はじめに
プロ野球(NPB)がある程度わかる人向けの記事です。
ちなみにわたしは🐯ファンですが,特定のファンを悪く言う目的はない,ということを理解した上で見てください。
以前,こんなニュースがありました。
プロ野球の応援マナーに関連したニュースが元となって,Twitterで議論が巻き起こるってたまにありますよね。ニュース自体に言及するというよりも,違うファン同士で「おまえらのほうがマナー悪いやんけ!」みたいな言い合い。よく見ます。
また,他球団への悪口やヤジ以外にも,自分の応援するチームの選手にも過激な言葉を吐く人もいたり。
実際,こういう民度の低い言葉ってどのくらいあるんだろう?
民度の良し悪しは,球団によってどのくらい違うんだろう?
という疑問を感じたので,今回はこれを簡単に分析していきます。
分析対象は,Twitterに投稿された実況ツイートです。
つまり,あくまでも**「Twitter民」の民度**ということをお忘れなく!
民度の定義
今回は,分析を簡単にするために,ヤジ・悪口だと思われる単語(ここでは「ちくちく言葉」と呼びます)を定義し,その単語が含まれているツイートの割合を計算して,民度の低さを測ります。
ついでに,民度の高さ(ファンの優しさ)も同じように定義して,「ふわふわ言葉」の割合を計算してみます。
これらを「ちくちく度」「ふわふわ度」として,下のように計算します。
$$チームAのファンのちくちく度=\frac{ちくちく言葉が入っているチームAのツイート数}{チームAのツイート数}$$
$$チームAのファンのふわふわ度=\frac{ふわふわ言葉が入っているチームAのツイート数}{チームAのツイート数}$$
実験方法と結果
実験方法の概要はこのようになっています。
- ツイートの収集
- 実況ツイートの言語をモデル化
- ちくちく言葉・ふわふわ言葉の単語を定義
- ちくちく度・ふわふわ度の計算
次から具体的に説明していきます。
ツイートの収集
野球の試合時間内に投稿されたツイートを各球団のハッシュタグを元に収集
以前書いた記事「プロ野球の実況ツイートを全部取得する」の方法でツイートを収集しました。
今回の実験では,2019年度のデータを扱います。
球団ごとの,ツイートを取得した試合数とツイートの総数は以下の通りです。
| 球団名 | 試合数 | ツイート総数 |
|---|---|---|
| 巨人 | 127 | 590634 |
| 中日 | 125 | 250771 |
| 広島 | 119 | 442592 |
| ヤクルト | 122 | 400029 |
| 阪神 | 128 | 428525 |
| DeNA | 127 | 564144 |
| 日本ハム | 120 | 415629 |
| ソフトバンク | 125 | 487349 |
| 楽天 | 122 | 256291 |
| 西武 | 123 | 528261 |
| ロッテ | 122 | 395208 |
| オリックス | 121 | 13710 |
※ オリックスに関しては,取得できたツイートが少なかったので,今回は省きます。ごめんなさい...
実況ツイートの言語をモデル化
ツイートを前処理してWord2Vecのモデルを学習
前処理
テキストのクリーニング
以下の処理等を行います
- URL,ハッシュタグ,スペース等の除去
- @以下の文字の除去
- 数字とアルファベットを半角文字に統一
形態素解析による単語分割
▼ mecab-ipadic-neologdの辞書を使って,mecabによる形態素解析
def bow(mecab_dict,text):
parts = ('名詞','形容詞','形容動詞','副詞','動詞','連体詞','感動詞','接続詞','記号')
parsed = mecab_dict.parse(str(text))
lines = parsed.split('\n') # 解析結果を1行(1語)ごとに分けてリストにする
lines = lines[0:-2] # 後ろ2行は不要なので削除
w_l = []
for word in lines:
l = re.split('\t|,', word)
d_ = {'Surface': l[0], 'POS1': l[1]}
if d_['POS1'] in parts:
w_l.append(d_['Surface'])
return w_l
mecab_dict = MeCab.Tagger('../data/mecab-ipadic-neologd/')
