CycleGANとは
ICCV 2017のUnpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networksで提案されたGANを用いた、画像スタイルを変換する手法です。著者の公開しているソースコードは参考にせずに、自分で論文を参考にして再現実装をしました。
著者のコードと論文のTraining detailsは見ずに再現実装をしたので、著者の実装とはやや異なるので、ご了承ください。
再現実装において、重要な部分はこの記事で述べますが、細かいところの説明は省きます。
実装したコードはgithubにあげたので、細かいところが気になる方はそちらを見てください。
画像変換とは

上図のように、画像のドメインを変換することを指します。具体的には、絵の画風(スタイル)を変換したり、馬をシマウマに変換することがあります。
CycleGANの強み

CycleGANが提案される以前にも、多くの画像変換の研究がなされてきました。
そのひとつにPix2Pixがあります。
Pix2PixはConditional GANを用いた画像変換の手法で高い精度を誇りましたが、
学習時に変換する画像のセットを上図のようにpaired(1対1)で用意しなければならない欠点がありました。
このような学習データを探すのはとても難しく、データセットの数が少ないことやそもそもデータセットが存在しないこともあります。

このような問題を解決するために、CycleGANは、上図のようにunpaired(不対)な学習データの画像のセットを用いて画像変換をすることを可能にして学習データを集めるコストを大幅に削減しました。
CycleGANの仕組み
CycleGANは3つのステージに分けることができます。2つ目まではよくあるGANのアルゴリズムです。
3つ目のCycle ConsistencyがCycleGANの一番の特徴です。
Fake画像の生成

まずは上図のように、Generatorを用いて本物の画像B(Real_B)から偽物の画像A(Fake_A)、本物の画像A(Real_A)から偽物の画像B(Fake_B)を生成します。Generatorは共有せずに、それぞれGB2A,GA2Bの2つを用意します。
RealかFakeの判定
 次に、元々あるReal画像と生成したFake画像に対してDiscriminatorがRealかFakeどうかを判定します。
ここでも同様にして、Discriminatorは共有せずに、それぞれDA, DBの2つを用意します。
次に、元々あるReal画像と生成したFake画像に対してDiscriminatorがRealかFakeどうかを判定します。
ここでも同様にして、Discriminatorは共有せずに、それぞれDA, DBの2つを用意します。
Cycle Consistency

Cycle Consistencyは、上図のような感じで、AからBに変換して、そのBを変換したらもとのAに戻ってきてほしいということを意味します。自分自身が教師になっているイメージです。
具体的には、ウマをシマウマに変換して、そのシマウマをウマに変換すれば、元のウマになって欲しいということです。
クルクルと行き来しているからCycle(循環)、元に戻ってほしいからConsistency(一貫性)。
そのため、2つ合わせてCycle Consistencyと呼ばれていると思います。
CycleGANでは、以下のようなアルゴリズムでCycle Consistencyを導入しています。

上図のように、Real_BからGeneratorで生成したFake_Aに対して逆のGeneratorを用いてRe_Bを生成します。
Re_BはReal_Bを2回変換したため元のReal_Bに戻って欲しいので、Real_B = Re_BになるようにLossをとります。
Real_Aに対しても、同様な操作をします。
再現実装
GeneratorとDiscriminatorのモデルと学習の仕方の実装について説明します。
Pytorchを用いて実装しました。
GeneratorとDiscriminatorのアーキテクチャ

