Jaeger は、分散トレーシング(Distributed Tracing) を実現するためのオープンソースのツールであり、マイクロサービスや分散システムにおけるリクエストの流れを可視化・分析するために広く利用されています。元々は Uber によって開発され、現在は CNCF 傘下のプロジェクトとして継続的にメンテナンスされています。
分散システムでは、1つのリクエストが複数のサービスやコンポーネントを横断して処理されるため、ボトルネックの特定や障害調査が困難になります。Jaeger は、各処理ステップにおけるスパンと呼ばれる単位で情報を収集し、それらをトレースとしてまとめ、リクエストの全体像を時系列で表示します。
主な特徴として、
- トレースの収集と可視化:リクエストの流れをツリー構造で視覚的に表示
- レイテンシ分析:どの処理がボトルネックになっているかを把握可能
- 分散アーキテクチャとの統合:OpenTelemetry などの標準と連携可能

AutoGen 連携
AutoGen には、アプリケーションの実行に関する包括的な記録を収集するためのトレースと観測のサポートが組み込まれています。この機能は、デバッグ、パフォーマンス分析、そしてアプリケーションのフローを理解するのに役立ちます。
この機能は OpenTelemetry ライブラリを活用しているため、OpenTelemetry と互換性のある任意のバックエンドを使用してトレースを収集および分析できます。
トレースを収集して表示するには、テレメトリバックエンドを設定する必要があります。Jaeger、Zipkinなど、いくつかのオープンソースのオプションが利用可能です。この例では、テレメトリバックエンドとして Jaeger を使用します。
今回 Jaeger をローカルで即座に構築し、時系列ログを Elasticsearch で永続化する ネ申 Docker Compose を作成しました。
docker-compose.yml
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.2
container_name: jaeger-elasticsearch
environment:
- discovery.type=single-node
- node.name=jaeger-node
- cluster.name=jaeger-cluster
- path.data=/usr/share/elasticsearch/data
ports:
- "9200:9200"
volumes:
- ./esdata:/usr/share/elasticsearch/data
restart: unless-stopped
jaeger:
image: jaegertracing/all-in-one:1.68.0
container_name: jaeger
environment:
- SPAN_STORAGE_TYPE=elasticsearch
- ES_SERVER_URLS=http://elasticsearch:9200
- LOG_LEVEL=debug
ports:
- "16686:16686"
- "4317:4317"
- "4318:4318"
- "5778:5778"
- "9411:9411"
depends_on:
