頭部検出についての記事を調査中です。
Context-aware CNNs for person head detection
- HollywoodHeads dataset を学習データに利用している・
- github https://github.com/aosokin/cnn_head_detection
- MATLABを必要とする。
- MatConvNet を必要とします 。
Youtube [DEMO] Context-aware CNNs for person head detection
この動画が示すように頭部を検出しているだけではなく、近接した人が、互いの顔を見つめ合っている状況を検出できるものになっている。
サンプルプログラムを動作させるためには、
学習済みのファイルを動作させるだけではなく、
サンプルプログラムで評価用の入力画像にも用いられているHollywoodHeads datasetを必要としている。
HollywoodHeads datasetの特徴:
HollywoodHeads dataset はモノクロの映画からの画像を多数含んでいる。カラーの画像のままの検出器を作ろうとする場合には、このデータセットだけでは足りないかもしれない。
後述のデータセットの大学の講義室の画像よりは、動作や背景や被写体の多様性はありそうだ。
--
github https://github.com/pranoyr/head-detection-using-yolo
-
必要なもの
TensorFlow
Keras -
利用している画像とアノテーション
上記のgithub上にGoogle Driveへのリンクがはられている。
Dataset
Download the dataset and put it in the root directory.
Images - https://drive.google.com/open?id=1zn-AGmsBqVheFPnDTXWBpeo3XRH1Ho15
Annotations - https://drive.google.com/open?id=1LiTDMWk0KglGueJCaxgneEA_ltvEbUDV
ここから学習用のデータの画像とアノテーションを入手できる(らしい)。データのライセンスも、このソースコードと同様のライセンスと判断してよいのだろうか。
また、学習済みのファイルもダウンロードできるようだ。
--
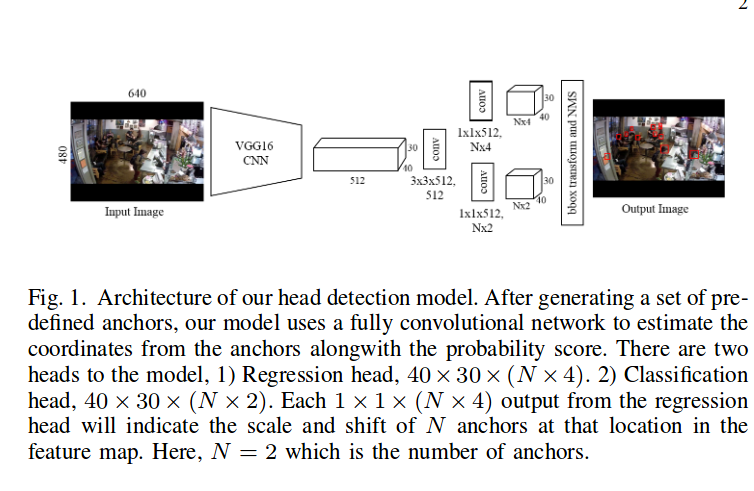
github https://github.com/aditya-vora/FCHD-Fully-Convolutional-Head-Detector
- 必要なもの
PyTorch - https://arxiv.org/pdf/1809.08766.pdf
- デモ動画がある。
- 学習データ
- BRAINWASH dataset
- https://www.mpi-inf.mpg.de/departments/computer-vision-and-multimodal-computing/software-and-datasets/
- http://datasets.d2.mpi-inf.mpg.de/brainwash/brainwash.tar
- 賑やかなカフェで天井にあるカメラから撮影した画像
- 日付の異なる3日での撮影。
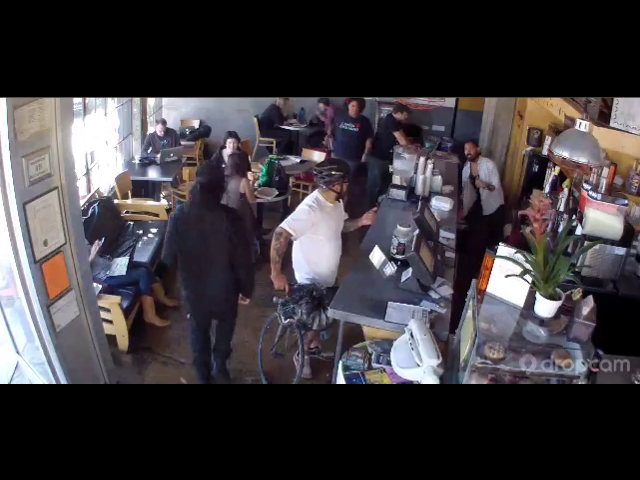
The dataset consists of images capturing the everyday
life of a busy downtown cafe and is split into the following subsets:
training set: 10769 with 81975 annotated people
validation set: 500 images with 3318 annotated people
test set: 500 images with 5007 annotated people
training set: 10769 with 81975 annotated people
validation set: 500 images with 3318 annotated people
test set: 500 images with 5007 annotated people
Bounding box annotations are provided in a simple text file format. Each line in the file contains
image name followed by the list of annotation rectangles in the [xmin, ymin, xmax, ymax] format.
これらのデータセットに着目するときには、頭部領域として範囲が、頭部の輪郭に対するBoundingBoxなのか、それに対してマージンが上下左右にどれくらい持っているのかに着目してみよう。
正面からみた頭部の場合には、頭部の輪郭に対してboundingBoxを描いても検出できるだろう。しかし、別の向きの頭部の場合は、頭部の輪郭に直に接するBoundingBoxを描くと特徴がなくなりすぎます。
BRAINWASH dataセットのBoundingBoXを見るための自作スクリプト
# -*- coding: utf-8 -*-
# pylint: disable=C0103
# pylint: disable=E1101
import cv2
def parseLine(line):
"""parse this kind of line.
Input example:
"brainwash_11_13_2014_images/00001000_640x480.png": (63.0, 260.0, 89.0, 287.0), (115.0, 174.0, 135.0, 193.0), (155.0, 158.0, 168.0, 174.0), (184.0, 162.0, 203.0, 180.0), (182.0, 137.0, 196.0, 150.0), (283.0, 124.0, 301.0, 143.0), (292.0, 132.0, 305.0, 145.0), (321.0, 119.0, 338.0, 134.0), (295.0, 161.0, 311.0, 180.0), (320.0, 173.0, 344.0, 192.0), (328.0, 222.0, 362.0, 261.0), (470.0, 245.0, 513.0, 289.0);
"""
line = line.strip().replace(";", "")
if line[-1] == ".":
line = line[:-1]
f = line.split(":")
name = f[0].replace('"', '')
nf = []
if len(f) >= 2:
nf = f[1].split(',')
nf = eval(f[1])
return name, nf
if __name__ == "__main__":
name = "brainwash_test.idl"
for line in open(name, "rt"):
name, nf = parseLine(line)
img = cv2.imread(name)
for rect in nf:
rect = [int(a) for a in rect]
x, y, x2, y2 = rect
cv2.rectangle(img, (x, y), (x2, y2), (0, 255, 0), 3)
cv2.namedWindow("img", cv2.WINDOW_NORMAL)
cv2.imshow("img", img)
key = cv2.waitKey(0)
if key == 27 or key == ord("q"): # wait for ESC key to exit
break
cv2.destroyAllWindows()
コメント:
頭部検出を評価する際のデータベースが特定の環境に集中していると、その環境のデータを学習用と評価用に分けて、検出率を評価しても、ほんとうに汎用的な頭部検出器になっているかが不安が残る。
極力多数のデータセットを用いて評価する必要があるだろう。
github https://github.com/HCIILAB/SCUT-HEAD-Dataset-Release
SCUT という大学での撮影したとみられるデータセットがpart A, part B としてGoogle Drive に公開されている。
大学の講義室の様子がサンプル画像として表示されている。
PartA

