マルチエージェントの開発を行う上で、評価はどのように行うのが良いのでしょうか。最終回答の精度のみの評価だと本当に呼ばれるべきエージェントが呼ばれたのか、呼ばなくて良いエージェントを呼んでいないか、非効率な実行経路になっていないかなどを考慮することができません。
langchain-ai/agentevals のエージェントの軌跡(Trajectory)評価を使用すると、ルールベースでエージェントが適切なツールを呼び出しているかどうかを確認したり(オプションで厳密な順序で)、LLM を判定基準として使用して軌跡を評価したりできます。また、langchain に実装されている TrajectoryEvalChain も利用可能です。
4/2 🎉azure-ai-evaluation にエージェント評価用の新しい組み込み評価機能(プレビュー版)が追加されました!
- IntentResolutionEvaluator: エージェントがユーザーの意図をどれだけ正確に識別し解決したかを評価
- ResponseCompletenessEvaluator: エージェントがユーザーの問い合わせに対して返答した応答の完全性を評価
- TaskAdherenceEvaluator: エージェントがユーザーの問い合わせに対して返答したタスクの適合性を評価
- ToolCallAccuracyEvaluator: エージェントがユーザーの問い合わせに対して返答したツールコールの精度を評価
1. langchain-ai/agentevals
Install
pip install agentevals
Agent の遷移
今回取り上げるマルチエージェントパターンはこちらで紹介した Swarm パターンを例に見ていきたいと思います。Swarm は各エージェントの tool_calls を用いて次のエージェント遷移先を決定しています。評価器ではこの遷移の軌跡を事前に定義したリファレンスと比較します。
-
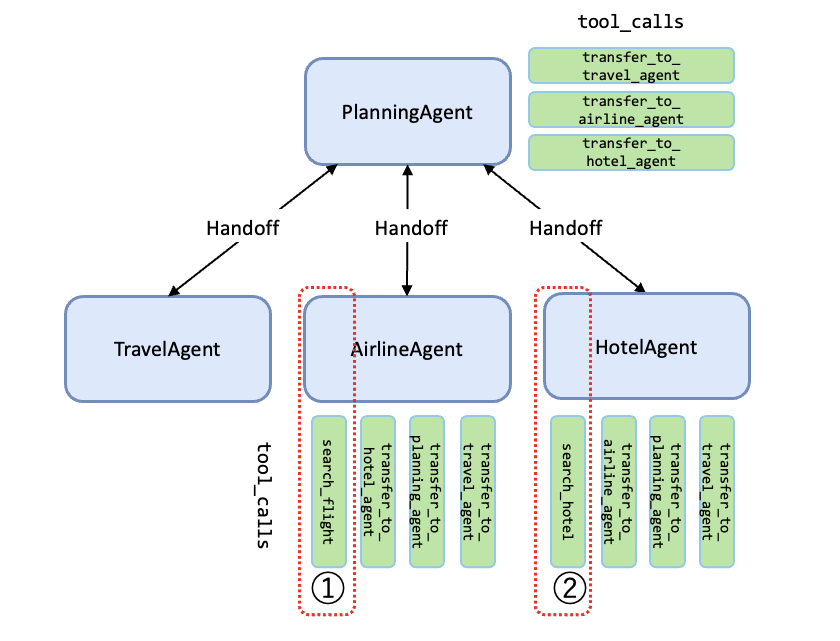
PlanningAgentが遷移先をAirlineAgentと決定 -
AirlineAgentがsearch_flight関数を実行 -
AirlineAgentが遷移先をHotelAgentと決定 -
HotelAgentがsearch_hotel関数を実行
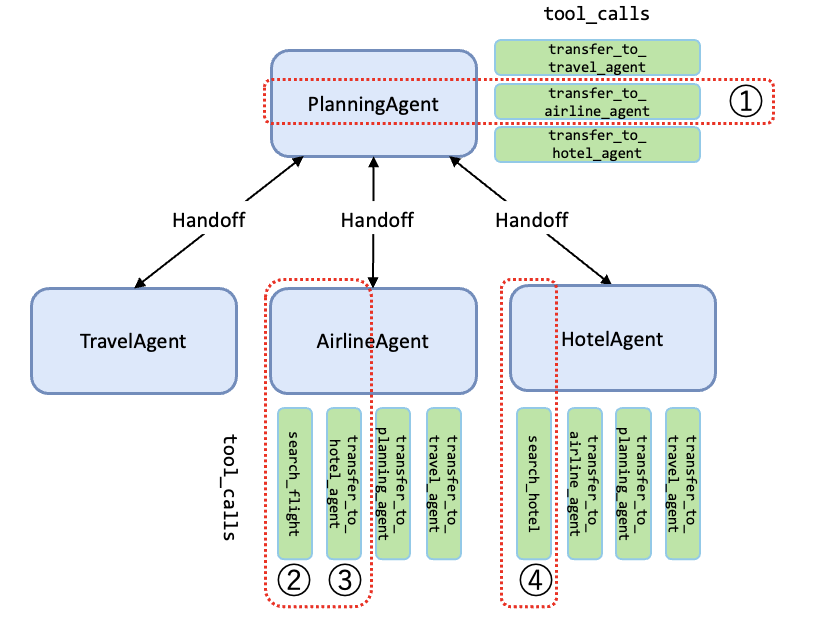
簡単のため、上図を下図と同義とみなすことによりシンプル化して説明します。
Strict match
trajectory_strict_match 評価器は、2つの軌跡を比較し、同じ順序で同じメッセージが含まれ、同じツールが呼び出されていることを確認します。メッセージの内容やツール呼び出しの引数の違いは許容されますが、各ステップで選択されたツールや順序が同じであることが要求されます。
import json
from agentevals.trajectory.strict import trajectory_strict_match
search_flight = {
"departure": "東京",
"destination": "福岡",
"arrival_time": "2025-02-01 19:00",
"passengers": 1,
}
search_hotel = {
"destination": "福岡",
"check_in": "2025-02-01",
"check_out": "2025-02-02",
"guests": 1,
}
outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
{
"role": "user",
"content": "東京から福岡への航空券をご案内いたします。\n\n- フライト番号: JL123\n- 航空会社: Japan Airlines (JAL)\n- 出発時刻: 2025年2月1日 16:30\n- 到着時刻: 2025年2月1日 18:50\n- 料金: 25,000円 (1名様)\n\nこのフライトでいかがでしょうか?\n\n### 次にホテルの手配についても確認を進めますか?",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_hotel",
"arguments": search_hotel,
}
}
],
},
]
reference_outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
{
"role": "user",
"content": "東京から福岡への航空券をご案内いたします。\n\n- フライト番号: JL123\n- 航空会社: Japan Airlines (JAL)\n- 出発時刻: 2025年2月1日 16:30\n- 到着時刻: 2025年2月1日 18:50\n- 料金: 25,000円 (1名様)\n\nこのフライトでいかがでしょうか?\n\n### 次にホテルの手配についても確認を進めますか?",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_hotel",
"arguments": search_hotel,
}
}
],
},
]
result = trajectory_strict_match(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_strict_match', 'score': True, 'comment': None}
search_flight->search_hotel の順で実行されたことが確認できれば True が返ります。順序を逆にしたり、tool_calls が足りないと False が返ります。
Unordered match
