はじめに
マイクロサービスとか、クラウドネイティブとかをやっている方は一度が聞いたことがある、信頼性のベースになる最重要機能の一つである可観測性(Observabilityまたはオブザーバビリティとも言われます)について、色々なお仕事を通じて感じた所感を整理して、特にレガシーなシステムからクラウドネイティブへ転換するときに可観測性を構築していくためのポイントをまとめたものです。
若干主観(や愚痴)を交えていくので、個人の見解ということでご理解ください。
可観測性とは
まず最初に可観測性が何なのかを説明していきます。
もともと可観測性という言葉は1960年に制御工学の分野で使われ始めた言葉で、そこでは以下のように定義されています。
システムの出力からある時点でのシステムの内部状態を推測することが出来る性質
なんじゃそれって思いますよね?監視と何が違うの?ってなりますね。
可観測性登場の背景
IT業界で可観測性という言葉を自分が始めて認識したのは、2013年に出版されたGreggさんのSystems Performanceという書籍です。1 彼のHomePageにて可観測性は、
The ability to observe と定義されています。
この書籍の中では、コンピュータ内部の挙動を観測するためのツール、データソース、メソドロジーを説明するために使われていました。
さらにここ最近クラウドネイティブ界隈で、CNCFを中心に可観測性という言葉が使われ始め、クラウドネイティブやっている人達にはバズワードとして一般化してます。
最近再び盛り上がり始めた背景には次のような潮流があるかなと思っています。
クラウドコンピューティングの普及
AWSをはじめとしたクラウドコンピューティングの普及によってインフラリソースの調達が容易になり、フルマネージドなサービスも増えています。こうなるとユーザーはインフラのキャパシティを意識なくても必要なときにすぐにスケールすればよい環境を利用できます。その結果、ユーザーはインフラの管理を気にする必要がなくなり、代わりにアプリケーションの管理に興味関心が移ってきていると考えられます。
アジャイル開発の普及
アジャイル開発は従来のウォーターフォール開発とは違い、優先度の高い要件から順に開発を進めていく開発手法です。サービスインまでの期間短縮やニーズに細かく対応でき、プロダクトの価値を継続的に最大化することに重点を置いています。従来ウォーターフォール開発では、リリース後はアプリケーションの変更頻度は非常に少なかったのに対して、アジャイル開発ではリリース後も頻繁にアプリケーションに変更が行われます。そのため頻繁な変更によりアプリケーションの品質を継続的に確認する必要性が出てきました。
アーキテクチャの複雑化
コンテナ技術やマイクロサービスアーキテクチャの採用により、システムレイヤの多層化とアプリケーションの分散化が進み、システム内部で行っている処理を把握しづらくなりました。またクラウドコンピューティングの自動スケールや継続的デリバリにより構成自体の変更頻度も必然的に増えたこともあり、さらにその傾向は加速しています。結果、人の認知負荷が非常に高くなり、従来ベテラン運用エンジニアが担っていた直感や勘に頼った職人芸が通用しなくなっています。
ユーザー体験の重要性
DXの成功において、ユーザー体験の最大化は重要な課題です。ユーザー体験の一つにレイテンシがあり、ユーザーからのリクエストに早く応答するシステムが競合との一つの差別化要素となります。そのためユーザーが体験するレイテンシを監視し、応答劣化時に原因を分析する手法や体制の備えが必要となると考えられます。
コンピュータ性能の向上
従来は限られたコンピュータリソースをいかに効率的に使うか、がエンジニアリングの勘所となっていましたが、コンピュータの性能が近年飛躍的に向上したことでインフラのリソースを効率的に使うということへの関心が減ってきました。またクラウドコンピューティングが主流になってきたことで、ハードウェアは抽象化され、ハイエンドなハードウェア導入での性能差別化も難しくなってきました。そうなると、例えばいかに速いコードを書くかといったソフトウェアレベルでの品質担保が競争力となるでしょう。
可観測性の再定義と解釈
こうした市場の背景を眺めながら、改めて可観測性の意味を考えてみると、
- DXはユーザー体験が鍵でパフォーマンスもその重要な要件となっている中で
- リリースが早く、インフラも動的に変化する分散システムに対して
- 正しく内部状態を観察し、ボトルネックを特定する能力
という感じになると思われます。
一方で、クラウドの世界では、Design for Failureという障害発生を前提としたシステムデザインの思想が一般的です。
そうなると、障害発生時のボトルネック特定だけではなく、そのボトルネックに対して迅速にアクションを行えることが必要な能力になってきます。
そうなると、クラウドネイティブでの可観測性は以下のような解釈としても捉えることができます。
- DXはユーザー体験が鍵でパフォーマンスもその重要な要件となっている中で
- リリースが早く、インフラも動的に変化する分散システムに対して
- 正しく内部状態を観察し、ボトルネックを特定し、
- 未知のインシデントに対して必要なアクションを迅速に行うことのできる能力
従来の監視とはだいぶニュアンスが違うことがわかりますね。
この定義だと、オンコールやインシデントレスポンスなども範疇に入ってきます。
この性質がマイクロサービス、クラウドネイティブなシステムを運用するときにまず必要な機能である、というのも納得できますね。すでに非機能要件ではなく、機能要件といってもいいほどです。
可観測性に必要な要素
では、可観測性に必要な要素ってなんでしょうか?