PartB

このデータセットは、講義室の混雑した環境のデータなので、頭部検出の一般的な性能を性能を評価するには、適してない。
VGG - Head detector - University of Oxford
ここでの VGG とは Visual Geometry Group のことです。
VGG16とかの表現のVGGは、以下の用に説明されています。
VGG is a convolutional neural network model proposed by K. Simonyan and A. Zisserman from the University of Oxford in the paper “Very Deep Convolutional Networks for Large-Scale Image Recognition”
とあるVGGは、このグループによるネットワークの構成の意味で使われています。
Headの矩形を返すだけではなく、HeadPoseをも返すとのことだ。
HOGを使っているらしいような図が書いてある。
2011年ごろのコードであって、深層学習以前のコードです。
MatlabもしくはC++のライブラリを使用して検出を行う。
Example of resultsに示されている評価データは次のデータ・セットです。
TV Human Interaction Dataset
Our Interaction Dataset consists of 300 video clips collected from over 20 different TV shows and containing 4 interactions: hand shakes, high fives, hugs and kisses, as well as clips that don't contain any of the interactions.
We annotated in each frame of every video:
1. The upper body of people (with a bounding box).
2. Discrete head orientation (profile-left, profile-right, frontal-left, frontal-right and backwards).
3. Interaction label of each person.
This dataset is available for research purposes only. I do not own the copyrights of the videos included in the dataset. These remain with their rightful owners.

Head Detection Using YOLO Algorithm
TensorFlow, Keras を使います。
github https://github.com/natanielruiz/deep-head-pose
頭部の向きを推定するコード
Hopenet is an accurate and easy to use head pose estimation network. Models have been trained on the 300W-LP dataset and have been tested on real data with good qualitative performance.
Depth画像を用いて頭部検出するアプローチ
Head Detection with Depth Images in the Wild
github https://github.com/JaouadROS/head_depth
以下のデータベースは、歩行者検出に関連するデータベースだ。
これらの画像は頭部を含んでいる。
INRIA Person dataset
http://pascal.inrialpes.fr/data/human/
LBP cascade for detect head and people in opencv
このページのリンク先から、OpenCVのLBP cascade 検出器用に学習された頭部検出器の学習済みデータをダウンロードすればよいようです。
それを利用するコードの例が書かれています。
追記(2023年2月)
頭部検出の代用になる情報の可能性
- 人体のポーズ推定でボーンのポイントを検出することでも,正面方向ならば、頭部の位置を知るのに十分な情報を返す可能性がある。
- そのような選択肢の場合、OpenPoseなどのボーン検出など、広く用いられている結果を流用できるでしょう。
- 最近の人検出は、人の見えている範囲が、人の限られた部位であっても検出できていることが多いので、頭部しか見えていない場合も人検出することが多いでしょう。
追記
- 頭部検出が、頭部検出だけで実社会のサービスとして有用な価値を持つことは少ないと思います。
- トラブルを未然に予防するための混雑度合いの判定をさせようとすれば、頭部がまるごとは写っていない、半ば隠れた頭部の検出も必要になってきます。
- 警備会社のサービスとしての場合には、監視カメラ画像からそのような判定をして、必要な対策を人がすることを支援することで価値を持っているでしょう。
- 交通量調査をしようとするならば、検出した頭部を追跡するなどをして、ある基準のラインを横切る頭部の数をカウントするなどの付加価値が必要になります。
- 頭部検出を、1カテゴリの物体検出として実装するよりは、頭部検出・顔検出・人検出など複数のカテゴリの物体検出の一部として実装するのが価値が高そうです。
- 頭部検出を作る際には、既存の検出器を利用して、追加の学習をするための頭部の枠を追加するのがよいと思われます。