ロボットに知性をもたせようとすると触覚は極めて重要な問題だ。
そこで、触覚とtransformerとの組合せがどのような状況なのか調査することとした。
極めて不十分な内容であり、関心を持つ人は、ぜひ自分で検索してほしい。
機械学習分野で課題設定から触覚の問題を避けてきたロボティクスの例
機械学習屋の多くは、画像認識分野での機械学習の進展の中で、静止画での画像認識・動画での画像認識を中心に開発してきた。
そのため、静止画データ、動画データを用いている。
それらのデータをwebで共有されることで、機械学習が大きく進展した。
それらのデータで学習した結果は、どのようなカメラでも利用可能になっている。
これらは、静止画・動画がデータとして標準化されているという強みによるものだ。
その代償として、画像認識・画像計測(マシンビジョン)の利用の中で、なるべく触覚データに頼らないしくみが作られている。
画像・動画の場合には十分に再現可能であるので、複数の開発チームでの結果の比較がしやすい。
そこに、標準化されていないデータが加わった場合には、複数の開発チームでの結果が比較されにくくなってしまう。
もちろん、触覚の分野で機械学習の成果をあげている組織は多くあり、良好な結果をあげている。
ただ、その結果が十分に共有されるにはいたっておらず、多くの機械学習屋は、触覚を避けている(もしくは、自分の仕事に取り込めていない)。
把持(にぎること、grasp)時の触覚は、ハンド(あるいはgripperなど)の形状と触覚センサの取り付け位置・触覚センサの種類などと密接にからみ合っている。
そのため、一つのハンドでの学習結果を別の構成のハンドに適用するのが難しいという問題を含んでいる。
これが、ハンドでの触覚を活用し切るのを難しくしている。
吸引によるpick and place
-
Amazon Picking Challenge は、吸引になってしまった。
-
吸引式(=吸着式)エンドエフェクタ

この例では赤い部分を対象物に押し付けて、吸着して対象物を持ち上げる。

段ボールさえも吸引で対応してしまっている。
柔軟性の高いグリッパーの使用
- グリッパーの柔軟性の高さで、把持力の制御の精度の必要性を減らしてきた。
触覚が画像や音声ほどには、データ構造が標準化されていない。
- カメラの場合:
- 静止画・動画のデータ形式は標準化されている。
- 同等品のカメラが見つけやすい。
- 静止画・動画の処理内容が標準化されいる。
- マイク(およびマイクロフォンアレイ)の場合
- マイク・マイクロフォンアレイのデータも標準化されている。
- 処理内容についても定式化が進んでいる。
- 例:ノイズ除去、音源推定、音声認識
- 同等品のマイクを見つけやすい
- 触覚の場合:
- データ形式が標準化されていない。
- 触覚の判定ロジックが、個別のセンサに強く結びついてしまっている(ようだ)。
- そのため、触覚の分布・触覚の時系列データに対するある触覚センサでの学習結果を、別な触覚センサには転用しがたい。
- そのため、触覚データに対して、よい解決方法が待たれている。
pdf Visuo-Tactile Transformers for Manipulation
github Visuo-Tactile Transformers for Manipulation
Abstract の和訳
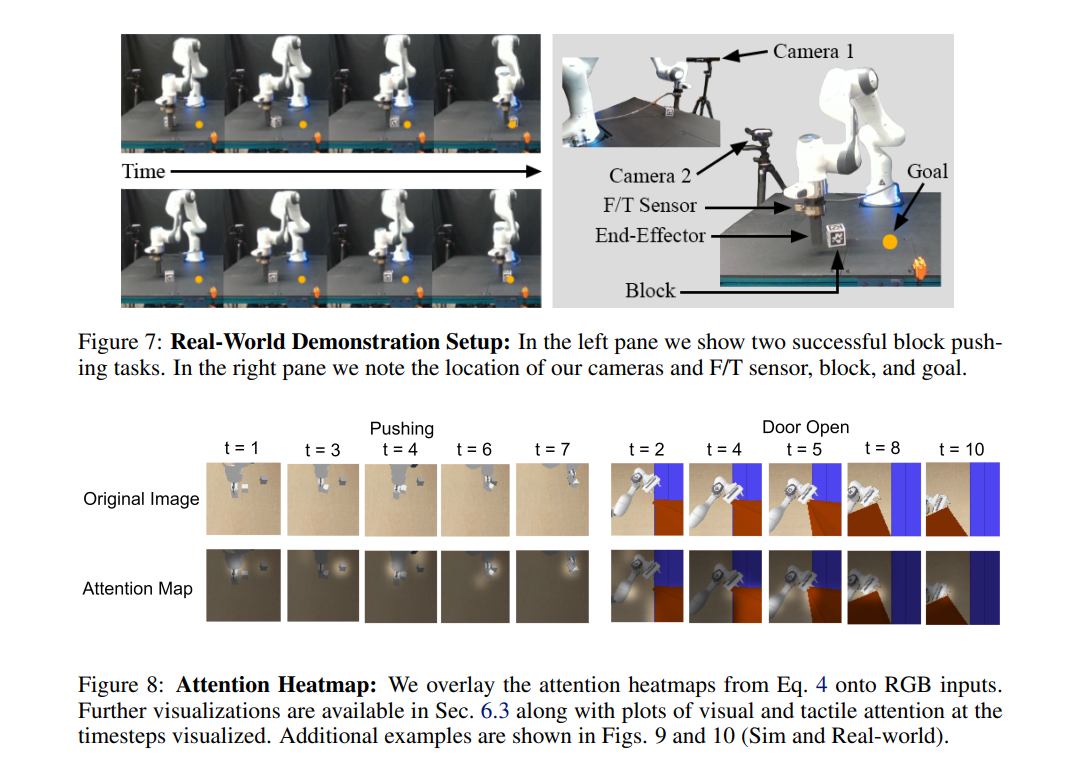
視覚と触覚の共同領域で表現を学習することで、相互情報と相補的な手がかりを利用し、操作の器用さ、ロバスト性、サンプル複雑性を向上させることができる。ここでは、モデルベースの強化学習とプランニングに適した、新しいマルチモーダル表現学習アプローチである視覚触覚トランスフォーマー(VTTs)を紹介する。我々のアプローチは、視覚-触覚フィードバックを扱うために視覚変換トランスフォーマーを拡張する。具体的には、VTTは触覚フィードバックと自己およびクロスモーダルアテンションを併用し、視覚領域における重要なタスク特徴にアテンションを集中させる潜在的ヒートマップ表現を構築する。我々は、4つの模擬ロボットタスクと1つの実世界のブロック押しタスクにおけるベースラインとの比較評価により、表現学習におけるVTTの有効性を実証する。ロボット操作のための表現学習におけるクロスモダリティの重要性を強調するために、VTTの構成要素に対するアブレーション研究を実施する。