ツールでしょうか?ツールはもちろん必要なのですが、それだけでうまくいくでしょうか?
(案件をしていると必ずツールだけでなんとかしようとする人たちに遭遇します^^;)
自分は以下の4つの要素が必要と考えています。

データソース
システムにデータを取得するための仕組みを実装すること。例えば、アプリケーションのログに分散トレースのIDを出力する、ビジネス指標をアプリケーション内部から取得するコードを実装する、サービスごとにヘルスチェックAPIを実装し、サマリ情報をAPI経由で取得できるようにすることなどが考えられます。従来は監視ツールのエージェントを入れるくらいの感じでしたが、人が意図的にデータソースを埋め込んでいくというのがポイントになります。
主な手法例
- 監視エージェントを導入する
- 分散トレースのSpanを実装する
- statsdやmicrometerなどのカスタムメトリクスをアプリケーション内に実装する
- SNMP Trapを設定する
- ヘルスチェックAPIを実装する
ツール
監視ツールの導入を検討します。システムには様々な観点での多種多様のデータが存在しており、そのデータの種類だけツールが存在しています。目的を持って複数のツールを組合せることが必要になる。
(一番いいツールは?ってよく聞かれます^^;)
主な手法例
- Application Performance Monitoring(APM)ツールを導入する
- Database Monitoring ツールを導入する
- インフラモニタリングツールを導入する
- ログ分析基盤を導入する
- On Call製品を導入する
