機械学習に着手することになった。
その時点で、必要になるツールがある。
その学習をチームとして成功させたてければ、これらのツールをチームとして共有して、開発スキルの上位標準化をする。
データの整合性のチェックツール
データの整合性は、データの整合性を保つための努力をすることなしに勝手に満たされていることはない。
-
データファイルのリスト作成ツール
-
データフォーマットの確認ツール
例:jsonフォーマットの妥当性の確認
自作ライブラリで出力したjsonファイルが、適切なjsonファイルになっていることを確認したかったら、Pydanticを使って読み取れることを確認することだ。
他の巨大なアプリケーションの中では、ファイルフォーマットが間違えたときに、わかりやすいエラーメッセージを出してくれない。 -
画像ファイルが壊れていないこと
-
Git LFS で扱っているファイルが壊れている。
-
orientation情報による画像回転をしていないことを確認する。
データのマージツール
データのマージツールは以下の状況で必要になります。
・アノテーションを1名で実行するのではなくて、多人数で実行する場合
・元のデータが複数のフォルダに分かれている場合
・データを追加する場合
データフォーマットが共通している範囲で、ツールを共有化することです。
COCOのデータセットのデータ形式の場合には、データをマージするためのツールがいろんな場所に既に公開されている。
それらのうち、あなたの用途に適したものを選んで使うのがいいだろう。
pyodi coco merge coco_1.json coco_2.json output.json
https://gradiant.github.io/pyodi/reference/apps/coco-merge/
データの表示ツール
・データのアノテーションの有無がわかるツール
どのデータにアノテーションがあって、どのデータにアノテーションがまだされていないのかを、手作業で確認してはいけません。
フォルダの数が多かったり、階層的なフォルダにデータがあるときには、最新の状況を確認するのに手間取ってしまいます。
データの統計を表示できるツール
データの状況は統計で確認をとることです。
物体検出の場合、それぞれのカテゴリの物体の数がいくつあるか統計を取ります。
アノテーション結果があれば、それらを統計にまとめることは比較的かんたんなはずです。
一つ一つのアノテーションの情報を1行分のデータとして、
それをPandasのDataFrameにすることです。
そうすれば、集計作業とグラフ化の作業が楽にできます。
特徴量エンジニアリングの視点で、データを表示できるツール
学習データのラベリングの状況を確認しよう
ポジティブサンプルのラベリングの状況は確認しやすい。
COCOデータセットを可視化してみた
画像のカテゴリ割合の比較
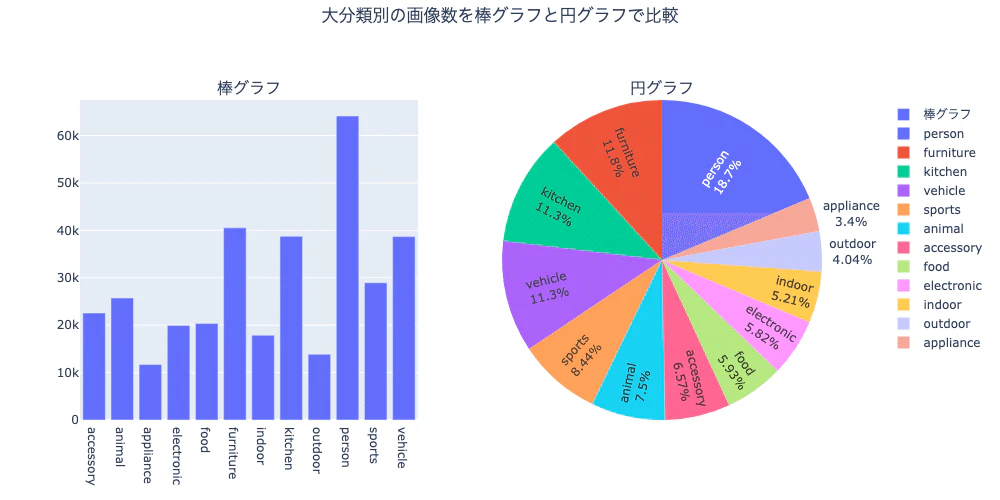
図は、上記のサイトから引用
画像の物体サイズの比較

図は、上記のサイトから引用
評価ツールの例
https://gradiant.github.io/pyodi/reference/plots/evaluation/
https://github.com/Gradiant/pyodi
pyodiの出力する図はgithub のREADME.md の方がわかりやすくなっています。
その評価指標は、目的にそったものになっていますか
評価指標は正しいですか?
歴史の出来事の順序を問う問題があって、正解の順序が
a, b, c, d, e,f だったとしよう。
これを
f, a, b, c, d, e
と答えてしまった場合と
a, f, e, d, c, b
と答えてしまった場合で、どちらが正解に近い状況でしょうか。
ほとんどの試験では、下の方が6点中の2点の正解(a,d)の位置があっているという採点になる。しかし、上では正解と一致する位置がないから0点になる。
しかし、f以外の全ての順序があっているので、本当は上の方が高い値を返すのが本来的にあるべきだと私は考える。
このように、評価指標は、ほんとうに妥当な評価指標になっているのかを疑ってかかることが大切です。
そのアノテーションデータでほんとうに適切ですか?
評価指標の設計は、適切に選択すれば使えるものになるだろう。
しかし、気をつけてほしい。アノテーションデータはほんとうに適切ですか?
- アノテーションルールによっては、ある程度より小さい対象物にはアノテーションをつけていない場合があったりする。
- オクルージョン(隠れ)を生じていることで、検出の難易度が高いデータに対しては、アノテーションがついていないこともあります。
- その場合、検出器の特性が改善すると、アノテーション漏れのために、誤検出が増えた扱いになってしまいます。

MS COCO datasetのフォーマットまとめ から引用。
観客席の多くの人に対してアノテーションがされていないことがわかりますね。
学習結果の評価のツール
誤検出データの表示ツール
(スコア順の表示あり)
未検出データの表示ツール
(スコア順の表示あり)
COCO API
MS COCO のラベリングを見るためのAPI
追記
- 最近、機械学習の評価の評価の自動化に力を入れている。
- 改良しているつもりがほんとうに改良になっているのかどうか
− 弱点はどこに発生してのか - そういったことがわかった方が、学習を改良できる。