目次
- はじめに
- 個人を特定する情報が個人情報じゃない
- デジタル署名は暗号化しない
- TLS(SSL) は共通鍵を公開鍵で暗号化しない
- TLS(SSL) が使われていれば安全じゃない
- 変数は箱じゃない
- Python 等は「ソースコードを 1 行ずつ実行するインタプリタ方式」じゃない
- 日本語 1 文字は 2 バイトじゃない
- 動画が動いて見えるのは残像によるものじゃない
- 標本化定理は「2 倍以上の周波数」じゃない
- その他いろいろ
はじめに
2022 年から高等学校で、プログラミング等を学ぶ「情報Ⅰ」が 必修 必履修科目になりました。1 さらには 2025 年入試から大学入試共通テストでも出題されるようになり、教科「情報」の重要性が高まっています。
これで 2030年に79万人不足すると言われる IT 人材 の問題が解決!…と言いたいところですが、先日も『課題感ある教科1位「情報」』という調査結果が公表されたように、残念ながら多くの問題を抱えているのが現状です。
例えば、指導する情報教員の不足問題。16% が正規免許なし という報道がありますが、残る 84% の教員も数学などの他教科が専門という教員が大多数2で、残念ながら情報を専門的に学んだ情報教員は少数です。
そして、本来正しいはずの教科書ですら間違っているという問題。これに関しては教員不足問題と異なり報道されているのを見かけないので、こうして記事として公開させていただくことにしました。
対象教科書
本記事で対象としたのは、以下の 6 教科書(令和 3 年時点での教科書見本)です。3
- 東京書籍「情報Ⅰ Step Forward!」(以下「東書」)
- 実教出版「高校 情報Ⅰ Python」(以下「実教」)
- 開隆堂「実践 情報Ⅰ」(以下「開隆堂」)
- 数研出版「高等学校 情報Ⅰ」(以下「数研」)
- 日本文教出版「情報Ⅰ」(以下「日文」)
- 第一学習社「高等学校 情報Ⅰ」(以下「第一」)
想定問答
Q. 「こんなところに書いてないで直接出版社に言ったら?」
A. もう言いました。
そして「検討します」的な回答の後 返事のない一社を除き、誤りを認める回答を頂いています。(つまり本記事の内容は私が一方的に間違っていると主張しているものではありません。)
ですが、一度文科省の検定を通ってしまった教科書は大きく変更することができません。ちょっとした変更であれば申請することで可能らしい(実際本記事に書いたことの一部は、現高校一年生の手元に渡っている版では修正されているようです。もしそうした箇所があればコメント等いただければ幸いです。)ですが、「変更が大規模になってしまい修正申請では対応できないので、次回の改定の際に修正したい」との回答が多数ありました。
すると、少なくとも数年間は誤った内容の教科書が出回ってしまうことになります。この記事が一人でも多くの高校生や高校情報教員の目に触れ、正しい情報が伝わってくれればと思います。
個人を特定する情報が個人情報じゃない
「個人情報」についての各社教科書の記述は、以下のようになっています。
単独または組み合わせによって個人を識別できる情報(東書P14)
いくつか組み合わせると個人を特定できるもの(実教P12)
名前や住所、電話番号など、個人が特定できる個人情報(開隆堂P33)
他の情報と組みあわせることで個人を特定・識別できる情報(数研P22)
個人を識別できる情報(日文P31)
日本において「個人情報」と言った際には、いわゆる 個人情報保護法 における「個人情報」を指すと考えてよいでしょう。では、個人情報保護法では「個人情報」をどう定義しているか。
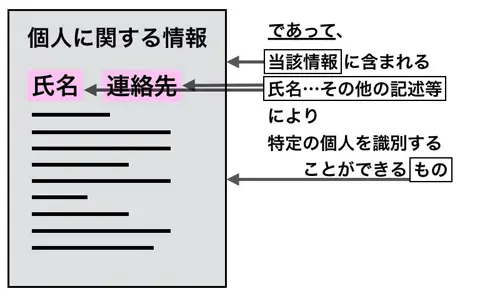
「個人情報」とは、(中略)当該情報に含まれる氏名、生年月日その他の記述等(中略)により特定の個人を識別することができるもの(個人情報の保護に関する法律 第二条、中略と強調は引用者による)
個人情報保護法にある「当該情報に含まれる」に類する記述が上記のどの教科書にも入っていませんが、この点こそが「個人情報」を正しく理解する上で重要であり、そこを落としてしまうと読んだ人がほぼ確実に誤解するような記述になってしまいます。
教科書の記述では、まず「氏名」や「住所」といったバラバラな「情報」があり、そうした「情報」の中で個人を特定・識別できる性質を持つものだけが「個人情報」だという誤解を与えます。さらに一部の教科書では、「個人情報の例」なるものを挙げて誤解に拍車をかけています。
(実教P12)
例えば「性別」は多くのこうした「個人情報の例」に含まれていますが、だとすると「ある男性」という記述だけで個人情報になると言うのでしょうか?
