Azure OpenAI Service で 7/6 から急に text-davinci-003 が新規デプロイできなくなった(既存でお使いの方は2024年7月5日まで使える)ため下記のコードが新規デプロイしようとすると動かなくなってます gpt-35-turbo を使うように変更されました。 アナウンスによると後継の Chat Completion API を使う gpt-35-turbo-instruct へ移行とのことですがまだそのモデルが登場していません。
なので回避策を考えます。これは gpt-35-turbo-instruct が登場してもおそらく使えるはず。上記コードでは、Azure Cognitive Search の検索ワードを text-davinci-003 に生成させていましたが、これを gpt-35-turbo へ置き換えます。
text-davinci-003 を gpt-35-turbo へ
API を ChatCompletion に変更し、ひとまず max_tokens を 100、temperature を 0.0 に設定します。
completion = openai.ChatCompletion.create(
deployment_id=self.chatgpt_deployment,
messages=messages,
temperature=0.0,
max_tokens=100,
n=1,
stop=["\n"]
)
System message
このアシスタントは、ユーザーの会話や新しい質問に基づいて質問文を検索クエリに変換します。
検索クエリは必ずスペースで区切ってください。
Example:###
Question:徳川家康ってなにした人
Search query: 徳川家康 人物 歴史
Question:徳川家康の武功を教えてください
Search query: 徳川家康 人物 武功 業績
Question:源範頼の墓所はどこにありますか?
Search query: 源範頼 墓所 墓
###
Few-shot で例を与え、テストします。
User message
Question:源範頼の簡単な情報と、彼のゆかりの地にあるいいカフェを教えて
Search query:
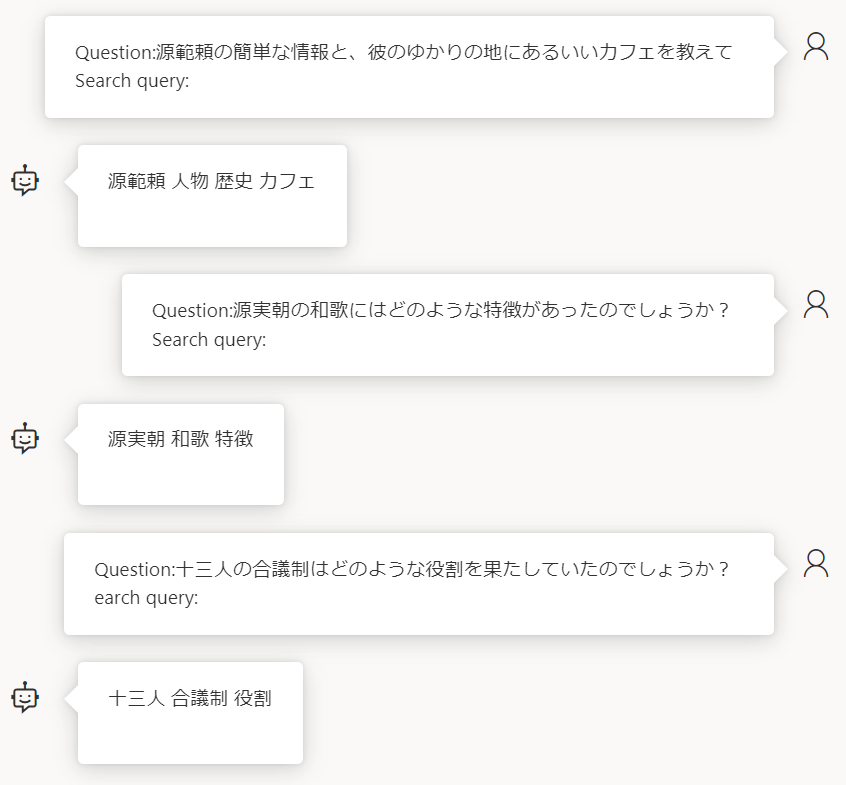
やるやん
でも同義語はうまく生成できていないみたいですね… このワードが Azure Cognitive Search 側で言語アナライザによる解析を受けます。
このレベルだったらそもそも ChatGPT 使って検索ワードを生成させる必要ないのでは?(ヲイ
ユーザーからの質問を直で Azure Cognitive Search に投げる
Azure Cognitive Search は全文検索エンジンですから、標準で日本語のアナライザーが使えます。検索クエリの生成を GPT-3 でさせずに、ユーザーの生の質問の解析を言語アナライザーに搭載されたトークナイザーにやらせてしまうとどうなるでしょうか。(Score を見るに on your data はそのような仕組みでは?)
{
"text":"源範頼の簡単な情報と、彼のゆかりの地にあるいいカフェを教えて",
"analyzer": "ja.lucene"
}
源範頼 簡単 情報 彼 ゆかり 地 いい カフェ 教える
…、まぁそうなるよな…
{
"text":"源実朝の和歌にはどのような特徴があったのでしょうか?",
"analyzer": "ja.lucene"
}
源実朝 和歌 どの 特徴
いいですね
{
"text":"十三人の合議制はどのような役割を果たしていたのでしょうか?",
"analyzer": "ja.lucene"
}
十 三 人 合議 制 どの 役割 果たす
これはちょっと微妙です…が OR 検索すれば欲しいドキュメントは得られそうですね。
めちゃくちゃ長い質問をされたときエライことになりそうですが。
同義語を生成させる
ChatGPT による検索クエリ生成では同義語が生成されていないので、こちらを生成させるように System message に以下を追加します。
**IMPORTANT**
検索クエリは、一般的な全文検索でヒットできるように、質問の意図に対して最低でも 3 つの同義語を生成し、
スペースで区切って追加する必要があります。

若干増えましたね。

Cool😎
ベクトル検索
Azure Cognitive Search にはベクトル検索機能がありますので、検索クエリ生成アプローチを使わなくとも質問者の意図を考慮した検索も可能ですのでこちらも検討します。すでに Tudor Golubenco さんがベクトル検索とキーワード検索を比較した記事を書いています。
ハイブリッド検索
ベクトル検索を使いつつキーワードのマッチも組み合わせることで、ベクトル検索では精度が出なかった場合のリカバリー策を講じることが可能です。
セマンティック検索
Azure Cognitive Search のセマンティック検索を十分に使うためには検索アルゴリズム側に意図を伝えなければなりませんので、前処理で質問文から意図を削除してしまうと機能が十分に働かない可能性があります。
おわりに
全文検索エンジンにおいて、適合率と再現率はトレードオフの関係ですから、どちらを重視するかを考える必要があります。このアーキテクチャにおいては多少検索ノイズが混じっていたとしても、トークン制限の中で検索結果を多く提供し、ChatGPT の質問応答能力によってカバーするというアプローチも考えられます。