# text_list = ['大山ツーベースでチャンス','いやいや、今の結構危なかったよ。', ...]
words_list = []
for text in text_list:
words = bow(mecab_dict,text)
words_list.append(words)
# words_list = [['大山','ツーベース','で','チャンス'],\
# ['いやいや','、','今','の','結構','危なかっ','た','よ','。']]
Word2Vecのモデルを学習
▼ gensimのWord2Vecライブラリを使って,実況ツイートをコーパスとした言語モデルを学習
def train_word2vec(all_words_list,vecsize,window,min_count,iter_num):
model = word2vec.Word2Vec(all_words_list,size=vecsize\
, window=window, min_count=min_count, iter=iter_num)
model.save('モデルのファイル名.model')
vecsize = 300
window = 10
min_count = 5
iter_num = 5
train_word2vec(words_list,vecsize,window,min_count,iter_num)
▼ モデルがちゃんと学習できているか確認,
def word2vec_model_check(model,p_words,n_words):
results = model.wv.most_similar(positive=p_words,negative=n_words,topn=10)
print('model.wv.most_similar(positive=',p_words,',negative=',n_words,')')
for result in results:
print(result)
return results
model = word2vec.Word2Vec.load('モデルのファイル名.model')
p_words, n_words = ['ラミレス'],[]
word2vec_model_check(model,p_words,n_words)
"""
# 実行結果
model.wv.most_similar(positive= ['ラミレス'] ,negative= [] )
('平石', 0.794029951095581)
('工藤', 0.7856395244598389)
('緒方', 0.7593538761138916)
('与田', 0.7247989177703857)
('辻', 0.7119660377502441)
('矢野', 0.7048444747924805)
('井口', 0.6532944440841675)
('名将', 0.6368062496185303)
('迷', 0.6259689331054688)
('采配', 0.6153334379196167)
"""
p_words, n_words = ['ホームラン'],[]
word2vec_model_check(model,p_words,n_words)
"""
# 実行結果
model.wv.most_similar(positive= ['ホームラン'] ,negative= [] )
('HR', 0.848455011844635)
('弾', 0.7043811082839966)
('アーチ', 0.6742182970046997)
('本塁打', 0.6652001142501831)
('ツーラン', 0.6070960760116577)
('ツーランホームラン', 0.5996525287628174)
('スリーランホームラン', 0.595179557800293)
('グラスラ', 0.5532823801040649)
