AutoGen は複雑なマルチエージェントを構成できますがその反面、デバッグが難しくなる傾向があります。今回は Azure AI Foundry のトレース機能を使って LLM のコールをトレースしてみましょう。
1. OpenAI SDK を Azure AI Foundry でトレース
まずシンプルに OpenAI SDK を使用して開発する場合は、コードをインストルメント化して、トレースが Azure AI Foundry に送信されるようにすることができます。
pip install azure-ai-projects azure-monitor-opentelemetry opentelemetry-instrumentation-openai
OpenAI SDK をインストルメント化
from openai import AzureOpenAI
from opentelemetry.instrumentation.openai import OpenAIInstrumentor
OpenAIInstrumentor().instrument()
Azure Application Insights リソースへの接続
こちらを参考に、Azure AI Foundry プロジェクトに関連付けられている Azure Application Insights リソースへの接続文字列を取得します。認証に Microsoft Entra ID を使用する必要がある Azure AI Project クライアントを使用します。
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
project_client = AIProjectClient(
credential=DefaultAzureCredential(),
endpoint="https://<YourFoundryService>.services.ai.azure.com/api/projects/xxx",
)
connection_string = project_client.telemetry.get_connection_string()
# Azure Application Insights にトレースを送信するように OpenTelemetry を構成します。
from azure.monitor.opentelemetry import configure_azure_monitor
configure_azure_monitor(connection_string=connection_string)
OpenAI SDK 実行
client = AzureOpenAI(
api_version="2024-12-01-preview",
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY")
)
completion = client.chat.completions.create(
model="gpt-4.1",
messages=[
{
"role": "user",
"content": "君の名はなんていうの?",
},
],
)
print(completion.to_json())
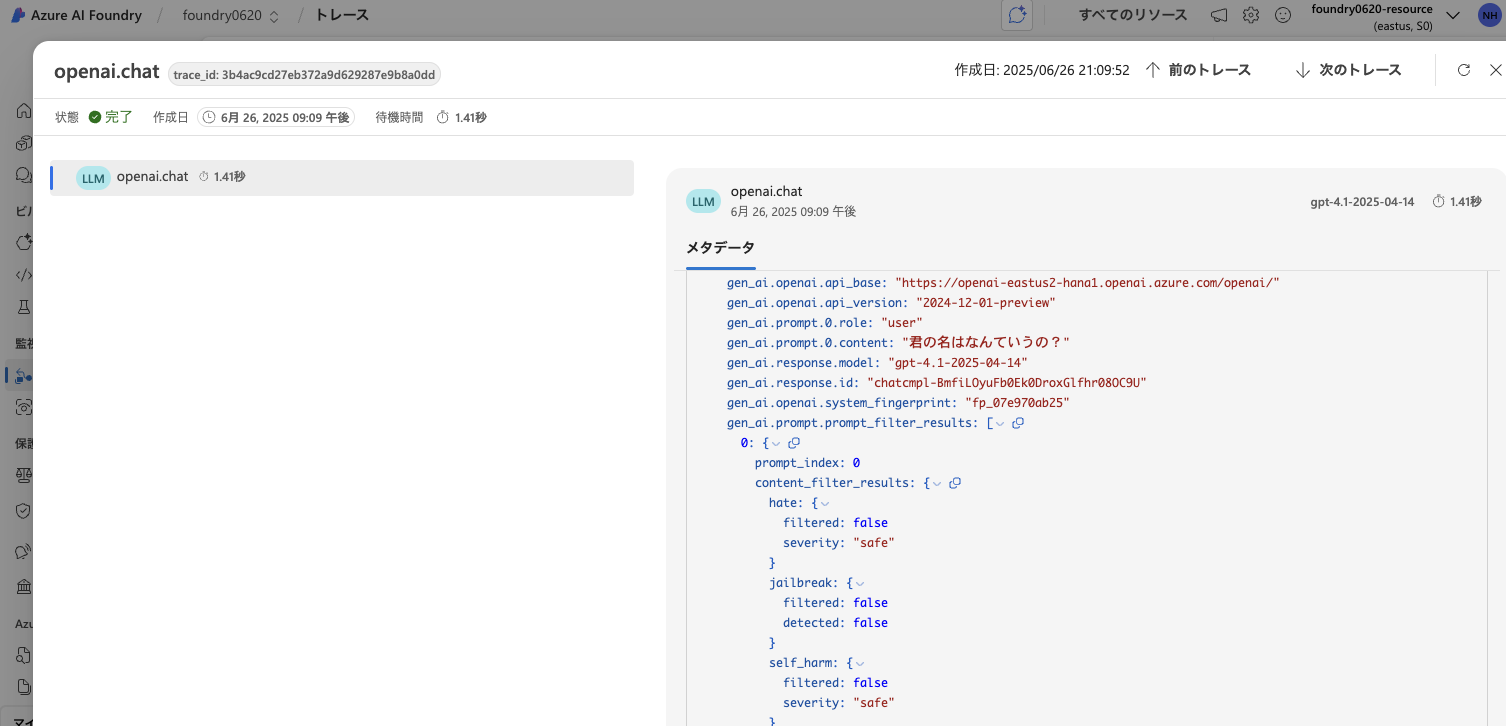
トレースの確認
実行から1〜2分程度で Azure AI Foundry に反映されます。
2. AutoGen のトレース
AutoGen には、アプリケーションの実行に関する包括的な記録を収集するためのトレースと観測のサポートが組み込まれています。この機能は、デバッグ、パフォーマンス分析、そしてアプリケーションのフローを理解するのに役立ちます。
この機能は OpenTelemetry ライブラリを活用しているため、OpenTelemetry と互換性のある任意のバックエンドを使用してトレースを収集および分析できます。
すでに紹介した「Azure Application Insights リソースへの接続」までを実行後、通常通り以下のコードを実行するだけです。
from autogen_ext.models.openai import OpenAIChatCompletionClient, AzureOpenAIChatCompletionClient
from autogen_agentchat.ui import Console
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.conditions import TextMessageTermination