個人情報保護法では、まず氏名や住所、好きな食べ物、読んだ本といったさまざまな記述を含んだひとかたまりとしての「情報」があり、その中に個人を特定・識別できる記述が含まれていれば、そのひとかたまりの「情報」まるごとが「個人情報」になると言っているのです。「性別」のような個別の記述が個人情報になるか否かを判断するのは無意味です。
これに関しては高木先生の以下の図がとにかく分かりやすいでしょう。
ちなみに、第一学習社は
生存する個人に関する情報で、その情報に含まれる氏名などの記述などにより、ある個人を特定することができるもの(第一P33)
と、個人情報保護法の記述を適切に要約しています。(さらに上の高木先生の図と同様のものも載っています。)やはり奥村先生が関わっているだけのことはあります。
個人情報とプライバシーを並べて語るのはどうなのか。
ところで、日文を除く 5 冊は、「個人情報」と同じ見開きページで「プライバシー」について扱っています。4
ですが、本当に「個人情報」と「プライバシー」は並べて扱うべきトピックなのでしょうか?そうした点に疑問を呈する記事がありました。
長文ですが一読の価値はあります。
デジタル署名は暗号化しない
デジタル署名に関する各社教科書の記述です。
秘密鍵を用いて暗号化された署名データを、受け取った人が公開鍵を用いて復号し…(東書P111)
要約文を送信者の秘密鍵で暗号化したもの(実教P93)
署名に含まれる暗号を公開鍵で復号する(開隆堂P172)
秘密鍵で暗号化し、(中略)公開鍵で復号する(数研P139)
送信者の秘密鍵によって(中略)暗号化したもの(日文P180)
秘密鍵によりファイルを暗号化し…(第一P140)
はい、全滅ですね。こうした記述には以下の 2 つの問題があると思います。
「暗号化」という言葉の問題
そもそも「暗号化」とは何でしょう?教科書によっては完全に上記のデジタル署名の記述と矛盾する説明がされています。5
特定の人にしかわからない形にした情報を暗号といい、暗号にすることを暗号化、暗号化された文を暗号文という。(数研P137)
この「暗号化」の説明には多くの人が納得するところだと思います。重要なのは、単に「わからない形にする」だけではなく、「特定の人にしかわからない形にする」という点です。
例えば「圧縮」という行為は「暗号化」に含まれるでしょうか?テキストエディタで開いて読めるような「わかる形」のデータを圧縮すると、テキストエディタで開いても意味不明な「わからない形」のバイナリデータへと変換されますが、だからといって「圧縮」を「暗号化」の一種だと考える人はあまり居ないでしょう。つまり、「暗号化」とは以下の 2 つの特徴を兼ね備える必要があるわけです。
- 見ても何が何だかわからない形に変換する。
- これだけだと、「圧縮」や「ハッシュ化」も含まれる。
- 変換されたデータは、特定の人(例えば、「秘密鍵」と呼ばれるデータを持つ人)だけが元の「わかる形」に戻せる。(復号できる。)
それを踏まえて同じ教科書のデジタル署名についての説明を見ると、
B が A に文書を送るとき、B だけがもつ秘密鍵で暗号化し、受け取った A が、B の公開鍵で復号すると、意味のある文書が出てくる。(数研P139)
と、「暗号化」されたものを不特定の人が持つ「公開鍵」で復号できると書いているわけで、自分自身で書いた「暗号化」の説明と矛盾しています。
デジタル署名の話をする際は、「暗号化」「復号」ではなく、「署名」「検証」といった言葉を使ったほうが良いでしょう。
実際のデジタル署名の仕組みと異なる、という問題
「いやいや上記の問題は単なる言葉尻の問題であって、実際にはデジタル署名における署名処理では公開鍵暗号における『暗号化』と同じ処理が行われているだろう」と思われた方もいるでしょう。
しかし、実際のデジタル署名でも「公開鍵暗号における暗号化」が行われているとは言えません。この点はさらに 2 つに分けられます。
RSA 署名でしかしてないよ問題
確かに RSA 署名では、公開鍵暗号である RSA 暗号が用いられます。しかしデジタル署名は RSA 署名しか無いわけではありません。DSA, ECDSA, EdDSA といったデジタル署名の場合は、「公開鍵暗号で暗号化」と呼べるような処理はおこなっていません。(下記記事を参照。)多くの教科書の記述は、複数ある方式のうち ごく一部にしか当てはまらない話を一般論であるかのように書いているため、誤りと言えます。
RSA 署名でも実際してないよ問題
さらに、理論的説明としての「RSA 署名」では確かに RSA 暗号における暗号化と同じ処理が行われますが、実際の RSA 署名では暗号化と同じ処理は行われません。
まず、RSA 署名・RSA 暗号においては、秘密鍵を使った処理には中華風剰余定理を用いた最適化が使えます。「秘密鍵を使った処理」とは、デジタル署名処理においては「署名」、暗号処理においては「復号」です。つまり実際には、署名の場合は「暗号化」ではなく「復号」と同じ処理が行われています。
また、教科書によっては単に「データを秘密鍵で暗号化」としか書いていませんが、データはまずハッシュ化されます。これは単にデータ量を減らして署名処理を高速化させるだけの理由ではなく、選択メッセージ攻撃への防御というセキュリティ上欠かせない理由によるものですので、「データを秘密鍵で暗号化」という説明は危険です。(以下の PDF を参照。)
さらに、ハッシュ化も適切に行わなければなりません。(以下の記事を参照。)「データをハッシュ化して秘密鍵で暗号化」と書いてもまだ説明が不足しているのです。
で、結局どう書く / どう教えるべき?