Generatorは上図のようなモデルにしました。特徴量の表現力をあげるために中間層にResNetのblockを用いました。
そのため、ResNetBlockのクラスを定義して、Generatorのクラスにそれを導入しました。
class ResNetBlock(nn.Module):
def __init__(self, dim):
super(ResNetBlock, self).__init__()
conv_block = []
conv_block += [nn.ReflectionPad2d(1),
nn.Conv2d(dim, dim, kernel_size=3),
nn.BatchNorm2d(dim),
nn.LeakyReLU(0.2),
nn.ReflectionPad2d(1),
nn.Conv2d(dim, dim, kernel_size=3),
nn.BatchNorm2d(dim)
]
self.conv_block = nn.Sequential(*conv_block)
def forward(self, x):
out = x + self.conv_block(x)
return out
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.ReflectionPad2d(3),
nn.Conv2d(3, 64, kernel_size=7),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
ResNetBlock(256),
ResNetBlock(256),
ResNetBlock(256),
nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.ReflectionPad2d(3),
nn.Conv2d(64, 3, kernel_size=7, stride=1, padding=0),
nn.Tanh()
)
self.model.apply(self._init_weights)
def forward(self, input):
return self.model(input)
def _init_weights(self, m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
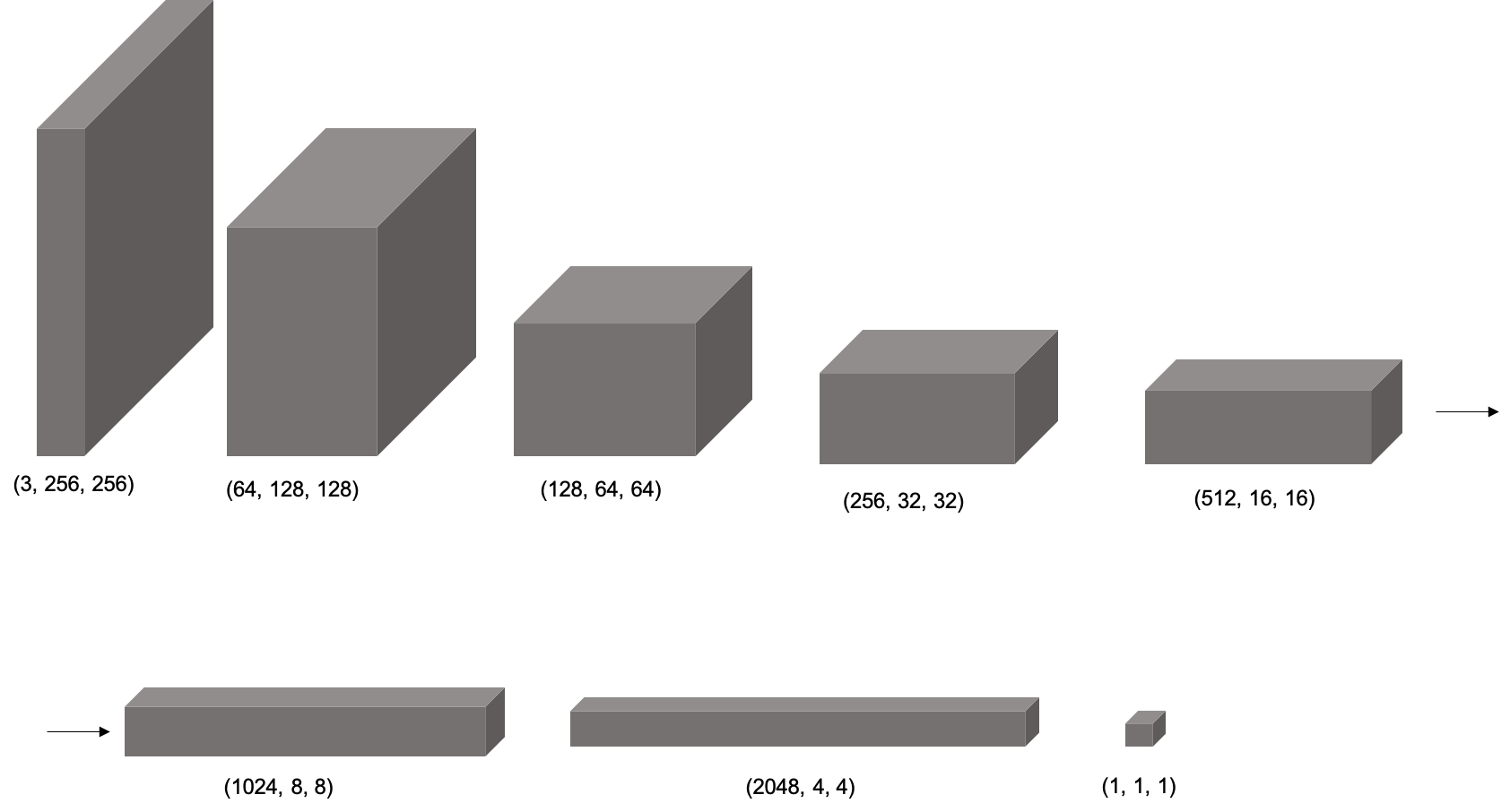
Discriminatorは画像を畳み込んで、最後の層でRealかFakeかどうかの信号を出すように上図のように定義しました。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.nf = 64
self.main = nn.Sequential(
nn.Conv2d(3, self.nf, 4, 2, 1, bias = False),
nn.LeakyReLU(0.2, inplace = True),
nn.Dropout(0.1),
nn.Conv2d(self.nf, self.nf * 2, 4, 2, 1, bias = False),
nn.BatchNorm2d(self.nf * 2),
nn.LeakyReLU(0.2, inplace = True),
nn.Dropout(0.1),
nn.Conv2d(self.nf * 2, self.nf * 4, 4, 2, 1, bias = False),
nn.BatchNorm2d(self.nf * 4),
nn.LeakyReLU(0.2, inplace = True),
nn.Dropout(0.1),
nn.Conv2d(self.nf * 4, self.nf * 8, 4, 2, 1, bias = False),
nn.BatchNorm2d(self.nf * 8),
nn.LeakyReLU(0.2, inplace = True),
nn.Dropout(0.1),
nn.Conv2d(self.nf * 8, self.nf * 16, 4, 2, 1, bias = False),
nn.BatchNorm2d(self.nf * 16),
nn.LeakyReLU(0.2, inplace = True),
nn.Dropout(0.1),
nn.Conv2d(self.nf * 16, self.nf * 32, 4, 2, 1, bias = False),
nn.BatchNorm2d(self.nf * 32),
nn.LeakyReLU(0.2, inplace = True),
nn.Dropout(0.1),
nn.Conv2d(self.nf * 32, 1, 4, 1, 0, bias = False),
nn.Sigmoid()
)
def forward(self, input):
output = self.main(input)
return output.view(-1, 1).squeeze(1)
学習を安定させるために、GeneratorとDiscriminatorの両方にLeakyReLUを使用しました。
同様の理由で、BatchNormを使用しました。
学習の仕方
まずは、AとBについてReal画像とFake画像を用意します。
Fake画像はGeneratorを用いてReal画像から生成します。
real_A = data_train[0].to(device)
real_B = data_train[1].to(device)
fake_A = netG_B2A(real_B)
fake_B = netG_A2B(real_A)