メソドロジー
データソース、ツールを効果的に活用し、実践するための方法論を業務に導入します。自分たちの運用が間違ってないとみんな大体信じていて、業務インパクトもあるため、その効果を過小見積もりされがちですが、このようなメソドロジーを業務を適用して自分たちのものにしていくのが非常に重要になります。中にはアプリケーションの観点が必要だったり、マインドチェンジが必要なものも存在します。SRE的手法といってもいいかもしれません。
(ここは特に従来型のインフラ運用を是にする人はなかなか受け入れてもらうのに時間がかかります)
主な手法例
- Service Level Objective(SLO)の設定
- ダッシュボードのカスタマイズ
- オンコール自動化
- ポストモーテム
チーム
ツールを使いこなし、メソドロジーを実践できるエンジニアの体制のことです。従来、運用の一次窓口はオペレータが担ってきました。しかし、クラウドネイティブなシステムでは未知の障害に備えなければならないため、初動するチームできるだけ優秀なエンジニアで組成することが有効です。いわゆるSREです。
主なケイパビリティ
- ソフトウェアエンジニアリング
- 自動化
- システムパフォーマンスに精通している
- 原因分析力
- 広い視野
- 関係各所の巻き込み
この4つに対して、きちんと設計をすることが大事です。
レガシー案件からのクラウドネイティブ化案件だと、特にツール以外の3つの重要性をメンバに理解してもらうことが非常に大変です。
可観測性導入プロセス