上で書いたように、「署名」がどのような処理なのかを適切に説明しようとしたら非常に複雑な話になってしまい、すべての高校生が学ぶべき内容ではなくなってしまうでしょう。6
ですので、暗号化という言葉を使わず「秘密鍵で署名」「公開鍵で検証」とだけ書いて、その「署名」「検証」が具体的にどのような処理なのかは説明せず、署名によって何ができるかだけを説明すればいいのではないかと思います。
その他デジタル署名周り
デジタル署名は公開鍵暗号の応用ではない
デジタル署名は公開鍵暗号方式の仕組みを応用している。(東書P111)
まず、「公開鍵暗号」という言葉には 2 通りの意味があります。1 つは狭い意味での「公開鍵暗号」、RSA 暗号に代表される「公開鍵で暗号化、秘密鍵で復号ができる技術」を指し、英語では PKE(Public Key Encryption) と呼ばれます。もう 1 つは広い意味での「公開鍵暗号」で、「『公開鍵』と『秘密鍵』というものがある技術全般」を指し、英語では PKC(Public Key Cryptography) と呼ばれます。デジタル署名は、PKC の中に含まれます。詳しくは以下の記事を参照してください。
「デジタル署名は公開鍵暗号の応用」という記述は、その「公開鍵暗号」が PKE / PKC どちらの意味だとしても、不適切な文章です。
PKE の意味だとしたら(そして実際どの教科書も「公開鍵暗号」を明らかに PKE の意味で使っているのですが)、先程書いたように、RSA 署名以外では PKE は使用されていないので誤りです。
PKC の意味だとしたら、「公開鍵暗号の応用」ではなく「公開鍵暗号の一種」と書かれるべきなので、どちらの意味でも誤りと言えるでしょう。
それは公開鍵暗号方式一般の説明じゃない
公開鍵暗号方式は、「公開鍵で暗号化した暗号文を公開鍵とペアの秘密鍵で復号する」だけでなく、「秘密鍵で暗号化した暗号文を公開鍵で復号できる」という性質をもっている。(数研P139)
それは RSA 暗号が持っているだけで、他の公開鍵暗号(PKE)が必ず持っている性質ではありません。実際例えば ElGamal 暗号は持っていません。
ちなみに、上記のような説明もなしに唐突に「秘密鍵で暗号化」という記述が出てくる教科書もあります。読んだ人が「え?秘密鍵って復号用の鍵じゃなかったの?」と混乱しそうです。
デジタル署名を南京錠で説明するのはどうなのか
(第一P140)
この南京錠の使い方だと、開けることができた B さんの南京錠を再利用して自分で書いた手紙を入れた箱に付ければ簡単に B さんになりすましできますね。
南京錠の喩えは PKE の喩えとしてなら良いとは思いますが、デジタル署名に使うのは上記の理由で問題があります。無理やり南京錠で上記の問題を解決しようとしたら「一度しか使えない南京錠」などと通常の南京錠とは違うものにならざるを得ません。「喩え」というものは身近なものに喩えることで理解を促すのが目的ですから、そんな喩えは不適切でしょう。デジタル署名を何かに喩えるのであれば、その名が示すように「署名」(あるいは日本ならば押印)が良いでしょう。
デジタル署名があってもその人が書いたわけじゃない
こうしてAは、まちがいなくBが作成した文書(=Bの秘密鍵で暗号化された文書)と確認できる。(数研P139)
上で「デジタル署名を何かに喩えるのであれば、その名が示すように署名(あるいは日本ならば押印)」と書きましたが、そう考えればこの記述が誤りであることが解ります。
我々が何かの書類に署名・押印をする場合、その「書類」は自分が作成したものではない場合がほとんどです。つまり署名は、その人がその書類の内容を承認したことの証明として使われるのです。また、そもそもなぜ署名がそうした用途に使えるかと言えば「署名はその人でないとできない行為だから(※ 他の人が署名を真似しても、筆跡鑑定でバレるから)」であり、つまりは本人証明にも使えます。
一方、署名は作成者の証明には使えません。自分が作ったわけではないものに自分の署名を付けることが可能だからです。デジタル署名もこうした署名の特徴を受け継いでいる7ので、署名と同様の目的にのみ使用できます。
TLS(SSL) は共通鍵を公開鍵で暗号化しない
TLS(SSL) に関する各社教科書の記述です。
共通鍵自体は、公開鍵暗号方式で暗号化・復号を行う(実教P93)
ユーザは、サーバと共有する共有鍵を公開鍵で暗号化し、サーバへ送る。(開隆堂P113)
サーバ証明書中の公開鍵を使って、新たに生成した共通鍵を暗号化して送り…(第一P141)
こうした「共通鍵を PKE で暗号化する」方式は確かに TLS 1.2 までは選択肢としてありましたが、TLS 1.3 で廃止されましたし、1.2 においてもあくまでも「選択肢の 1 つ」に過ぎず、そして現在あまり使われていない(大体この 3 社のサイトだって使っていない8)方式であるので、それが唯一のものであるかのような書き方は誤りです。
この方式には、前方秘匿性(Forward secrecy) の問題があります。ですので最近は、鍵共有 で共通鍵を共有し、デジタル署名でサーバ認証を行う方式が主流です。
ちなみに上で挙げた 3 社以外も、
公開鍵暗号方式と共通鍵暗号方式を組み合わせてデータ通信を行う。(東書P111)
共通鍵暗号と公開鍵暗号の長所を組み合わせたSSL/TLS(日文P181)
…と書いており、そして「公開鍵暗号」を PKE の意味でしか説明していないことから、誤りと言ってよいでしょう。
あと、東書と数研はいまどき「SSL」しか書かないのはどうかと思います。
TLS(SSL) が使われていれば安全じゃない
常時 SSL は通信傍受対策?
