タイトル変更
変更前のタイトル「PapersWithCode でステレオマッチングを調べてみる。」
機械学習分野でのアルゴリズム調査の1例であるので、より多くの人に読んでもらいたいので、タイトルを変更しました。
再度、タイトルを変えました。「PapersWithCodeを使ったアルゴリズム」というように誤読できることに気づいたからです。
はじめに
PapersWithCode は、各種アルゴリズムについて、starの数とpaperのpdf とcodeのgithuh 紹介しているサイトである。
ステレオマッチングの分野は年間に発表されるコードの数が多く、自力での調査が限られる。
そこで、PapersWithCodeを使ってstar の多い実装を調査することにした
この記事の目的
- PapersWithCode を使って、特定のタスクについての最新の実装の状況を見定めるやり方を示すこと。
調査例
paperswithcode stereo matching のキーワードでgoogle 検索すると次のURLが見つかった。

★の数が812個もあってCVPR2023 で採択された論文であることが分かる。
Deep Learning of Partial Graph Matching via Differentiable Top-K
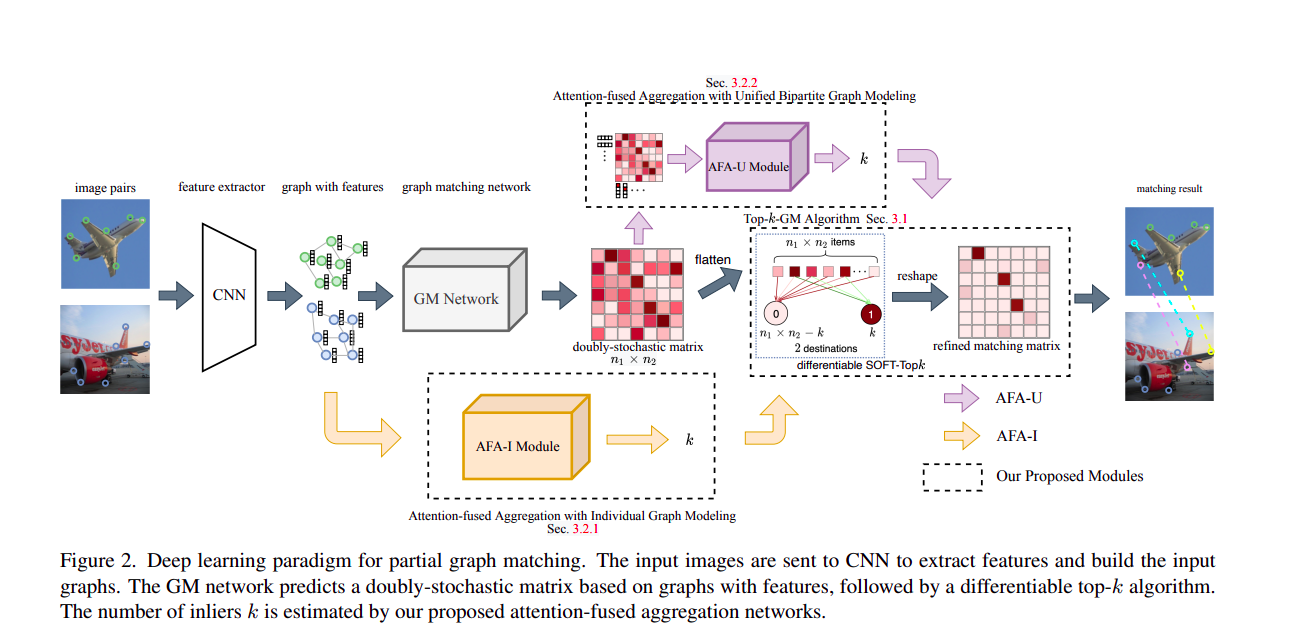
図2. 部分グラフマッチングのための深層学習パラダイム。入力画像はCNNに送られ、特徴を抽出し、入力グラフを構築する。GMネットワークは特徴を持つグラフに基づく二重ストキャスティック行列を予測し、続いて微分可能なtop-kアルゴリズムが実行される。 インライアの数kは、我々の提案する注意融合集約ネットワークによって推定される。
ちがった。これはステレオマッチングではなかった。
次のものは★の数が509個の論文でこれもCVPR2023に採択されている。
Iterative Geometry Encoding Volume for Stereo Matching
リカレント全対フィールド変換(RAFT)は、マッチングタスクにおいて大きな可能性を示している。しかし、全対相関は非局所的な幾何学的知識を欠き、イリーポーズ領域における局所的な曖昧性に取り組むことが困難である。本論文では、ステレオマッチングのための新しいディープネットワークアーキテクチャであるIGEV-Stereo(Iterative Geometry Encoding Volume)を提案する。提案するIGEV-Stereoは、局所的なマッチングの詳細だけでなく、ジオメトリとコンテキスト情報をエンコードする複合ジオメトリエンコーディングボリュームを構築し、視差マップを更新するためにそれを反復的にインデックス化する。収束を早めるために、ConvGRUs反復のための正確な開始点を回帰するためにGEVを利用する。我々のIGEV-Stereoは、KITTI 2015および2012(Reflective)において、全ての公開手法の中でランク付けされ、上位10手法の中で最速である。さらに、IGEV-Stereoはデータセット横断的な汎化が強く、推論効率も高い。また、我々のIGEVをマルチビューステレオ(MVS)、すなわちIGEV-MVSに拡張し、DTUベンチマークにおいて競争力のある精度を達成した。コードはhttps://github.com/gangweiX/IGEV。
