Azure AI Search の誕生

Microsoft Ignite 2023 にて、Azure Cognitive Search のベクトル検索が GA となり、ブランド名が「Azure AI Search」となることが発表されました。Azure AI Search は AI を活用した情報検索プラットフォームとして位置づけられます。
Azure Cognitive Search はフルマネージドな全文検索エンジンとして長年にわたって世界で多くの企業のナレッジベースとして用いられてきました。2021 年、Microsoft 製の LLM である Turing モデルをベースにしたセマンティック検索機能を搭載し、既存の全文検索アルゴリズムにセマンティックリランカーを追加して検索精度の向上に寄与してきました。そして 2023 年、Azure OpenAI Service の発表と Embeddings モデルが利用可能になったことで、ベクトルデータベースとしての役割が新たに加わりました。これによって検索拡張生成(RAG)アーキテクチャを Azure OpenAI Service と同一のネットワーク内で実現できるようになり、利用が爆発的に拡大しました。
同時に発表された Azure AI Studio との連携もネイティブに対応し、どなたでもマルチモーダルな RAG アーキテクチャを簡単に実装できるようになりました。

アップデート
- ベクトル検索 GA
- セマンティックランキング GA(旧セマンティック検索)
- Integrated vectorization (preview)
- Import and vectorize data wizard (preview)
- インデックスプロジェクション (preview)
- 2023-11-01 Search REST API
- 2023-11-01 Management REST API
- Azure OpenAI Embedding skill (preview)
- Text Split skill (preview)
※2023 年 11 月 15 日以降、Azure Cognitive Search は Azure AI Search という新しい名前になりました。既存のすべてのデプロイ、構成、統合は、引き続き現在と同様に機能します。価格の変更はなく、API や SDK に重大な変更はありません。
Azure AI Search × Azure OpenAI Service
ベクトル検索
すでに多くの方がパブリックプレビューに参加されていたかと思いますが、最新のベクトル検索機能では、ANN である HNSW アルゴリズムと網羅的 KNN に対応しており、データ量や精度、速度、コストなどのニーズに応じて変更できます。
Integrated vectorization (preview)
Integrated vectorization により、インデクサーのインデックス作成のスキルにデータのチャンク化とテキストから Embeddings への変換が追加されます。また、クエリにテキストから Embeddings への変換も追加されます。
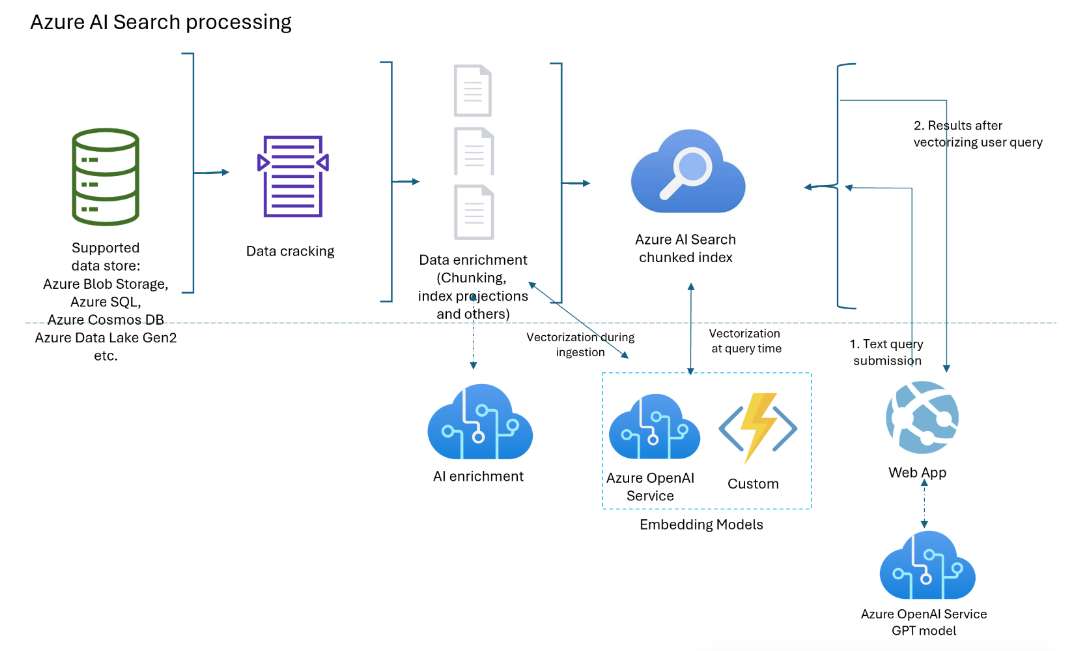