…常時SSLという。通信を傍受されないという、Webサイトの信頼性を向上させるために行われる。(開隆堂P113)
常時 SSL は、傍受されないことが重要なのではありません。(傍受だけが重要なのだとしたら、重要な情報をやり取りするページのみ TLS を使えば充分ということになってしまう。)重要なのは、まず通信相手が本物であるという「認証」です。通信相手が偽物であれば、いくら暗号化しても無意味です。以下の記事が参考になります。
TLS を使っていても偽サイトの可能性はある
(数研P139)
「SSL が使われていれば、偽サイトは作れない」「つまり、SSL が使われていれば偽サイトではない」という誤解を与えるマズい説明です。
TLS ができるのは、「 https://qiita.com という URL でエラーなくアクセスできる、Qiita の偽サイト」を防ぐことです。逆に言えば、「 https://piita.com という URL でエラーなくアクセスできる、Qiita の偽サイト」であれば作成可能です。
本物のサイトかどうかを確かめるためには、TLS が使われていることに加え、ドメイン名が正しいものであることを何らかの方法で確かめる必要があります。9 上で引用した数研に限らず他社教科書もそこまで書いてあるものは殆どありませんが、教科書というものはそういうことをこそ教えたほうが良いのではないでしょうか。
TLS を使っていても そのサイトが信頼できるわけじゃない
閲覧しているWebサイトが、実在する運営組織によって公開されていることを確認できる。(日文P181)
これも「TLS が使われていれば、実在する運営組織によって公開されているから安全」という誤解を与えるマズい説明です。
TLS 通信で用いられる「証明書」には DV, OV, EV の3種類がありますが、「実在する運営組織によって公開されていることを確認できる」のは後者 2 つだけです。そして TLS 証明書の 80% 以上は DV 証明書 です。(ついでに言うと、そう書いている日本文教出版の Web サイトで使われているのも DV 証明書です。)ですので、TLS が使われているからといってそのサイトが実在する運営組織によって公開された安全なサイトというわけではありません。
Web サイトの実在?
URLを確認するだけでなく、そのWebサイトが実在しているか確認する必要がある。(第一P141)
アクセスできた時点で、Web サイトは「実在」しているんじゃないですかね…
変数は箱じゃない
変数についての各社教科書の記述です。
データを保管する箱のようなもの(実教P135)
箱の名前:x(開隆堂P81)
「箱」のようなもの(数研P102)
名前のついた箱のようなもの(日文P135)
(文章は無いが、図で「箱」として描画)(第一P109)
確かに、プログラミング言語によっては「変数は箱のようなもの」という喩え話は適切です。しかし多くの教科書で扱っている Python や JavaScript のようなプログラミング言語の場合は、「変数は箱」というのは早い段階で理解に困ることになる不適切な喩え話です。
例えば、以下の Python プログラムを考えます。
a = [1, 2, 3]
b = a
「変数は箱」だとしたら、この 2 行目はどのように解釈すればいいのでしょうか?
a の箱に入っているものと同じもの([1, 2, 3])をもうひとつ用意して、b という新たな箱に入れたのでしょうか?(下図左)
それとも a という箱をまるごと b という箱に入れたのでしょうか?(下図右)
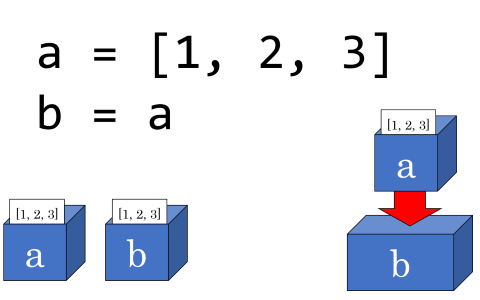
先ほどの 2 つの考え方のどちらが正しいのか確かめるため、このようなプログラムを考えてみます。
a = [1, 2, 3]
b = a
del a[0]
print(a) # => [2, 3]
print(b) # => ?
これを実行してみると、print(b) の結果は [2, 3] となります。a の値を変えたら b の値も変わったということは、先ほどの 2 つの考え方のうち、後者が正しかったと言えます。
しかし、続いてこのようなプログラムを考えてみます。
a = [1, 2, 3]
b = a
a = [2, 3]
print(a) # => [2, 3]
print(b) # => ?
今度は print(b) の結果は [1, 2, 3] になります。a の値を変えても b の値は変わらないということは、先ほどの 2 つの考え方のうち、前者が正しかったことになります。矛盾する結果が得られてしまいました。これは、そもそもの喩え話が不適切だったと言えるでしょう。
では、適切な喩えは?
こうした言語では、最近は「変数は名札、代入は名札を貼ること」という喩えが主流になってきています。10
(五十嵐 邦明、松岡 浩平「ゼロからわかる Ruby 超入門」P53)
「変数は名札」という喩えであれば、先ほどの結果を適切に説明できます。
a = [1, 2, 3] # [1, 2, 3] というデータに、「a」という名札を貼る。
b = a # 「a」という名札の貼られたデータ(つまり [1, 2, 3] )に、「b」という名札も貼る。
del a[0] # 「a」という名札の貼られたデータの先頭を消去
print(a) # 「a」という名札の貼られたデータ(つまり [2, 3])を表示
print(b) # 「b」という名札の貼られたデータ(つまり [2, 3])を表示
a = [1, 2, 3] # [1, 2, 3] というデータに、「a」という名札を貼る。
b = a # 「a」という名札の貼られたデータ(つまり [1, 2, 3] )に、「b」という名札も貼る。
a = [2, 3] # 「a」という名札を、[2, 3] というデータに貼り直す。(名札「b」は変わらず。)
print(a) # 「a」という名札の貼られたデータ(つまり [2, 3])を表示
print(b) # 「b」という名札の貼られたデータ(つまり [1, 2, 3])を表示
(※ 追記:読み落とされている方が居るようなので補足しますが、最初に「(変数は箱だという喩えは)プログラミング言語によっては適切」と書いたとおり言語によって適した喩えは違うので、「変数は箱」という喩えが常に悪いという主張ではありません。Python 等の言語を使っている以上は「変数は箱」より「変数は名札」という喩えのほうが適切でしょう、という主張です。)
Python 等は「ソースコードを 1 行ずつ実行するインタプリタ方式」じゃない
「インタプリタ」についての各社教科書の記述です。
1行ずつ機械語に変換し実行する言語(実教P131)
1行1行読みこみながら順番に翻訳・実行していくインタプリタ(数研P101)
インタプリタと呼ばれるプログラムがソースコードを1行ずつ直接実行する(日文P137)
で、Python や JavaScript はその「インタプリタ型言語」なんだそうです。
まぁ Python や JavaScript を「インタプリタ型言語」に分類することには異論はないですが(ただしそもそも現代においてそうした分類にあまり意味は無いと思いますが)、じゃあ Python や JavaScript が教科書の記述のような動作をしているのかと言えば否です。例えば以下のような Python プログラムを実行してみれば解ります。
plint(123) # ← スペルミス
if int(input()) = 123: # ← == を =
print(456)
「1行ずつ実行」しているのであれば、まず 1 行目を実行しようとしてエラーになるはずです。しかし実際にはエラーは 2 行目で発生します。
PythonError: Traceback (most recent call last):
File "<exec>", line 2
if int(input()) = 123: # ← == を =
^^^^^^^^^^^^
SyntaxError: cannot assign to function call here. Maybe you meant '==' instead of '='?
