらには東京都のCOVID19のデータが日々更新されています。(若干のタイムラグがあって、1日遅れだと思ってください) このサイトのデータをスクレイピングしてきて、グラフ化の元データにしようと思いました。
取得したいデータは、検査実施人数と陽性患者数です。
検査実施人数
https://stopcovid19.metro.tokyo.lg.jp/cards/number-of-inspection-persons/
陽性患者数
https://stopcovid19.metro.tokyo.lg.jp/cards/number-of-confirmed-cases/
URLから、BeautifulSoupを使って、サイトのデータをダウンロードします。
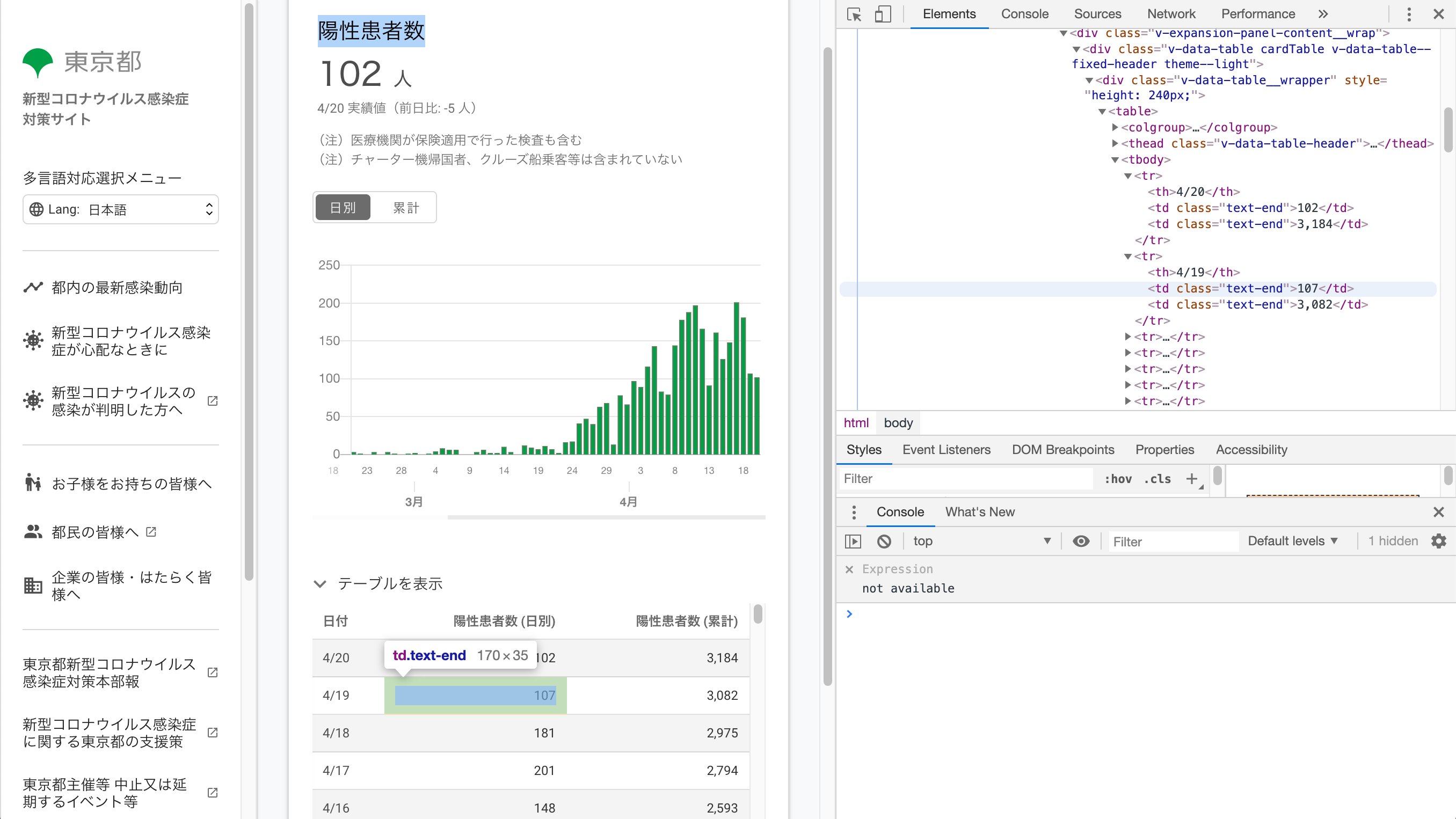
ChromeでURLを開き、デベロッパーツールを表示させましょう。
HTMLのタグを辿っていきながら、目標の数値(陽性患者数)が書かれているタグまで降りていきます。
タグにはクラス(text-end)が設定されていて、このクラスを使ってデータを抜き出していきます。requestsでスクレイピングしたいURL情報をダウンロードし、BeautifulSoupで、その中から、text-endクラスが設定されているタグを全て抜き出して
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
kensa_url = 'https://stopcovid19.metro.tokyo.lg.jp/cards/number-of-inspection-persons/'
yousei_url = 'https://stopcovid19.metro.tokyo.lg.jp/cards/number-of-confirmed-cases/'
r = requests.get(kensa_url , timeout=10, params=None)
soup = BeautifulSoup(r.text,'html.parser')
kensa_data = soup.select('.text-end')
r = requests.get(yousei_url , timeout=10, params=None)
soup = BeautifulSoup(r.text,'html.parser')
yousei_data = soup.select('.text-end')
3. 取得データの処理
抜き出したリストの中身を見てみると、最初の2つはヘッドになっていました。また、日付と累計が交互に保存されているのがわかりました。
使いやすいように必要な部分だけを抜き出してみましょう。
[<th aria-label="検査実施人数 (日別)" aria-sort="none" class="text-end" role="columnheader" scope="col"><span>検査実施人数 (日別)</span></th>,
<th aria-label="検査実施人数 (累計)" aria-sort="none" class="text-end" role="columnheader" scope="col"><span>検査実施人数 (累計)</span></th>,
<td class="text-end">304</td>,
<td class="text-end">8,683</td>,
<td class="text-end">339</td>,
-----以降省略-----
各種データをリストに保存していきましょう。
for i in range(2, len(kensa_data), 2):
を使いヘッドを避けて、リストの3行目からfor文をスタートします。また、2つおきにリストから取り出すことで、日付の数値だけを取り出していきます。
同時に日付も取得していきましょう。ダウンロードした本日をdatetime.today()取得して、for文でデータを取得ごとに1日ずつ日付を戻していきます。
num_listも、表示用についでに作成しておきます。
kensa_list = []
yousei_list = []
date_list = []
num_list = []
num = 0
date = datetime.today()
date = date - timedelta(days=1)
for i in range(2, len(kensa_data), 2):
kensa_list.append(kensa_data[i].string)
yousei_list.append(yousei_data[i].string)
date_list.append(datetime.strftime(date, '%Y/%m/%d'))