クエリにテキストから Embeddings への変換が追加
ベクトル フィールドに vectorizers 設定が関連付けられている場合、 クエリが自動的にベクトル化され、一致する結果が表示されます。
"search": "源実朝の趣味って何?",
"vectorQueries": [
{
"kind": "text",
"text": "源実朝の趣味って何?",
"k": 5,
"fields": "vector"
}
Import and vectorize data wizard (preview)
Azure portal のデータのインポートとベクトル化ウィザードを使用して、Integrated vectorization を実行できます。
インデックスプロジェクション (preview)
Azure OpenAI Serivce の Embeddings API の登場によってドキュメント本文のチャンク化が必要になり、これによって検索インデックスの構造が 1 対多の関係になりました。これまでは既存のプロジェクション機能を使って Table Storage にプロジェクションしていましたが、これからは直接親から子のインデックスにプロジェクションできます。このインデックスプロジェクション機能の優れている点は、親の変更を子と同期できる点です。
"indexProjections": {
"selectors": [
{
"targetIndexName": "myTargetIndex",
"parentKeyFieldName": "ParentKey",
"sourceContext": "/document/pages/*",
"mappings": [
{
"name": "chunk",
"source": "/document/pages/*"
}
]
}
]
}
インデクサーのデータソースで変更の追跡と削除の検出がサポートされている場合、親ドキュメントが変更された場合、その特定のプロジェクションのターゲット インデックス内のデータは、インデクサーとスキルセットを実行する度にその変更を反映するように更新されます。
なぜ Azure AI Search なのか
ノーコードでデータ取り込みを自動化
それは企業に貯まった構造化・非構造化データの保存先(ナレッジベース)として最も最適化されているからです。クラウド上の Blob Storage などにファイルを保管しておけば、Azure AI Search のインデクサー(クローラー)によって自動的にインデックス化が行われます。取り込み対象のファイルもビジネスでよく使われるファイルは基本的に対応していますし、データベースとのコネクターも備えています。また、ベクトル検索を行うためのチャンク化や Embeddings API の呼び出しについても自動化する Integrated vectorization (preview) が開始されました。
検索精度の向上
RAG アーキテクチャにおいては検索エンジンの精度が最終的な応答品質に影響を与えます。したがっていかに高い精度でほしいドキュメントを上位に持ってくるかが最も重要です。Azure AI Search では検索精度のチューニングについても多くの選択肢が用意されています。現在以下の検索モードが利用可能であり、RAG システムにおいては 1 から 4 へ行くにしたがって精度が向上していくことが Microsoft の定量分析結果で示されています。
