配列をそのまま取り扱えるデータ形式は少ない
Webでデータのやり取りをする時に、頻出のJSON形式。
GIS界隈、特にWebGIS界隈では、GIS用に拡張し、位置情報を標準で付与できるように拡張したGeoJSONが広く利用されていますが、普通のJSONとして取り扱うことも可能であるため非常に利用しやすく、またテキストデータであるため、人間が可読するのに優れ柔軟で良いデータ形式です。
ただまぁ柔軟というか仕様が緩い感じだと色んなことができちゃうわけで…
複数の地物のtypeを共存させることができたり、propertiesに配列とか辞書とか入れれちゃいます。
(GISデータで、Point + Polygonのように複数のtypeを格納できる形式はあまり存在しないです。)
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"int_array": [0, 1, 2, 3],
"string_dict": { "key": "value" }
},
"geometry": {
"type": "Point",
"coordinates": [141.43798828125, 43.052833917627936]
}
},
{
"type": "Feature",
"properties": {
"string_array": ["こんにちは", " GIS"]
},
"geometry": {
"type": "Polygon",
"coordinates": [
[
[141.44545555114746, 43.0469380870684],
[141.46386623382568, 43.0469380870684],
[141.46386623382568, 43.05932494785292],
[141.44545555114746, 43.05932494785292],
[141.44545555114746, 43.0469380870684]
]
]
}
}
]
}
まず、複数のレイヤーが単一ファイルで読み込めちゃうと、QGISなどとソフトウェアで読み込んだときに結局レイヤーを分けられてしまいます。
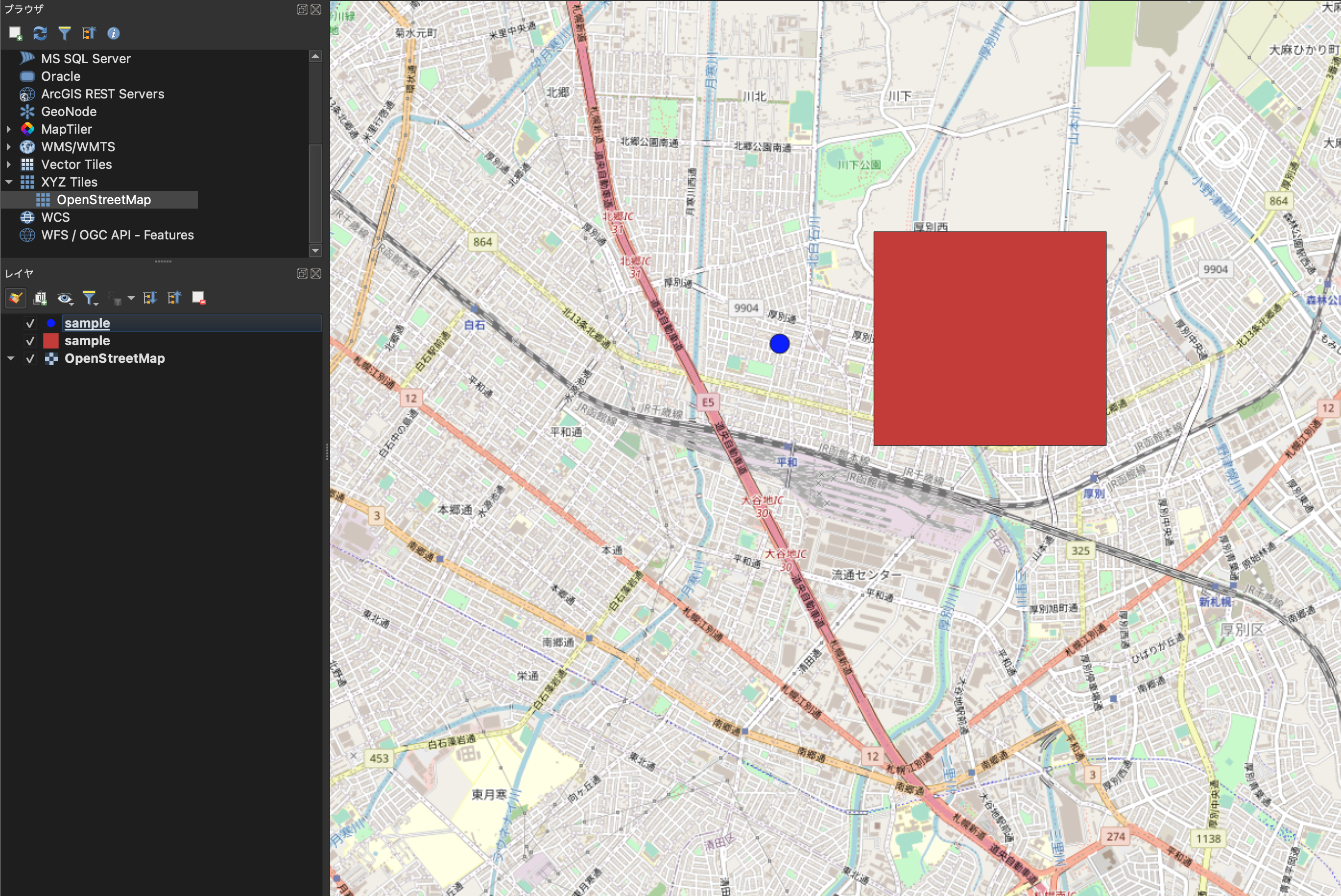
片方のtypeだけ読み込んだとしても、フィールドは各地物に付与されているものを全て拾ってきてしまうので、Pointの地物に存在していないはずのstring_arrayがnullとして表示されたりしちゃいます。
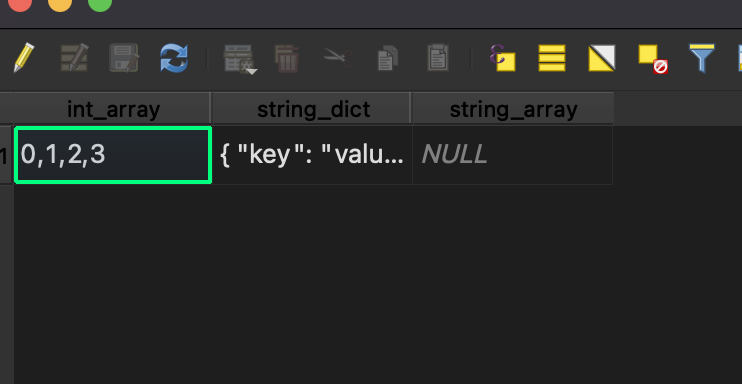
このようにPointはstring_array属性を持っていません。
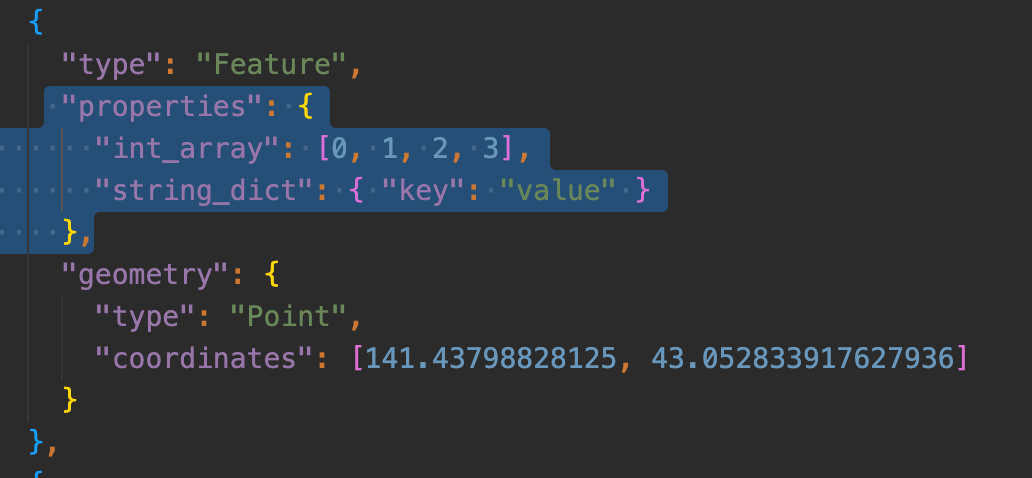
Pointのレイヤーを出力しようとすると、string_arrayが標準でエクスポートされるようになっちゃってますし、なんならstring_dictの方は連想配列ではなく、文字列型になっちゃっていたりと色々ややこしいですね。
