機械学習に興味があるあなたのことだ。おそらくMNISTの手書き文字分類の機械学習のデモプログラムを実行したことがあるだろう。
SSII2020 から[限られたデータからの深層学習]
(https://confit.atlas.jp/guide/event/ssii2020/static/lecturenotes#OS)
SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習
SSII2020 [OS2-03] 深層学習における半教師あり学習の最新動向
擬似ラベル:
ラベルづけされているデータで作った学習済みモデルを使って、ラベルづけされていないデータで予測値を出して作ったラベルのこと。
非対称な三叉学習
「同じ推定結果 & 事後確率が閾値以上 →疑似ラベルとして推定結果」
ふむふむ。何も工夫しないで、予測値を出して、それをそのまま学習データにできるほどあまくない。
ドメイン適応:
ドメイン適応(Domain Adaptation)は,転移学習(Transfer Learning)と呼ばれる学習手法の一種です.十分な教師ラベルを持つドメイン(Source Domain,ソースドメイン)から得られた知識を,十分な情報がない目標のドメイン(Target Domain, ターゲットドメイン)に適用することで,目標ドメインにおいて高い精度で働く識別器などを学習します(ここで、ドメイン(Domain)とは,データの集まりを指す言葉です).出典
・Source ドメインの識別エラーを最小化
・ドメイン間の重なりを最大化
そのため、損失関数がclassification loss とDomain Lossの重み付きの和からなるように書き換えられている。
Deep Domain Confusion
SOURCE_NAME = 'amazon'
TARGET_NAME = 'webcam'
source ドメインとtarget ドメイン間でのDomain Loss の値をも小さくするようになっている。
Pytorch のtorch.nn.CrossEntropyLoss()を利用している。
clf_criterion = nn.CrossEntropyLoss()
ここにあるのは画像分類。
Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaptation
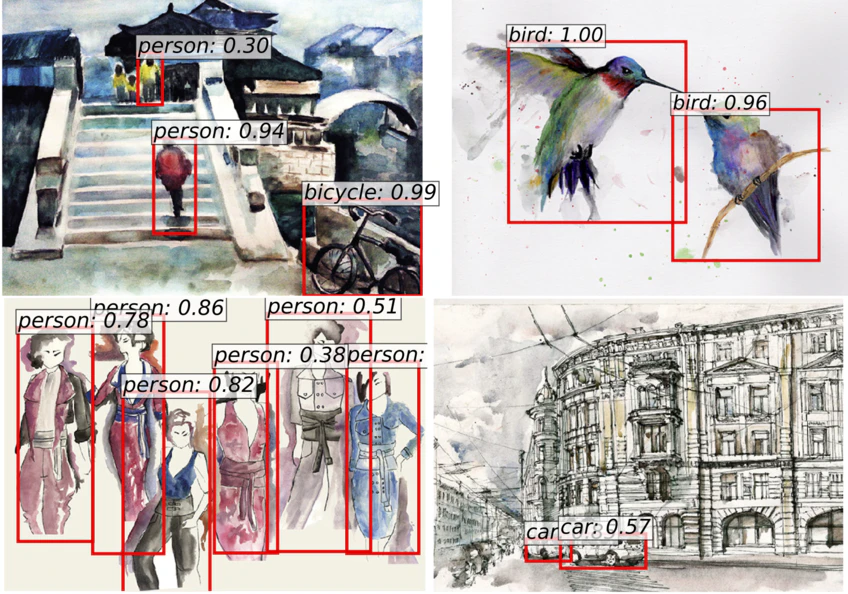
上記の論文のコードのgithub
ふむふむ。
SSD300 というネットワークモデルを使っているようだ。
from chainercv.links import SSD300
...
