Seeing Glass: Joint Point-Cloud and Depth Completion for Transparent Objects
github https://github.com/pairlab/TranspareNet
dataset Toronto Transparent Object Depth Dataset
多くのオブジェクト操作アルゴリズムの基本はRGB-D入力である。しかし、汎用的なRGB-Dセンサーは、光の屈折と吸収により、広範囲の透明オブジェクトに対して歪んだ深度マップしか提供できない。透明オブジェクトがもたらす知覚の課題に取り組むために、我々は、点群および深度補完の共同手法であるTranspareNetを提案する。既存の透明物体データ収集スキームの欠点に対処するため、ロボット制御による画像収集と視覚ベースの自動アノテーションからなる自動データセット作成ワークフローも提案する。この自動化されたワークフローを通して、我々は15000枚近いRGB-D画像からなるトロント透明物体深度データセット(TODD)を作成した。 我々の実験的評価では、TranspareNetがClearGraspを含む複数のデータセットにおいて、既存の最先端の深度補完手法を凌駕すること、またTODDで学習した場合、乱雑なシーンも処理できることを実証している。コードとデータセットは https://www.pair.toronto.edu/TranspareNet/ で公開される予定です。
DeepLによる翻訳です。

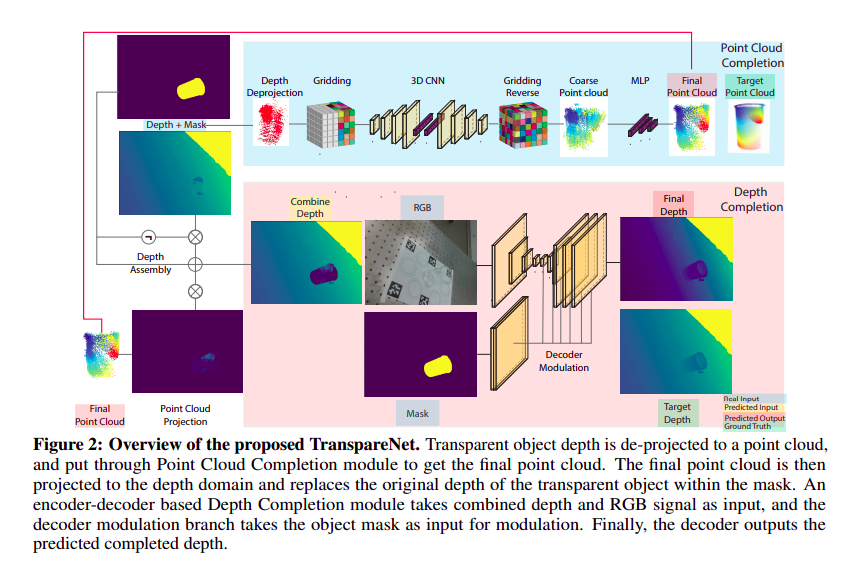
図2:提案するTranspareNetの概要。透明オブジェクトの深度は点群にデプロジェクションされ、最終点群を得るために点群補完モジュールにかけられます。最終的な点群は深度領域に投影され、マスク内の透明オブジェクトの元の深度を置き換えます。エンコーダ-デコーダベースの深度補完モジュールは、結合された深度とRGB信号を入力として受け取り、デコーダ変調ブランチは、変調のための入力としてオブジェクト・マスクを受け取ります。最後に、デコーダは予測された完成深度を出力する。
DeepLによる翻訳です。
Q: 透明物体に対するマスク画像は、どのようにして得るのだろう。
それができない限り、完全に自動でdepthを算出することができないと思うのだが。
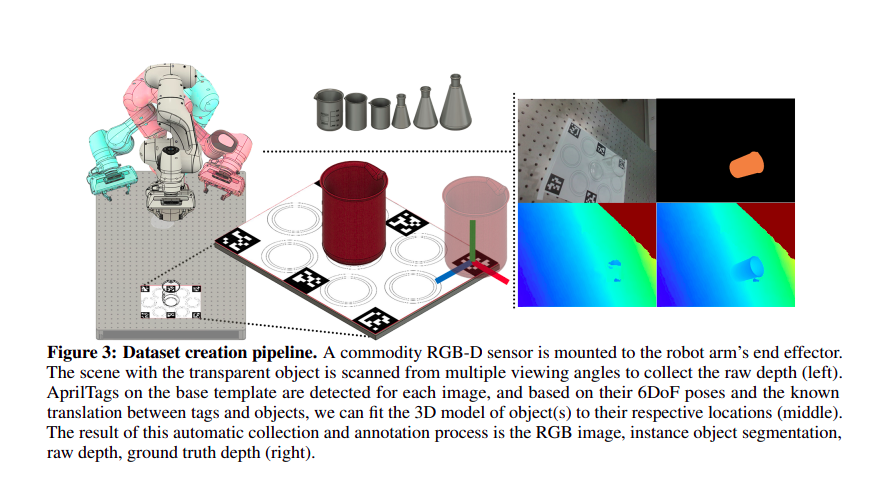
データセット作成パイプライン。汎用RGB-Dセンサーをロボットアームのエンドエフェクターに装着。 透明な物体があるシーンを複数の視野角からスキャンし、生の深度を収集する(左)。 ベーステンプレート上のAprilTagsが各画像について検出され、その6DoFポーズとタグとオブジェクト間の既知の並進に基づいて、オブジェクトの3Dモデルをそれぞれの位置にフィットさせることができます(中央)。 この自動収集と注釈付けプロセスの結果が、RGB画像、インスタンスオブジェクトセグメンテーション、生の深度、真値の深度(右)である。我々の手法は、データセット作成とアノテーションのための自動化されたパイプラインにより、データセット収集のために以前の手法が使用していた手作業を克服している。
DeepLによる翻訳です。