date = date - timedelta(days=1)
全てのデータは、時系列が逆になっているので、.reverse()で順番を逆にしておきます。
kensa_list.reverse()
yousei_list.reverse()
date_list.reverse()
4. データの保存
保存する場合は、ここでCSVに保存しておきましょう。
with open('COVID-19.csv','a') as f:
writer = csv.writer(f)
writer.writerow(['date', 'kensa', 'yousei'])
for i in range(len(date_list)):
writer.writerow([date_list[i], kensa_list[i], yousei_list[i]])
4. データの確認
検査実施人数と陽性患者数を確認してみましょう。
plt.subplot(2,1,1)
plt.plot(num_list, kensa_list, label="kensa-list")
plt.legend()
plt.subplot(2,1,2)
plt.plot(num_list, yousei_list, label="yousei-list")
plt.legend()
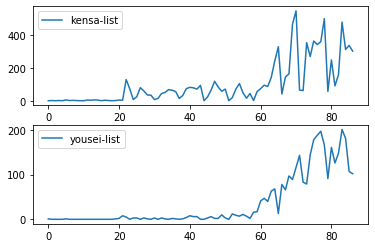
グラフで見てもわかるように検査実施人数が日によって増減が激しく変わっていますね。一見、検査実施人数と陽性患者数と相関関係になってそうですが、80のあたりを見てみると、検査実施人数が大きく下がっていても、陽性患者数の下がり方が不自然な気がします。これは日々の検査数が必ずしも日々の陽性者数に対応していないことからくると思われます。
5. データをわかりやすくする。
そこで、その日までの陽性数の合計を、その日の前日までの検査数の合計で割ったデータを作ってみます。合計のすることで、検査結果の日程に関係なく日々の合計同士の比率でグラフを作ることができます。検査数を前日までに設定したのは、検査即日の結果は陽性者数には反映されていないと思われるためです。
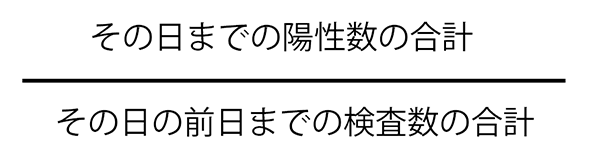
kensa_total = 0
yousei_total = 0
kensa_yousei_list = []
for i in range(len(kensa_list)):
yousei_total = yousei_total + int(yousei_list[i])
if kensa_total == 0:
kensa_yousei_list.append(0)
else:
kensa_yousei_list.append(yousei_total/kensa_total)
kensa_total = kensa_total + int(kensa_list[i])
for文で回しながら、kensa_totalとyousei_totalの合計を足していきます。足しながら、その都度、kensa_totalをyousei_totaで割った値をkensa_yousei_listを追加していきます。
plt.plot(num_list, kensa_yousei_list, label="Average")
plt.legend()
plt.show()
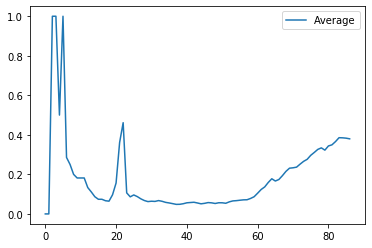
最初の方で、数値が大きく上がっている部分は、データ初期の検査数が0が続いていたためなので、ここは無視してください、後半に向かっていくとともにグラフが右肩上がりになっていますね。これは検査数の中で陽性数の割合が徐々に増えていくのがわかります。陽性者数の経過だけでは、イマイチ本当に要請者の割合が増えているかわかりませんでしたが、こうやって総検査数で割ることで安定したグラフを作成することができ、これを見ることで陽性者の割合も増えていることが判ります。
このグラフを作成した4月21日あたりでは、少し陽性者数が下がってきているので、グラフの最後の方が少し下がっています。
6. まとめ
日々の数値データをそれまでの合計で比率を求めることで、わかりやすいグラフを作成することができました。グラフを見てみると、割ときれいな形で増加していっているのがわかります。また、日々の検査数の増減にも依存しない為、急に数値が増えてびっくりすることもないと思います。(数値が上がるには、その前に検査数が増えなければならない為)
今回のコードは下記で公開しています。
https://github.com/no-B-github/COVID19_Data_Scraping
グラフを日々更新できるようにWebアプリケーションにしてみました。今後はこちらを注視しながら、COVID19の自粛をがんばっていきたいと思います。