この記事の内容
AlmaLinux9のVMを3つ使って、Masterノードx1、Workerノードx2のk8sのクラスタを作ります。
その後、nginxのpodを3つ動かして、クラスタ内でhttpでアクセスが通ることを確認します。
環境
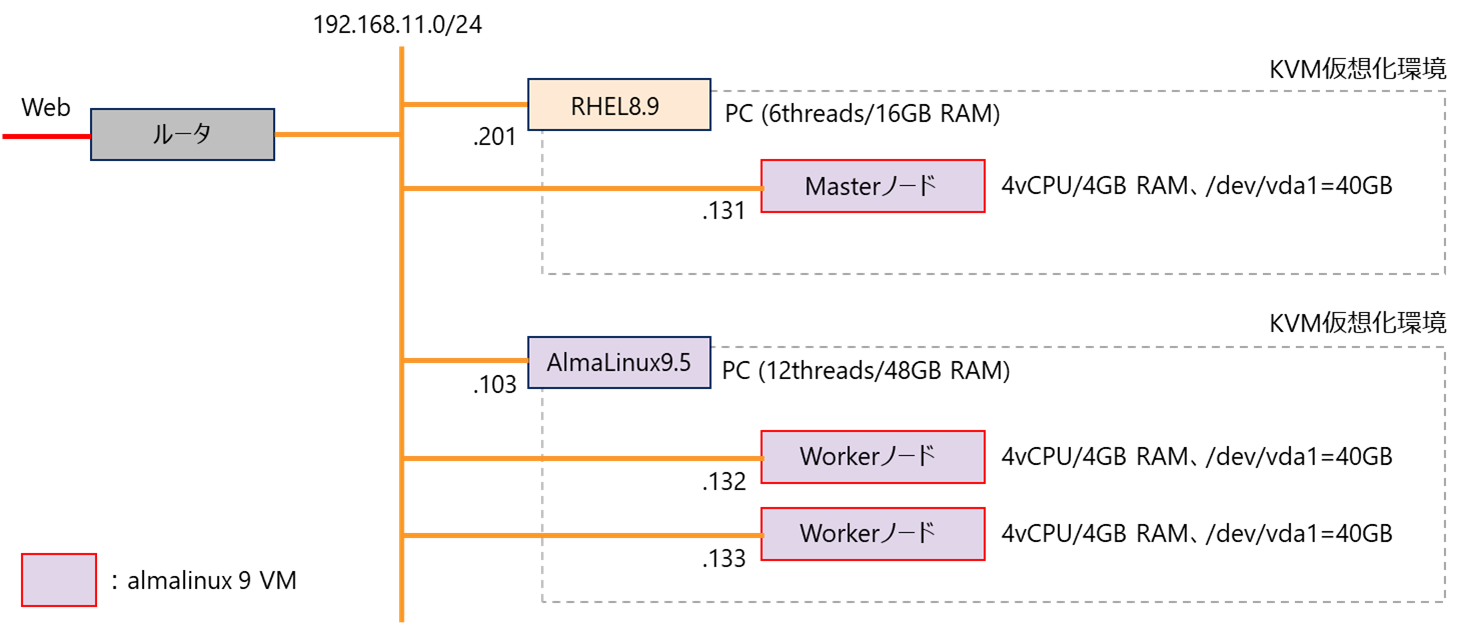
- RHEL8のPCが非力なので、もう一台Linux ホストOSのPCを用意して使います。
- almalinux9のVMは、以下の記事の方法で、マシンイメージから作っています。
これは、パブリッククラウドのインスタンスのように、最低限構成のVMを簡単に素早く作るためなので、OSインストーラから普通に構築したVMでも問題ありません。
k8sクラスタ構築の流れ
まず、VMごとに共通の設定を行います。
(1) k8sクラスタにするVM3つに、それぞれ、OSをインストールする。※この時点では、k8sについて考慮することはありません。
(2) k8sの各ノードとするために必要なOS設定を行う。
(3) cri-oをインストールする。※コンテナランタイムの1つ。containerdや他のものに可換。
(4) kubeadmをインストールする。
Masterノードに対して設定を行います。
(1) k8sの主要コンポーネントのコンテナが動くようにする。
(2) flannelをインストールする。※CNIプラグインの1つ。calicoや他のものに可換。
(3) クラスタ参加のためのトークンを生成する。
各Workerノードに対して設定を行います。
(1) Masterノードで生成したトークンを使って、クラスタに参加します。
1. OSのインストールと設定
a. OSのインストール
各ノードにするVMは、以下のマシンイメージから作りました。
https://repo.almalinux.org/almalinux/9/cloud/x86_64/images/AlmaLinux-9-GenericCloud-9.5-20241120.x86_64.qcow2
AlmaLinux9.5のisoファイルの更新日時が2024/11/13なので、恐らく、9.5のマイナーバージョンアップ提供開始直後に作られたもの。
各ノードのVMの構成は、次の通り。
| rhel8host VM1 | al9host VM1 | al9host VM2 | |
|---|---|---|---|
| ホスト名 | master1.internal | worker1.internal | worker2.internal |
| vCPU数 | 4 | 4 | 4 |
| Memory | 4 GiB | 4 GiB | 4 GiB |
| ルートディスク | 40 GiB | 40 GiB | 40 GiB |
| IPアドレス(/24) | 192.168.11.131 | 192.168.11.132 | 192.168.11.133 |
k8s v1.32のリソース要件は、各ノード2GB以上のメモリ、Masterノード2CPU以上、です(ギリギリではない)。
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
b. VM/OSの設定
(1) nmtuiで、System eth0を削除、IPv4のIPなどを設定、ホスト名を設定。
(2) タイムゾーンをAsia/Tokyoに設定。
timedatectl set-timezone Asia/Tokyo
(3) firewalldをインストール、有効化。
dnf install -y firewalld
systemctl enable --now firewalld
firewall-cmd --list-all
※ついでに、ルーティング設定を見たりできるよう、iptablesも入れてみる。
dnf install -y iptables
(4) vimをインストール。
dnf install -y vim
(5) rootのsshログインを許可。/etc/ssh/sshd_configの、PermitRootLoginをyesにし、sshd.serviceを再起動。
(6) VMのvCPU数を4に変更。(1ソケット4コア)。
(7) cloud-init.isoを取り外す。(多分、再起動すると勝手に外れる)
2. k8sの各ノードとするためのOS設定
以下の設定は、3ノードで、それぞれ、実施します。
(1) /etc/hostsに、互いのホスト名を記載。