trajectory_unordered_match 評価器は、2つの軌跡を比較し、呼び出し順に関わらず同じ数のツールを含むことを保証します。
from agentevals.trajectory.unordered import trajectory_unordered_match
outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_hotel",
"arguments": search_hotel,
}
}
],
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
]
reference_outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_hotel",
"arguments": search_hotel,
}
}
],
},
]
result = trajectory_unordered_match(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_unordered_match', 'score': True, 'comment': None}
search_hotel と search_flight を入れ替えても True が返ることが確認できました。
Subset match
生成されたツール呼び出しの軌跡が、リファレンスに対して必要な呼び出しを不足なく満たしているか(スーパーセット)、もしくはその一部を満たしているか(サブセット)を評価します。
from agentevals.trajectory.subset import trajectory_subset
outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
]
reference_outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_hotel",
"arguments": search_hotel,
}
}
],
},
]
result = trajectory_subset(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_subset', 'score': True, 'comment': None}
Superset match
リファレンスの内容を全て含み、かつ余計なものがあってもOK
from agentevals.trajectory.superset import trajectory_superset
outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_hotel",
"arguments": search_hotel,
}
}
],
},
]
reference_outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
]
result = trajectory_superset(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_superset', 'score': True, 'comment': None}
Trajectory LLM-as-judge
LLM-as-judge 軌跡評価器は、軌跡を評価するために LLM を使用します。他の軌跡評価器と異なり、リファレンスを必要としないため、軌跡の比較に柔軟性を持たせることができます。もちろん Azure OpenAI も使えますよ。以下の例ではわざとホテル検索に失敗したパターンで評価してみます。
from agentevals.trajectory.llm import create_trajectory_llm_as_judge, TRAJECTORY_ACCURACY_PROMPT
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = "<Your Azure Endpoint>",
api_key="<Your Azure API Key>",
api_version="2024-08-01-preview"
)
inputs= "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。"
outputs = [
{
"role": "user",
"content": "東京から福岡、1人 2/1 19:00に空港到着したいな。あと当日のホテルも教えて。",
},
{
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "search_flight",
"arguments": search_flight,
}
}
],
},
{
"role": "user",
"content": "東京から福岡への航空券をご案内いたします。\n\n- フライト番号: JL123\n- 航空会社: Japan Airlines (JAL)\n- 出発時刻: 2025年2月1日 16:30\n- 到着時刻: 2024年2月1日 18:50\n- 料金: 25,000円 (1名様)\n\nこのフライトでいかがでしょうか?\n\n### 次にホテルの手配についても確認を進めますか?",
},
{
"role": "assistant",
"content": "ホテルが見つかりませんでした",
},
]
trajectory_evaluator = create_trajectory_llm_as_judge(
prompt=TRAJECTORY_ACCURACY_PROMPT,
model="gpt-4o",
judge=client
)
result = trajectory_evaluator(outputs=outputs, inputs=inputs)
