はじめに - 可観測性とは?
クラウドネイティブなシステムでは可観測性を確保することが必須である、という話題を最近よく聞きます。可観測性はもともと制御理論で用いられていたワードでしたが、クラウドネイティブな業界では「システムという複雑な系から、その内部状態に関する情報を取得できる性質」と定義されます。可観測性が高ければ高いほど、システムの健康状態や可用性の正確な把握、また障害分析からの早期復旧が見込める度合いが強くなると言えます。可観測性を担保するうえで主要な3つのデータソースがメトリクス、ログ、トレーシングでありこれらの情報を効果的にモニタリングすることが重要になってきます。
モニタリングとデバッギング
Cindy氏は Monitoring in the time of Cloud Native というタイトルのブログの中で可観測性を構成する要素としてプロアクティブな部分とリアクティブな部分を分けて、プロアクティブな部分はオーバービューとアラートといういわゆるモニタリング、リアクティブな部分はデバッキング、プロファイリング、依存性分析であると述べています。モニタリング基盤としてPrometheusやELK, 分散トレーシングを駆使して障害発生のレイヤまでは特定しても、そのサーバの中で何が起こってるかわからず原因不明で終わってしまう障害は少なからず存在します。こういった場合にデバッギングをはじめとした分析が必要となります。

こうしたデバッグの技術は、多くの企業がそのシステムに長い経験を持つ職人エンジニアに頼ることも多く、またスタックトレースやstraceなど本番環境では負荷が高くて実施できず、時間が取れず原因調査を断念せざるを得ないということも現場ではたびたび発生します。
デバッグを本番環境でも安全に低負荷で行う方法があれば可観測性も上がり結果的に職人エンジニアの負荷も下げることが可能になります。
eBPF is 何?
eBPF は extended Berkeley Packet Filterの略で1992年に発表された「The BSD Packet Filter:A New Architecture for User-level Packet Capture」という論文で発表されたネットワークのパケットキャプチャツールに端を発しています。これはユーザー空間でカーネル内の任意の操作を安全に実行するためのフレームワークでネットワークパケットのフィルタや集計をユーザー空間からの操作でカーネル内で行い必要な結果だけをユーザー空間に戻すことができました。tcpdumpもBPFの仕組みを内部で使っています。eBPFはこれをネットワークパケット以外にも拡張したものでユーザープログラムから様々なカーネルのイベントをフックして情報をフィルタしたり集計された結果をユーザー空間に戻すことが可能です。
eBPFの特徴としては、
- 内部にverifierという機構がありループなどの危ない処理は実行できないようになっている
- 計算量が少なくリソースオーバーヘッドが少ない
ということがあげられます。
ここではeBPF自体の詳細な仕組みの説明はいたしませんが、Linuxカーネルに命令を送る新しい安全なインターフェースができたことでソフトウェアの作り方まで変わりうる革命的な出来事であると言われています。
このあたりを知りたい方はBredan Gregg氏がUbuntu Matstersの基調講演であるA new type of softwareをあたってください。
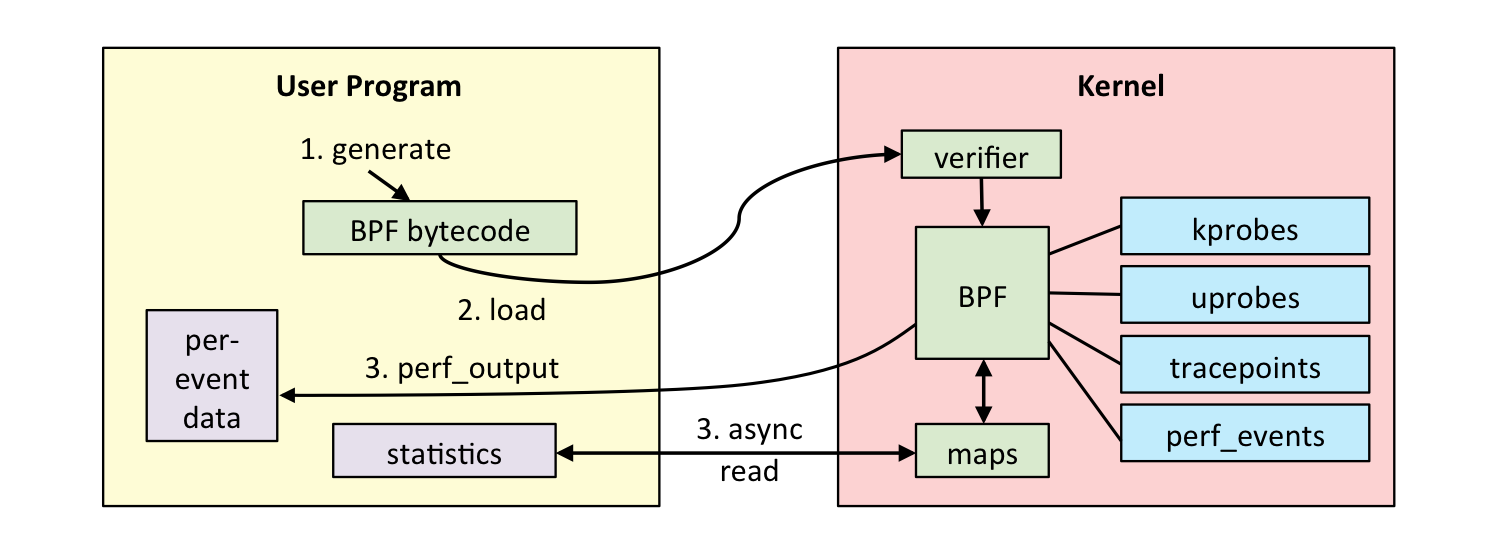
eBPFのユースケースはネットワークのトレーサビリティ、セキュリティ、パフォーマンス分析などにも広がりeBPFをベースとした新しいツールやベンダも次々に出現しています。
本記事ではeBPFのユースケースの中の一つであるパフォーマンス分析ツールとしての用途を紹介します。
これらはLinux Observabilityとも呼ばれ、まさにデバッグで活躍する道具になります。
bcc, bpftrace
eBPFはフレームワークなのでもちろん自分で実装することができるのですが、バイトコードレベルでの実装になるため、いきなりだと実装の敷居が非常に高いです。そこでBCCやbpftraceといった形でユーザーからはバイトコードを意識しない形で使えるツール群が作られています。