cat > /etc/hosts << EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.11.103 al9host al9host.internal
192.168.11.201 rhel8host rhel8host.internal
192.168.11.131 master1 master1.internal
192.168.11.132 worker1 worker1.internal
192.168.11.133 worker2 worker2.internal
EOF
(2) ロードされるドライバを設定。
- br_netfilter:ネットワークポリシーによるトラフィック制御を、ブリッジに対して適用するためのもの。
- ip_vs~:kube-proxyがIPVS(IP Virtual Server)モードで動作するためのもの。サービスがPodにトラフィックを振り分けるとき、userspaceモード、iptablesモード、IPVSモード、があり、ip_vs等のドライバがない場合のデフォルトはiptablesモード。
- overlay:OverlayFSを使用するためのもの(コンテナを動かすのに必要)。
modprobe br_netfilter
modprobe ip_vs
modprobe ip_vs_rr
modprobe ip_vs_wrr
modprobe ip_vs_sh
modprobe overlay
cat > /etc/modules-load.d/kubernetes.conf << EOF
br_netfilter
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
overlay
EOF
(3) sysctlの設定。
- ipv4.ip_forward:IPv4パケットの転送を有効にする。システムがルータのように動作し、受信したパケットを、ほかのNICに転送できるようになる。Pod間通信や、ノード間通信に必要。
- bridge-nf-call-iptables:ブリッジ経由のトラフィックのフィルタリングとセキュリティの設定。
- それらのIPv6の設定も、念のため。
cat > /etc/sysctl.d/kubernetes.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv6.conf.all.forwarding = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
sysctl --system
※確認じゃなく、設定の反映なので、省略不可。
(4) swapの無効化。
マシンイメージから作ったゲストOSは、swap領域のパーティション/LVはありませんでした。やる場合は以下です。
swapoff -a
sed -e '/swap/s/^/#/g' -i /etc/fstab
(5) firewalldの設定。
https://kubernetes.io/docs/reference/networking/ports-and-protocols/
に、k8sのMasterノードと、Workerノードが求めるポートがあります。
Masterノード用。
firewall-cmd --zone=public --permanent --add-port=6443/tcp
firewall-cmd --zone=public --permanent --add-port=2379-2380/tcp
firewall-cmd --zone=public --permanent --add-port=10250/tcp
firewall-cmd --zone=public --permanent --add-port=10257/tcp
firewall-cmd --zone=public --permanent --add-port=10259/tcp
続いて、Workerノード用。ただ、ここでは区別せず、全ノード、両方を設定します。
firewall-cmd --zone=public --permanent --add-port=10250/tcp
firewall-cmd --zone=public --permanent --add-port=10256/tcp
firewall-cmd --zone=public --permanent --add-port=30000-32767/tcp
vxlan用。ノードをまたぐ通信をするとき、この2つのポートを許可しないと、curlとかが通らなったので追加。
firewall-cmd --permanent --zone=public --add-port=8285/udp
