こちらはSORACOM Advent Calendar 2020の15日目の記事です。
TL;DR
- SORACOM APIを叩いてコスト詳細をGrafanaで見えるようにした
- ユーザコンソールの「ご利用料金詳細」の「CSV形式でダウンロード」からexcelでピボットテーブルを都度作るの飽きたので
- 料金明細csvをGrafanaでみえるようにしただけではある
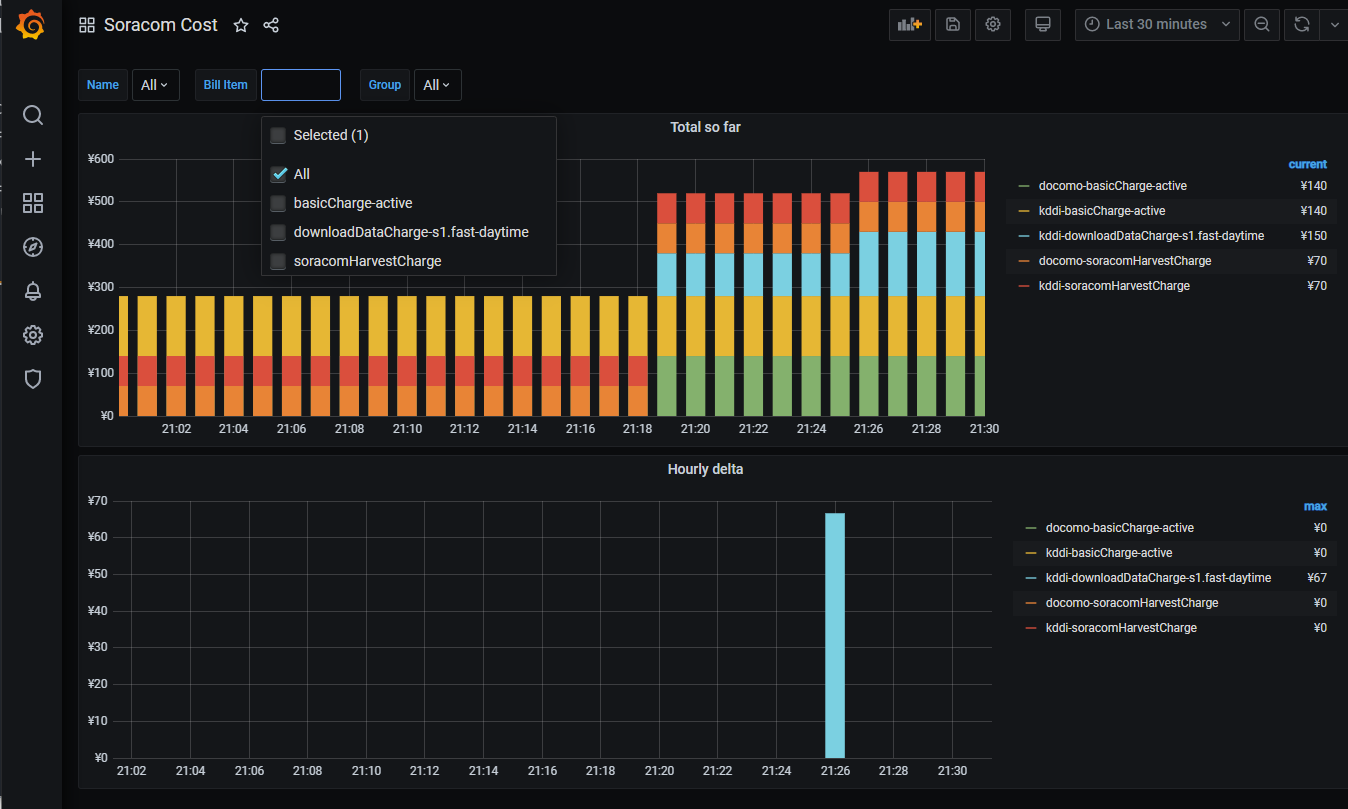
(これだと上のグラフで全体のコスト感の時間変化、下で単位時間あたりにkddiなるsimのs1.fast dlが急に増えたのがわかる!みたいな。データ量少ないけど...)