bcc
bccはeBPFの仕組みを使って開発されたツール群の総称でそのほどんとのツールはLinux カーネル4.1以上を必要とします。LinuxのCLI形式でまとめられていて2019年12月現在83個のツールがあります。
下図にあるようにシステムのあらゆるレイヤの分析を可能にするツール群が揃っています。

bpftrace
bpftraceはeBPF技術に基づいた高レベルのフロントエンド言語です。2018年にAlastair Robertsonによって公開されました。
SystemTapやDTraceの後継版だと思っていればおおよそイメージ合ってると思います。
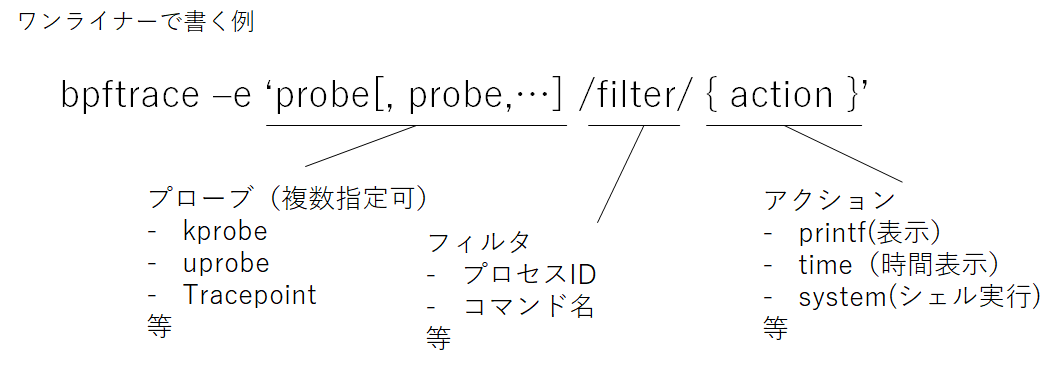
bpftrceは複数のprobeを計測対象(下図)としてその結果について処理を行います。シンプルなものであれば下記のようにワンライナーで書くことができます。指定したプローブで発生したイベントをフックすると、フィルタで指定した条件で、アクションを実行するというかたちで動きます。

使ってみた
Brendan氏がgithubで公開しているWorkshopの内容を実践する形でLinuxのObservabilityを体感してみます。
このworkshopにあるlab001をまずはコードを見ずに実行してみます。
なお、下記のコマンド操作はAWS上でFerora 31を使って実行しました。
$gcc -O0 -o lab001 lab001.c
$./lab001 &
調査スタート
まずはbcc, eBPFを使わずに従来の方法で調査をしてみます。
# vmstat 1 10
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 1 0 5693392 168812 1907500 0 0 7 1621 383 835 1 1 76 22 0
0 1 0 5693396 168812 1907508 0 0 0 532 246 501 0 0 50 50 0
0 1 0 5693396 168812 1907508 0 0 0 2544 228 460 0 0 50 50 0
0 1 0 5693396 168812 1907508 0 0 0 536 234 497 0 0 50 50 0
0 1 0 5693396 168812 1907508 0 0 0 532 237 486 0 0 50 50 0
iowaitがCPU50%程度を占めています。
次にコアごとに見てみます。
# mpstat -P ALL 1
Linux 5.3.7-301.fc31.x86_64 (ip-10-7-0-39) 12/22/2019 _x86_64_ (2 CPU)
04:58:28 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
04:58:29 AM all 0.00 0.00 0.00 50.00 0.00 0.00 0.00 0.00 0.00 50.00
04:58:29 AM 0 0.00 0.00 0.00 33.00 0.00 0.00 0.00 0.00 0.00 67.00
04:58:29 AM 1 0.00 0.00 0.00 67.00 0.00 0.00 0.00 0.00 0.00 33.00
04:58:29 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
04:58:30 AM all 0.00 0.00 0.00 49.75 0.00 0.00 0.00 0.00 0.00 50.25
04:58:30 AM 0 0.00 0.00 0.00 33.33 0.00 0.00 0.00 0.00 0.00 66.67
04:58:30 AM 1 0.00 0.00 0.00 66.00 0.00 0.00 0.00 0.00 0.00 34.00
04:58:30 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