ここからは、色々苦労してきた中で、こうやっていくとうまくオンボーディングしていくよ、というポイントを書いていきます。これが正解じゃないし、これ以外もあると思いますが。
まず最も大きな制約になるのが、運用とか開発とかの組織に関する部分です。Team Topologiesのようにできたら苦労はないんでしょうけどレガシーなシステムからクラウドネイティブにリプレースしていうような案件だと、ここが一番のボトルネックになります。ということでここから着手していきます。
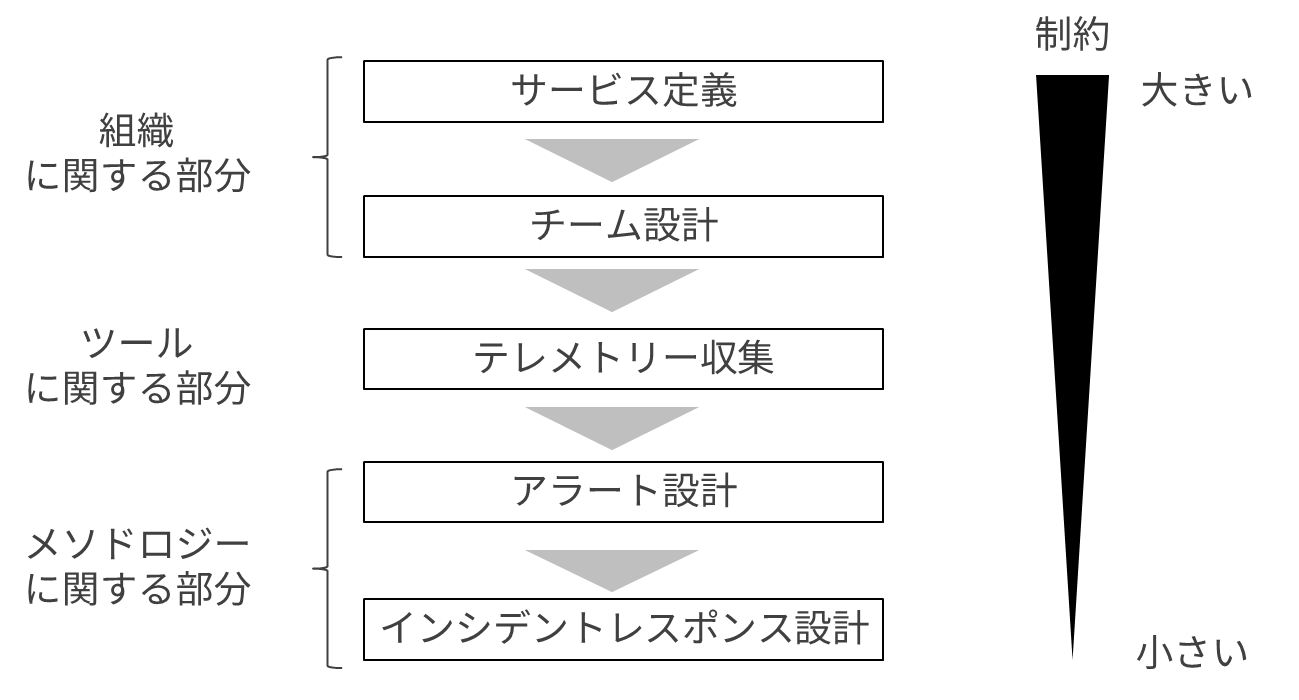
組織
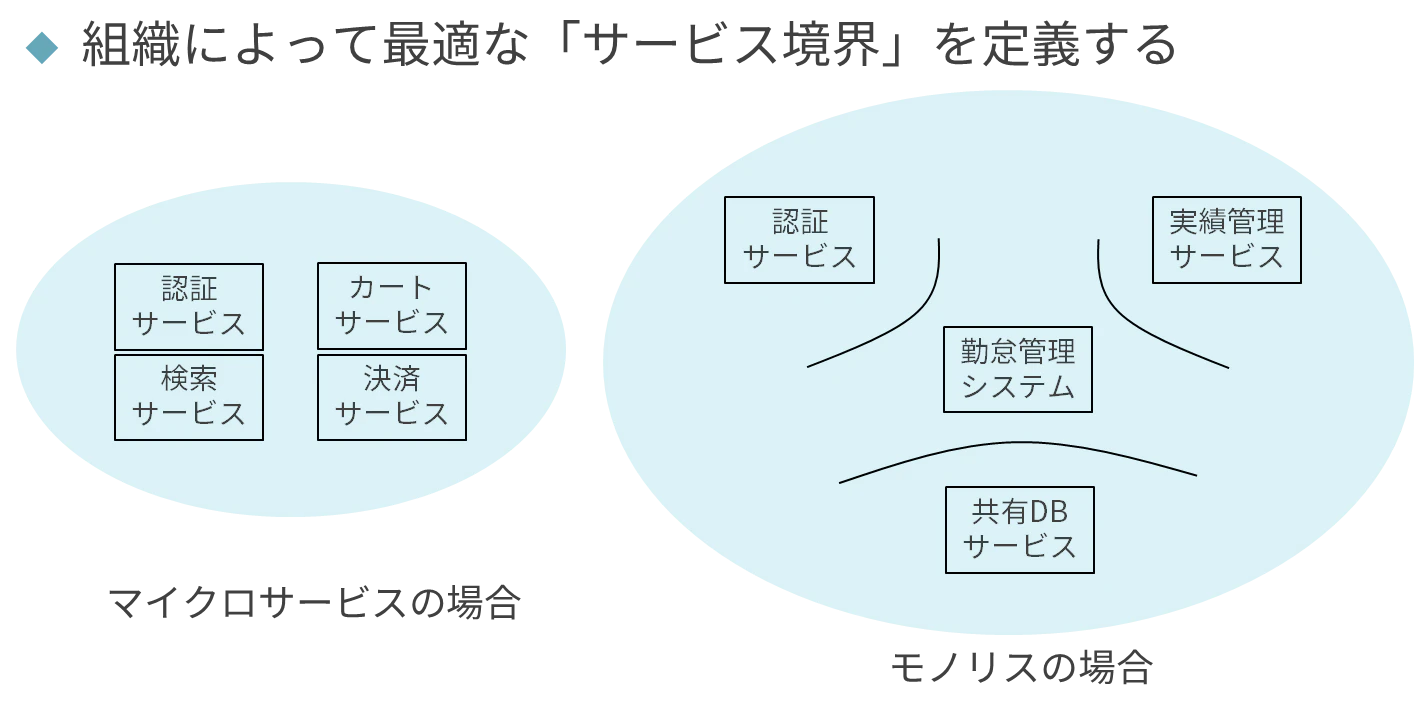
サービス定義
組織が制約になると書きましたが、多くの場合その制約はそのまま受け入れてはいけません。大体サービスに関して最適化されてないからです。まずは守るべきサービスというのを明確に定義していきながら、それに対応するチームを1vs1対応させていく形がとれないかを探っていきます。マイクロサービスなら分割済みなので、話は早いのですが、そうでないならそうもいきません。
ここはマイクロサービスではないなら、ドメイン分割とかを意識する必要はありません。どちらかというと開発チーム単位とか運用チーム単位とか、機能単位とかでサービスとそのサービスの面倒を見るチームが対応していればよいです。
チーム設計
次にサービス分割案をもとに、それに対応するチームを設定していきます。前段でサービスを定義したので、ポイントはそのサービスの信頼性に責任を持っている人たちでチームを構成していくという点です。