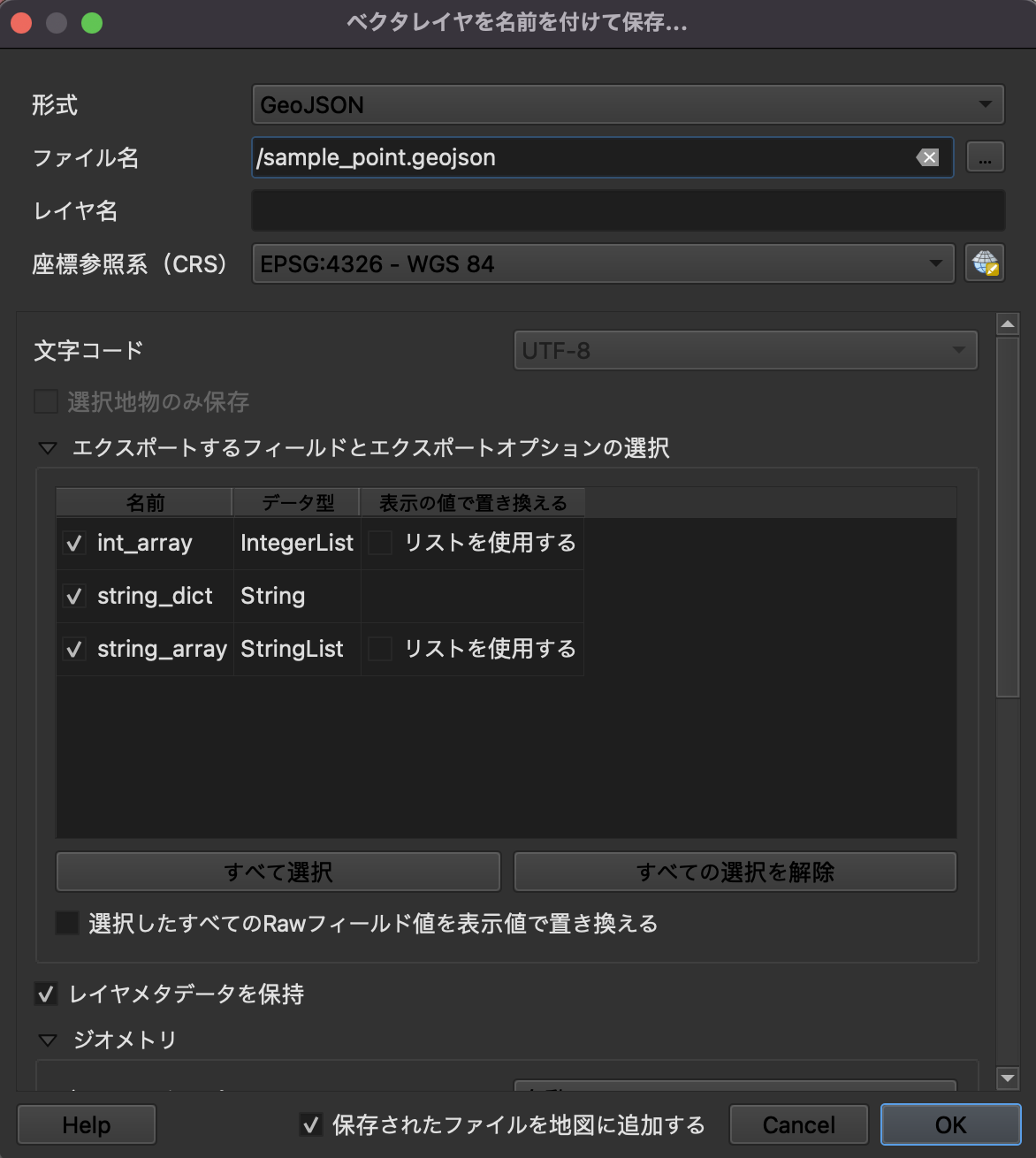
実際に吐き出してみるとこんな感じで、やっぱりstring_arrayはnullになっています。
(しかも文字列型って書いてたのに実際の値は連想配列のままなんかい…!っていう。)
{
"type": "FeatureCollection",
"name": "sample_point",
"crs": {
"type": "name",
"properties": { "name": "urn:ogc:def:crs:OGC:1.3:CRS84" }
},
"features": [
{
"type": "Feature",
"properties": {
"int_array": [0, 1, 2, 3],
"string_dict": { "key": "value" },
"string_array": null
},
"geometry": {
"type": "Point",
"coordinates": [141.43798828125, 43.052833917627936]
}
}
]
}
その他、色々データの管理やバリデーションが大変だったり、テキストデータなので大容量のデータを取り扱おうとするとI/Oがものすごい時間かかります。
他のフォーマットに変換してみる
で、GeoJSONだけを取り扱っているならまだいいんですが、大容量のデータだったり(100MBとかでも相当きついです)、他のフォーマットに変換が必要になったりするともう大変です。