現代において実用的な「インタプリタ型言語」で、教科書記述のような動作をしているものはあまり無いでしょう。多くの実用的言語実装ではソースコードをバイトコードに変換し、そのバイトコードを VM が実行します。
この「バイトコード」は言わば VM の機械語であり、そのためソースコード→バイトコードへの変換も「コンパイル」と表現される場合があります。仮に「バイトコードへの変換などコンパイルとは認めん!」という立場をとったとしても、最近は JIT で実機機械語にコンパイルされることも多いでしょう。ですので、「インタプリタかコンパイラか」という分類にはあまり意味が無いと思います。
Python や JavaScript の話ではないですが、以下の記事をご参照ください。
日本語 1 文字は 2 バイトじゃない
漢字を含めた日本語の文字を2バイトで表す(東書P41)
漢字を含めた日本語では、文字の種類が多いため2バイトを使います。(開隆堂P90)
どうして令和にもなって「日本語 1 文字 2 バイト」なんて断定的に書いちゃうんでしょう。大体あなたがたの出版社サイトも HTML 見たら UTF-8 じゃないですか。
Web サイト向けの文字コードは今やほぼ UTF-8 であり、その場合は日本語 1 文字 3 バイト(以上)ですね。内部的には基本 2 バイトの方式が使われている場合もありますが、少なくとも「2 バイト」と断定的に書くのは明らかに誤りでしょう。
その他文字コード周りの話
「日本語用の文字コード」として「EUC」を挙げる出版社が複数あるんですが、少なくとも「日本語用の」って書くならそこは「EUC-JP」と書くべきじゃないですか?(個人的にはそもそも「EUC」を「文字コード」として挙げることにも違和感ありますが。)
ところで、東書のこの記述がよく判りませんでした。
■ユニコード 多国語を共通して利用できるように開発されたコード体系。16ビット体系のものや32ビット体系のものがある。(東書P40)
UTF-16 と UTF-32 のことを言おうとしている?しかしだとしたら UTF-8 を差し置いてなぜその 2 つのことだけを?
動画が動いて見えるのは残像によるものじゃない
「動画がなぜ動いて見えるのか」についての各社教科書の記述です。
人間の視覚特性によって起こる残像のためである。(東書P45)
見たものがすぐに消えない人間の視覚の残像現象を利用して…(開隆堂P97)
このような現象(見たものがすぐに消えない性質)を残像現象という(数研P62)
「動画が動いて見えるのは残像現象によるもの」というのは一瞬納得してしまいそうになりますが、冷静に考えてみるとおかしい説明です。
例えば、ボールが右から左へ動く 4 フレームの動画があるとしましょう。

「残像現象」理論によれば、残ることになる「残像」は以下のようなものであるはずです。

しかし我々はこの動画を見たときに、充分なフレームレートであれば「ボールが短距離テレポーテーションしながら少しずつ左へ進んだ」とは思わず、「ボールが右から左へ動いた」と思うはずです。実際には画面中央にボールは映っていないにもかかわらず、画面中央をボールが通ったと思ってしまうのです。これは明らかに残像では説明できない現象です。
残像現象で説明できること
とはいえ、動画の説明に残像現象がまったく関わらないわけではありません。例えばブラウン管テレビの場合、実際には一部に何も映っていない瞬間が存在しています。その証拠にカメラでブラウン管テレビを撮影してみると、黒い線が入ります。(参考:Google 検索「ブラウン管 黒い線」)
にも関わらず我々が目でブラウン管テレビを見ているときにはこうした「黒い線」が感じられないのは、まさに「残像現象」によるものです。
しかし上述の通りそれが「動いて見える理由」ではありませんし、ましてブラウン管テレビなど今や身の回りにほとんど存在しません。動画の話をする際に残像現象の話をする必要はないのです。
残像現象ではないなら何?
動画が動いて見える理由は残像現象でないとしたら、何という現象によるものなのでしょうか?