チーム内にインフラメンバだけみたいな感じになると、アプリ側の修正ができないなどの問題が生じますので必ず技術的にフルスタックになるように構成します。SREもこの中で徐々に育成していくプランがあるとさらによいでしょう。
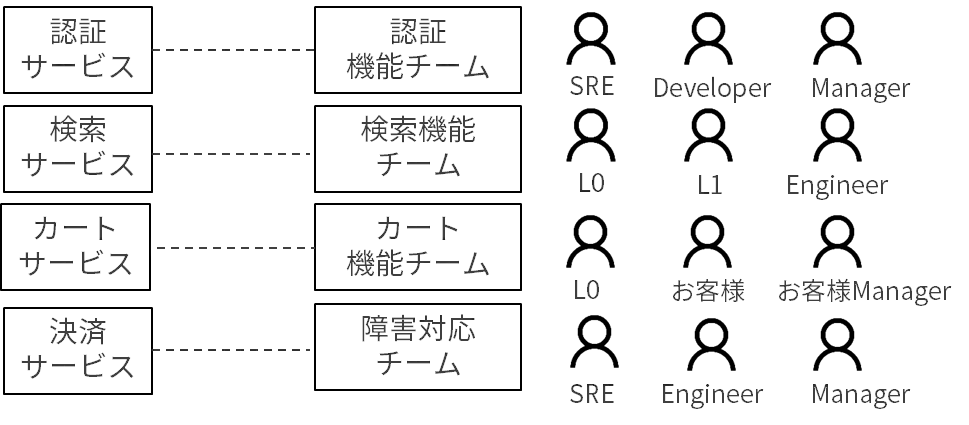
レガシーとかオンプレでよくあるのが、システム全体をまるっとインフラエンジニアが運用するというパターンです。これはクラウドネイティブのような動的で変更していくシステムには通用しません。キャパシティ上のボトルネックが変わりうるため、インフラメトリックだけでは障害発生時の原因を追いきれないからです。またこうして1vs1で対応させるチーム設計をすることで傍観者効果を排除することも狙いです。One Service, One Teamで構成してあげましょう。
テレメトリー収集
これはデータソースを作り込みツールを選定する作業です。
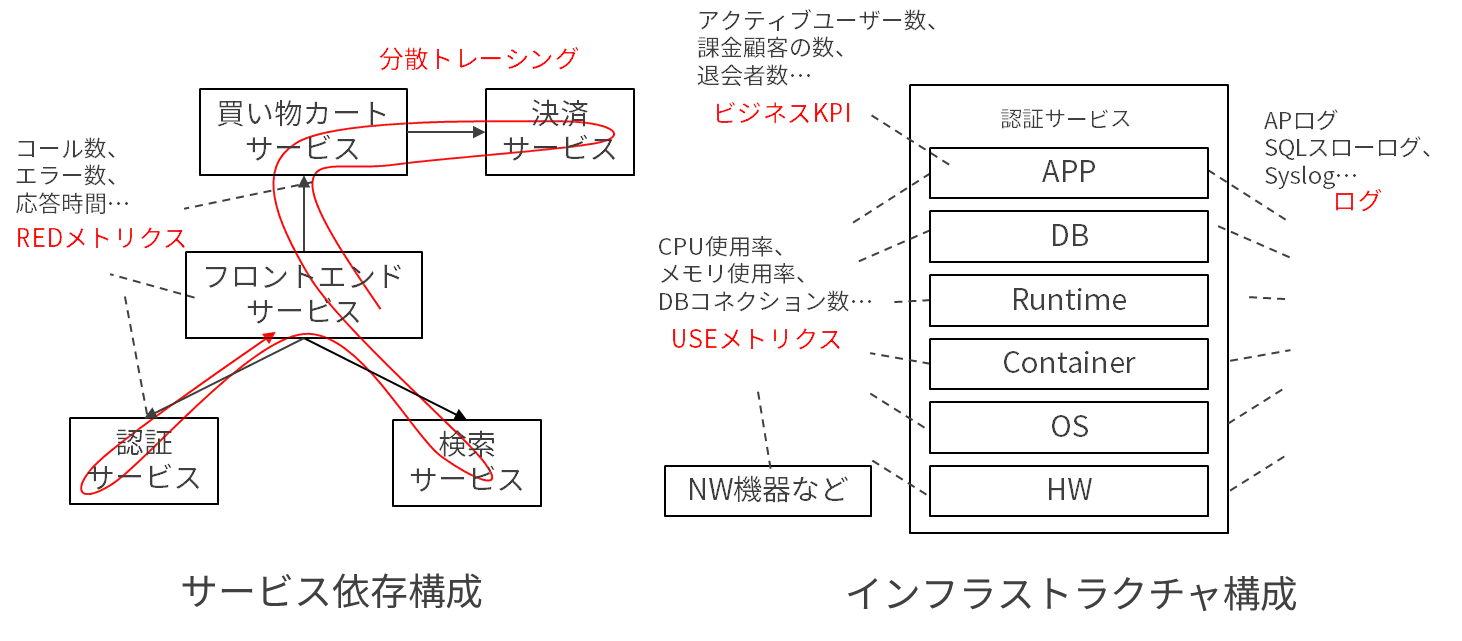
ざっくりテレメトリーは3種類に分類されます。有名な3本の柱で俯瞰するとわかりやすいでしょう。

これらはそれぞれ特性があり、どれか1つが欠けると可観測性が下がりますので、気をつけましょう。
またこれらをシステムレイヤにマッピングして、サービスごとに見るべきテレメトリーを設定していきます。
ここで重要なのは、サービス視点、アプリケーション視点のテレメトリーです。インフラはどうでもいいとまでは言いませんが、SaaS監視ツールを選ぶと、大抵はよろしく収集してくれますので、ここではサービスとして取得すべきデータを慎重に選定することに集中しましょう。前段でサービスごとに分割したことで、ターゲットが明確になり、よりそのサービスに即した検討ができるようになります。
