average pairwise correlationってなに
いったいこの計算をする必要がある人が世界に何人いるかはおいといて。
average pairwise stock correlationとは株式どうしの値動きの相関係数の平均をとったものです。一般に、リーマンショックや欧州債務危機やらの危機時には市場全体が大きく下げ、その後反動で大きく上げる、という環境になり、株式同士の相関係数が高くなります。相関が跳ね上がるとどの銘柄も同じように動くので、アクティブ株式投資家が銘柄選択によって超過収益を稼ぐのが難しい市場環境になります。
ということで、この指標を使ってポートフォリオのリスクレベルを調整したり(勝てる見込みが少ないときにはリスクを落とす等)するのに使います。もっとしょぼい例としては、アクティブ株式運用者が「最近勝ててませんがこういう市場環境ですから勘弁して下さい」という言い訳に使ったりします...
pandasを使うとこんなに簡単
まずはデータを用意します。縦に日付(m日とします)、横に株式銘柄(n個とします)、各要素に株式の日次リターンが入ったDataFrame(m x n)を用意しましょう。
今回はデータは外で用意してcsvで読み込みました。
こちらの記事などを参考にして、pandasを使ってyahooから株価をダウンロードしてpct_change()メソッドを使って日次リターンに直してもよいでしょう。
そしていよいよ相関係数を計算するのですが、
# pairwise correlation の計算 (結果はPanel)
result = df.rolling(window=60, min_periods=30).corr()
rolling pairwise correlationの計算はこれ一行で完了!
やっていることは「その日までの日次リターンの60日ぶんの全銘柄間の相関係数をとった相関行列(n x n行列)を計算。ただし30日ぶんのデータがない銘柄についてはNoneとする。これを全日付で繰り返す」です。結果のresultはpandas.Panelオブジェクトで2次元のDataFrameに軸(時間軸)を一つ増やして3次元(m x n x n)になったものです。
correlationの計算はできましたが、平均をとるのにはひと工夫必要です。これは 1)相関行列なので対角成分には1が入っており、これを抜いた平均を取る必要がある 2)データ欠損で相関係数が計算できなかった場合はNone値が入っており、これを抜いた平均を取る必要がある という2つの理由からです。
まず対角成分の1ですが、Numpyのnp.fill_diagonal()を使い、None値に変更することにします。単一のDataFrameに対してはnp.fill_diagonal(df, None) のように使いますが、今回は次のようにapply()メソッドを使ってPanel全体に適用します。
# 対角成分をNoneに変換する
tmp = result.apply(lambda x: np.fill_diagonal(x.values, None), axis=(1,2))
次にmean(skipna=True)メソッドを適用して、None値を無視した平均値を計算します。これがaverage pairwise correlationです。こちらもapply()メソッド一発で時間軸にわたって適用します。
# Noneを無視して平均を計算する
apc = result.apply(lambda x: x.unstack().mean(skipna=True), axis=(1,2))
Panel.apply(..., axis=(1,2))とすると、時間軸を動きながら、各時点における相関行列をDataFrame x として取り出しながら順番に処理できます。
もう計算は完了です!プロットしてみます。
apc.plot()
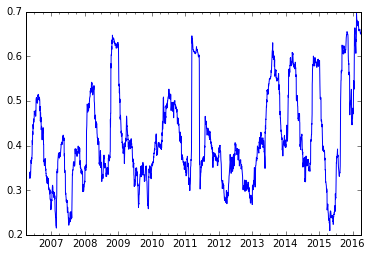
時折訪れる、マクロ要因に市場が左右される時期に相関が跳ね上がっているのがわかります。
おわりに
コードをまとめるとたったこれだけ。簡単ですね。
pandasは作者のWes McKinney氏がヘッジファンドのAQR Capital在職中に開発をはじめたものだけあって、金融データの取り扱いがとっても簡単にできるようになっています。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データ読み込み
df = pd.read_csv('data.csv', na_values=' ', index_col=0, parse_dates=True)
# pairwise correlation の計算 (結果はPanel)
result = df.rolling(window=60, min_periods=30).corr()
# 対角成分をNoneに変換する
tmp = result.apply(lambda x: np.fill_diagonal(x.values, None), axis=(1,2))
# Noneを無視して平均を計算する
apc = result.apply(lambda x: x.unstack().mean(skipna=True), axis=(1,2))
# プロットする
apc.plot()
参考文献
- Pandasドキュメント。
rollingメソッドはpandas 0.18.0以降で変更されたので、最新のpandasに更新してからお使い下さい。
http://pandas.pydata.org/pandas-docs/stable/computation.html#window-functions