print(result)
{'key': 'trajectory_accuracy', 'score': False, 'comment': "AIエージェントは、ユーザーのフライト要件を特定し、関連するフライトの詳細を提供することに成功した。しかし、ユーザーのクエリの一部でもあったホテル情報の検索には失敗した。この軌跡は、最初は論理的な推論を示したが、後半が不完全であったため、効率基準をオーバーライドしていると批判される可能性がある。したがって、このスコアは偽であるべきである。"}
AIエージェントは、ユーザーのフライト要件を特定し、関連するフライトの詳細を提供することに成功した。しかし、ユーザーのクエリの一部でもあったホテル情報の検索には失敗した。この軌跡は、最初は論理的な推論を示したが、後半が不完全であったため、効率基準をオーバーライドしていると批判される可能性がある。したがって、このスコアは偽であるべきである。
TRAJECTORY_ACCURACY_PROMPT
軌跡を評価するプロンプトは以下のように実装されています。
"""
あなたはデータ ラベラーのエキスパートです。
あなたの仕事は、AI エージェントの内部軌跡の精度を評価することです。
<Rubric>
正確な軌跡:
- ステップ間の論理的な意味がある
- 明確な進行を示す
- 比較的効率的ですが、完全に効率的である必要はありません
</Rubric>
まず、入力 (入力が存在しない場合は、最初のメッセージの内容から推測してください)
と最終メッセージの出力を見て、軌跡の目標を理解します。目標を理解したら、
その目標の達成に関連する軌跡を評価します。
次の軌跡を評価します:
<trajectory>
{outputs}
</trajectory>
{inputs}
"""
TrajectoryEvalChain
langchain-ai/agentevalsでは二値のスコアリングでしたが、langchain v0.3 系に実装されている TrajectoryEvalChain には 0-1 でスコアを返す評価器があります。実際に tool_calls を実行し、中間ステップを取得します。その中間ステップと最終出力を用いて評価します。
必要なツール search_flight をわざと呼ばないようにする
from langchain.agents import AgentType, initialize_agent
from langchain_community.chat_models import ChatOpenAI, AzureChatOpenAI
from langchain.evaluation import TrajectoryEvalChain
from langchain.tools import tool
from datetime import datetime
@tool
def search_flight(departure: str, destination: str, arrival_time: str, passengers: int) -> str:
"""
Search for flights based on given conditions.
:param departure: Departure city.
:type departure: str
:param destination: Destination city.
:type destination: str
:param arrival_time: Desired arrival time (format: YYYY-MM-DD HH:MM).
:type arrival_time: str
:param passengers: Number of passengers.
:type passengers: int
:raises ValueError: If arrival_time format is invalid.
:return: Flight search results.
:rtype: str
"""
# Sample fixed result
result = {
"departure": departure,
"destination": destination,
"flight_number": "JL123",
"airline": "Japan Airlines",
"departure_time": "2025-02-01 16:30",
"arrival_time": "2025-02-01 18:50",
"price": 25000,
"currency": "JPY",
"passengers": passengers,
}
# Validate arrival_time
try:
datetime.strptime(arrival_time, "%Y-%m-%d %H:%M")
return str(result)
except ValueError:
error_message = "Error: Invalid arrival_time format. Use 'YYYY-MM-DD HH:MM'."
return error_message
@tool
def search_hotel(destination: str, check_in: str, check_out: str, guests: int) -> str:
"""
Search for hotels based on given conditions.
:param destination: Destination city.
:type destination: str
:param check_in: Check-in date (format: YYYY-MM-DD).
:type check_in: str
:param check_out: Check-out date (format: YYYY-MM-DD).