DiscriminatorAの学習
Discriminatorに関してはGAN Lossのみを考えれば良いです。
Aに関するRealかFakeを判定するDiscriminatorAを学習させます。
criterion_GANはBCELossのことを指しています。
本物を見分けるので、Real_Aに対してlabel=1とします。
次に偽物を見分けます。Fake_Aに対してはlabel=0とします。
それぞれ画像を入力とするDiscriminatorのoutputに対してBCELossをとります。
これで、DiscriminatorのGAN Lossは満たされます。
# Discriminator Aの学習
optimizerD_A.zero_grad()
# 本物を見分ける
batch_size = real_A.size()[0]
label = torch.ones(batch_size).to(device)
output = netD_A(real_A)
errD_A_real = criterion_GAN(output, label)
errD_A_real.backward()
# 偽物を見分ける
label = torch.zeros(batch_size).to(device)
output = netD_A(fake_A.detach())#勾配がGに伝わらないようにdetach()して止める
errD_A_fake = criterion_GAN(output, label)
errD_A_fake.backward()
loss_train_D_A_epoch += errD_A_real.item() + errD_A_fake.item()
optimizerD_A.step()
DiscriminatorBの学習
DiscriminatorBに対しても、DiscriminatorAと同様な学習をさせます。
# Discriminator Bの学習
optimizerD_B.zero_grad()
# 本物を見分ける
label = torch.ones(batch_size).to(device)
output = netD_B(real_B)
errD_B_real = criterion_GAN(output, label)
errD_B_real.backward()
# 偽物を見分ける
label = torch.zeros(batch_size).to(device)
output = netD_B(fake_B.detach())#勾配がGに伝わらないようにdetach()して止める
errD_B_fake = criterion_GAN(output, label)
errD_B_fake.backward()
loss_train_D_B_epoch += errD_B_real.item() + errD_B_fake.item()
optimizerD_B.step()
Generatorの学習
Generatorの学習には、GAN LossとCycle Consistency Lossの2つがあります。
GAN Loss
BからAに変換するnetG_B2AとAからBに変換するnetG_A2Bの2つのGeneratorを同時に学習させます。
Generatorは自分が生成したFakeをDiscriminatorにRealと思わせたいので、label=1とします。
先ほどと同様に、それぞれ画像を入力とするDiscriminatorのoutputに対してBCELossをとります。
これで、GeneratorのGAN Lossは満たされます。
# Generatorの学習
optimizerG.zero_grad()
fake_A = netG_B2A(real_B)
fake_B = netG_A2B(real_A)
# GAN Loss
label = torch.ones(batch_size).to(device)
output1 = netD_A(fake_A)
output2 = netD_B(fake_B)
errG_B2A = criterion_GAN(output1, label)
errG_A2B = criterion_GAN(output2, label)
errG = errG_B2A + errG_A2B
loss_train_G_B2A_epoch += errG_B2A.item()
loss_train_G_A2B_epoch += errG_A2B.item()
Cycle Consistency Loss
netG_A2Bが生成したfake_Bに対して、netG_B2Aを用いてre_Aを生成します。
2回変換を施したので、re_A = Aになって欲しいです。(つまり、元に戻って欲しい)
そのため、real_Aとre_AにL1Lossを取れば良いです。
同じ操作をreal_Bに対しても行います。
(ここでは、criterion_cycleがL1Lossとする)
re_A = netG_B2A(fake_B)
re_B = netG_A2B(fake_A)
# cycle Loss
loss_cycle = criterion_cycle(re_A, real_A) + criterion_cycle(re_B, real_B)
loss_train_cycle_epoch += loss_cycle.item()
errG += loss_cycle
errG.backward()
optimizerG.step()
実験結果
データセット
データセットにはmapsを使用しました。
下図のような航空写真とその地図写真の組み合わせのデータセットです。