メソドロジー
メソドロジーはたくさんあるので、全てをここではあげませんが、重要なメソドロジーをいくつかあげます。
SLI, SLOの設定
前段で分割したサービスに対してSLI、SLOを設定していきます。
SLI, SLOの説明はあまりにも解説が世にあふれているため、ググってください。
アラート設計
アラートはSLO違反したものや既知の重要なイベントに限って通知します。何でもかんでもアラートを送ると、大量のアラートに埋もれて、アクションが遅れます。すなわち可観測性が低下する要因になります。ここも結構既存運用の人には拒否感を示す方が多い印象ですので、丁寧に説明してあげましょう。
大事なのはアクションすべきイベントを確実に人が認知できることです。
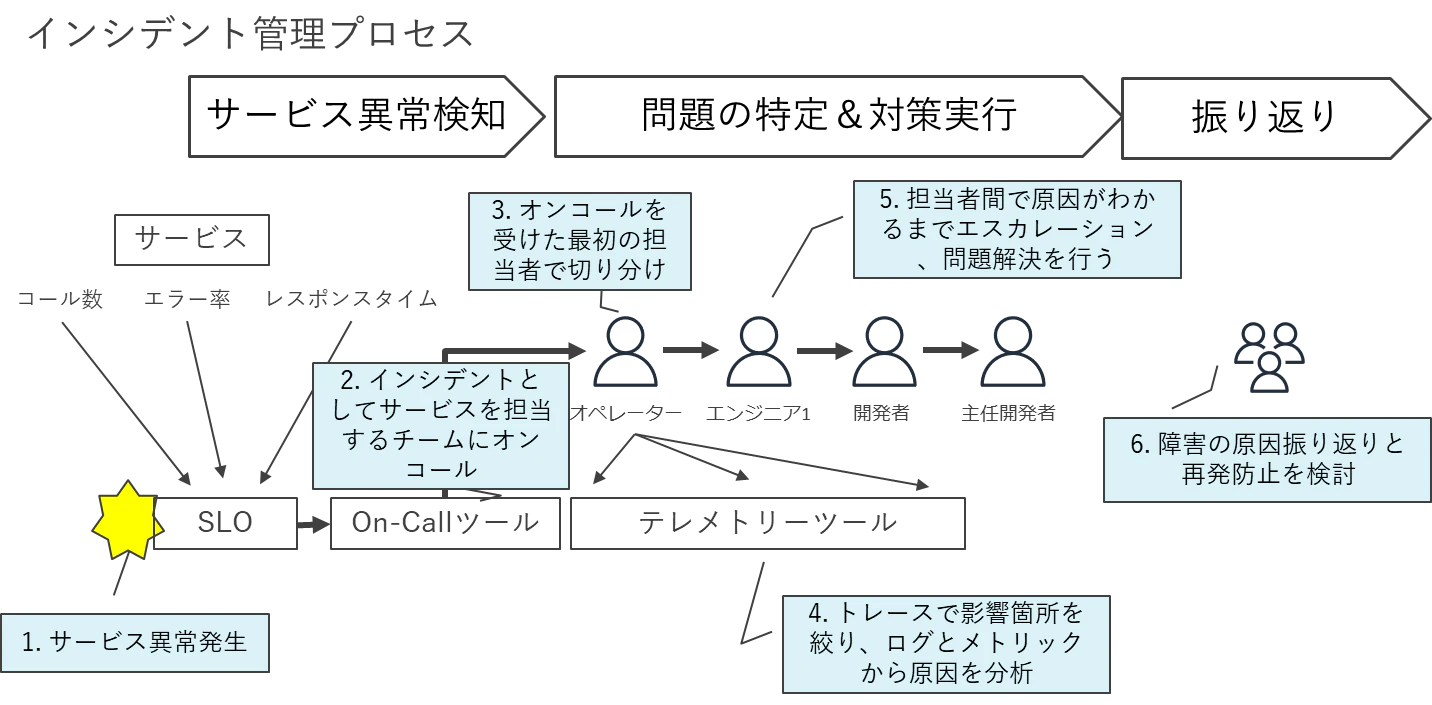
インシデントレスポンス設計
ここはオンコールの流れを設計して、その連携を自動化することが大事です。
ポストモーテムとかそういうのもここに入りますが、まずはオンコール連携の自動化を優先しましょう。
障害に対して、人がアクションするまでの時間を短縮することが大事です。
まとめ
本記事では、可観測性を現場で構築していくときに、大事なポイントを所感ベースでまとめてみました。
これは現場のクラウド習熟度やマインドによって大きく変わりますが、大事なのはツールなどの技術だけでは可観測性は作れないということで、エンジニアリング要素が多分に詰まっているよ、ということです。
この記事が誰かの気付きになれば幸いです。ありがとうございました。