:type check_out: str
:param guests: Number of guests.
:type guests: int
:raises ValueError: If check_in or check_out format is invalid.
:return: Hotel search results.
:rtype: str
"""
# Sample fixed result
result = {
"destination": destination,
"hotel_name": "Grand Fukuoka Hotel",
"check_in": check_in,
"check_out": check_out,
"price_per_night": 12000,
"currency": "JPY",
"guests": guests,
"total_price": 24000,
}
# Validate check_in and check_out
try:
datetime.strptime(check_in, "%Y-%m-%d")
datetime.strptime(check_out, "%Y-%m-%d")
return str(result)
except ValueError:
error_message = "Invalid date format. Use 'YYYY-MM-DD'."
return error_message
llm = AzureChatOpenAI(
azure_deployment="gpt-4o",
openai_api_version="2024-08-01-preview",
azure_endpoint="<your-azure-endpoint>",
openai_api_key="<your-openai-api-key>"
)
agent = initialize_agent(
tools=[search_hotel],
llm=llm,
agent=AgentType.OPENAI_FUNCTIONS,
return_intermediate_steps=True,
)
question = "東京から福岡、1人 2/1 19:00に空港到着したいな。あとホテルも探して。"
response = agent(question)
eval_chain = TrajectoryEvalChain.from_llm(
llm=llm, agent_tools=[search_flight, search_hotel], return_reasoning=True
)
result = eval_chain.evaluate_agent_trajectory(
input=question,
agent_trajectory=response["intermediate_steps"],
prediction=response["output"]
)
print(result["score"])
score: 0.25
Output
'東京から福岡へのフライトについて、出発時間や到着時間などの条件に基づいて検索する機能は現在利用できません。ただし、フライトの手配についてのアドバイスや情報提供は可能です。\n\n一方で、福岡でのホテルについては探すことができます。以下の情報を教えていただけますか?\n\n1. チェックイン日(例: 2024-02-01)\n2. チェックアウト日(例: 2024-02-02)\n3. 予算やホテルの希望条件(例: 駅近、温泉付きなど)\n\n教えていただければ、最適なホテルを探します!'
reasoning
Step-by-Step Evaluation:最終的な回答は役に立ったか:最終的な回答は部分的に役に立った。ユーザーはフライト検索とホテル検索の両方を要求しましたが、AIモデルはその要求に部分的にしか対応しませんでした。この目的のために特定のツール(
search_flight)が提供されていたにもかかわらず、AIモデルはフライト検索を実行できないと主張しました。ホテルについては、AIモデルは追加情報(チェックイン日やチェックアウト日など)を要求したが、これは妥当なことだが、search_hotelツールをまったく活用できなかった。全体的に、応答は不完全で、ユーザーの要求を満たしていない。
必要なツールを呼ぶように変更
agent = initialize_agent(
tools=[search_flight, search_hotel],
llm=llm,
agent=AgentType.OPENAI_FUNCTIONS,
return_intermediate_steps=True,
)
score: 1.0
Output
'以下の条件で予約可能なフライトとホテルを見つけました。\n\n### フライト\n- 航空会社: Japan Airlines (JL123)\n- 出発地: 東京\n- 目的地: 福岡\n- 出発時刻: 2024年2月1日 16:30\n- 到着時刻: 2024年2月1日 18:50\n- 料金: 25,000円 (1名分)\n\n### ホテル\n- ホテル名: Grand Fukuoka Hotel\n- チェックイン: 2024年2月1日\n- チェックアウト: 2024年2月2日\n- 料金: 1泊12,000円\n- 合計料金: 24,000円 (税込み, 1名分)\n\n予約をご希望ですか?'
reasoning
AIの性能評価:最終回答は役に立ったか: 最終回答は役に立った。
AIはリクエストされたフライトとホテルの両方について、航空会社、出発と到着の時間、費用を含む詳細な情報を提供した。同様に、ホテルについても、チェックインとチェックアウトの日付、価格、総費用など、包括的な詳細を提供してくれました。応答は構造化されており、すべて日本語で、ユーザーの問い合わせの言語と一致している。
AI言語は論理的なツールの順序で質問に答えているか。
AIはまずsearch_flightツールを使って指定された到着時刻に合うフライトを探し、次にsearch_hotelツールを使って目的地(福岡)のホテルを探す。この順番はユーザーのリクエストと一致している。
AI言語モデルは有用な方法でツールを使用していますか? search_flight
ツールは、ユーザーによって提供された正しい入力パラメー タ(出発地、目的地、到着時間、乗客数)で使用された。同様に、search_hotel`ツールは、目的地の都市、チェックインとチェックアウトの日付、宿泊者数といった適切な入力パラメータで使用された。どちらのツールも適切で正確な出力を返した。
AI言語モデルは質問に答えるために多くのステップを使いすぎましたか?