- elasticsearch
restart: unless-stopped
設定
cd jaeger
mkdir esdata
sudo chown -R 1000:1000 ./esdata
docker compose up -d
Jaeger ローカルサーバーの起動後、http://localhost:16686 にアクセスして Jaeger UI を開きます。
Jaeger に接続
コードの一番最初で以下のように Jaeger への接続設定およびトレーサープロバイダーの設定を行います。
from opentelemetry import trace
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.openai import OpenAIInstrumentor
service_name = "autogen"
# OTLPエクスポーターの設定 (gRPC経由で送信)
otlp_exporter = OTLPSpanExporter(
endpoint="http://localhost:4317", # JaegerのgRPCエンドポイント
)
tracer_provider = TracerProvider(resource=Resource({"service.name": service_name}))
# トレーサープロバイダーの設定
trace.set_tracer_provider(tracer_provider)
# バッチスパンプロセッサーを設定
span_processor = BatchSpanProcessor(otlp_exporter)
tracer_provider.add_span_processor(span_processor)
# トレーサーを取得
tracer = tracer_provider.get_tracer(service_name)
OpenAIInstrumentor().instrument()
シンプルなトレース
from autogen_ext.models.openai import OpenAIChatCompletionClient, AzureOpenAIChatCompletionClient
from autogen_agentchat.ui import Console
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.conditions import TextMessageTermination
model_client = AzureOpenAIChatCompletionClient(
azure_deployment="gpt-4.1-mini",
model="gpt-4.1-mini",
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-12-01-preview",
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
)
# Create the final reviewer agent
writer_agent = AssistantAgent(
"writer_agent",
model_client=model_client,