やりたいこと
- simごとbill item(s1.fastとかbeamとか基本使用料とか)の内訳を見たい
- ダッシュボードで時系列としてぱぱっと見たい
実装
(またこの人SORACOM API叩いてnode_exporterのtext collectorに食わせてるな...とか去年を思い出してはいけない)
システム構成

ファイル構成例えば
./
prometheus/
(prometheus本体とかconfとか)
node_exporter/
node_exporter(bin本体)
text_collector/
soracom_cost.prom
soracom_cost_exporter/
main.py(作ったbatch)
- batch
- crondとかでhourlyで起動
- SORACOM APIのPOST /bills/latest/exportを叩く
- csvを集計してprometheus metricsをtextで出力
- ユーザコンソール上でsimごとtagを指定してるとさらにcsvには追加されたりするのでよしなに調整を
- それをnode exporterのtext collectorで読み取ってあとはprometheusやgrafanaへ
- prometheus側はnode exporterをscrapeする設定いれてるだけ
- node_exporterは起動オプションでtext collectorを有効に
batchのコード
soracom_cost_exporter/main.py
import io
import json
import pandas as pd
import requests
from prometheus_client import CollectorRegistry, Gauge, write_to_textfile
# get cost csv
auth_response = requests.post( # get soracom access token
url="https://api.soracom.io/v1/auth",
headers={"Content-Type": "application/json"},
data=json.dumps(
{
"authKeyId": "keyId-(自分の)",
"authKey": "secret-(自分の)"
}
)
)
export_response = requests.post( # get latest bill report url
url="https://api.soracom.io/v1/bills/latest/export?export_mode=sync",
headers={