フライト検索とホテル検索の2つのステップでタスクを完了しました。これは効率的で、ユーザーのリクエストに適切です。search_flightツールはフライトを検索するために使用され、search_hotel`ツールはホテルを検索するために使用されました。無関係なツールは呼び出されなかった。
評価プロンプト例
"""
AIの言語モデルには、ユーザーの質問に答えるのに役立つ以下のツール群へのアクセスが与えられている。
AIモデルに与えられたツールは以下の通りです:
[TOOL_DESCRIPTIONS]
{tool_descriptions}
[END_TOOL_DESCRIPTIONS
人間がAIモデルに尋ねた質問は次のとおりである:
[QUESTION]
{question}
[END_QUESTION]{reference}
AI言語モデルは、質問に答えるために以下のツールセットを使用することを決定した:
[AGENT_TRAJECTORY]
{agent_trajectory}
[END_AGENT_TRAJECTORY]
AI言語モデルの質問に対する最終的な回答は、次のようになった:
[RESPONSE]
{answer}
[END_RESPONSE]
AI言語モデルの回答を step by step で詳しく評価してみましょう。
1点から5点までのスコアをつける前に、以下の基準を考慮します:
i. 最終的な回答は役に立つか?
ii. AI言語は、質問に答えるためにツールの論理的なシーケンスを使用しているか?
iii. AI言語モデルは有用な方法でツールを使用しているか?
iv. AI言語モデルは、質問に答えるために多すぎるステップを使用しているか?
v. 質問に答えるために適切なツールが使われているか?
"""
このスコアリングプロンプト、いろんなところで使えそうです😁
2. azure-ai-evaluation
Azure AI Evaluation SDK は、生成 AI アプリケーションのパフォーマンスを評価するフレームワークです。
Intent Resolution Evaluator
インテント解決評価機能は、エージェントがユーザーの意図をどれだけ正確に識別し解決したかを測定します。 スコアは1から5の整数で評価され、以下のようになります。
- スコア1:ユーザーの意図とはまったく関係のない応答
- スコア2:ユーザーの意図とわずかに関連する応答
- スコア3:ユーザーの意図を部分的に満たすが、詳細が完全ではない応答
- スコア4:ユーザーの意図をある程度正確に満たすが、若干の不正確さや省略がある応答
- スコア5:ユーザーの意図に直接対応し、完全に解決する
Response Completeness Evaluator
レスポンスの完全性評価機能は、エージェントの回答がどれだけ提供された基準データと一致しているかを評価することで、その品質を評価します。スコアは1から5の整数で評価され、以下のようになります。
- スコア 1:完全な不完全性:回答は基準データと比較して、必要な関連情報をすべて欠いている
- スコア 2:かろうじて完全:回答に必要な情報の割合はわずか
- スコア 3:中程度の完全性:回答に必要な情報の約半分を含んでいる
- スコア 4:ほぼ完全: 回答には必要な情報のほとんどが含まれており、わずかな抜けがある程度
- スコア 5:完全: 回答は、グランドトゥルースのすべての必要な関連情報と完全に一致
Task Adherence Evaluator
タスク遵守評価機能は、エージェントが割り当てられたタスクや事前に設定された目標にどの程度従っているかを測定します。
スコアは1~5の整数で評価され、以下のようになります。
スコア1:完全な不遵守
スコア2:ほとんど遵守
スコア3:中程度の遵守
スコア4:大部分遵守
スコア5:完全遵守
Tool Call Accuracy Evaluator
ツールコール精度評価機能は、以下の点を検証することで、AIがツールをどの程度正確に使用しているかを評価します。
- 会話との関連性
- ツール定義に基づくパラメータの正確性
- 会話からのパラメータ値の抽出
- ツールコールの潜在的有用性
評価ツールは、2値のスコアリングシステム(0または1)を使用します。
- スコア0:ツールコールが関連性のない、または会話/定義にない情報を含む
- スコア1:ツールコールが関連性のある、会話から適切に抽出されたパラメータを含む
この評価では、ツール呼び出しが、ツール定義を適切に順守し、会話履歴に存在する情報を使用しながら、問い合わせへの対応に有意義に貢献しているかどうかを測定することに重点を置いています。
Azure AI Foundry カスタム評価フロー
以前、Azure AI Foundry の Prompt flow のカスタム評価フロー機能を使って独自の評価フローを作成しましたが、同じ要領で今回の軌跡評価を実装することができます。
参考