DeepL による和訳
MIT License だ。
業務での利用も可能だ。
出力がdisparity(視差)もしくはdepth(深度)データであることを確認しよう。
動作環境を確認する。
NVIDIA RTX 3090
Python 3.8
Pytorch 1.12
とある。
Cudaが使える環境だとなんとかなりそうだ。
Pretrained models can be downloaded from google drive
リンクをたどるとPretrained model がgoogle driveからダウンロードできる。
ブラウザからダウンロードできる。
gdown コマンドを使えば、シェルスクリプトやDockerfile の中でダウンロードができる。
gdown --fuzzy --folder https://drive.google.com/drive/folders/1yqQ55j8ZRodF1MZAI6DAXjjre3--OYOX?usp=drive_link
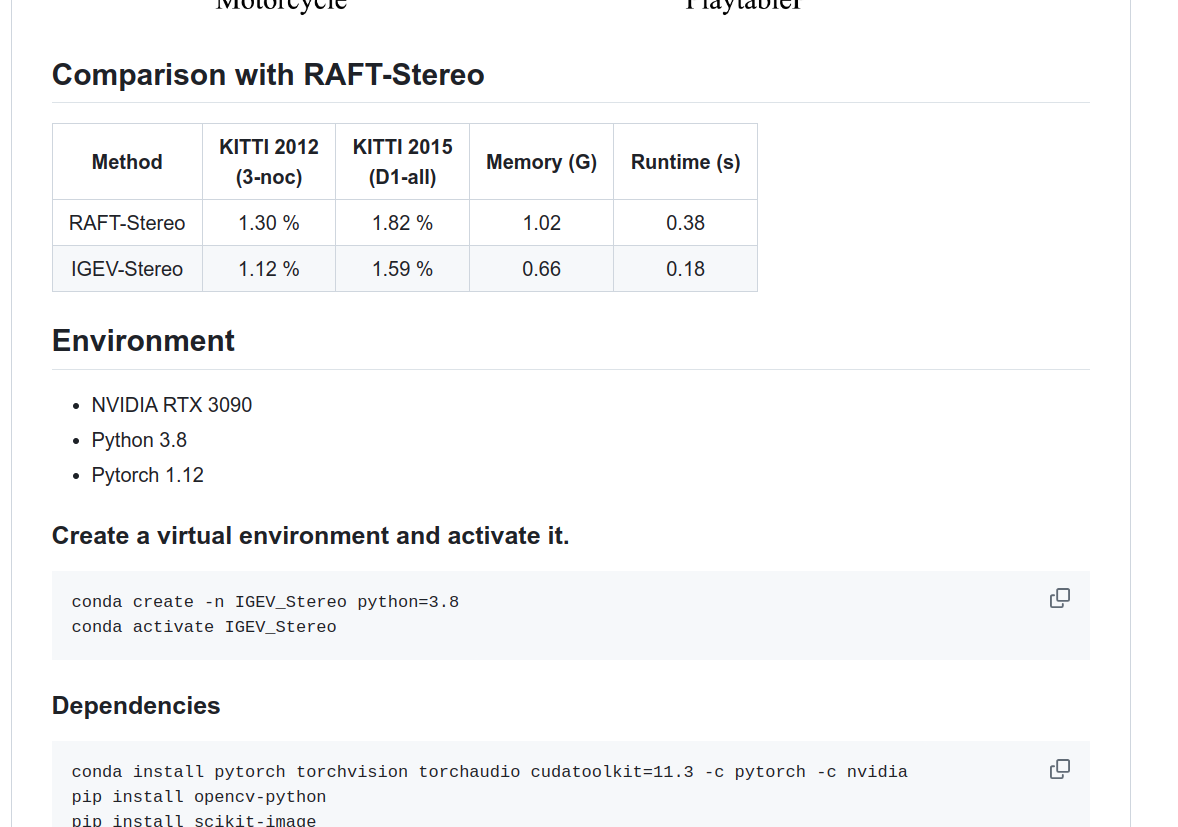
使用するメモリ量や動作環境での実行速度が示されている。
Demosには、画像ペアを指定することで、結果を表示する例、動画を入力として結果を表示する例とが予め準備されている。
python demo_imgs.py \
--restore_ckpt pretrained_models/sceneflow/sceneflow.pth \
-l=path/to/your/left_imgs \
-r=path/to/your/right_imgs
python demo_video.py \
--restore_ckpt pretrained_models/sceneflow/sceneflow.pth \
-l=path/to/your/left_imgs \
-r=path/to/your/right_imgs
自分の用途に対して十分な状況だろうか
- 2023、2024年の時点の実装は、数年前の実装に比べて性能が向上している可能性が高い。
- 対応点がとれない画素に対しても、欠損点ではなくdisparity(視差)が算出されている。
- 細かい領域に対してもdisparity(視差)が適切に導出されている。
未確認の項目
- 透明物体(例:ワイングラス)での視差の算出
- 反射があって映り込みがある物体での視差の算出
- 前景の物体と背景との境界でのartifactの有無
これがあると、物体の3次元領域の切り出しに影響します。
ないに越したことがありません。
他の実装を調べてみる。
その論文の中で比較しているのは、著者がその時点で一番良いと思っているはずの実装だ。
RAFT-Stereo
pdf RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching


みてごらん、これだって、こんなにいい結果になっている。
GPUの種類の制約、画像の大きさの条件、フレームレートと遅延時間の方が重要だったりはしないか、
bestではなくacceptable を目指そう
- 最新の実装の全てを調査することはできない。
- 利用目的の範囲で十分な実装になっていれば、それで十分だろう。