はじめに
- GKEに入門した時に確認したことのメモです。
Kubernetes構成概要
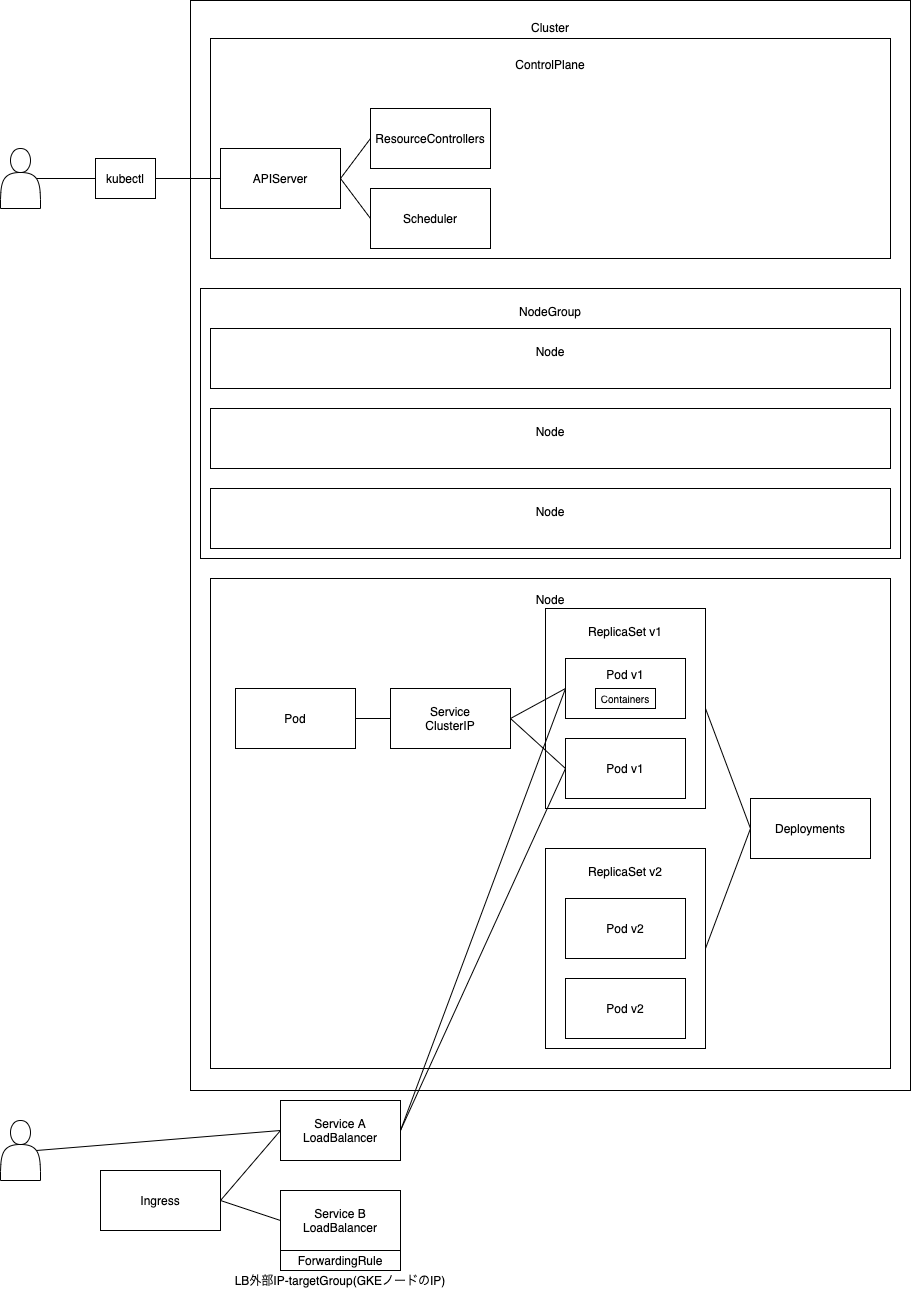
Kubernetes基礎
- Cluster = ControlPlane+Node
- Pod: 1つ以上のコンテナを含み、1つの機能を実現する論理的な単位
- ex.nginx が動作するPod
- Pod内のコンテナは、ネットワークやストレージを共有する(localhostでアクセス可能)
- Deployment: ReplicaSetとPodを管理するオブジェクト。指定されたPodの数を保つように動くReplicaSetに加えて、ローリングアップデートやロールバック機能を提供
- Job: Deploymentと同様に複数のPodを実行。JobはPodの正常な終了を追跡することが目的。並列化やリトライ回数の設定が可能
- Service: Deployment に対して外部からアクセス可能な IP アドレスを付与し、外部からアクセスできるようにしたもの
- Podへのアクセス
- ClusterIP
- クラスタ内部の通信に利用する
- 複数のPodに対してClusterIPと呼ばれる一つのIPと一つのDNS名を付与して抽象化することで負荷分散を実現する。一つのClusterIPに複数のPodIPが紐付く
- DNS名はk8sの内部DNSに自動的に登録される(core-dns) -> ここでClusterIPを取得する
- NodePort
- NodeのIPとポートを利用する
- LoadBalancer
- クラウドプロバイダーが提供するロードバランサーを利用する
- ClusterIP
- Ingress:
- 外部からのHTTP/HTTPSアクセスを
Serviceにルーティングする。NodePortまたはLoadBalancer - グローバル展開、パスでルーティングしたい場合に利用する
- リクエスト元のユーザの地理的近接性に基づいて、トラフィックが流れるtargetPoolを最も近いリージョンのものに自動的に設定する
- SSL証明書をインストール可能
- 外部からのHTTP/HTTPSアクセスを
- サービスメッシュ:
- サービスディスカバリ、サーキットブレイカー、オブザーバビリティ、セキュリティ
- 変化を自動的に検知し、アプリケーションから見た場合にシームレスなサービスディスカバリを提供する
- ディスク
- Pod内のコンテナのファイルシステムは揮発性
- ストレージ機能を抽象化したVolume
- Nodeのローカルストレージ、EBS、GCPのPersistent Disk、etc
- Persistent Volume: Volumeと異なりPodと切り離して作成可能
- Secret: base64でNodeに登録。Gitで管理しない、RBACを設定する
- namespace: リソース使用量のハードリミットとして、namespaceでクォータを設定可能。LimitRange
- オートスケール
- NodeとPodの2つのスケーリングを考える
- Pod: HPAとVPA
- HPAの計算式: 必要なレプリカ数 = 現在のレプリカ数×(現在のメトリクス値÷指定したメトリクス値)
- Node: Cluster Autoscaler、水平スケーリング
- ex. CPUの使用量が定めた値を超えるとPodがオートスケールする
- ResourceRequest/LimitsとQosクラス
- ResourceRequest: PodのコンテナごとにCPUやメモリ・エフェメラルストレージなどのリソース要求を行う
- → Podのスケジューリングの計算の際に利用。足りなければPendingになる。 → 過剰なRequest値を設定するべきではない
- ResourceLimits: コンテナランタイムはPod内のコンテナに設定されたLimitを超えないようにする。メモリの場合はOOM KillerによりプロセスをKillする