firewall-cmd --permanent --zone=public --add-port=8472/udp
firewall-cmd --zone=public --permanent --add-source=10.244.0.0/16
そして、これらのポートを許可しても、なお、curlが通らず。同様の事例が以下にありました。
https://github.com/flannel-io/flannel/issues/2055
firewalldはnftablesを使い、flannelはiptablesを使う、の違いがあり、ノード間の転送がnfstablesにフィルタされてしまうため、Pod間ネットワークに使用する、10.244.0.0/16ネットワーク全体を許可する設定を追加することとしました。
firewall-cmd --reload
firewall-cmd --list-all
(6) SELinuxの設定。
Permissiveにします。
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/config
(7) kubelet、kubeadm、kubectl、cri-oのインストール。
kubeadmのインストール手順は、ここにあります。
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
また、cri-oのインストール手順は、ここにあります。
https://github.com/cri-o/packaging/blob/main/README.md#usage
ここでは、最新のv1.32をインストールします。
まずは、kubernetesのリポジトリと、cri-oのリポジトリを、有効化します。
KUBERNETES_VERSION=v1.32
CRIO_VERSION=v1.32
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/$KUBERNETES_VERSION/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/$KUBERNETES_VERSION/rpm/repodata/repomd.xml.key
EOF
cat <<EOF | tee /etc/yum.repos.d/cri-o.repo
[cri-o]
name=CRI-O
baseurl=https://pkgs.k8s.io/addons:/cri-o:/stable:/$CRIO_VERSION/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/addons:/cri-o:/stable:/$CRIO_VERSION/rpm/repodata/repomd.xml.key
EOF
インストールします。
dnf install -y container-selinux
なぜか、公式の手順が、dnfでなくyumなので、yumにしてます(dnfでも同じだと思いますが)。
yum install -y cri-o kubelet kubeadm kubectl --disableexcludes=kubernetes
crioとkubeletのサービスを有効化します。
systemctl enable --now crio.service
systemctl enable --now kubelet.service
ここまでの設定を、3ノードで、それぞれ、実施します。
3. Masterノードの設定
以下の設定は、Masterノードでのみ、実施します。Workerノードでは実施しません。
(1) k8sの主要コンポーネントのコンテナイメージをローカルにプル。
kubeadm config images pull
何のコンテナイメージを必要とするかは、kubeadmが知っているようです。
[root@master1 ~]# kubeadm config images pull
[config/images] Pulled registry.k8s.io/kube-apiserver:v1.32.1
[config/images] Pulled registry.k8s.io/kube-controller-manager:v1.32.1
[config/images] Pulled registry.k8s.io/kube-scheduler:v1.32.1
[config/images] Pulled registry.k8s.io/kube-proxy:v1.32.1