配列をフィールドに格納しておけるフォーマットはほとんどなく、基本的にはカンマ区切り文字列になってしまいます。
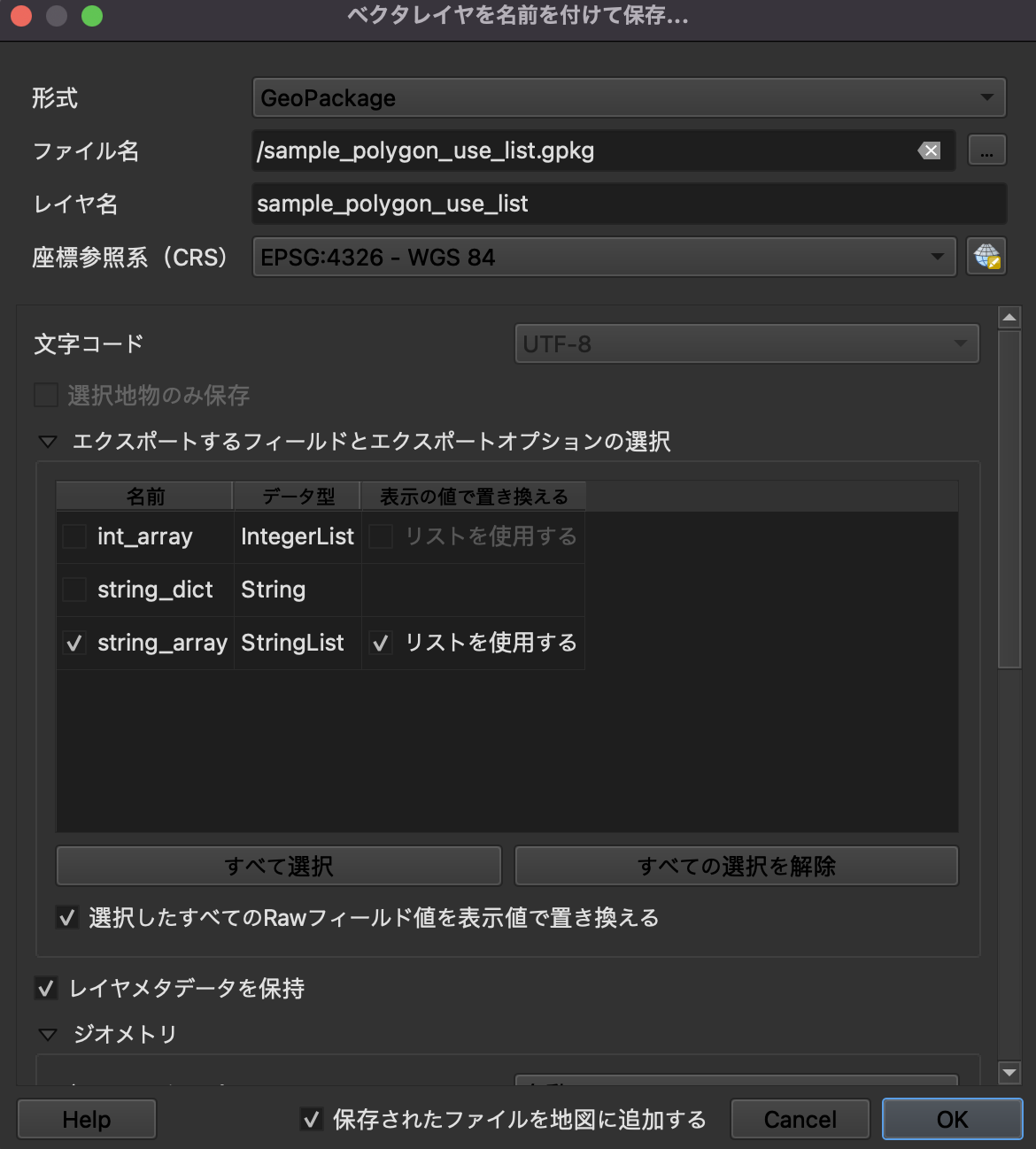
試しに、まずはQGISの標準エクスポート形式のGeoPackageでの出力を試みてみましょう。
先ほどのGeoJSONのPolygonの方はstring_arrayという属性が配列で値を持っているので、そちらのレイヤーを利用します。
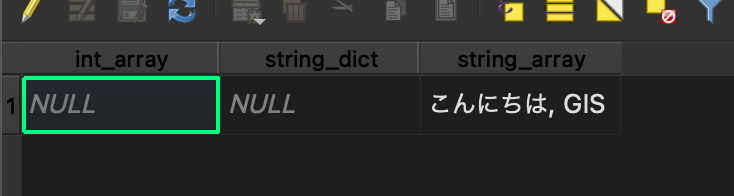
本来Polygonが持っていないはずの属性値のチェックボックスは外して、さらに「リストを使用する」のチェックは外しておきましょう。
(※後述しますが、この「リストを使用する」のオプションもめちゃくちゃややこしい動作をします)
そうするとちゃんとポリゴンが吐き出せましたね。
と、思った方!!!騙されないでくださいね!!!
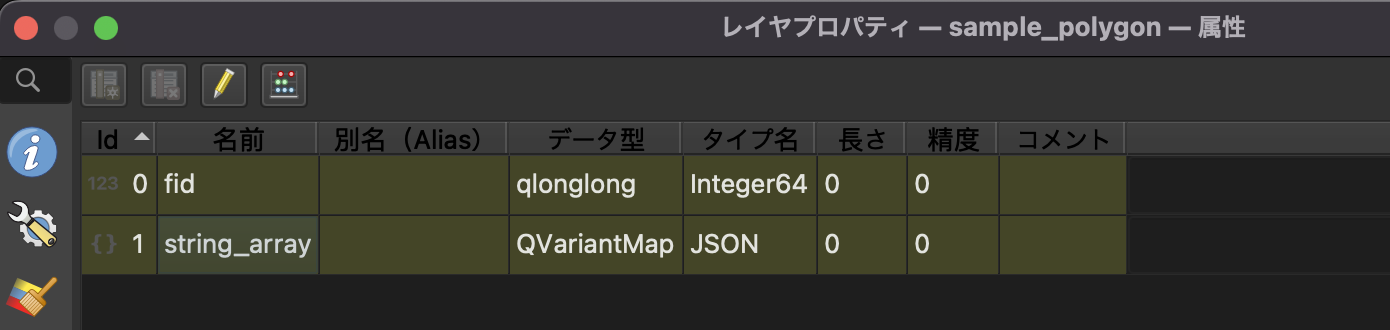
fidはGeoPackageで勝手に作られるフィールドなので置いといて…肝心のstring_arrayはJSON型に変更されています。
で、それだけならまだ良いんですが、なんと値が消えちゃうんですよね…
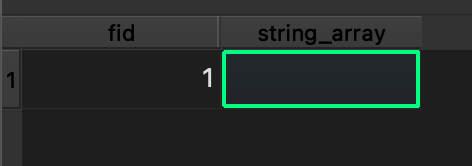
じゃあ「リストを使用する」にチェックを入れたらどうなるの!?っていうと…
カンマ区切り文字列になっちゃいましたー!