model_client = AzureOpenAIChatCompletionClient(
azure_deployment="gpt-4.1-mini",
model="gpt-4.1-mini",
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-12-01-preview",
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
)
# Create the final reviewer agent
writer_agent = AssistantAgent(
"writer_agent",
model_client=model_client,
system_message="あなたはプロの小説家です。魅力的な文章を完結なタッチで書くことができます。",
)
stream = writer_agent.run_stream(task="SEが異世界に転生して無双する異世界転生系短編小説を書いてください。")
await Console(stream)
トレースの確認

独自のスパンを作成
複雑なアプリケーションを開発するときに、ビジネス ロジックとモデルを組み合わせたコードのセクションをキャプチャすると便利な場合があります。 OpenTelemetry では、スパンの概念を使用して、関心のあるセクションをキャプチャします。 独自のスパンの生成を開始するには、現在の トレーサー オブジェクトのインスタンスを取得します。
from opentelemetry import trace
tracer = trace.get_tracer(__name__)
from typing import List
@tracer.start_as_current_span("write_and_critic_short_story")
async def write_and_critic_short_story():
current_span = trace.get_current_span()
# Set attributes for the current span
current_span.set_attribute("operation.critic_count", 3)
# Create the final reviewer agent
writer_agent = AssistantAgent(
"writer_agent",
model_client=model_client,
system_message="あなたはプロの小説家です。魅力的な文章を完結なタッチで書くことができます。",
)
# Create the final reviewer agent
critic_agent1 = AssistantAgent(
"critic_agent1",
model_client=model_client,
system_message="作成された文章を批判的な観点から評価し、改善点を提案すること。",
)
# Create the final reviewer agent
critic_agent2 = AssistantAgent(
"critic_agent2",
model_client=model_client,
system_message="あなたはリスクアドバイザーです。作成された文章のアイデア被りやSMS等で炎上しないかどうかを評価し、改善点を提案すること。",
)
# Create the final reviewer agent
critic_agent3 = AssistantAgent(
"critic_agent3",
model_client=model_client,
system_message="あなたは法学のスペシャリストです。作成された文章を法的観点から評価し、改善点を提案すること。",
)
# add agents to array
critic_agents: List[AssistantAgent] = [
writer_agent,
critic_agent1,
critic_agent2,
critic_agent3,
]
termination_condition = TextMessageTermination("critic_agent3") #3人目が発言したら終了
critic_team = RoundRobinGroupChat(critic_agents, termination_condition=termination_condition)