github https://github.com/GTLIDAR/DeformableObjectsGrasping
特に果物のような変形可能な物体に対する信頼性の高いロボット把持は、グリッパーとの不十分な接触相互作用、未知の物体のダイナミクスや形状のために、依然として困難な課題である。本研究では、安全な物体把持のために触覚と視覚情報を活用する、剛体グリッパー用のTransformerベースのロボット把持フレームワークを提案する。具体的には、Transformerモデルは、予め定義された2つの探索動作(つまむ動作と滑らせる動作)の実行を通じて、センサフィードバックによる物理的特徴埋め込みを学習し、与えられた把持強度で多層パーセプトロン(MLP)を通じて把持結果を予測する。これらの予測を用いて、グリッパーは推論により安全な把持強度を予測する。畳み込みリカレントネットワークと比較して、Transformerモデルは画像シーケンスにまたがる長期的な依存関係を捉えることができ、空間的特徴量と時間的特徴量を同時に処理することができる。我々はまず、スリップ検出のための公開データセットを用いて、Transformerモデルのベンチマークを行う。その後、TransformerモデルがCNN+LSTMモデルよりも、把持精度と計算効率の点で優れていることを示す。また、新しい果物把持データセットを収集し、提案フレームワークを用いたオンライン把持実験を、見た果物と見たことのない果物の両方に対して行う。さらに、我々のモデルを異なる形状の物体に拡張し、我々の大規模なデータセットを用いて訓練した事前訓練モデルの有効性を実証する。
DeepL.com(無料版)で翻訳しました。