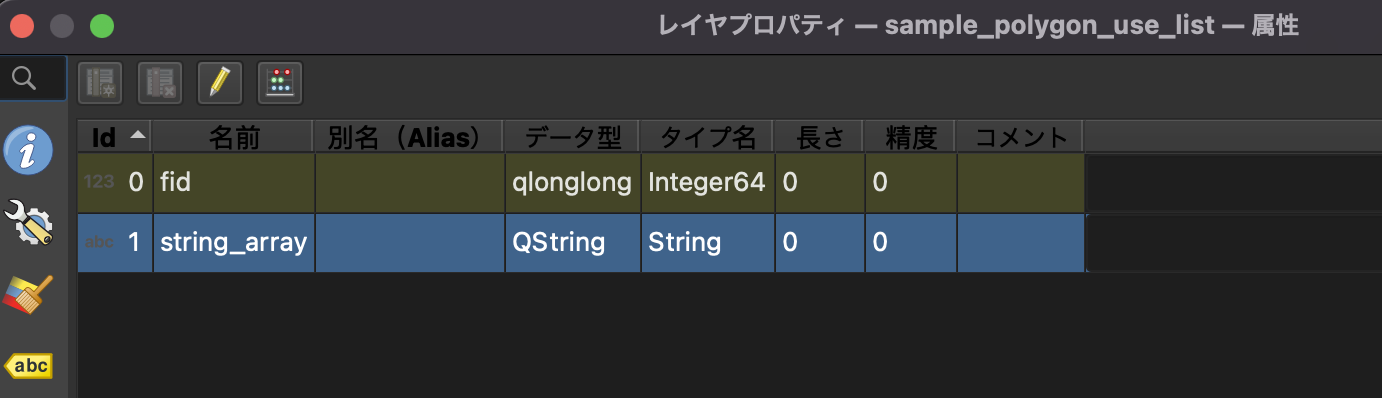
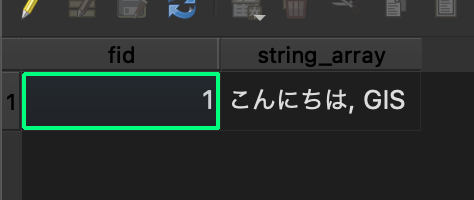
FlatGeobufやshapefileなど主要形式も同様で、配列には対応していないので、リストを使用しなければ値は消えてしまうし、リストを使用すれば文字列になります。
余談
じゃあ配列を持ったGeoJSONをGeoJSONに変換するとどうなるの?というと…
「リストを使用する」のチェックを外すと…
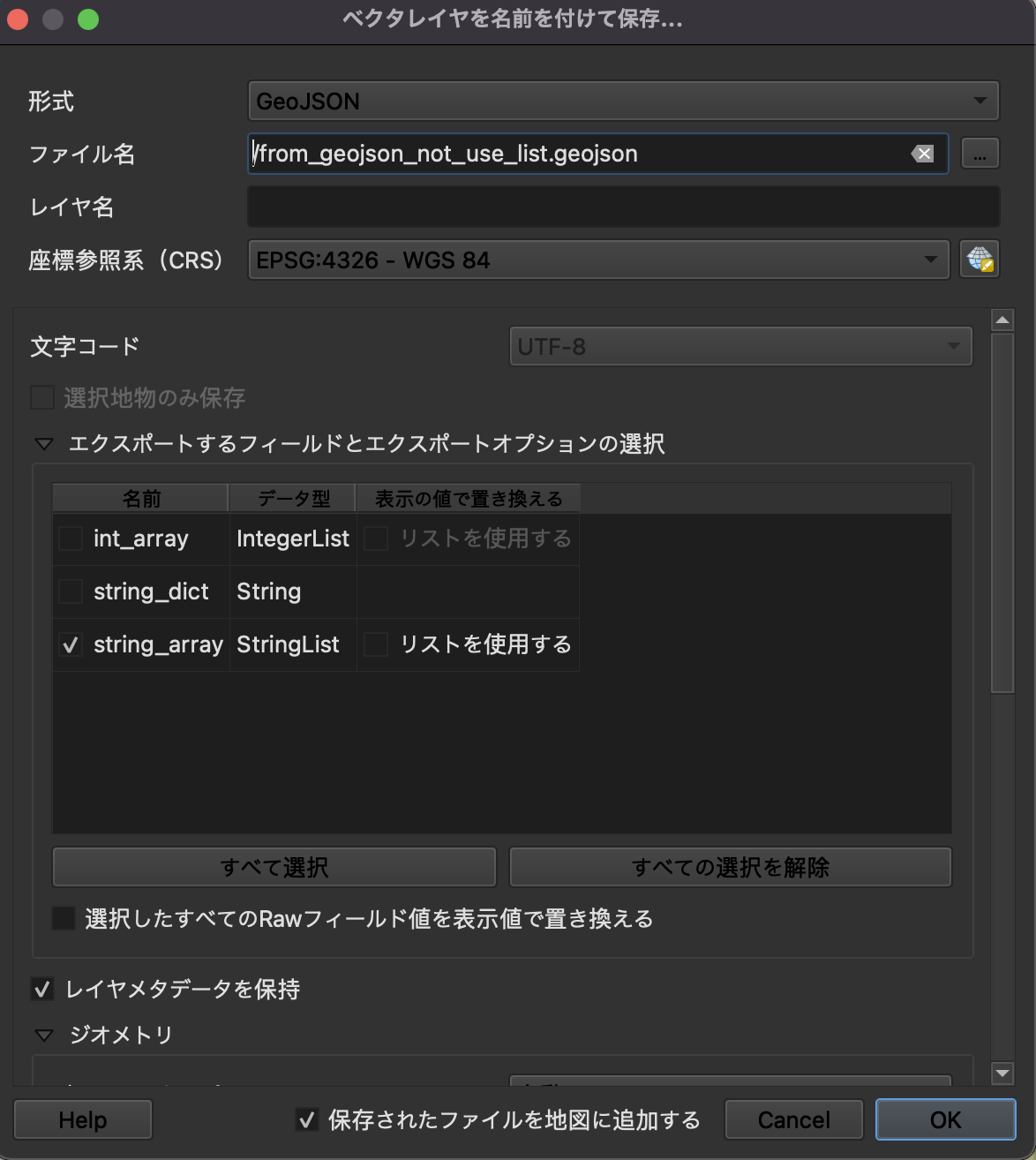
リストのまま出てきます

{
"type": "FeatureCollection",
"name": "from_geojson_not_use_list",
"crs": {
"type": "name",
"properties": { "name": "urn:ogc:def:crs:OGC:1.3:CRS84" }
},
"features": [
{
"type": "Feature",
"properties": { "string_array": ["こんにちは", " GIS"] },
"geometry": {
"type": "Polygon",
"coordinates": [
[
[141.445455551147461, 43.046938087068398],
[141.463866233825684, 43.046938087068398],
[141.463866233825684, 43.059324947852922],
[141.445455551147461, 43.059324947852922],
[141.445455551147461, 43.046938087068398]
]
]
}
}
]
}
「リストを使用する」にチェックを入れると…?
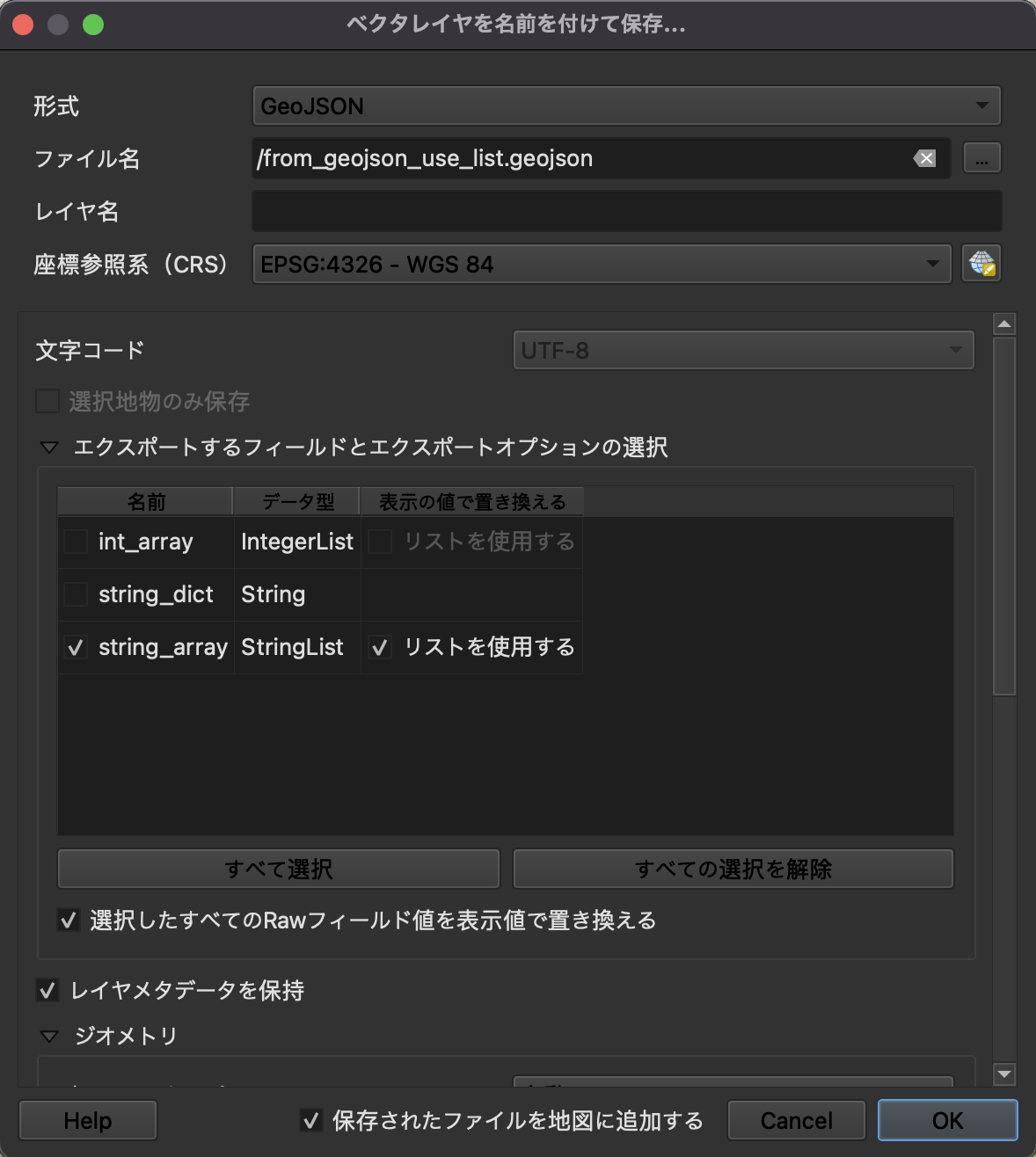
文字列に変換されてしまいます。
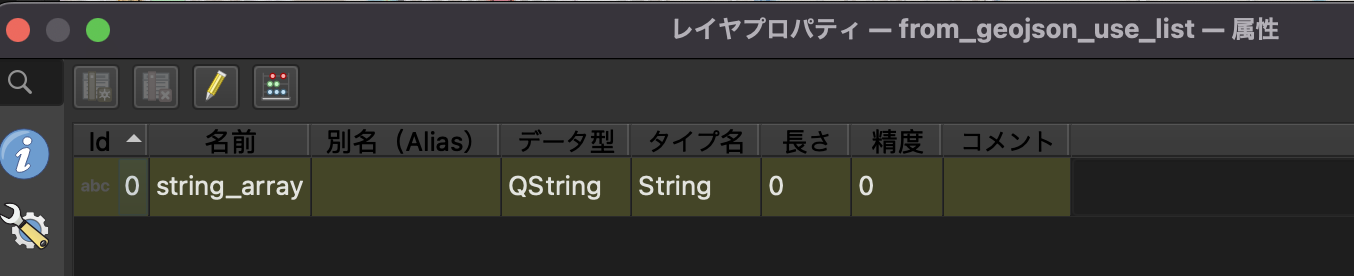
しかも、前後の文字列が日本語だからか、全角スペースが入っているっぽい…