04:58:31 AM all 0.00 0.00 0.00 50.00 0.00 0.00 0.00 0.00 0.00 50.00
04:58:31 AM 0 0.00 0.00 0.00 38.38 0.00 0.00 0.00 0.00 0.00 61.62
04:58:31 AM 1 0.00 0.00 0.00 61.62 0.00 0.00 0.00 0.00 0.00 38.38
ここまで見てlab001のプログラムが原因かはわかりませんが、マルチCPUコアを使ってIOを大量にしてそうだ、という状況まではわかりました。
次にプロセスごとのIOを見てみます。
# pidstat -d 1 5 -l
Linux 5.3.7-301.fc31.x86_64 (ip-10-7-0-39) 12/22/2019 _x86_64_ (2 CPU)
06:04:21 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:22 AM 0 395 0.00 0.00 0.00 67 jbd2/nvme1n1p1-
06:04:22 AM 0 14461 0.00 136.00 0.00 34 ./lab001
06:04:22 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:23 AM 0 395 0.00 0.00 0.00 65 jbd2/nvme1n1p1-
06:04:23 AM 0 14461 0.00 132.00 0.00 32 ./lab001
06:04:23 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:24 AM 0 395 0.00 0.00 0.00 67 jbd2/nvme1n1p1-
06:04:24 AM 0 14461 0.00 136.00 0.00 33 ./lab001
06:04:24 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:25 AM 0 395 0.00 0.00 0.00 67 jbd2/nvme1n1p1-
06:04:25 AM 0 14461 0.00 132.00 0.00 34 ./lab001
06:04:25 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:26 AM 0 395 0.00 0.00 0.00 61 jbd2/nvme1n1p1-
06:04:26 AM 0 14461 0.00 2172.00 0.00 38 ./lab001
Average: UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
Average: 0 395 0.00 0.00 0.00 65 jbd2/nvme1n1p1-
Average: 0 14461 0.00 541.60 0.00 34 ./lab001
これを見るとlab001が何やら書き込みを(しかもずっと観察していると6秒に1度程度大量の書き込み)をしていることがわかります。
従来の方法だと本番環境でこれ以上の調査をするのは、なかなか難しいかなと思います。
次にeBPFの仕組みを使ったbccを使って調査をしてみます。
# ./biosnoop.py
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
0.000000 jbd2/nvme1n1p1 396 nvme1n1 W 3716912 8192 10.13
0.009870 jbd2/nvme1n1p1 396 nvme1n1 W 3716928 4096 9.78
0.020079 jbd2/nvme1n1p1 396 nvme1n1 W 3672064 4096 10.16
0.029849 lab001 14461 nvme1n1 W 2525368 4096 9.70
0.030500 jbd2/nvme1n1p1 396 nvme1n1 W 3716936 32768 0.58
0.030971 jbd2/nvme1n1p1 396 nvme1n1 W 3717000 4096 0.39