残念ながら、多くの人がさまざまなことを言っていて、どれが正しいものなのか私には判りかねました。
- 仮現運動だよ派 (九州大学芸術工学研究院 伊藤裕之教授、Wikipedia「残像効果」)
- 短いレンジの仮現運動だよ派 (法政大学 吉村浩一教授)
- 一次運動だよ派 (上記の吉村教授の論文中でそうした異説があることに触れている。)
- 時空間標本化だよ派 (東京工科大学 吹抜敬彦教授)
ただ少なくとも、残像現象を理由に挙げている専門家は見当たりませんでした。
ですので、「少しずつ異なる静止画像を次々見せられると動いているように見える」という現象そのものを伝えて、特にその現象の名称は伝えないのが良いかと思います。
標本化定理は「2 倍以上の周波数」じゃない
標本化定理についての各社教科書の記述です。
元の波形の周期の1/2以下で…(東書P43)
周期の半分以下の時間間隔で標本化すれば…(実教P55)
もとの音の最高周波数の2倍以上の…(日文P82)
「1/2以下の周期」「2倍以上の周波数」という表現になっていますが、「1/2より小さい周期」「2倍より大きい周波数」が正しい表現です。
とはいえ、数学的には「以上」と「より大きい」の区別は重要ですが、物理的には両者にあまり違いはありません。「50 N より大きい力」と言った時には 50.0000001 N の力でもよく、有効数字を考えると結局 50 N になってしまうからです。ですのでこの記述だけであれば、重箱の隅つつきの指摘です。
ただ、その上で一部教科書は、そのコーナーケースである「2 倍の周波数の時」を使って標本化定理を説明してしまうので、よく解らないことになってしまっています。
(東書P43)
確かに「うまく標本化すれば」(そしてうまく標本化したということも伝えれば)元の波形が再現できるでしょう。しかし現実には、アナログ波形を見てから「よし、このタイミングで標本化しよう」と決めるわけではないので、ちょうど山と谷が標本点に来るように「うまく標本化」することなどできません。下のようなタイミングで標本化されてしまったとしたら、元の波形を再現するのはどう考えても不可能です。

それから、東書と開隆堂は単に「周期」としか書いていませんが、これだとどんな波形であってもその周期の 1/2 未満で標本化すれば完全に再現できると誤解してしまいそうですね。日文は「最高周波数」という表現を使っていますが、これも説明が無いと「たとえば音楽における一番高音の時の周波数」くらいの意味に思えてしまいます。実教は「もとのアナログ波形を構成する正弦波のうち最も周波数の大きい(周期の小さい)ものに着目し、この周期の半分以下(P55)」と書いていて、「以下」を「未満」にするべきだという点を除けば正確です。(残る数研/第一は、そもそも標本化定理を紹介していません。)
その他いろいろ
なぜそれが構文エラーだと思った?
(実教P133)
それ、Python だと構文エラーじゃなくて実行時エラーです。構文エラーは、たとえば前述の『Python 等は「ソースコードを 1 行ずつ実行するインタプリタ方式」じゃない』のところで例示したプログラム
plint(123) # ← スペルミス
if int(input()) = 123: # ← == を =
print(456)
でやらかした「== を = と間違える」などのように、SyntaxError(あるいはそのサブクラス)になるエラーです。「実行時エラー」と違って実行前にエラーになるので、それで 1 行目の本来エラーになる処理が実行されなかったわけです。
「実行時エラー」の例がゼロ除算になっているところから推測すると、C 言語等におけるビルドエラーと実行時エラーの感覚で書いているんですかね?
選択ソート最強説
整列アルゴリズムでは、カードの入れ替えの回数が少なければ、より効率のよいアルゴリズムと判断することができる。(東書P81)
なぜソートにおいてアルゴリズムの優劣を交換回数だけで決めようとする…だとしたら選択ソートが最強のソートアルゴリズムですね。
普通はソートアルゴリズムの優劣は交換だけでなく比較等も含めた総計算回数で決めますよね。(ただし一般的にはソートの場合 比較回数≧交換回数 なので、オーダー記法で考える場合には比較回数のみで決まるでしょう。)
状況次第で最悪計算量か平均計算量か、あと安定ソートか否か、メモリ使用量はどうか等も考える必要があるでしょうが、あまり交換回数を最重視する状況は無い気がします。(少なくとも、それが唯一の基準であるように書くのは誤り。)
(※ 追記:上の記述は、@taqu さんのコメントを受けて修正しました。)
退避変数は「必要」じゃない
2つのデータを入れ替えるためには、片方のデータを一時的に退避させておく専用の変数(右の例ではtmp)が必要となる。(日文P144)
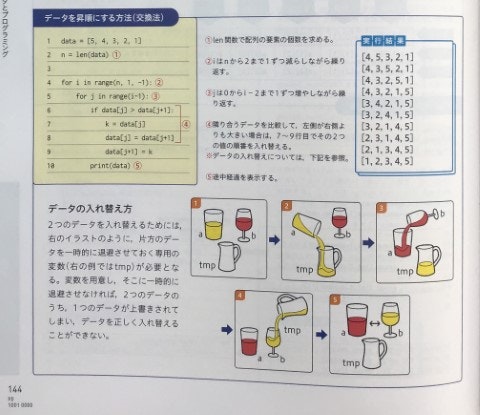
「必要」ではないですよね、この教科書で使っている Python みたいな多重代入のある言語なら。
a, b = b, a
…これだけだと「『必要』とまでは言えないことを『必要』と言っている」という日本語の粗探しに過ぎないと思った方が居るかも知れません。しかし、ここが気になったのには理由があります。
上に載せた実際の画像を見てもらえば解るように、この教科書では「データの入れ替え方」を画像をふんだんに使って丁寧に説明しています。しかし、あまりにも丁寧に説明されているがゆえに、読んだ人が「きっとこれはプログラミングにおける非常に大事なポイントに違いない!」と思ってしまわないでしょうか?
ソートについての話をするのであれば、大事なのはデータの入れ替え方ではなく、例えばこのやり方でどのようなリストであっても確実にソートすることができるという驚きを伝えることだったり、あるいは同じソートであってもアルゴリズムを変えると計算回数に雲泥の差が出るということから効率的なアルゴリズムについて考えさせるきっかけにしたりすることではないでしょうか?
