物体検出の精度を上げていこうとすると、検出した領域での属性推定がほしくなる。例、顔検出の精度を上げていこうとすると、マスクをつけた人の画像も欲しくなる。髪の毛が前に垂れていて眼の領域を隠している画像も欲しくなる。マスクの有無判定、眼領域オクルージョンの有無の判定が欲しくなる。
Autoencoder
オートエンコーダ(自己符号化器、英: autoencoder)とは、機械学習において、ニューラルネットワークを使用した次元圧縮のためのアルゴリズム。2006年にジェフリー・ヒントンらが提案した。オートエンコーダ
autoencoderで符号化されたベクトルを利用して、属性推定に利用することができる。
こうした考えに基づく初期の研究では,Neural Network を用いて複数属性を認識する手法が挙げられる.Cottrell ら [117] は,現在使われている Autoencoder に相当する特徴抽出用のNeural Network を用いて学習した顔画像特徴量を元に,識別用の Neural Network によって顔,感情,性別の認識を行っている.
それぞれの属性認識器で認識した結果を元に,それらの結果を統合して最終的な属性認識結果を再計算したり,別の属性を求めるアプローチとしては,属性認識器の出力結果を特徴量として分類する手法 [73] や,Bayesian Network を利用したものが挙げられる。
[サーベイ論文:画像からの歩行者属性認識] (https://www.vislab.is.i.nagoya-u.ac.jp/~murase/pdf/1300-pdf.pdf)
autoencoderを用いて属性推定を行うことは、入力画像から属性推定すること、属性推定の結果から画像を生成する(生成画像と入力画像の差分を小さくする)処理の一部だと考えられる。
仮説:autoendcoderと属性推定込みの物体検出とを構築することは、物体検出だけを学習させるよりも、精度の高い検出を実現する。
判断の理由:
- 属性のラベリングをすることは、検出枠の情報だけを与えることよりも多くの情報を与えて検出の学習をさせていることになる。
- 例: 顔の検出に対して、マスクの有無の属性を付与する。
- マスクありの属性があれば、鼻や口に由来する特徴量がなくても顔検出を判定できることに確証を与える。
- マスクありの属性の有無は、本来なら鼻や口が見える領域に、マスクらしいもので覆われている場合に、その特徴量を学習して判定することを可能にすると見られる。
属性推定を物体検出に付随して実行することは、そんなに難しくないはずだ。
歩行者の属性推定の実装の1例
github https://github.com/dangweili/pedestrian-attribute-recognition-pytorch
- 学習用のデータのダウンロード 上記のリポジトリのREADME.md に記載がある。
- 学習の手順 https://github.com/dangweili/pedestrian-attribute-recognition-pytorch/blob/master/script/experiment/train.sh の実行
Multi-attribute Learning for Pedestrian Attribute Recognition in Surveillance Scenarios
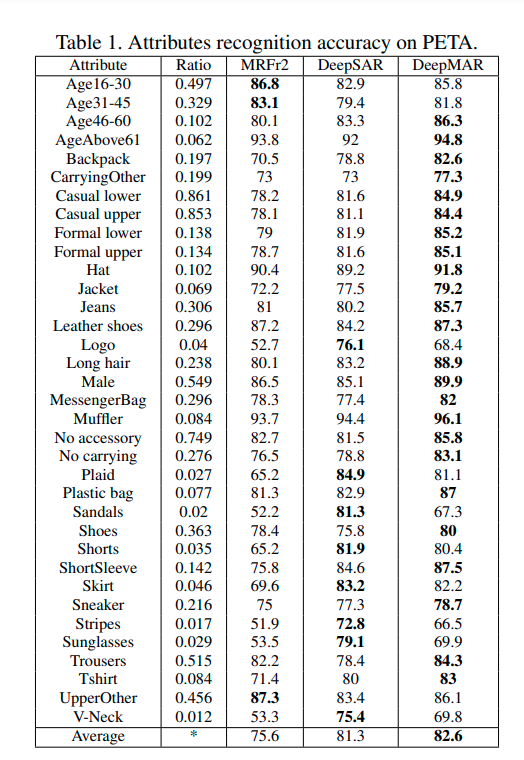
図 上記の論文中にある属性認識の属性
PETA dataset Pedestrian Attribute Recognition At Far Distance
github HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
pdf
以下のgithub Pedestrian-Attribute-Recognition-Paper-List
を読むことで、最新の動向をつかもう。