system_message="あなたはプロの小説家です。魅力的な文章を完結なタッチで書くことができます。",
)
stream = writer_agent.run_stream(task="SEが異世界に転生して無双する異世界転生系短編小説を書いてください。")
await Console(stream)
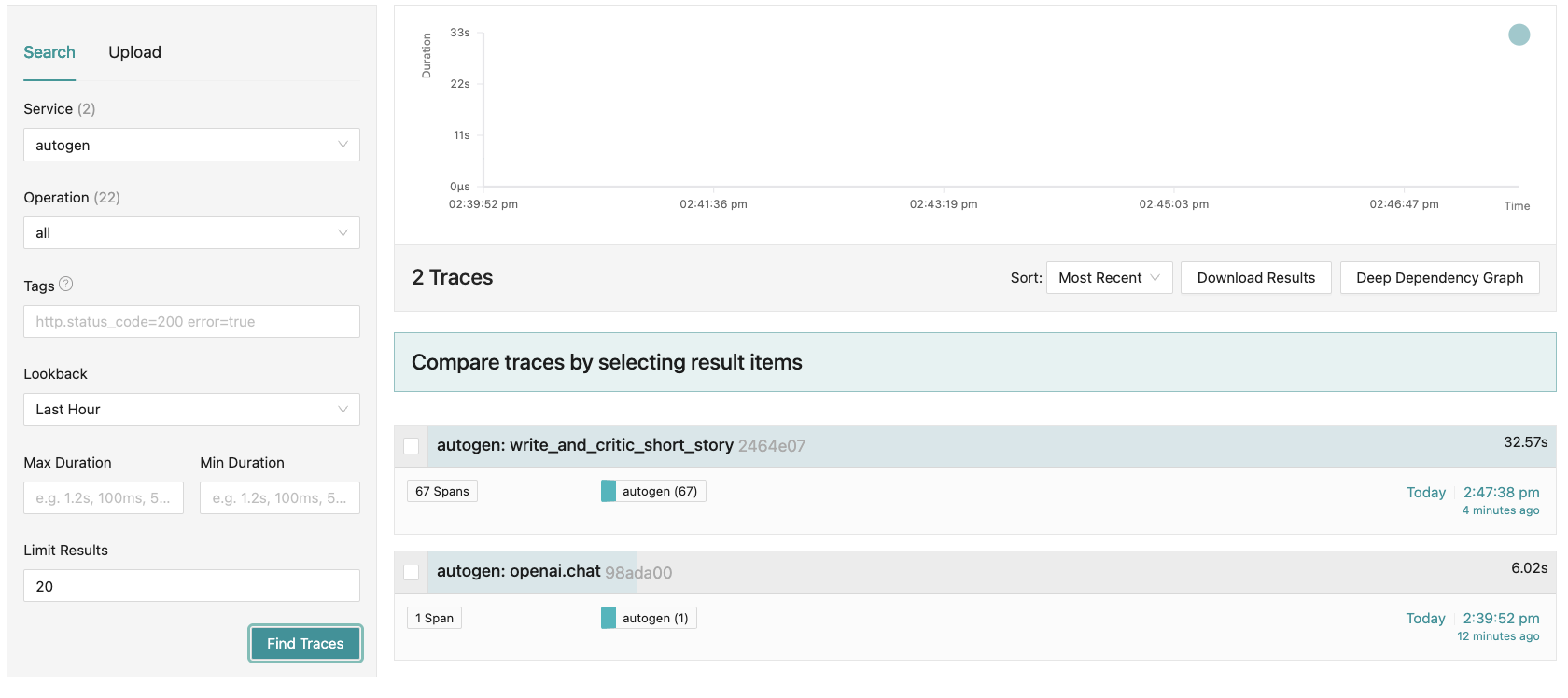
トレースの確認
http://localhost:16686 にアクセスし Jaeger UI を更新すると Service フィルタに autogen が追加されています。シンプル実行では Operation に openai.chat のみが入ります。

右ペインの検索結果一覧よりトレースエントリーを選択します。デフォルトの Timeline 表示がめちゃくちゃ便利です。各処理の実行時間やタイミングが一目でわかります。

独自のスパンを作成
複雑なマルチエージェントを開発していると、「ビジネスロジック」と「データモデル」の処理が混ざった部分を追跡したくなることがあります。OpenTelemetry では、こうした特定の処理部分を「スパン」という単位で記録することで、あとからその流れを確認できるようにします。スパンを自分で作って記録を始めたいときは、まず「トレーサー」というオブジェクトを使ってスパンの作成を開始します。
from typing import List
@tracer.start_as_current_span("write_and_critic_short_story")
async def write_and_critic_short_story():
current_span = trace.get_current_span()
# Set attributes for the current span
current_span.set_attribute("operation.critic_count", 3)
# Create the final reviewer agent
writer_agent = AssistantAgent(
"writer_agent",
model_client=model_client,
system_message="あなたはプロの小説家です。魅力的な文章を完結なタッチで書くことができます。",
)
# Create the final reviewer agent
critic_agent1 = AssistantAgent(
"critic_agent1",
model_client=model_client,
system_message="作成された文章を批判的な観点から評価し、改善点を提案すること。",
)
# Create the final reviewer agent
critic_agent2 = AssistantAgent(
"critic_agent2",
model_client=model_client,
system_message="あなたはリスクアドバイザーです。作成された文章のアイデア被りやSMS等で炎上しないかどうかを評価し、改善点を提案すること。",
)
# Create the final reviewer agent
critic_agent3 = AssistantAgent(