stream = critic_team.run_stream(task="SEが異世界に転生して無双する異世界転生系短編小説を書いてください。")
await Console(stream)
return
await write_and_critic_short_story()
さらに current_span.set_attribute("operation.critic_count", 3) によって独自のメトリクスをトレースに追加することもできます。

トレースの確認
@tracer.start_as_current_span("write_and_critic_short_story") スパンをセットしているため write_and_critic_short_story 内に処理が階層化されていることが分かります。
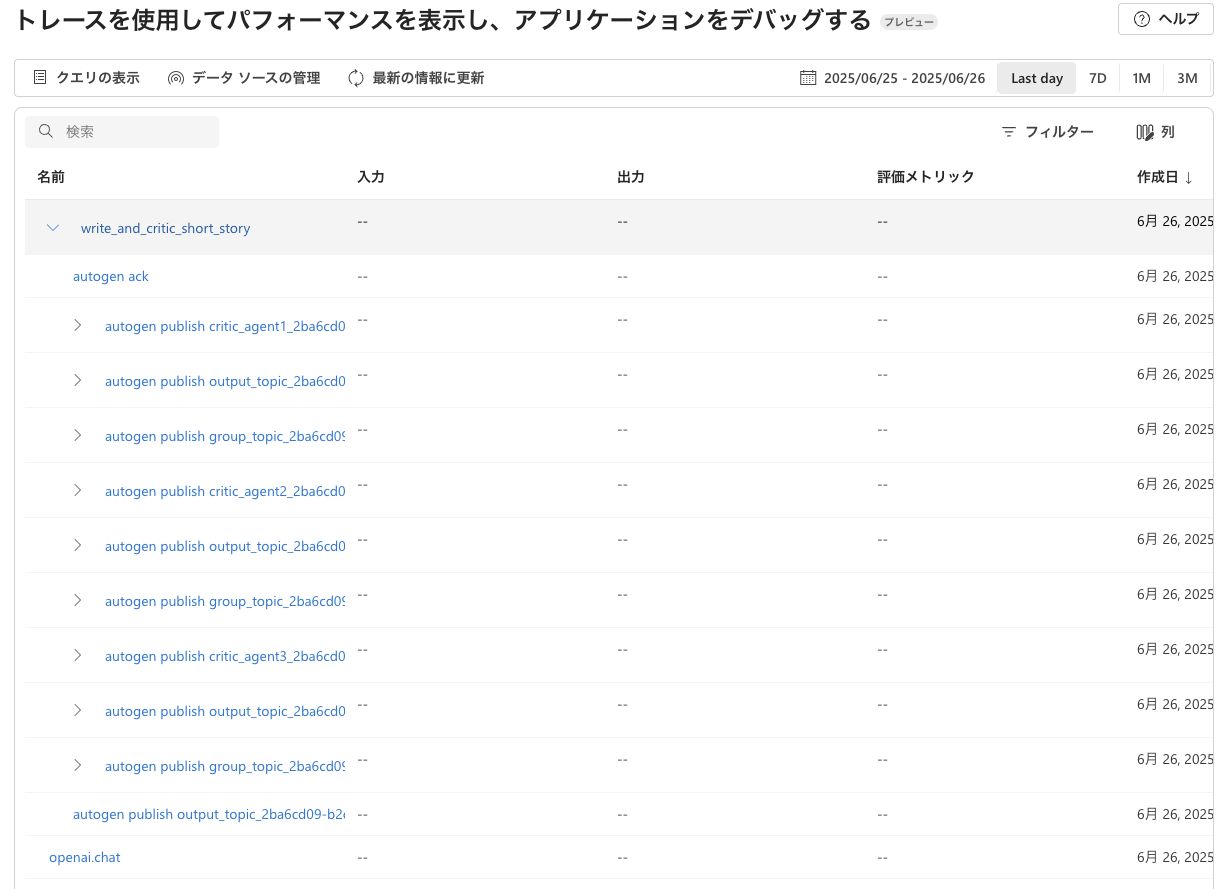
AutoGen のランタイムは既に以下のランタイムメッセージングイベント(メタデータ)をログに記録するようにインストルメント化されています。
-
create: メッセージが作成されたとき -
send: メッセージが送信されたとき -
publish: メッセージが公開されたとき -
receive: メッセージが受信されたとき -
intercept: メッセージがインターセプトされたとき -
process: メッセージが処理されたとき -
ack: メッセージがACKされたとき
AutoGen 内部の処理を詳細にデバッグするにはこれらの情報で十分かと思います。OpenAI のコールは LLM アイコンで表示されます。
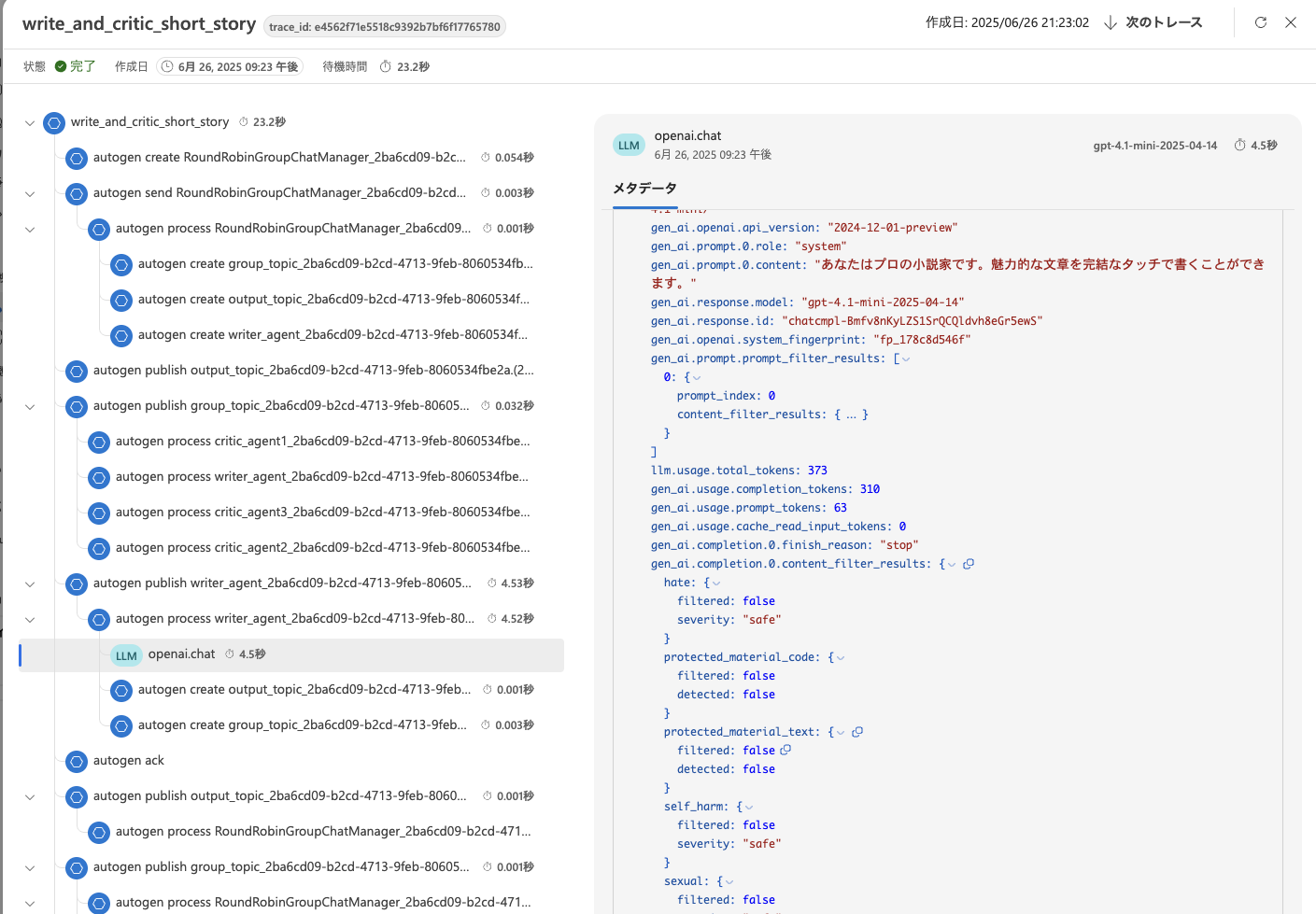
Azure AI Foundry のトレース機能を使うことによって、実験結果が自動的にクラウド上に保存されるようになるので、後からあの時のプロンプトなんだったっけ?となったときに便利です。以下のように OpenAI のコールだけをフィルタリングすることも可能です。
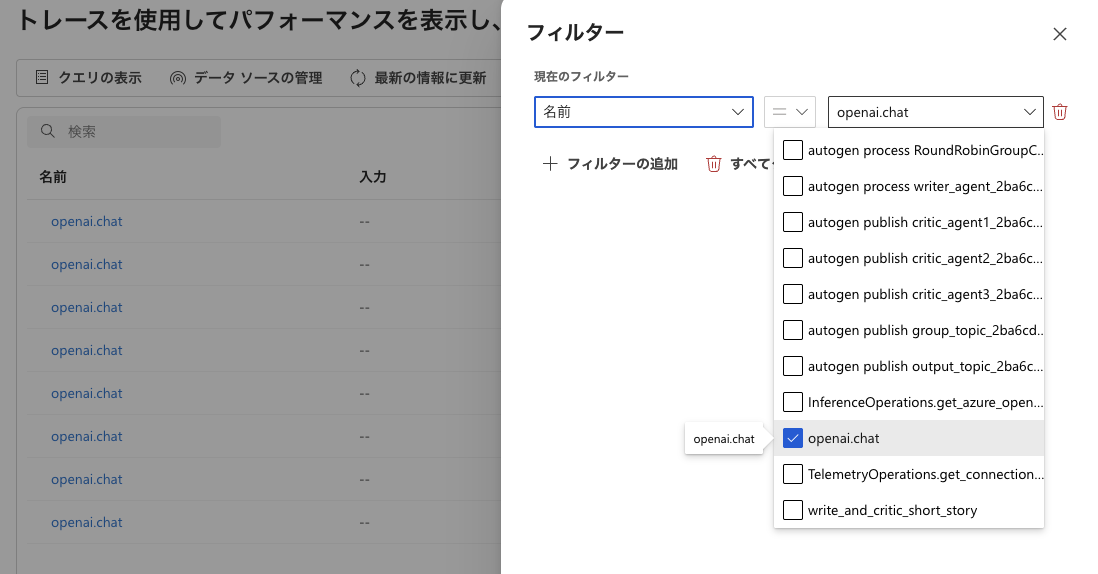
あとは Timeline UI があれば尚良しなんですがね。。。
GitHub