('タイムリー', 0.4852123558521271)
('ヒット', 0.48372089862823486)
"""
「ラミレス」と「ホームラン」に近い単語TOP10を表示してみました。
「ラミレス」さんは監督なので,他のチームの監督の名前が上位になっています。
「ホームラン」は,別の表記方法などが上位になっています。
ちくちく言葉・ふわふわ言葉の単語を定義
初期設定となる,ちくちく言葉・ふわふわ言葉の単語を指定
どのような単語をツイート内検索するのかを定めるために,検索ワードを2種類用意します。
chikuchiku_wordsとfuwa fuwa_wordsを以下のように設定。
(テキストデータとして載せたくなかったので,スクショで失礼します)

Word2Vecを使って検索ワードを拡張
上記の単語だけだと,表記揺れや似たような表現があるはずなので,先ほど学習させたWord2Vecのモデルを用いて,検索ワードを拡張します。
初期の単語それぞれに対して,似た単語上位30件を抽出し,類似度が高い単語を検索ワードのリストに加えます。
def get_related_words(model,search_words,thres,remove_words):
related_words = []
for sw in search_words:
results = word2vec_model_check(model,sw,[])
for r in results:
if r[1]>thres:
related_words.append(r[0])
related_words = list(set(related_words+search_words)-set(remove_words))
return related_words
# ちくちく言葉の単語リスト
search_words = chikuchiku_words
remove_words = [...省略] #抽出された単語でおかしいものを手動で削除
thres = 0.55 # 類似度の閾値
related_words = get_related_words(model,search_words,thres,remove_words)
print(related_words)
# ふわふわ言葉の単語リスト
search_words = fuwafuwa_words
remove_words = [...] #抽出された単語でおかしいものを手動で削除
thres = 0.55 # 類似度の閾値
related_words = get_related_words(model,search_words,thres,remove_words)
print(related_words)
結果,以下の言葉を「ちくちく言葉の単語リスト」「ふわふわ言葉の単語リスト」とします。

ちくちく度・ふわふわ度の計算
それぞれ,11球団のファンによる,ちくちく言葉(またはふわふわ言葉)が入っているツイート数とその割合を計算しました。
ちくちく度
| 球団名 | ちくちく言葉を含むツイート数 | ツイート総数 | ちくちく度 |
|---|---|---|---|
| 巨人 | 8663 | 590634 | 1.47 % |
| 中日 | 2776 | 250771 | 1.11 % |
| 広島 | 7469 | 442592 | 1.69 % |
| ヤクルト | 4992 | 400029 | 1.25 % |
| 阪神 | 6217 | 428525 | 1.45 % |
| DeNA | 6468 | 564144 | 1.14 % |
| 日本ハム | 2846 | 415629 | 0.685 % |
| ソフトバンク | 3975 | 487349 | 0.816 % |
| 楽天 | 2548 | 256291 | 0.994 % |
| 西武 | 8163 | 528261 | 1.55 % |