であれば、このページに書かれたプログラム
data = [5, 4, 3, 2, 1]
n = len(data)
for i in range(n, 1, -1):
for j in range(i-1):
if data[j] > data[j+1]:
k = data[j]
data[j] = data[j+1]
data[j+1] = k
print(data)
は、多重代入を使って
data = [5, 4, 3, 2, 1]
n = len(data)
for i in range(n, 1, -1):
for j in range(i-1):
if data[j] > data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
print(data)
としてしまってはどうでしょう?そして「データの入れ替え方」についての説明に使っていた紙面でもっと他のことを伝えてはどうでしょうか?
もちろん、パフォーマンスを考えると多重代入より退避変数を使ったほうがいいでしょう。ですがパフォーマンスを問題にするのであれば、そもそもソートを自分で実装せずに data.sort() するのが最良です。ソートのやり方を示すのが目的であれば、多重代入を使うことにはメリットがあると言えます。
とはいえ、別に私は「絶対に多重代入を使った方がいい」と主張したいわけではありません。多重代入を使って説明することには、その後多重代入の無い言語を使い始めた際に困ってしまう等のデメリットも考えられるからです。
そうしたメリット・デメリットを勘案した結果退避変数を使うことにしたのであれば構いません。ですが、退避変数以外のやり方に気づいていたのであれば「退避変数が必要」とは書かず「退避変数を使えば良い」のような書き方をするでしょうから、多重代入を使うやり方に気づいておらず当然検討すらされていない可能性が高いでしょう。
というわけで、多重代入を使ったやり方も一度は検討していただければと思います。
その他プログラミング周りで細かい点
フォントについて
@sevenc-nanashi さんのコメントで気づきましたが、開隆堂・数研はプログラムにプロポーショナルフォントを使っています。それ以外は等幅フォントで、なおかつ第一と日文は(フォント名までは判りませんでしたが)ゼロに斜線が入ったりしているプログラミング向けフォントでした。
なお、プログラムにプロポーショナルフォントを使うことは決して悪いことではありません。詳しくは以下の記事をご参照ください。
教科書での利用ということを考えると、初心者には「これはプログラムの流れ的にオーではなくゼロだな」などの判断がつきにくいでしょうから、プロポーショナルにしろ等幅にしろ文字の区別のつきやすいプログラミング向けフォントを使ったほうがいいかなと思います。
JavaScript に関していろいろ
実教は、JavaScript で変数宣言するのに var を使っています。そこは let 使いましょうよ。あるいはいっそ変数宣言無しでやってしまうのもそれはそれでアリだと思います11が、少なくとも var を使う意味は無いと思います。
あと、東書P84に載っている以下の JavaScript プログラム。
let a=prompt('INPUT 1or2:');
if(a==1){
JavaScript の魔界、暗黙的型変換の扉を開けやがった…12
頒布権の侵害?
(1) 個人で見るのはよいが、コピーを同級生に配るのは複製権や頒布権の侵害になる。(実教P19)

この行為は複製権の侵害ではありますが、頒布権の侵害にはあたるとは言い切れません。
大事なことなので強調してもう一度書いておきますが、この行為は複製権の侵害ではあるので違法です。この記事が主張しているのは「複製権は確かに侵害しているが、頒布権の侵害にはあたらない可能性がある」というだけで、合法行為ではないので絶対に真似をしてはいけません。
頒布権とはその名の通り頒布する権利(の専有)ですが、では「頒布」とは何でしょう。その答えも著作権法に書かれています。
十九 頒布 有償であるか又は無償であるかを問わず、複製物を公衆に譲渡し、又は貸与することをいい、映画の著作物又は映画の著作物において複製されている著作物にあつては、これらの著作物を公衆に提示することを目的として当該映画の著作物の複製物を譲渡し、又は貸与することを含むものとする。
ご覧の通り、「公衆」という言葉が必ず関わってきます。では、この例題の状況は「公衆」に譲渡しているのでしょうか?
「公衆」という言葉も著作権法に定義されていて『この法律にいう「公衆」には、特定かつ多数の者を含むものとする。』となっています。通常「公衆」と言うと不特定(不特定少数/不特定多数)のイメージがありますが、著作権法上では「特定多数」も含む、ということですね。逆に言えば、「特定少数」であれば「公衆」にはあたりません。
まず「少数」の部分ですが、文化庁は「一般には50人を超えれば多数」と考えているとのことですので、この例題の状況ではあてはまらないと考えられます。(ただし後述する「著作権テキスト」には『なお,何人以上が「多数」かについては,著作物の種類や利用態様によって異なり,一概に何人とはいえません。』と書かれているので、断言はできません。)
続いて「特定」の部分ですが、当初この記事では「同級生だから不特定ではないだろう」と安直に考えてしまっていましたが、どうも単純な話ではないようです。(@takedarts さん、ご指摘ありがとうございます。)
文化庁の「著作権テキスト」 P19 に、以下のように書かれています。
さらに,一つしかない複製物を「譲渡」「貸与」するような場合,「特定の一人」に対して,「あなたに見て(聞いて)欲しいのです」と言って渡す場合は「公衆」向けとはなりませんが,「誰か欲しい人はいませんか?」と言って希望した人に渡した場合は,「不特定の人」=「公衆」向けということになります。
なんとなく私がこの例題を見てイメージした状況は「布教目的で推しドラマを配る」みたいなものでしたが、その場合は「特定少数」となり頒布権の侵害にあたらないことになります。一方「欲しい人いる?」と訊いて希望した人に渡した場合は「不特定少数」となり頒布権の侵害にあたることになります。