-
グリッパーには、Gelsight Tactile sensor、RealSense D435を用いている。
-
そのため、Visionでの学習は、グリッパーの付け根付近からの見え方に固定されます。グリッパーの開閉する範囲の外からの見え方になっています。
-
Gelsight Tactile sensor を用いている。
-
透明な弾性体とイメージセンサとを組合せたセンサなので、センシングデータは画像データである。そのため、ViTの枠組みの中にある。視触覚センサの場合、触覚に関するデータは画像になるため、透明な弾性体の変形量を取り出せれば、視覚データと同様な扱いで学習に用いることができる。
-
対象物の分類タスクもあるので、対象物の種類によって、どれだけの力だったら壊さないかを学習できる。
これと似たセンサはFinger Visonがある。
面として広がりのあるグリッパーを想定することになる。
大まかな位置にたどり着いたあとは、realsenseとGelSight sensorだけで、把持動作をするのに十分な情報になっている。
アームの姿勢情報は、不要である。
そのような単純化できる枠組みになっている。
現在の触覚デバイスは、記録された触覚信号を再生することによって触覚テクスチャ感覚を生成することができ、仮想現実(VR)や拡張現実(AR)における異なる材料のテクスチャ相互作用を可能にする。人間は、材料表面の様々な走査パラメータ(すなわち、印加される法線力、走査速度、なでる方向/位置)下で、同じテクスチャに向かって異なるテクスチャ感覚を感じることができるため、このような方法は、様々な走査パラメータ下で自然な触覚テクスチャのレンダリングをサポートすることができません。このため、我々は、変換器ベースのネットワークの枠組みを活用した、マルチモーダル触覚信号生成のための深層学習ベースのアプローチを提案した。本システムは、加速度信号合成のためのマルチモーダル特徴埋め込みモジュールを備えた変換器ベースの生成モデルを通して、物質表面の視覚画像を視覚データとして、表面上のペンのスライド運動によって誘発される走査パラメータを持つ加速度信号を触覚データとして取り込む。我々は、VR/ARにおいて自然でリアルな質感感覚を実現するために、素材表面の画像とユーザの走査状態に基づいた動的な加速度信号の合成を目指している。
- AR/VRの分野の触覚の扱い
- 触覚信号をVRの分野のために生成する。
Robotic Perception of Object Properties using Tactile Sensing

触覚は人間にとって環境の理解や相互作用に重要な役割を果たしており、ロボットにとっても欠かせないものです。特に触覚センシングは物体理解に役立つ情報を提供します。物体の分布圧力、温度、振動、手触りなど。また、ロボットの把持中は視覚が遮られることが多く、センシングが視覚ではアクセスできない領域を測定できます。最近数十年間、触覚センサーの開発が進み、様々なロボットタスクで使用されています。本章では、ロボットの把持における触覚センシングの利用と物体の触覚知覚について調査します。形状、姿勢、材料特性のような物体特性の把持における重要性について述べ、さらに触覚センシングを用いた把持の安定性予測に関する最近の動向を概観します。視覚と触覚センシングの協調の必要性も明らかになり、最近開発された視覚ガイド付き触覚センシングの提案が紹介されます。この提案では、カメラビジョンと光学触覚センサを組み合わせることで、ひび割れ形状再構成を改善できることが実証されています。最後に、触覚センシングの未解決課題と今後の方向性について考察されます。
Abstract の和訳への要約(DeepL)
この論文の中では、以下の内容を含んでいます。
- MATERIAL PROPERTIES RECOGNITION USING TACTILE SENSING
- 触覚を用いた材質の認識
- OBJECT SHAPE ESTIMATION USING TACTILE SENSING
- 触覚を用いた物体形状の推定
- OBJECT POSE ESTIMATION USING TACTILE SENSING
- 触覚を用いた物体の姿勢の推定
- GRASPING STABILITY PREDICTION USING TACTILE SENSING
- 触覚を用いた把持の安定性の予測
- VISION-GUIDED TACTILE PERCEPTION FOR CRACK RECONSTRUCTION
Robotic Tactile Perception of Object Properties: A Review (2017)
触覚センシングは、ロボットが周囲の環境、特にロボットが相互作用する対象物を理解するのに役立つ。この目的のために、ロボット工学者はここ数十年の間にいくつかの触覚センシング・ソリューションを開発し、文献で広く報告されている。また、伝達された触覚情報を解釈する研究も近年注目され始めている。しかし、このトピックに関する包括的な研究はまだ報告されていない。本調査では、この分野における主な科学的成果を収集・要約することを目的として、物体の特性に関するロボットの触覚知覚に関する現在の動向を幅広くレビューする。 物体特性の触覚認識に関する広範なレビューの前に、利用可能な触覚センシング技術を簡単に紹介する。 このレビューで対象とする物体特性は、形状、表面材質、物体姿勢である。また、他のセンシングソースと組み合わせたタッチセンシングの役割についても議論する。このレビューでは、未解決の課題を特定し、将来の方向性を示す。
DeepL.com(無料版)で翻訳しました。
TVL A Touch, Vision, and Language Dataset for Multimodal Alignment