{
"type": "FeatureCollection",
"name": "from_geojson_use_list",
"crs": {
"type": "name",
"properties": { "name": "urn:ogc:def:crs:OGC:1.3:CRS84" }
},
"features": [
{
"type": "Feature",
"properties": { "string_array": "こんにちは, GIS" },
"geometry": {
"type": "Polygon",
"coordinates": [
[
[141.445455551147461, 43.046938087068398],
[141.463866233825684, 43.046938087068398],
[141.463866233825684, 43.059324947852922],
[141.445455551147461, 43.059324947852922],
[141.445455551147461, 43.046938087068398]
]
]
}
}
]
}
つまり「リストを使用する」っていうオプションは「ここに格納されているのはリスト(配列)っぽいけど、リスト取り扱えないフォーマットがほとんどだよね。だからチェックを入れたらリストの中に入っている値を文字列に変換することで、暫定的に変換先のデータにも格納しといてあげるね」っていうオプションのようですね。
めっちゃややこしい…
大容量データだと尚更めんどくさい
軽量データであれば今までやってきたように、QGISなどのGUIツールで属性を確認しながらガチャガチャできますが、数百MBや数GBの大規模なデータセットであればそうはいきません。
冒頭で述べた通り、GeoJSONはテキストデータですので、I/O処理が重たい上、QGISで図形を表示するのに時間がかかり、画面移動のたびに同じだけの時間がかかり、属性の表示にも時間がかかり、なおかつ変換処理には失敗して処理落ちの可能性もあります。
このため、データ処理するためにはまずGeoJSONより軽快に操作できるGeoPackageやFlatGeobufなどに変換するのが一般的です。
が!!!!!前述の通りGUIでは色々と厳しいのでデータ変換に良く使われるogr2ogrを利用しようとすると、ここで問題が発生します。
先ほどから利用しているGeoJSONのPolygonのみ抽出したこんなGeoJSONがあるとして…
{
"type": "FeatureCollection",
"name": "sample_polygon",
"crs": {
"type": "name",
"properties": { "name": "urn:ogc:def:crs:OGC:1.3:CRS84" }
},
"features": [
{
"type": "Feature",
"properties": { "string_array": ["こんにちは", " GIS"] },
"geometry": {
"type": "Polygon",
"coordinates": [
[
[141.445455551147461, 43.046938087068398],
[141.463866233825684, 43.046938087068398],
[141.463866233825684, 43.059324947852922],
[141.445455551147461, 43.059324947852922],
[141.445455551147461, 43.046938087068398]
]
]
}
}
]
}
こんなコマンドでGeoJSONからGeoPackageに変換します。
ogr2ogr -f "GPKG" sample_polygon.gpkg sample_polygon.geojson
すると「そんな型はサポートしてねぇっす」とエラーが…
Warning 1: The output driver does not natively support StringList type for field string_array. Misconversion can happen. -mapFieldType can be used to control field type conversion.
