透明物体のDepthの推定について、さらに調査中
以下のものは、Depthの推定を実施していなかった。
Keypointの3Dの復元をするものでしかなかった。
StereoLabsのZEDカメラを利用している。
KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects
pdf KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects
github https://github.com/google-research/google-research/tree/master/keypose
KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects

机上の物体の3Dポーズを推定することは、ロボット操作などのアプリケーションにとって極めて重要である。この問題に対する既存の多くのアプローチは、学習と予測の両方に物体の深度マップを必要とするため、RGBDセンサで良好なリターンを生成する不透明でランバートな物体に制限される。本論文では、深度センサーを使用せず、生のステレオ入力を使用する。第二に、KeyPoseと呼ばれるディープニューラルネットワークを開発し、ステレオ入力から、3Dキーポイントを用いて物体のポーズを正確に予測することを学習する。本手法の性能を評価するために、5つのクラスに分かれた15個の透明な物体からなるデータセットを作成し、48Kの3Dキーポイントラベル付き画像を用意した。インスタンスモデルとカテゴリモデルの両方を訓練し、新しいテクスチャ、ポーズ、オブジェクトに対する汎化を示す。KeyPoseは、このデータセットの3Dポーズ推定において、1.5から3.5のファクターで最先端の性能を上回る。このパフォーマンスにはステレオ入力が不可欠であり、単眼入力を使用した場合よりも2倍向上する。我々は、データキャプチャとラベリングパイプライン、透明オブジェクトデータベース、KeyPoseモデルと評価コードのパブリックバージョンを公開する予定である。プロジェクトのウェブサイト:https://sites.google.com/corp/view/keypose.
DeepLによる翻訳
興味深い点:
- 似た形状の透明ではない物体と透明な物体とを用意して撮影している。
Youtube
KeyPose: 立体イメージから透明な物体の 3D 姿勢を推定する

)
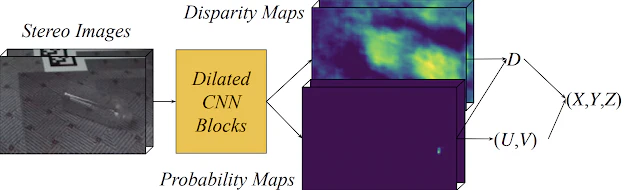



利用しているカメラ
Hardware specifications
for the ZED are at https:
//www.stereolabs.com/zed/,
and for the Kinect Azure are in
https://docs.microsoft.com/en-us/azure/kinect-dk/
hardware-specification.

背景となるテクスチャはFig 17 のとおり。
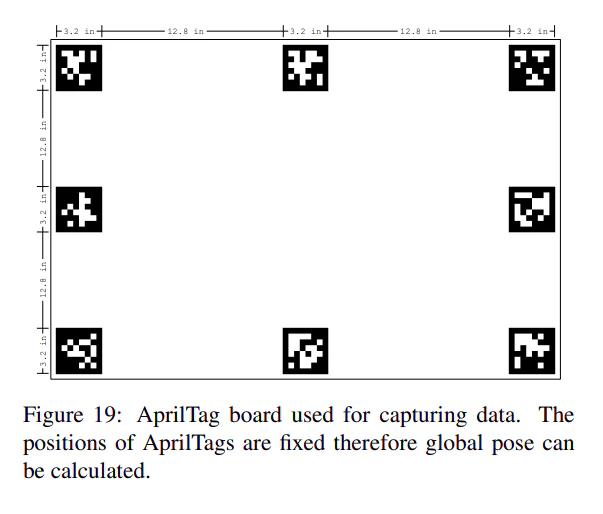
Fig 19の配置をAprilTagを8箇所使用している。このため、カメラの位置と姿勢が決定されやすい。
keyPose の実装にあるサンプルデータ
000001_L.png
000001_R.png
000001_L.pbtxt protocol buffers のデータのテキストファイル
000001_R.pbtxt
000001_border.png
000001_mask.png
私見
- depthの算出もしてくれていればなあ