"X-Soracom-API-Key": auth_response.json().get("apiKey"),
"X-Soracom-Token": auth_response.json().get("token"),
"Accept": "application/json",
}
)
cost_csv_url = export_response.json().get("url") # download cost csv
cost_csv_response = requests.get(cost_csv_url)
# tally a cost csv
df = pd.read_csv(io.BytesIO(cost_csv_response.content))
df = pd.pivot_table(
df,
values="amount",
index=["name", "billItemName", "group:name"],
columns=[],
aggfunc="sum"
)
# write metrics file
registry = CollectorRegistry()
soracom_cost_gauge = Gauge(
"soracom_cost_jpy",
"soracom cost jpy",
["name", "bill_item", "group_name"],
registry=registry
)
for d in df.itertuples(name=None):
name, bill_item_name, group_name = d[0]
amount = d[1]
soracom_cost_gauge.labels(name, bill_item_name, group_name).set(amount)
write_to_textfile("../node_exporter/text_collector/soracom_cost.prom", registry)
metricsの設計
- name/bill_item/group_nameごとに料金明細csvのamountを割当
- monthlyのcostがずっと増えていって月初でresetされる感じ
- 出力されるファイルの中身はこんな
$ cat node_exporter/text_collector/soracom_cost.prom
# HELP soracom_cost_jpy soracom cost jpy
# TYPE soracom_cost_jpy gauge
soracom_cost_jpy{bill_item="basicCharge-active",group_name="default",name="docomo"} 140.0