model = SSD300(
n_fg_class=len(voc_bbox_label_names), pretrained_model='voc0712')
Adversarial Discriminative Domain Adaptation
Strong-Weak Distribution Alignment
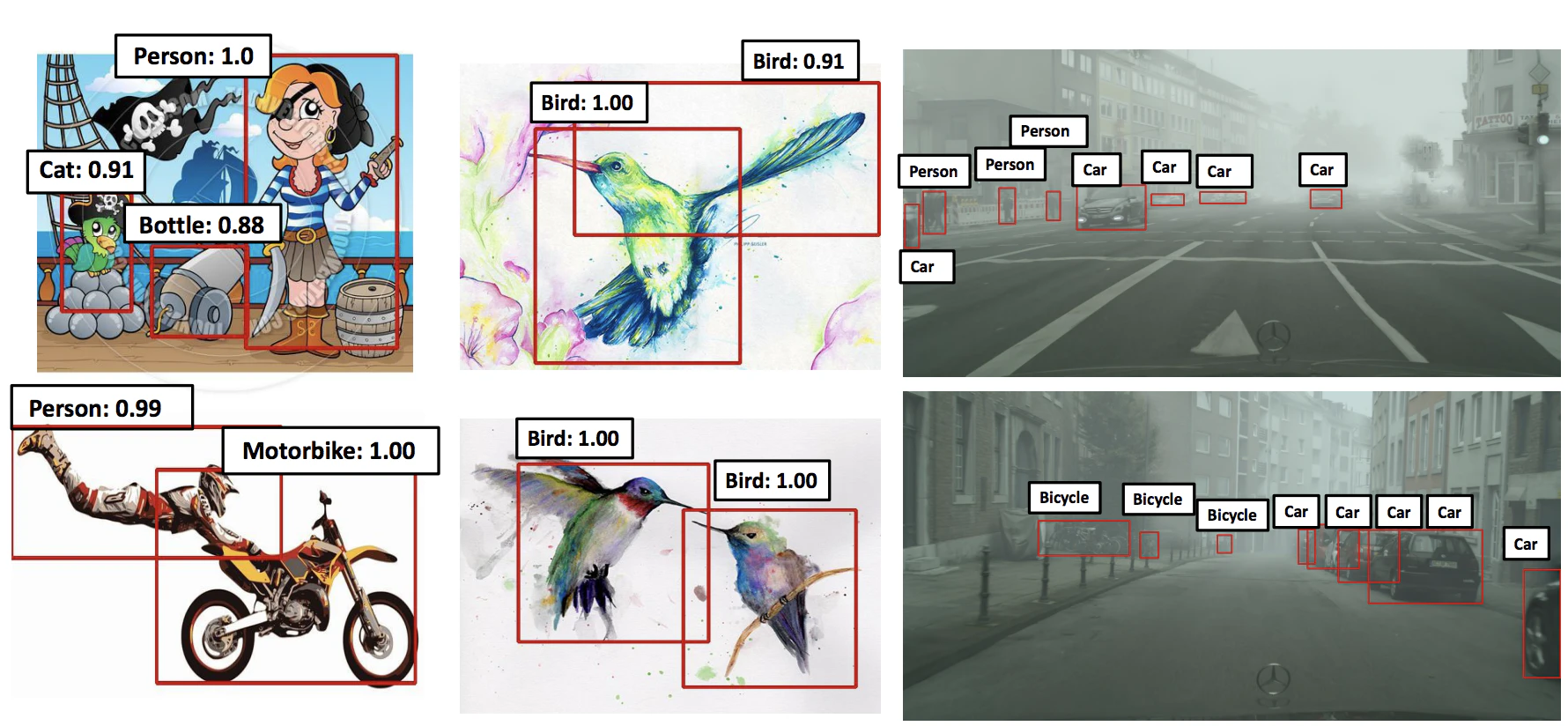
VGG, ResNet101 のネットワークモデル。
github [A Pytorch Implementation of Strong-Weak Distribution Alignment for Adaptive Object Detection (CVPR 2019)]
(https://github.com/VisionLearningGroup/DA_Detection)
consistency regularization
摂動を加えても同一の予測になるように制限を加える。
学習画像の側に摂動が加わるだけでなく、損失関数の中にも変更があるらしい。
https://github.com/lyakaap/VAT-pytorch
https://github.com/takerum/vat_tf
https://github.com/9310gaurav/virtual-adversarial-training
[Source code for STAC: A Simple Semi-Supervised Learning Framework for Object Detection]
(https://github.com/google-research/ssl_detection)
pdf Domain Adaptive Faster R-CNN for Object Detection in the Wild
github Domain Adaptive Faster R-CNN in PyTorch
以下の論文では、暗がりの中の物体検出を、ドメイン適応で改善している。
YOLO in the Dark - Domain Adaptation Method for Merging Multiple Models -
https://github.com/biparnakroy/pseudoLabelGeneratorForYOLO
このリポジトリは、既存のYoloの学習結果を元に、仮のラベルを付けて、さらなる学習を進めるためのものらしい。
追記
以下の情報は、学習をロバストにする手法の1例を示している。
qiita [論文紹介: ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness]
(https://qiita.com/f0o0o/items/eb1e86d11318aeb54109)
追記(2022.11.10)
最近の機械学習の流れとしては、ある程度学習ができている状況で、さらに学習するべきデータをどのようにサンプリングするのかという部分にフォーカスしているらしい。
さらには、CNNでは対応しきれない部分をVisual Transformer で解消しつつあるらしい。