このdataset についての説明は、以下のURLに記載がある。
https://huggingface.co/datasets/mlfu7/Touch-Vision-Language-Dataset
触覚センサ(tactile sensor)
のデータもjpg画像になっている。
これは、触覚を画像化したデータセットを用いている。
grasp anything
Large-scale Grasp Dataset from Foundation Models
ChatGPTのような基盤モデルは、実世界の領域を普遍的に表現するため、ロボットタスクにおいて大きな進歩を遂げてきた。本論文では、基盤モデルを活用して、幅広い産業応用が期待されるロボット工学の根強い課題である把持検出に取り組む。数多くの把持データセットがあるにもかかわらず、それらのオブジェクトの多様性は、実世界の数値と比較すると依然として限定的である。幸いなことに、基盤モデルは、我々が日常生活で遭遇する物体を含む、実世界の知識の広範なリポジトリを持っている。その結果、これまでの把持データセットにおける限られた表現に対する有望な解決策は、これらの基盤モデルに埋め込まれた普遍的な知識を利用することです。我々は、この解決策を実現するために、基盤モデルから合成された新しい大規模な把持データセットであるGrasp-Anythingを発表する。Grasp-Anythingは多様性と規模において優れており、テキスト記述を含む1Mサンプルと3M以上の物体を誇り、先行するデータセットを凌駕している。経験的に、我々はGrasp-Anythingが視覚ベースのタスクや実世界のロボット実験においてゼロショット把持検出を成功裏に促進することを示す。
DeepL.com(無料版)で翻訳しました。
Grasp-Anything++
github https://github.com/andvg3/Grasp-Anything

Grasp-Anything++は、Grasp-Anythingを拡張したもので、1,000万個の把持命令と関連する真値を含んでいる。
このデータセットは、言語駆動型把持タスクに使用することができ、ロボットが言語命令に基づいて特定の物体を把持することを可能にする。
視触覚センサ(=vision-based tactile sensors)という標準化可能なデータ
- FingerVison
- Gelsight
- 視触覚センサの場合には、ベースがイメージセンサである点、データ形式が標準化されやすい。
- 平面構造のグリッパーを用いている。
触覚を視覚としてとらえる別のアプローチ
- 接触によって、変形を生じる。生じた変形の量で応力の大きさを求める。
- これを行なっているセンサの代表例が視触覚センサだ。
- 視触覚センサの場合には、イメージセンサの上に弾性体が載っていて、その歪を計測することで応力を算出している。
- 別のアプローチは、応力を計測するためのマーカーはイメージセンサ上の弾性体上ではなく、空間的に離れた場所にあってもよいということだ。そのアプローチをしているのがPunyoである。
Soft Bubble Gripper in Punyo

https://pressroom.toyota.com/sensing-is-believing/
https://toyota-cms-media.s3.amazonaws.com/wp-content/uploads/2020/09/TRI-Soft-Bubble-Gripper-Image-6-1024x576.jpg
ロボットのために必要な触覚上の判断
- 対象物を適切な力で把持できているか判断できること。
- 例:シュークリームをつかむときに、シュークリームを潰してはいけない。
- 滑りが生じている・生じていないの区別がつくこと、滑りが生じたら滑りを止められること
- 例:ボールペンを持っているときに、落とさないこと。
- 複数の対象物の位置関係が妥当であるかを検証できること
- 例:鍵穴に鍵を差し込めたかどうか?
- 例:ネジがネジ穴に入っているかどうか?
- 例:ドライバーがネジの頭部にはまったままであるか?
- 例:ネジを回している部分のトルクがネジ締めできたトルクになっているかどうかの判断
ほしい触覚データ
- 複数指の人の手に似せたハンドでの触覚データを含む同期のとれた動画
- しかも自己視点画像で、自らの両腕と対象物とを含む相互作用とを含むもの
- さらには、ステレオ画像での撮影を行なっているもの。
- 触覚センサの種類・取り付け位置が明示されており、第三者がどうような状況を再現できればなおよい。
SEE ALSO
https://www.sciencedirect.com/topics/engineering/tactile-data
CVPR 2024のpaperのlistでgrasp で検索して、8件見つかった。
この分野が熱い戦いの現場になっているようだ。
ロボット学会のセミナー
【オンライン開催】第153回 「力触覚・近接覚を活用したラスト1センチのロボットマニピュレーション」
が開催されました。
講演タイトルと発表者の名前をもとに、それぞれの研究内容を調査することです。
ハンドの器用さを実現するには力触覚・近接覚は不可欠な要素です。
この分野は急激に変わっています。
ViTの利用などもされるようになってきていますので、
画像認識系のエンジニアが触覚の分野に流れ込んでいるのはありそうです。