- キーワード検索(既存の全文検索)
- ベクトル検索
- ハイブリッド検索
- セマンティックハイブリッド検索(Microsoft 独自機能)
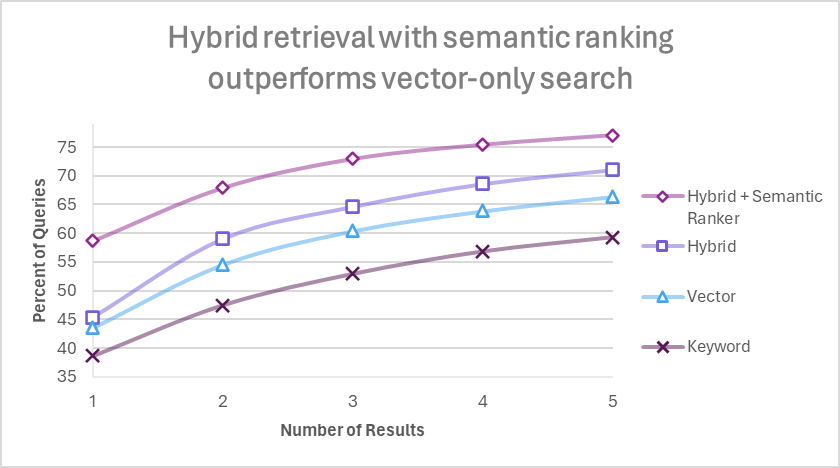
最も精度の高いセマンティックハイブリッド検索は、Microsoft が 2 年前から導入し改善し続けているセマンティックリランカーが寄与しています。
Azure AI Search の事例ではありませんが、先日 OpenAI 社が開催した OpenAI DevDay の A Survey of Techniques for Maximizing LLM Performance でも Colin 氏が RAG アーキテクチャの精度向上ストーリーを解説していますが、こちらでもリランクが精度向上策の 1 つとして有効であることが示されています。
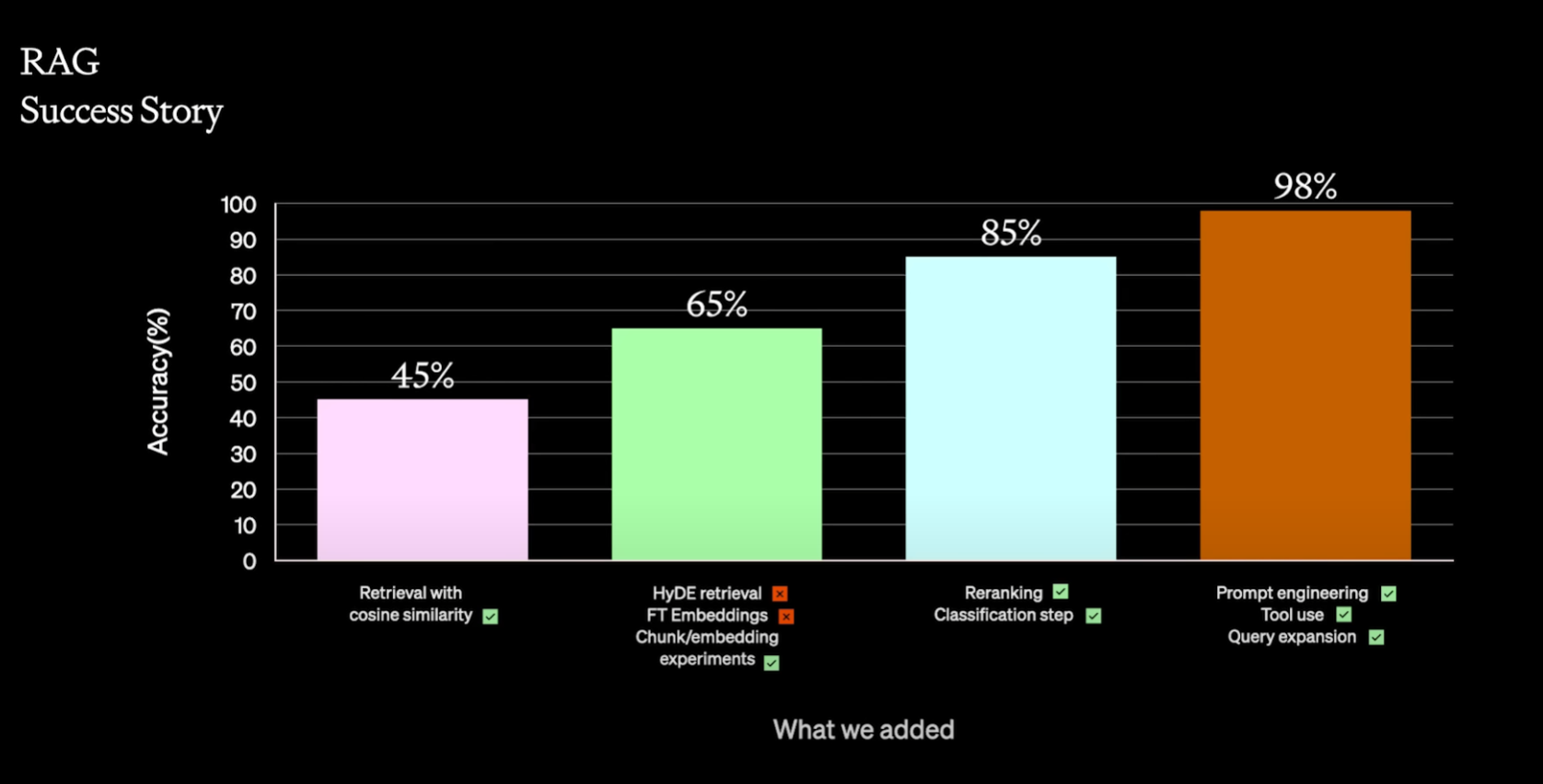
セッションではクロスエンコーダーを用いたリランクが紹介されていましたが、Azure AI Search を使えば機能をオンにするだけで使うことができます。(追加料金は必要ですが)
マルチモーダルナレッジベース
Azure AI Search は単に text-embedding-ada-002 を使ってテキストをベクトル化したものを保存するだけにとどまりません。GPT-4V の登場によって今後世界はマルチモーダル対応した LLM アプリケーションへシフトしていくでしょう。