[config/images] Pulled registry.k8s.io/coredns/coredns:v1.11.3
[config/images] Pulled registry.k8s.io/pause:3.10
[config/images] Pulled registry.k8s.io/etcd:3.5.16-0
[root@master1 ~]#
プルされたイメージは、crictl imagesで確認できます。
[root@master1 ~]# crictl images
IMAGE TAG IMAGE ID SIZE
registry.k8s.io/coredns/coredns v1.11.3 c69fa2e9cbf5f 63.3MB
registry.k8s.io/etcd 3.5.16-0 a9e7e6b294baf 151MB
registry.k8s.io/kube-apiserver v1.32.1 95c0bda56fc4d 98.1MB
registry.k8s.io/kube-controller-manager v1.32.1 019ee182b58e2 90.8MB
registry.k8s.io/kube-proxy v1.32.1 e29f9c7391fd9 95.3MB
registry.k8s.io/kube-scheduler v1.32.1 2b0d6572d062c 70.6MB
registry.k8s.io/pause 3.10 873ed75102791 742kB
[root@master1 ~]#
なお、crictl imagesで見えるローカルイメージは、podman imagesでも見えます。この環境にはpodmanが入っていないので、入れて確認すると、以下です。
dnf install podman
[root@master1 ~]# podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.k8s.io/kube-apiserver v1.32.1 95c0bda56fc4 3 weeks ago 98.1 MB
registry.k8s.io/kube-controller-manager v1.32.1 019ee182b58e 3 weeks ago 90.8 MB
registry.k8s.io/kube-scheduler v1.32.1 2b0d6572d062 3 weeks ago 70.6 MB
registry.k8s.io/kube-proxy v1.32.1 e29f9c7391fd 3 weeks ago 95.3 MB
registry.k8s.io/etcd 3.5.16-0 a9e7e6b294ba 4 months ago 151 MB
registry.k8s.io/coredns/coredns v1.11.3 c69fa2e9cbf5 6 months ago 63.3 MB
registry.k8s.io/pause 3.10 873ed7510279 8 months ago 742 kB
[root@master1 ~]#
(2) kubeadm initで、k8sクラスタを初期化。
Pod間ネットワークとして、ここでは、10.244.0.0/16を指定しています。
kubeadm init --pod-network-cidr=10.244.0.0/16
以下、実行ログ例です。「Your Kubernetes control-plane has initialized successfully!」が出れば、問題なく行えていると思います。
[root@master1 ~]# kubeadm init --pod-network-cidr=10.244.0.0/16
[init] Using Kubernetes version: v1.32.1
[preflight] Running pre-flight checks
~
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.11.131:6443 --token e00jos.ecf0zgpfkfrreih3 \
--discovery-token-ca-cert-hash sha256:84d6e7a1280e5deedd8887d2328da21a0e2d4fba4daa8860713f75e6dedff533
[root@master1 ~]#
[root@master1 ~]# echo $?