| ロッテ | 4958 | 395208 | 1.25 % |
うん,だいたい思った通りの結果。
●:「ちくちく度」が一番高いのは広島,一番低いのは日ハムでした。
ふわふわ度
| 球団名 | ふわふわ言葉を含むツイート数 | ツイート総数 | ふわふわ度 |
|---|---|---|---|
| 巨人 | 20876 | 590634 | 3.53 % |
| 中日 | 9989 | 250771 | 3.98 % |
| 広島 | 21979 | 442592 | 4.97 % |
| ヤクルト | 22888 | 400029 | 5.72 % |
| 阪神 | 13177 | 428525 | 3.07 % |
| DeNA | 28083 | 564144 | 4.98 % |
| 日本ハム | 24105 | 415629 | 5.80 % |
| ソフトバンク | 26886 | 487349 | 5.52 % |
| 楽天 | 10877 | 256291 | 4.24 % |
| 西武 | 25462 | 528261 | 4.82 % |
| ロッテ | 15831 | 395208 | 4.01 % |
ちくちく度のランキングとは少し違う様子。
●:「ふわふわ度」が一番高いのは日ハム,一番低いのは阪神でした。
グラフにしてみた
◼︎ ちくちく度,◼︎ ふわふわ度
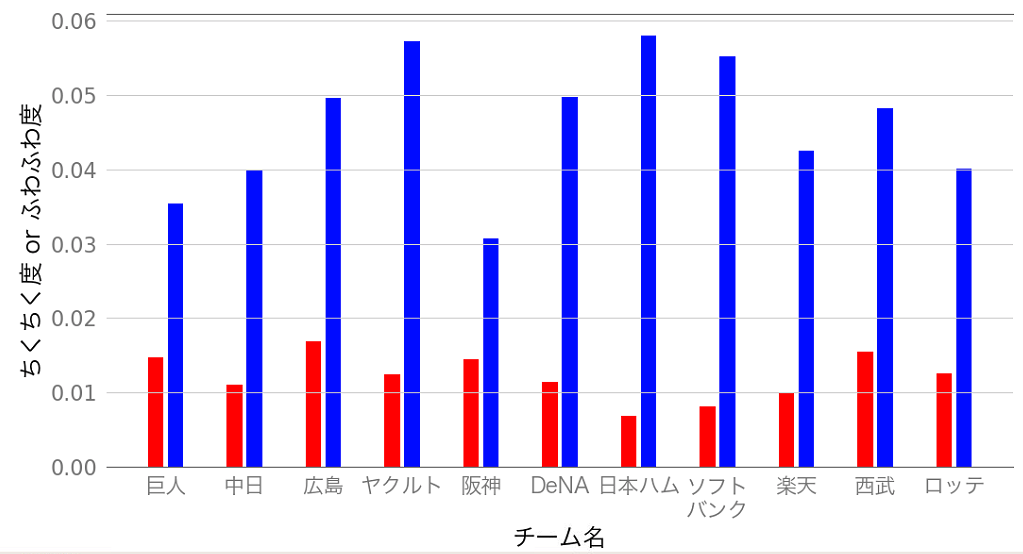
心の声(おい,阪神ファンの人たちもっと選手を褒めてやれよ!ツンデレか??)
考察
民度が低い投稿(ちくちく度)は,おおよそどの球団も1%前後ということがわかりました。
検索ワードの検討で,検索ワード(ちくちく言葉,ふわふわ言葉)を少し変えたりして実験してみはしましたが,大きく結果が変わることはありませんでした。
有意差の計算はしていないので,意味のある差かどうかはわかりませんでしたが,おおよそ予想どうりになったと思います。
勝率との関係性
勝率をx軸として,「ちくちく度」「ふわふわ度」「ふわふわ度/ちくちく度」をプロットしてみた。(勝率は以下のデータから 2019年度 公式戦成績)
点線は値の平均です。
「ふわふわ度/ちくちく度」は,この値が高いほど,ちくちく言葉が少なく,ふわふわ言葉が多いということになります。
(ふわふわ度のばらつきが大きいので,ふわふわ度にかなり左右される値かもしれませんが)
●:「ちくちく度」,●:「ふわふわ度」
●:「ふわふわ度/ちくちく度」
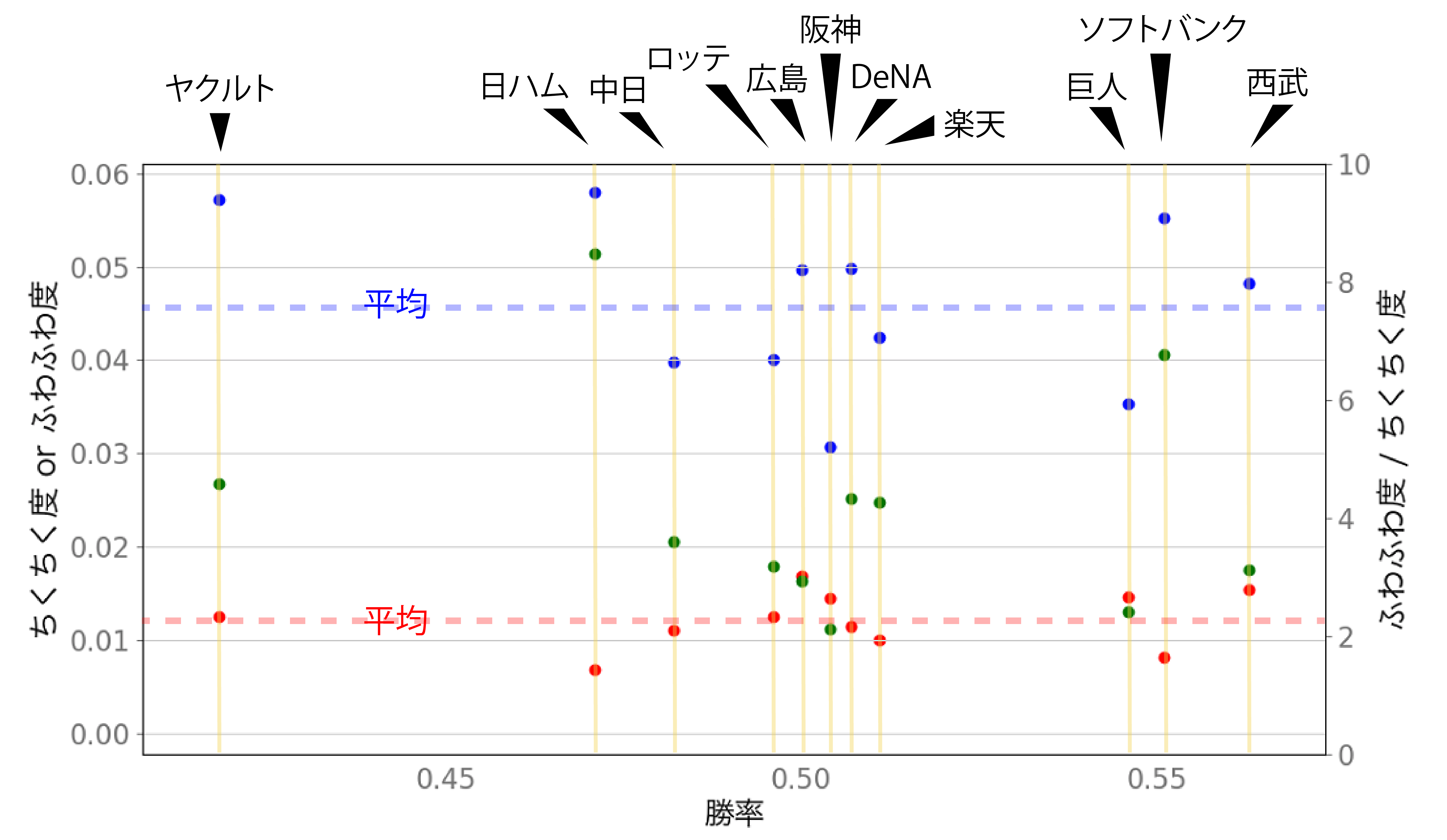
見事に相関がない。
つまりファンの民度依存の結果ということなのでしょうか,やっぱり。
でも,時期で分けてチームごとの変動を計算すれば,もしかしたら相関が現れるかもしれません。(ホンマか?)
「ちくちく度」「ふわふわ度」の関係
11球団の平均と比べたときに,球団の特徴が4つに分類できます。
ちくちく多・ふわふわ少 ➡︎ 巨人・阪神・ロッテ
ちくちく多・ふわふわ多 ➡︎ 広島・西武・ヤクルト
ちくちく少・ふわふわ少 ➡︎ 中日・楽天
ちくちく少・ふわふわ多 ➡︎ 日ハム・DeNA・ソフトバンク
上の方が民度が低めってことでいいんだろうか🤔🤔🤔
まとめ
ツイッターに概要をかきました
今回の分析だけでは,一概にどの球団のファンの民度が低いということは言えないですけど, だいたい,多くの人が思っているような結果になったんではないでしょうか。プロ野球の実況ツイートからファンの民度を測ってみた https://t.co/kqUciEzsBD #Qiita
— のんのさん🟣 (@p_lab_n) August 18, 2020
投稿しました! #npb #Qiita pic.twitter.com/SpNGQCExjV
とにかく言えることは,
割合として「ちくちく度」<「ふわふわ度」になったのは本当に良かった😌
あと,日ハムのファンの方たち素晴らしい👏👏👏
なんかもうちょっと考察が言える方がいらっしゃったら,コメントください。