実際、出力されたGeoPackageをQGISで開いてみると、文字列で出力されている上、何やら奇妙な文字列に変換されてしまいました。
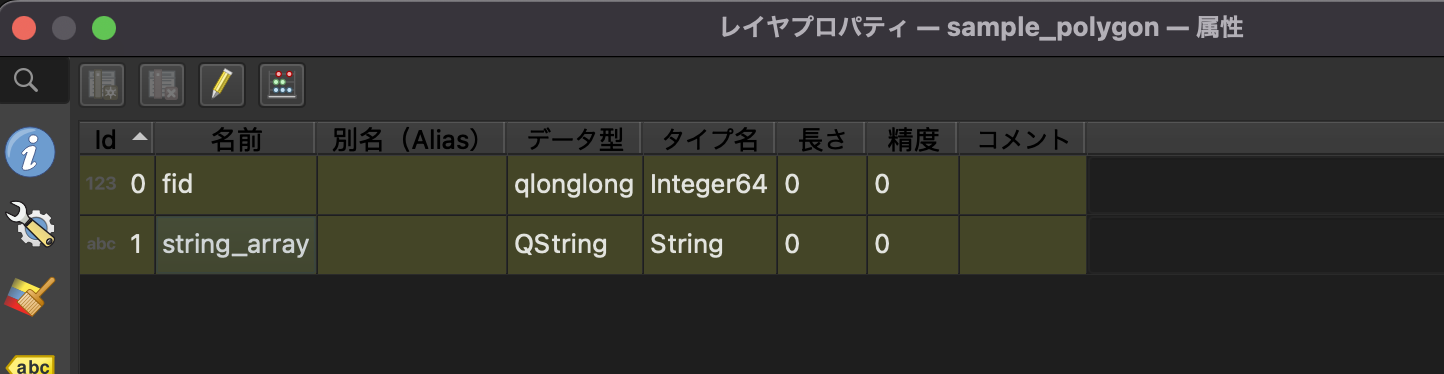
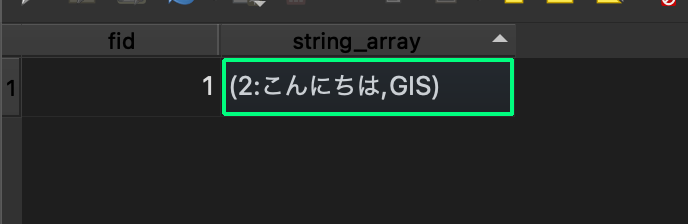
このように、データが重たいという理由で変換をかけたいのに、肝心なデータがスキップされてしまうので、手詰まりになってしまいました。
GeoPandasやpyogrioで他のフォーマットに変換しようとするともっと酷くて、pyogrioではエラーのためGeoDataFrameが生成できませんし、GeoPandasだとGeoDataFrameは生成できますが、配列を持っているカラムはスキップされます。
pyogiro
- ロード
import geojson
import geopandas
import pyogrio
# pyogrioではogr的に読み取れない型があったときにエラーが出る上、スキップできずpyogrioでは読み込めない
pyogrio_data = pyogrio.read_dataframe("./sample_polygon.geojson")
- エラー
Skipping field string_array: unsupported OGR type: 5
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [2], in <cell line: 1>()
----> 1 pyogrio_data = pyogrio.read_dataframe("./sample_polygon.geojson")
...
File pyogrio/_io.pyx:764, in pyogrio._io.ogr_read()
File pyogrio/_io.pyx:557, in pyogrio._io.get_features()
File pyogrio/_io.pyx:443, in pyogrio._io.process_fields()
TypeError: an integer is required
GeoPandas
dgf_data = geopandas.read_file(
"./sample_polygon.geojson",
driver="GeoJSON"
)
dgf_data.dtypes
# geometry geometry
# dtype: object
GeoPandasのGeoDataFrameを作成するだけでも一苦労します。
作成するには一度geojsonライブラリでgeojsonインスタンスを作成したのち、GeoPandasのfrom_featuresメソッドを利用して読み込む必要があります。
with open("./sample_polygon.geojson") as f:
geojson_data = geojson.load(f)
features_gdf = geopandas.GeoDataFrame.from_features(geojson_data)
features_gdf.dtypes
# geometry geometry
# string_array object
# dtype: object
features_gdf.head()
# geometry string_array
# 0 POLYGON ((141.44546 43.04694, 141.46387 43.046... [こんにちは, GIS]
type(features_gdf["string_array"])
# pandas.core.series.Series
が、結局GeoPackageなどに吐き出すためにはプログラムを書いて文字列に変換しておく必要がありますのでご注意ください。
GeoParquet
ちなみに、GeoParquetならそのまま吐き出せます!!!
features_gdf.to_parquet(
"./sample_polygon.parquet",
index=True,
compression="brotli",
)
が、最新版のogr2ogrで対応したばかりのフォーマットですし、QGISではまだ出力できないフォーマットですので、あまりおすすめできる方法ではないでしょう…
GeoParquetについてはこちら。
GeoPandasをやるならFlatGeobufより10倍早いGeoParquetを使おう!
結論
このため実質、配列に対応している汎用フォーマットはGeoJSONのみとなりますし、GeoJSONはファイルサイズが大きくなると他のフォーマットより処理速度に大きく遅れを取ります。
配列で属性を持とうとする以上、他の型よりも要素数が多くなる → ファイルサイズが大きくなることは目に見えているため、身動きが取れなくなってしまう可能性が高いです。
ということでGISデータに配列を格納するのはやめましょう!!!!
(やむを得ない場合でも、 危険性を理解して使ってね。)