- QoSクラス: ResourceRequest/Limitsの設定内容から決まる。Nodeのリソースが枯渇した際にOOM KillerによってKillされるPodを選定する際の優先順位などに利用される
- きちんと設定されているかなど
- Priorityと違って、スケジューリングの優先順位に影響を与えない
- ResourceRequest: PodのコンテナごとにCPUやメモリ・エフェメラルストレージなどのリソース要求を行う
- Priority: Podがスケジューリングされる際やNodeから退避させられる場合に考慮される
- Nodeのリソース不足の時は、PriorityとQoSとの組み合わせで決まる
- Probeによるコンテナ監視
- Liveness Probe, Readiness Probe, Startup Probe
- Pod内で障害が発生しても、Liveness Probeにより自動で再起動される、etc
- コマンド実行、HTTPリクエスト、TCPコネクション
- Liveness Probe, Readiness Probe, Startup Probe
- ログ収集
- Fluentdなどのログ収集ツールをDaemonSetとして各ノードで起動する
- アップグレード
- Data Plane: AMI更新、Kubernetesアドオン・カスタムコントローラー・マニュフェストのアップグレード
- インプレースだが基本ダウンタイムなし
- Control Plane -> Data Plane
- Managed NodeGroupの場合、アップグレードコマンドを実行することで自動的にPodを安全に避難させてインプレースでNodeが更新される
- Kustomize: マニュフェスト管理ツール。開発・テスト・本番環境など複数環境を管理。ディレクトリを分けて、baseとoverlays/develop, production。-kオプション。
- Helm: パッケージマネージャ。aptのk8s版。リソースの作成・更新・削除・ロールバック。パッケージ=Chart。
helm install aws-load-balancer-controller ...- Terraformでも管理可能
- Flux: GitのソースとCluster上のリソースを定期的に監視、Cluster上で動作、kustomization.yamlの変更を検知してClusterへリリース、Gitのパスや監視間隔を設定
- Argo CD: FluxはCUIベースだが、Argo CDはGUIベース
GKE基礎
- ControlPlaneの管理不要
- ネットワーク
- クラスタ作成時に--networkで指定しないとdefaultネットワークに作成され、そこのファイアーウォールが適用されるので注意
- ControlPlaneは専用VPCに作成される、自動でピアリングされる
- ワーカーノードのIPアドレスに、サブネットのプライマリIP範囲を使用
- PodのIPアドレスに、セカンダリIP範囲を使用
- ServiceのCluster IPアドレスに、別のセカンダリIP範囲を使用
- ワーカーノードがホストされたVPC内からkubectlコマンドを実行
- 限定公開クラスターには、内部IPアドレスと外部IPアドレスの2つのエンドポイントが存在し、--internal-ipオプションを付けることで、外部IPアドレスではなく、内部IPアドレスのエンドポイントへ接続するように設定される
- GCRにアクセスするにはGCSの権限が必要
- GCRの脆弱性スキャン: メモとオカレンス
-
gcloud init: 自身が正常にGCPを触れるように専用のサービスアカウントを発行しローカルに保存する - ローカルで
gcloud components install kubectlでkubectlをインストールしておく - Autopilot
- ノードの管理が不用
- Podに関する課金のみ
- カーネルのチューニングはできない
GKE設計ポイント