Fig.5 に示される例では、データセットによって画像データの撮影条件が違う。
右側の2つには、マーカーが貼られている。
左上の例では、床面にテクスチャがないので、ガラスを透過したことによる影が明瞭である。
右上の画像では、フラスコに色水が入っている分だけ、透明な液体が入っている場合よりも扱いやすくなっていそうである。


左から順に
RGB 画像
RBG-Dセンサからの生のDepth
PCC 予測のdepth
DC 予測のdepth
TranspareNet予測のdepth
真値のdepth
トロント透明オブジェクト深度データセット(TODD)
トロント透明オブジェクト深度データセット(TODD)
TODD(Toronto Transparent Objects Depth Dataset)には、5つの異なる背景に6つのガラスビーカーとフラスコを含む14,659のシーン画像がある。4つのオブジェクトがトレーニングセットに使用され、他の2つの新しいオブジェクトが新しい検証セットとテストセットになります。学習セットには10,302枚の画像があり、検証セットとテストセットを合わせた画像は4357枚である。すべてのシーンはオクルージョンを持つ最大3つの透明オブジェクトで構成され、データセットにさらなる複雑さをもたらす。オブジェクトとその配置は、現実の透明なガラス食器を模倣するように選択されており、透明な容器を操作できる視覚認識ロボットの開発に役立つ。
https://www.pair.toronto.edu/TranspareNet/ の中の説明をDeepLの機械翻訳
私見
- ビーカーとフラスコだけでいいの?
- どうやったら、汎用的に使用できる学習になっているかわかるの?
dataset の例
1ショットについて以下のデータがある。depthは8bit深さでは収まらないため,exrファイルを用いている。
instance_segment.png はRGB画像で、人の目でみて区別しやすいようになっている。
apriltag.pkl
depth.exr
detph_GroundTruth.exr
image.jpg
instance_segment.png
pose_type.json
pose_type.jsonには
以下のように射影行列を含んだものになっています。
{"0": {"pose": [
[0.5920793162654716, -0.01069925101679558, 0.8058086679096294, 0.07380988679297365],
[-0.4298675609679924, 0.8415866899360739, 0.3270255698716417, -0.0738569653014021],
[-0.6816567782088292, -0.5400160824921072, 0.49368681101669787, 0.366816166944394]],
"type": 2}}
apriltag.pkl はapriltagのマーカーに関する量をpickle で保存したファイル。
インストール
以下のgithub から git clone してインストールできます。
https://github.com/pairlab/TranspareNet
python3 -m pip install -r requirements.txt
を参考にします。
足りないものがあれば、随時apt installや pip installを行なってください。
apt-get install -y libhdf5-serial-dev libhdf5-dev
apt install libopenexr-dev zlib1g-dev openexr
apt install -y clang-format
apt install -y p7zip-full
などが必要かもしれません。
bit深さの深い画像である.exrファイルを使うのにはopenexr, OpenEXR, pyexr などが必要になります。
cmake でのbuildの際には clang-formatを前提としています。
データセットは7z 形式で用意されていましたから、7zip-full も入れておきます。
cudaで書かれたモジュールのbuild
./TranspareNet/grnet_point_cloud_completion/extensions/*/setup.py
にsetup.pyがある。
それぞれのディレクトリで
python3 setup.py install
を実行します。
そうすることで、grnet_point_cloud_completion/extensionsの下のモジュールが利用できるようになりました。
AprilTag とは
- https://april.eecs.umich.edu/software/apriltag
- https://jp.mathworks.com/help/vision/ug/camera-calibration-using-apriltag-markers.html
- https://qiita.com/Karin-Sugi/items/7678b3a0cc7b80e45940
Automated Dataset Collection
Intel RealSense を使ってデータ・セットを収集するためのヒントが書かれている。
https://github.com/pairlab/TranspareNet?tab=readme-ov-file#automated-dataset-collection
付記
TranspareNet は tranparent のタイプミスとして検索エンジンで自動変換されてしまうようで、
検索で既に知っているURLでさえヒットしない。
pre-trained checkpoint modelはどこだ?
残念なことにpre-trained checkpoint model をまだ見つけることができていません。
そのため、自分の環境で、推論を実行するにいたっていません。
利用しているライブラリ
https://github.com/SamsungLabs/saic_depth_completion
saic_depth_completionのモジュールを利用している