soracom_cost_jpy{bill_item="soracomHarvestCharge",group_name="default",name="docomo"} 70.0
soracom_cost_jpy{bill_item="basicCharge-active",group_name="default",name="kddi"} 140.0
soracom_cost_jpy{bill_item="soracomHarvestCharge",group_name="default",name="kddi"} 70.0
soracom_cost_jpy{bill_item="downloadDataCharge-s1.fast-daytime",group_name="default",name="kddi"} 150.0
grafanaの設定
ダッシュボードの中身
-
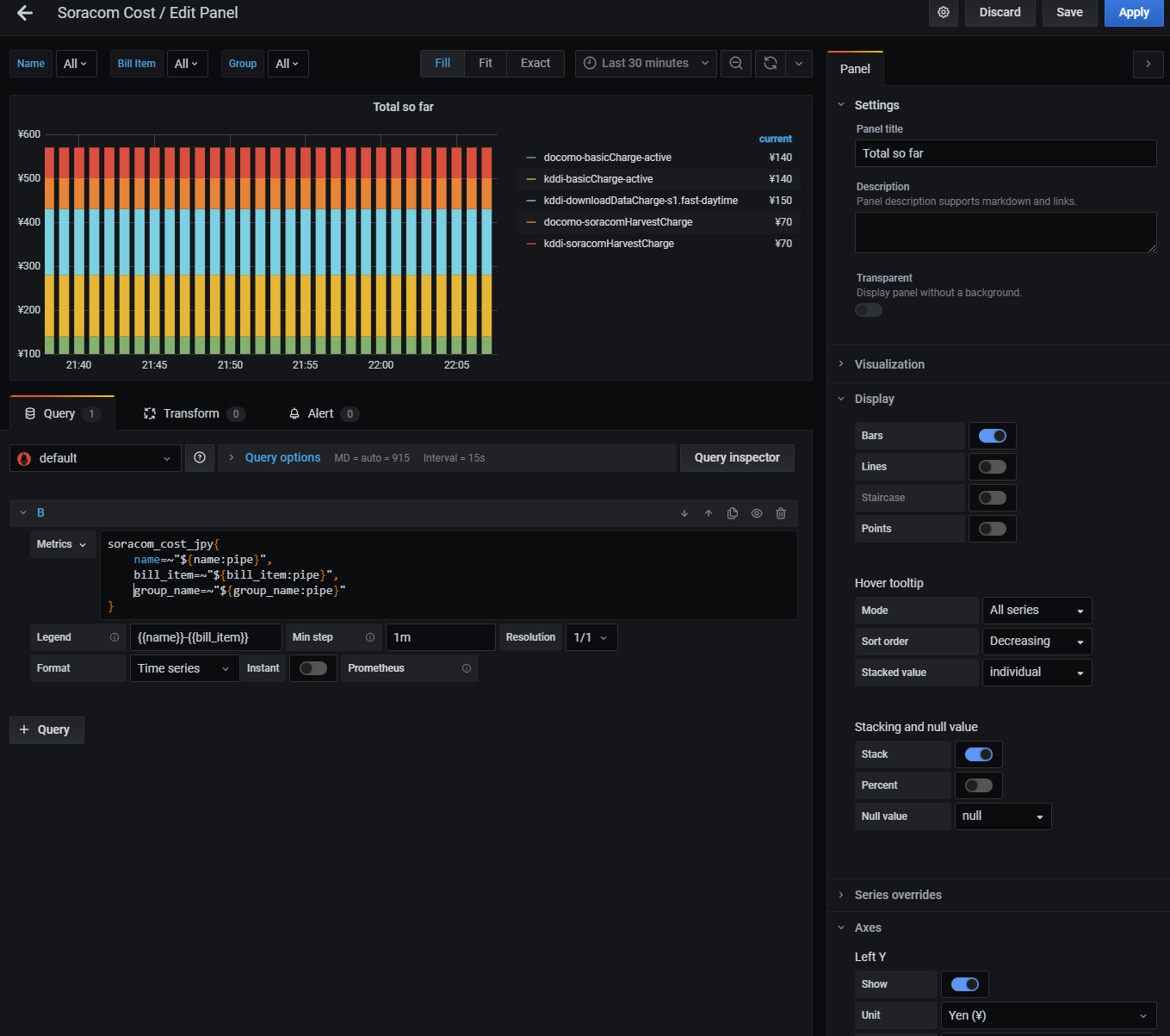
"Total so far"ではmetricsをそのままだし、
-
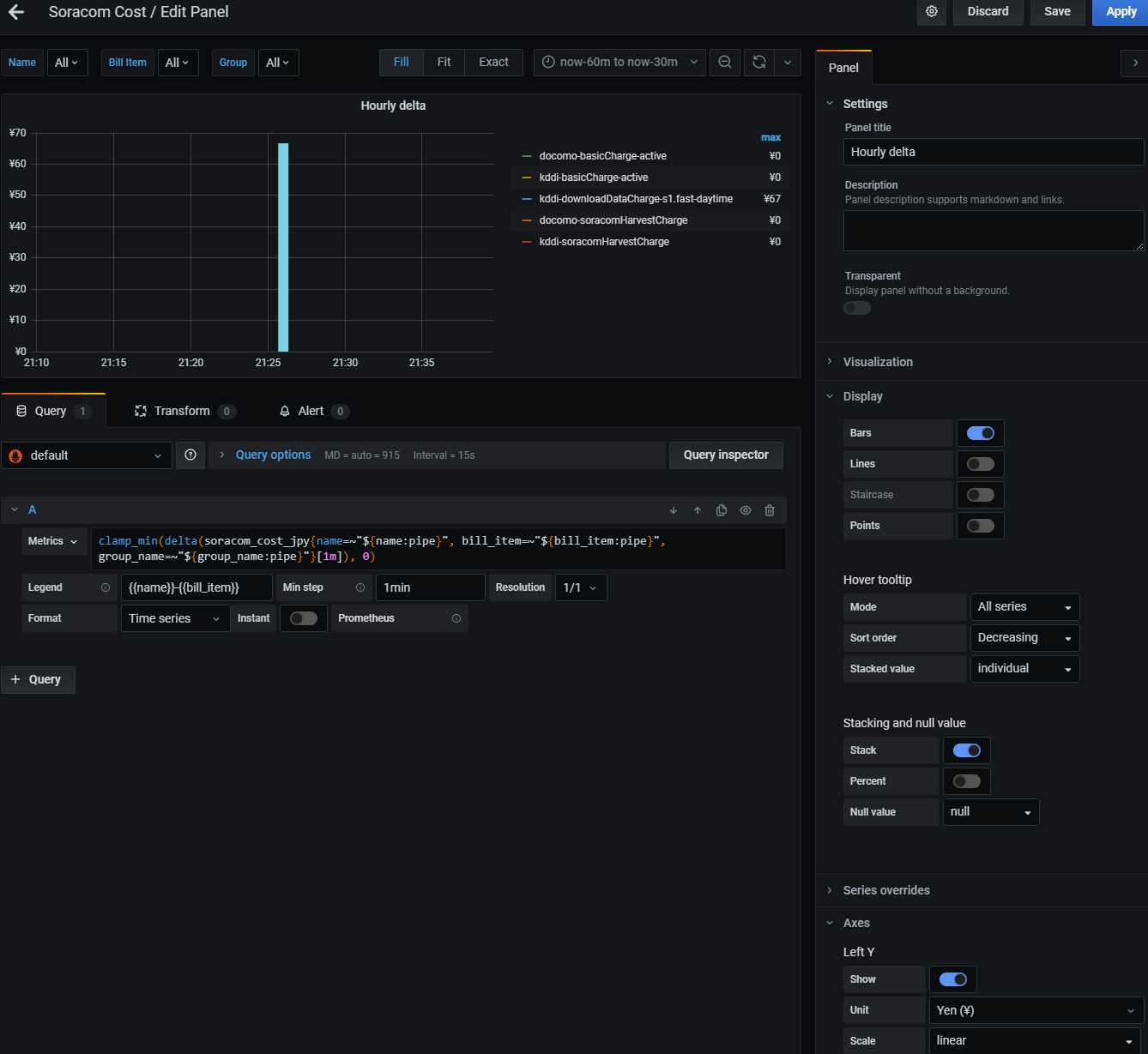
"Hourly delta"ではprometheusのquery的にdeltaをとっています
-
ダッシュボードのvariableを設定しているので全体を"All"で眺めて、どれか多いのあったらfilterする感じの使い方を想定
- dashboard variableをlabels_valuesで定義して自動でとってきて、グラフ側name=~"${name:pipe}"みたいに展開して個別でもALLでも見れるようにしてるのがおしゃれポイントです

取得できたmetricsについての言い訳
- docomoとかkddiとかがsimのtag:Nameです(分かりづらいですが...)
- データの更新頻度などは嘘っぱちです
- 表にだせるそれっぽい利用料金のデータがなかったので個人のを加工してます
- データが蓄積されてなくて(直前で記事書いてるからゲフンゲフン...)
やってみて
- 結構がっつりSORACOMさんを使っているのでcostを真面目にみないとなと
- んでAWS web consoleでいうとこのcost expolorerが欲しかった
- が、SORACOMユーザコンソールだと通信量などのダッシュボードはあれどコストの画面はシンプル...
- SORACOM Harvest Dataに料金データを突っ込んでLagoonでみるか?とも思ったが、流石に用途違いな感じで...
- やっぱGrafanaでぐりぐりいじれるとexcelのピボットテーブルとにらめっこには戻れないw 気軽に見えるようにするのが肝要
- きっとこんなの自作しなくとも、おいおいソラコムさんがかっこいいダッシュボードを実装してくれるはず!(チラッ
おわり