学習曲線
さまざまな数のトレーニングサンプルに対して、訓練データに対するトレーニングスコアとクロスバリデーションに対するバリデーションスコアをプロットしたグラフ。
このグラフを見ることで、「High bias(未学習)」に陥っているのか、「High variance(過学習)」に陥っているのかがわかる。また、サンプル数を増やせばより良いモデルにすることができるのかの判断もできる。
バリデーションスコアとトレーニングスコアの両方が、サンプル数が大きくなるにつれて低すぎる値に収束した場合、サンプル数を増やしても効果は薄いことがわかる。つまり、パラメータや特徴量を見直した方が良い。(データをかき集めても時間の無駄に終わる可能性が高い)
学習曲線は、CourseraのMachine Learningコースにも出てくるので、まだの方は受講してみると良いと思います。
scikit-learn, matplotlibで学習曲線を描く
scikit-learnには、learning_curveメソッドがあるのでこれを使います。
このメソッドに以下の値を渡してあげると、トレーニングスコアとバリデーションスコアを計算してくれる。
- estimator → 検証したいモデル
- X → 入力データ
- y → 出力データ
- train_sizes → 試したいサンプル数([100, 200, 300, ..., 1000])
- cv → バリデーションデータセットを作成する際の分割方法(デフォルトは5-fold法)
他にも引数はいっぱいありますが、詳しくはドキュメントをみてください。
トレーニングスコアとバリデーションスコアを算出してみる
cancerのデータセットにLogisticRegressionを適用して、サンプル数が50, 100, 150, 200, 250, 300, 350個のときのトレーニングスコアとバリデーションスコアを算出してみる。
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
cancer = load_breast_cancer()
X = pd.DataFrame(cancer.data, columns=cancer.feature_names)
y = cancer.target
estimator = LogisticRegression()
# 50から350まで50刻みで検証する
train_sizes = np.arange(50, 351, 50)
# cvにintを渡すと k-foldの「k」を指定できる
# ↓では3にしているので、3-fold法を使用する。
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=3, train_sizes=train_sizes, random_state=42, shuffle=True
)
print("train_sizes(検証したサンプル数): {}".format(train_sizes))
print("------------")
print("train_scores(各サンプル数でのトレーニングスコア): \n{}".format(train_scores))
print("------------")
print("test_scores(各サンプル数でのバリデーションスコア): \n{}".format(test_scores))
print結果↓。3-fold法を指定したので、各サンプルで3つずつスコアが算出されている。
# 出力
train_sizes(検証したサンプル数): [ 50 100 150 200 250 300 350]
------------
train_scores(各サンプル数でのトレーニングスコア):
[[1. 1. 1. ]
[0.97 0.97 1. ]
[0.97333333 0.96666667 0.98 ]
[0.975 0.96 0.97 ]
[0.956 0.96 0.98 ]
[0.95333333 0.94333333 0.97666667]
[0.96 0.94571429 0.96857143]]
------------
test_scores(各サンプル数でのバリデーションスコア):
[[0.89473684 0.92631579 0.8994709 ]
[0.94736842 0.93684211 0.87830688]
[0.93157895 0.95789474 0.91534392]
[0.93157895 0.96315789 0.91005291]
[0.92631579 0.95263158 0.88888889]
[0.93157895 0.95789474 0.92592593]
[0.93684211 0.96842105 0.93650794]]
算出したトレーニングスコアとバリデーションスコアをプロットして学習曲線を描く
今回、3-fold方で分割したので、各サンプルで3つスコアがある。
まずは、平均と標準偏差を算出する
import numpy as np
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
これらの値を使ってプロットしていく
import matplotlib.pyplot as plt
plt.figure()
plt.title("Learning Curve")
plt.xlabel("Training examples")
plt.ylabel("Score")
# Traing score と Test score をプロット
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Test score")
# 標準偏差の範囲を色付け
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, color="r", alpha=0.2)
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, color="g", alpha=0.2)
plt.ylim(0.85, 1.0)
plt.legend(loc="best")
plt.show()
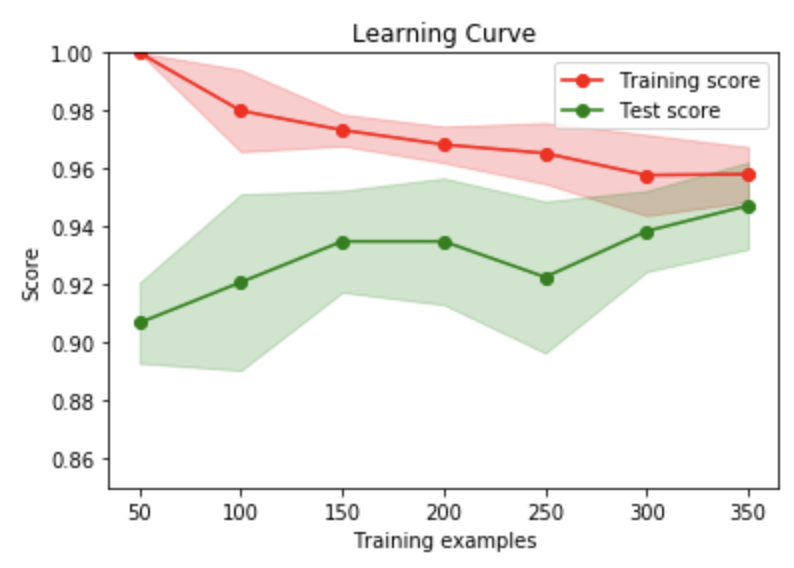
メソッド定義しておくと便利そう
scikit-learnのExampleにも書かれていますが、学習曲線を描くメソッドを定義しておくと簡単に確認できるので便利ですね!!