0
[root@master1 ~]#
(3) k8sクラスタにアクセスするための設定ファイルを、ユーザのホームディレクトリにコピー。
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
rootで実行してきたので、この場合、/root/.kube/configに設定ファイルがコピーされます。以後、rootユーザでkubectlコマンドを実行すると、このconfigファイルの指す先をk8sクラスタとして、要求が飛びます。以下例の場合、192.168.11.131(=master1.intarnal)の6443番ポートです。
[root@master1 ~]# cat ~/.kube/config | grep server
server: https://192.168.11.131:6443
[root@master1 ~]#
(4) flannelをインストール。
インストールは、以下の手順に従います。
https://github.com/flannel-io/flannel
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
このコマンド1つで、flannelのインストールが完了しますが、裏側では、以下のようなことをしています。
- flannelの開発コミュニティで配布されている、kube-flannel.ymlのファイルをダウンロードする。このファイルは、カスタムリソースの定義が記載されたマニフェストファイル、と呼ばれる。
- マニフェストファイルの中では、どこどこからコンテナイメージをプルし、どうやって起動する、といった設定が記述されている。
- kubectl apply -f ~kube-flannel.yamlで、このマニフェストファイルから、flannelのカスタムリソース(Podやserviceなど)を作成する。上手く作成できれば、k8sクラスタ上の各ノードでflannelのPodが常駐するようになり、Pod間ネットワークが形成維持される。
どういうコンテナイメージをプルしているかは、マニフェストファイルに書かれています。
ghrc.ioは、GitHub Container Registryのレジストリです。
[root@master1 flannel]# curl -L -O https://github.com/flannel-io/flannel/release
s/latest/download/kube-flannel.yml
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 4409 100 4409 0 0 2874 0 0:00:01 0:00:01 --:--:-- 4305k
[root@master1 flannel]#
[root@master1 flannel]# grep -n1 image: kube-flannel.yml
145- value: "5000"
146: image: ghcr.io/flannel-io/flannel:v0.26.4
147- name: kube-flannel
--
172- - cp
173: image: ghcr.io/flannel-io/flannel-cni-plugin:v1.6.2-flannel1
174- name: install-cni-plugin
--
183- - cp
184: image: ghcr.io/flannel-io/flannel:v0.26.4
185- name: install-cni
[root@master1 flannel]#
crictl imagesで、プルされたコンテナイメージを確認できます。
[root@master1 flannel]# crictl images | grep -e IMAGE -e flannel
IMAGE TAG IMAGE ID SIZE
ghcr.io/flannel-io/flannel-cni-plugin v1.6.2-flannel1 55ce2385d9d8c 11MB
ghcr.io/flannel-io/flannel v0.26.4 1421c6bce6d6e 78MB
[root@master1 flannel]#
(5) k8sクラスタに、Workerノードを追加させるためのトークンコマンドを生成。
kubeadm token create --print-join-command
この実施例の場合、出力(kubeadm join ~)をコピーし、そのまま、Workerノードで実行します。
[root@master1 ~]# kubeadm token create --print-join-command
kubeadm join 192.168.11.131:6443 --token vcysam.ewwr9dlhb3jwc413 --discovery-token-ca-cert-hash sha256:84d6e7a12~
[root@master1 ~]#
4. Workerノードの設定
(1) Workerノードで、トークンコマンドを実行。
kubeadm join 192.168.11.131:6443 --token vcysam.ewwr9dlhb3jwc413 --discovery-token-ca-cert-hash sha256:84d6e7a12~
各Workerノードで、それぞれ、実行します。
(2) Masterノードで、k8sクラスタにWorkerノードが参加したことを確認。
kubectl get nodes
正常に参加できれば、以下のように、各ノードのSTATUSがReadyになります。NotReadyからReadyになるまで数十秒待つ必要があります。
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1.internal Ready control-plane 6m54s v1.32.1
worker1.internal Ready <none> 34s v1.32.1
worker2.internal Ready <none> 30s v1.32.1
[root@master1 ~]#
[root@master1 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master1.internal Ready control-plane 6m59s v1.32.1 192.168.11.131 <none> AlmaLinux 9.5 (Teal Serval) 5.14.0-503.14.1.el9_5.x86_64 cri-o://1.32.1
worker1.internal Ready <none> 39s v1.32.1 192.168.11.132 <none> AlmaLinux 9.5 (Teal Serval) 5.14.0-503.14.1.el9_5.x86_64 cri-o://1.32.1
worker2.internal Ready <none> 35s v1.32.1 192.168.11.133 <none> AlmaLinux 9.5 (Teal Serval) 5.14.0-503.14.1.el9_5.x86_64 cri-o://1.32.1