trainに1096ペア、testに1098ペアあります。
以下、航空写真をA, 地図写真をBとします。
各種パラメータの設定
- 画像のサイズ 256×256
- バッチサイズ 1
- Discriminatorの学習率 両方とも0.000014
- Generatorの学習率 両方とも0.0002
- エポック数 100
- Optimizer Adam
結果
100エポックの学習に丸2日かかりました。

上に示したグラフは、学習時のLossのグラフです。
G_BはAからBに変換するGenerator, G_AはBからAに変換するGenerator, D_AはAがRealかFakeどうかを判別するDiscriminator, D_BはBがRealかFakeどうかを判別するDiscriminator, cycleは2つのCycle Consistency Lossの和を表しています。
G_BのLossが高くなっています。2つのGeneratorはどちらともDiscriminatorよりLossが高くなっています。Cycle Consistency Lossは小さいので、うまく機能していることがわかります。

次に、テスト時のLossのグラフです。学習時と同じようなグラフになりました。過学習が起きてないことがわかります。Bに関しては、学習時よりGeneratorとDiscriminatorのグラフが均衡しています。こちらもCycle Consistency Lossは小さいので、うまく機能していることがわかります。
100エポック目のテスト時に変換した画像を見てみましょう。
成功例
これが変換する前のペア画像です。


これが変換した後のペア画像です。


もう1組見てみましょう。
これが変換する前のペア画像です。


これが変換した後のペア画像です。


どちらのペアもきれいに変換できていることがわかります。
失敗例
これが変換する前のペア画像です。


これが変換した後のペア画像です。


もう1組見てみましょう。
これが変換する前のペア画像です。


これが変換した後のペア画像です。


どちらのペアも画像がうまく変換されていません。特にBの方は全く変換されていません。
考察
綺麗に生成された画像は住宅街の画像が多く、失敗した画像の多くは木や水を含む画像でした。
このことから、住宅や道路などの変換は学習できていますが、森や山や川や海などの自然の変換の学習に失敗していることがわかりました。
また、生成した画像全体にGAN特有のアーティファクトがありました。
失敗した理由1
データセットには、圧倒的に住宅街の画像が多かったので、住宅や道路などの変換を学習するには十分でしたが、自然を含む画像は比較的に少なめでしたので、自然の変換の学習には足りなかったと考えられます。
失敗した理由2
実験で試したデータセットは1種類のみでした。性能を試すには他のデータセットも使用するべきでした。
失敗した理由3
論文のTraining detailsでは、DiscriminatorにPatchGANを使用してました。しかし、自分の再現実装では、普通に画像全てを畳み込んでRealかFakeかどうかの判定をしてしまいました。
失敗した理由4
論文では、Proposed MethodでGANのLossに普通のmin-max optimizationを使っていたので、私も再現実装では、GANのLossに普通のmin-max optimizationを使用していましたが、論文のTraining detailsではLSGANのLossを使用して学習を安定させてました。
失敗した理由5
生成結果を良くするパラメータの調整はやりませんでした。
まとめ
CycleGANの再現実装をしましたが、論文で示されているほどの綺麗な生成画像は生成できませんでした。
DiscriminatorとGeneratorのアーキテクチャが論文と異なることが原因だと考えられます。
しかし、CycleGANの本質であるCycle Consistency Lossを再現実装できて、まあまあな結果が得られたので、自分としてはよかったかなと思います。