0.039843 lab001 14461 nvme1n1 W 2525376 4096 8.82
0.049854 jbd2/nvme1n1p1 396 nvme1n1 W 3717008 8192 9.96
0.059852 jbd2/nvme1n1p1 396 nvme1n1 W 3717024 4096 9.92
0.069824 lab001 14461 nvme1n1 W 2525376 4096 9.91
0.079877 jbd2/nvme1n1p1 396 nvme1n1 W 3717032 8192 9.99
・・・・
biosnoop はブロックデバイスI/OをIOごとに出力するbccのツールです。これを実行すると上記のように
書き込みI/O が短い間隔でひたすらされていることがわかります。
jdb2/はカーネルプロセスなので、おそらくlab001からの処理を行っているI/O系のプロセスでしょう。
次に、これらのI/Oがどのファイルに対して行われているかをfileslowerというツールで調べてみます。
引数にある0はmsのレイテンシを指定します。
今回は0ms以上で指定しましたが、ここは任意の値を指定でき、指定した時間以上のみ表示することができます。
# ./fileslower.py 0 -p 14461
Tracing sync read/writes slower than 0 ms
TIME(s) COMM TID D BYTES LAT(ms) FILENAME
0.012 lab001 14461 W 128 0.01 lab001.log
0.040 lab001 14461 W 128 0.02 lab001.log
0.071 lab001 14461 W 128 0.02 lab001.log
0.101 lab001 14461 W 128 0.02 lab001.log
0.131 lab001 14461 W 128 0.02 lab001.log
0.161 lab001 14461 W 128 0.02 lab001.log
0.190 lab001 14461 W 128 0.02 lab001.log
0.221 lab001 14461 W 128 0.02 lab001.log
0.251 lab001 14461 W 2097152 0.54 lab001.log
0.361 lab001 14461 W 128 0.01 lab001.log
0.391 lab001 14461 W 128 0.01 lab001.log
0.420 lab001 14461 W 128 0.01 lab001.log
0.450 lab001 14461 W 128 0.01 lab001.log
0.480 lab001 14461 W 128 0.01 lab001.log
0.511 lab001 14461 W 128 0.01 lab001.log
0.541 lab001 14461 W 128 0.01 lab001.log
0.571 lab001 14461 W 128 0.01 lab001.log
0.600 lab001 14461 W 128 0.01 lab001.log
0.630 lab001 14461 W 128 0.01 lab001.log
・・・
fileslowerはカーネルの中のvfs_read(), vfs_write()関数が行うファイルの読み取り/書き込みイベントをトレースします。
lab001は短い時間にlab001.logファイルに大量の書き込みをしていることがわかりました。
また実際のコードも確認してみてください。
上記の例ではごくごく簡単な例でしたが、実際本番環境のプロダクションコードでデバッグが必要な状況を想定すると、その威力は容易に想像できるのはないでしょうか。このディスクI/O以外の例でもCPU、メモリ、ネットワークなどのレイヤで同じような詳細な分析が可能になっています。
まとめ
- クラウドネイティブでは可観測性が大事
- 可観測性にはモニタリングとデバッギングがある
- eBPFの仕組みを使うことでLinux上で安全で低負荷にデバッキングができる