[root@master1 ~]#
5. nginxのPodによる動作確認
これで、k8sクラスタが構成できた、ということで、最後に、nginxのPodを3つ動かすDeploymentを作り、k8sクラスタ内で通信が通ることを確認します。
以下、Masterノードで操作しています。
(1) nginxディレクトリを作り、マニフェストファイルを作成。
mkdir ~/nginx
cd ~/nginx/
vim nginx-deployment.yaml
nginxのPodを3つ動かすDeploymentを作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
(2) マニフェストファイルから、Deploymentを作成。
kubectl apply -f nginx-deployment.yaml
数十秒後、以下のように、podが3つが作られていることを確認します。
[root@master1 nginx]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 22s
[root@master1 nginx]#
[root@master1 nginx]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-96b9d695-6hksq 1/1 Running 0 26s
nginx-deployment-96b9d695-d9x97 1/1 Running 0 26s
nginx-deployment-96b9d695-tflc5 1/1 Running 0 26s
[root@master1 nginx]#
(3) PodのIPアドレスと、どのWorkerノードで動いているか確認。
[root@master1 nginx]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-96b9d695-6hksq 1/1 Running 0 94m 10.244.3.2 worker2.internal <none> <none>
nginx-deployment-96b9d695-d9x97 1/1 Running 0 94m 10.244.1.3 worker1.internal <none> <none>
nginx-deployment-96b9d695-tflc5 1/1 Running 0 94m 10.244.1.2 worker1.internal <none> <none>
[root@master1 nginx]#
今の状態を図示すると、こうなります。

- 2つのPodは、worker1で動いている。
- 1つのPodは、worker2で動いている。
- 各Podは、10.244.0.0/16のネットワークのIPアドレスを持っている。
また、Masterノードのネットワークを見ると、
[root@master1 nginx]# ip addr | grep -e UP -e inet | grep -v inet6
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
inet 127.0.0.1/8 scope host lo
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
inet 192.168.11.131/24 brd 192.168.11.255 scope global noprefixroute eth0
3: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
inet 10.244.0.0/32 scope global flannel.1
4: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
inet 10.244.0.1/24 brd 10.244.0.255 scope global cni0
5: vethe6e983e7@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default qlen 1000
6: veth7310f40c@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default qlen 1000
[root@master1 nginx]#
つまり、こうなっており、Pod間ネットワーク(10.244.0.0/16)と通信するためのI/Fを持っています。
| I/F名 | IPアドレス | prefix | 通信用途 |
|---|---|---|---|
| eth0 | 192.168.11.131 | /24 | k8sクラスタ外 |
| cni0 | 10.244.0.1 | /24 | 自ノードのリソース |
| flannel.1 | 10.244.0.0 | /32 | 他ノードのリソース |
(4) Masterノードから、各Podにhttpリクエストを要求。
[root@master1 nginx]# curl http://10.244.1.2 | head -n4
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 615 100 615 0 0 600k 0 --:--:-- --:--:-- --:--:-- 600k
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
[root@master1 nginx]#
[root@master1 nginx]# curl http://10.244.1.3 | head -n4
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 615 100 615 0 0 600k 0 --:--:-- --:--:-- --:--:-- 600k
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
[root@master1 nginx]#
[root@master1 nginx]# curl http://10.244.3.2 | head -n4
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 615 100 615 0 0 600k 0 --:--:-- --:--:-- --:--:-- 600k
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
[root@master1 nginx]#
このように、Masterノードから、3つのPodにhttpリクエストを送り、応答を返していることが確認できます。

6. まとめ
- AlmaLinux9.5のVM3つで、k8sクラスタを作成しました。
- nginxのPodを3つ作り、k8sクラスタ間で、通信ができることを確認できました。
参考にした情報
ありがとうございます。