そうなると企業には様々な画像・音声・動画などのデータが増加していくはずです。そうなったときでもこれらのファイルをベクトル化して Azure AI Search に保存することができます。
すでに Azure AI services の Azure AI Vision Image Analysis サービスを使って画像ベクトル検索システムを構築するサンプルを公開しています。

私が予想していた通り、Azure OpenAI の on your data に画像類似検索機能を入れてきましたね。
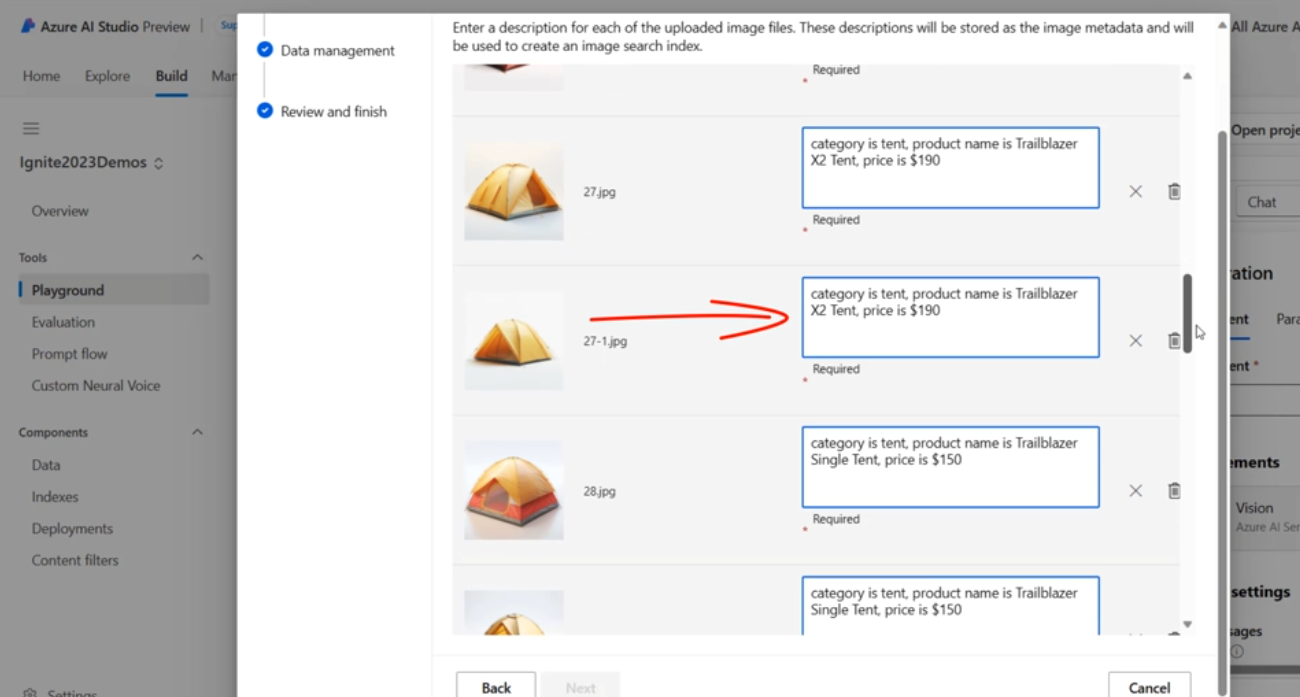
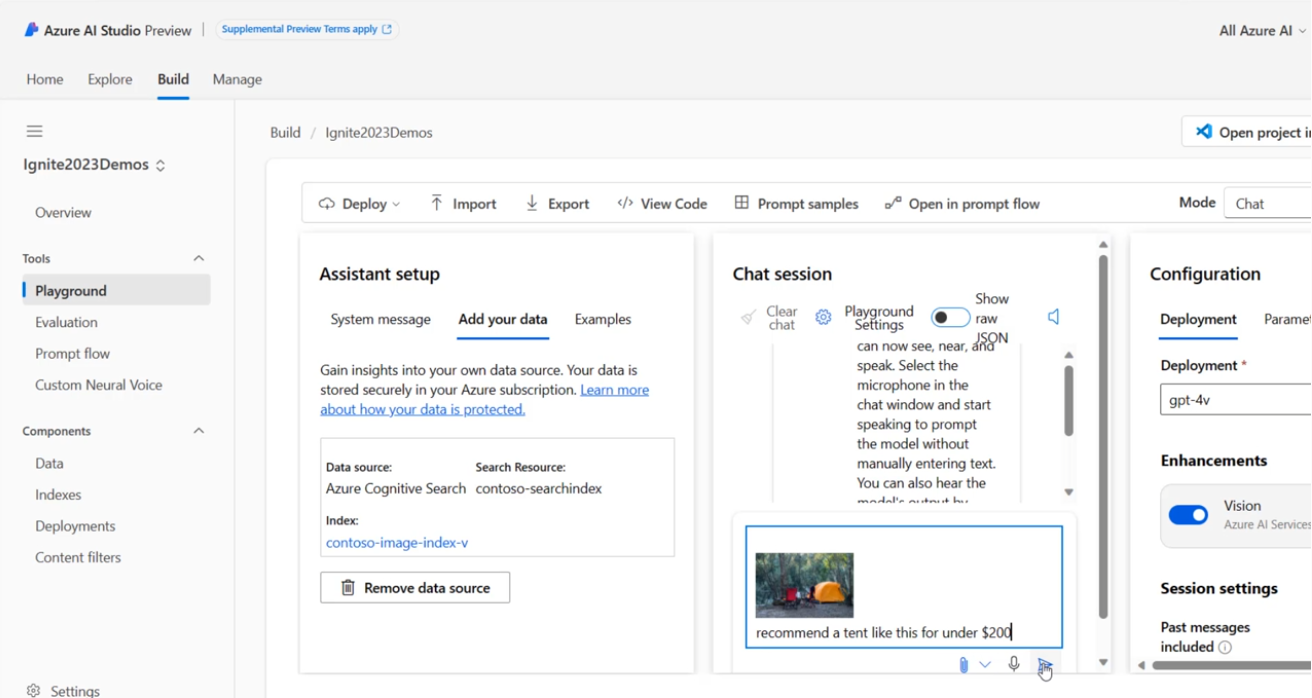
GPT-4 Turbo with Vision、Azure AI Search、および Azure AI Vision の組み合わせ技です。
Azure AI Search エコシステム
Azure AI Search は世界中の LLM 開発者が使う LangChain や Semantic Kernel、Llamaindex の Retriever として利用することができます。また、今回発表のあった Azure AI Studio とも連携しているので簡単に接続することができます。Azure から広がるエコシステムの詳しい解説はこちら。
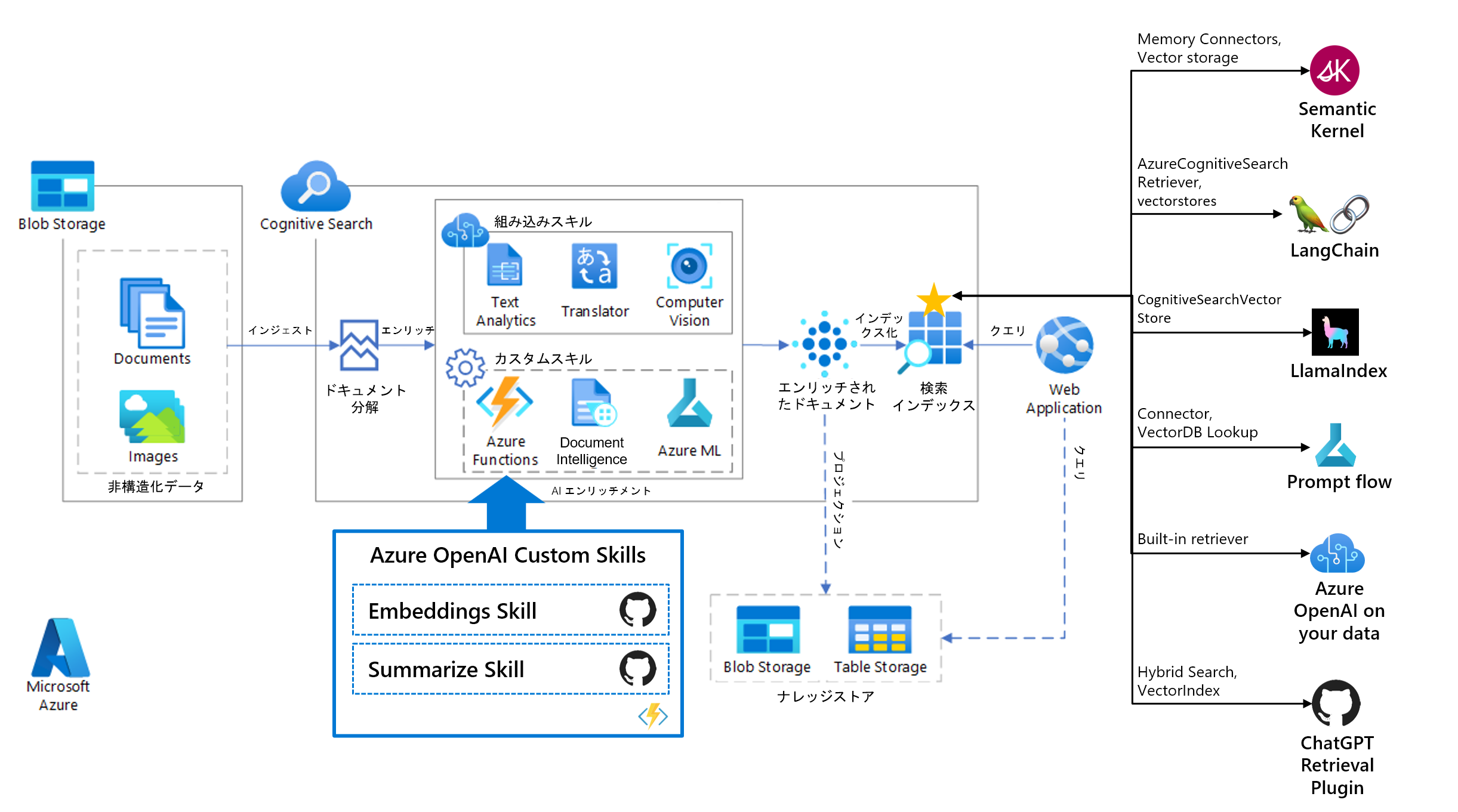
私は言いたい、これはもはや Azure AI Search Universe や!