少なくとも、この例題の文章からは頒布権の侵害であると言い切ることはできません。ですので、頒布権の侵害に確実にあたるよう状況を補足するか、もしくは頒布権の侵害の有無には触れず複製権の侵害であることだけを伝えるのが良いかと思います。
終わりに
出版社に向けて
全体的に、「古い知識でそのまま書かれている」という印象を受けました。(日本語 1 文字 2 バイトの件とか特に。)情報分野は変化の激しい世界です。教科書は数年間使われるものなので常に最新の内容にすることは難しいでしょうが、新しく発行するタイミングではできる限り最新の知見を取り入れたものにしてほしいと思います。
また、情報という教科で扱う内容は多岐にわたるので すべての分野について専門家を駆り出すのは難しいでしょうが、それでも別に専門家でもなんでもない私レベルでも気づく誤りは無くしてもらえればと思います。
この記事を読んでくださった方へ向けて
教科書ですら誤りがあるのですから、当然この記事自体にも何らかの誤りがあるかもしれません。もしありましたらコメントや修正リクエストをお願いします。
また、手元に情報Ⅰ教科書13のある方は、こうした誤りが修正されているかどうかや、あるいはここに書いた以外にも誤りがあれば、コメント等で教えていただけると嬉しいです。
-
なお、「情報」という教科自体は 2003 年から
必修必履修で行われており、その時から「プログラミングを学ぶ科目」自体は存在していました。当初は「情報A / B / C」という 3 科目からの選択、その後「社会と情報 / 情報の科学」という 2 科目からの選択になりましたが、その中でプログラミングを学ぶ科目(情報 B / 情報の科学)を選択する学校は少数派でした。(それどころか、いわゆる「進学校」の中には「情報」の時間に実際には別の教科をやっている学校も…)
そこで今回の改定では、全員が履修する科目「情報Ⅰ」でプログラミングを扱うようになった、そして共通テストにも出題される以上逃げられなくなった、というのが大きなポイントとなっています。
(※ 追記:「必修」と書いていましたが「必履修」が正しいので修正しました。辰己先生ご指摘ありがとうございました。ちなみに辰己先生は日文教科書の執筆者のお一人です。) ↩ -
もちろんそうした先生方の中にも情報科学等について独学でしっかりと身に付けた方も多々いらっしゃるかと思いますが、アレな人も間違いなく居ます。例えば私が出会った情報の免許持ち教員(※ 本業は理科)には、電話で「パソコンの再起動の仕方が分からないからちょっと来てくれ」と呼び出されたことがあります。(さすがにその人は生徒に情報を教えてはいませんでしたが…) ↩
-
同じ出版社からも複数の教科書が出ているので「情報Ⅰの教科書」は全部で 13 冊あるのですが、全部見る余裕は無かったので「同じ出版社であれば同じような間違いをしているだろう」と考え各社から 1 冊ずつ確認しました。
なお、順番および出版社略称は 文部科学省 令和3年4月教科書目録 に従いました。 ↩ -
さらに実教では、「手紙の宛先が個人情報で、手紙の内容がプライバシー」というずっと昔に「プライバシーマーク制度」のサイト上にあった誤った解説(現在は削除済)をしています。
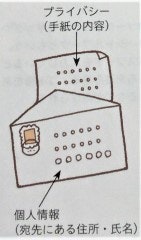 (実教P12)
(実教P12)
実教ではプライバシーという語を「むやみに他人に知られたくない私生活上の個人的な情報(P12)」と定義していますが、個人を特定できる記述を含まなければ「むやみに他人に知られたくない私生活上の個人的な情報」たりえないでしょう。例えば「A 君は今でもおねしょをしている」という情報は A 君にとってプライバシーの侵害になるでしょうが、「知り合いに今でもおねしょをしている人がいる」という情報は(ほかに個人を特定できるだけの記述を含まなければ)A 君のプライバシーの侵害とはならないでしょう。つまりこの定義で言う「プライバシー」は、基本的には個人情報に必ず含まれると言えます。 ↩ -
とはいえある意味矛盾している方がマシと言えて、教科書によってはハッシュを暗号化の一種としていたりします。「ハッシュは復号できない一方向性の暗号化(開隆堂P170)」だとしたら焚書も暗号化の一種ですね。 ↩
-
ちなみに、「署名」がどのような処理なのかを雰囲気だけでも伝えられないかと思って書いた拙記事があります。→ 足し算だけの世界の物語~第二話「デジタル署名(による認証)」 ↩
-
もちろん、あらゆる面でデジタル署名と署名が等しいわけではありません。デジタル署名はデジタルデータ故に完全なコピーが可能なので、本人証明に使うためには工夫が必要です。詳しくは 電子署名による認証(身分証明) をご参照ください。 ↩
-
もしかしたらクライアント側の設定次第では使える設定になっているかもしれませんが、そこまで確認はしていません。 ↩
-
自分のコンピューターがウイルス感染等している場合はそれでも偽サイトの可能性が残りますが、それはまた別の問題です。 ↩
-
個人の意見ですが、これは適切な入門書を見分けるのに使えると思っています。Python の入門書が雨後の筍のように出版されており玉石混淆の状況になっていますが、何冊か見た限りアレな本では「変数は箱」と説明していて しっかりした本では「変数は名札」と説明しているような気がします。 ↩
-
もちろん JavaScript で変数宣言しないのは良くないので一般論としてはやめたほうがいい(というか strict モードにするべき)ですが、プログラミング初心者に向けた入門としては、覚えることをできるだけ少なくするのは選択肢としてアリでしょう。 ↩
-
ちなみに東書は Python と JavaScript のプログラムを並べて書く形をとっていまして、隣の Python プログラムでは(当然ながら)
intによる明示的型変換をおこなっているので、それに合わせる意味でも JavaScript 側でも明示的型変換をおこなったほうが良いのではないかと思います。 ↩ -
それから、教員用指導書や問題集等を持っている方は、そちらがどうなっているか教えて頂けると非常に嬉しいです。なかなかそちらまでは手が届かず…教科書以上にいい加減なのではないかと危惧しています。 ↩