- ワークロードの分散、課金管理、クォータ、料金コスト、運用コスト、拡張性
- ベースイメージ: マネージドベースイメージを使うか
- Public Cluster or Private Cluster
-
- No client access to the public endpoint
-
- Limited access to the public endpoint
-
- Unrestricted access to the public endpoint
-
- CIDR設計
- IP アドレス割り振りの最適化
- ノード、Pod、サービス、コントロールプレーン
- ノード以外はセカンダリ
- サービスは/24、コントロールプレーンは/28など
- ノードあたりのPod数なども考慮して決める
- IPマスカレード
- IAM権限付与
- Secretのマウント, Workload Identity, nodeに付与
- Workload Identity
- クラスタでWorkload Identity有効化
- GSAを作成し、KSAとのIAM policy Bindingを作成
- KSAを作成し、GSAへのアノテーションを追加
- PodでKSAを指定
- AutoScale
- NodeGroupの最大数に達してスケールできない場合のログ監視
- リージョン or ゾーン
- PodのAnti-Affinity
- ゾーン間でWorkloadを均等に配置するか
- リトライ設計
- ノードプール
- 学習と推論、GPU有無
- nodeselectorを利用するなど
- NameSpace, label
- environment: dev, など
- リソースクォータ制限
- ResourceQuota
- メンテナンスウィンドウ
- バージョンアップ
- マイナーバージョンアップデート
- 自動アップデート
- サージアップグレード
- バージョン情報の隠蔽
- ログ
- Node(Data Plane), Node(ホストOS), コンテナ
- Kustomize, KPT, namespace
- リソースをPodで指定させる、それを把握できるようにする。ノードのスペックを下げたがPodを下げ忘れて起動しない、とかが内容に
- JobとPodの使い分け
- Composerを使うときはリトライを寄せるからPodで良いのでは、とか
- Podが終了してもSuccessで残る、とかがある。削除してから新しいものを作る?
- モニタリング
- CPU利用率は注意。ノードかPodか。確保か利用か。
- ダッシュボードで取得できるCPU使用率はnamespaceごとのリクエストに対するCPU使用率
- 使用しているPodごとのCPU使用率を監視する場合にはLimitの設定が必要か
- Request: Podのスケジューリングなどで利用される、全体のリソースに余裕があればオーバーコミットされていても使用される
- 個別にLimitとRequestが設定されていないコンテナはRequestのみ設定される。0.1cores
コマンド
$ kubectl exec -n <namespace> -it pod1 -- bash
$ kubectl get node -n <namespace>
$ kubectl get pod
$ kubectl describe pod pod1
# port確認
$ kubectl get svc -n <namespace>
$ kubectl get deployment -n <namespace>
$ kubectl get deployment metrics-server -n kube-system
# Allocated resourceでNodeのリソースが予約されているか確認できる
$ kubectl describe nodes
# メトリクス確認
$ kubectl top node
# hpaによるPodのスケーリングを確認
$ kubectl get hpa -w