"critic_agent3",
model_client=model_client,
system_message="あなたは法学のスペシャリストです。作成された文章を法的観点から評価し、改善点を提案すること。",
)
# add agents to array
critic_agents: List[AssistantAgent] = [
writer_agent,
critic_agent1,
critic_agent2,
critic_agent3,
]
termination_condition = TextMessageTermination("critic_agent3") #3人目が発言したら終了
critic_team = RoundRobinGroupChat(critic_agents, termination_condition=termination_condition)
stream = critic_team.run_stream(task="SEが異世界に転生して無双する異世界転生系短編小説を書いてください。")
await Console(stream)
return
トレースの確認
AutoGen の AgentChat チームを実行した場合、数十のスパンが記録されます。
AutoGen のランタイムは既に以下のランタイムメッセージングイベント(メタデータ)をログに記録するようにインストルメント化されています。
-
create: メッセージが作成されたとき -
send: メッセージが送信されたとき -
publish: メッセージが公開されたとき -
receive: メッセージが受信されたとき -
intercept: メッセージがインターセプトされたとき -
process: メッセージが処理されたとき -
ack: メッセージがACKされたとき
デフォルトでは以下のように詳細なイベントが記録されます。実行時間が Timeline で可視化されるのが最も有用です。
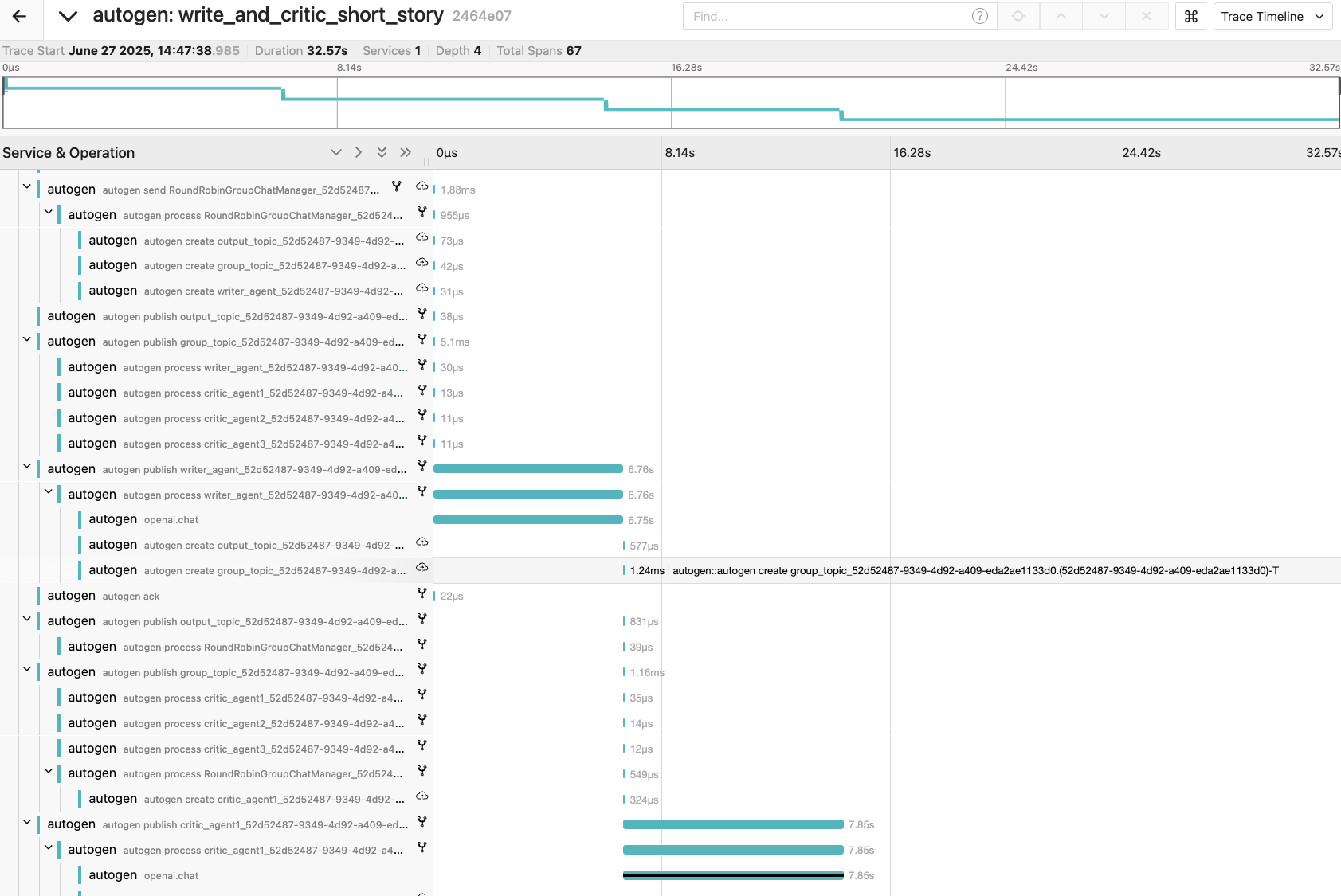
しかし逆に不要なイベントまで表示されてしまって、一番見たい openai.chat イベントがどこにあるかわからなくなる場合があります。この時は以下のようにフィルタを設定します。 openai.chat のエントリ数が自動的にカウントされ 4 と表示されていて、さらに Timeline 中で該当箇所が自動ハイライト&展開されます。

これによってマルチエージェントの実行順、推論内容を精密にデバッグできます。
AutoGen v0.6.0 で Concurrent 実行に対応
AutoGen v0.6.0 から GraphFlow が Concurrent 実行に対応しました。以下の例では、society_of_mind1 と society_of_mind2 が並行(concurrent)して実行され、両方の完了を待ってから summary_agent が実行されていることが分かります。

トレースデータの永続化
docker-compose.yml によって Docker の Elasticsearch に永続化され、時系列インデックスは docker-compose.yml の実行ディレクトリ ./esdata 以下に保存されます。
GitHub
参考