この記事はなに?
Elastic Stackバージョン8.xを使って、オブザーバビリティやSIEM用途でログやメトリクスを収集するなら、Elastic AgentとIntegrationsを使うのが一番です。それにより色々なソフトウェアのログやメトリクスを簡単に集めることができます。
本記事では、そのElastic Agent自身の監視や状態確認を行うための方法について紹介します。
この記事はElastic Stack バージョン8.14を元の執筆しています。
Elastic Agentのインストール
まずはElastic AgentとIntegrationのセットアップから。
IntegrationsからElastic Agentで使うデータ収集方法を選択します。今回はCustom Logsを選択します。
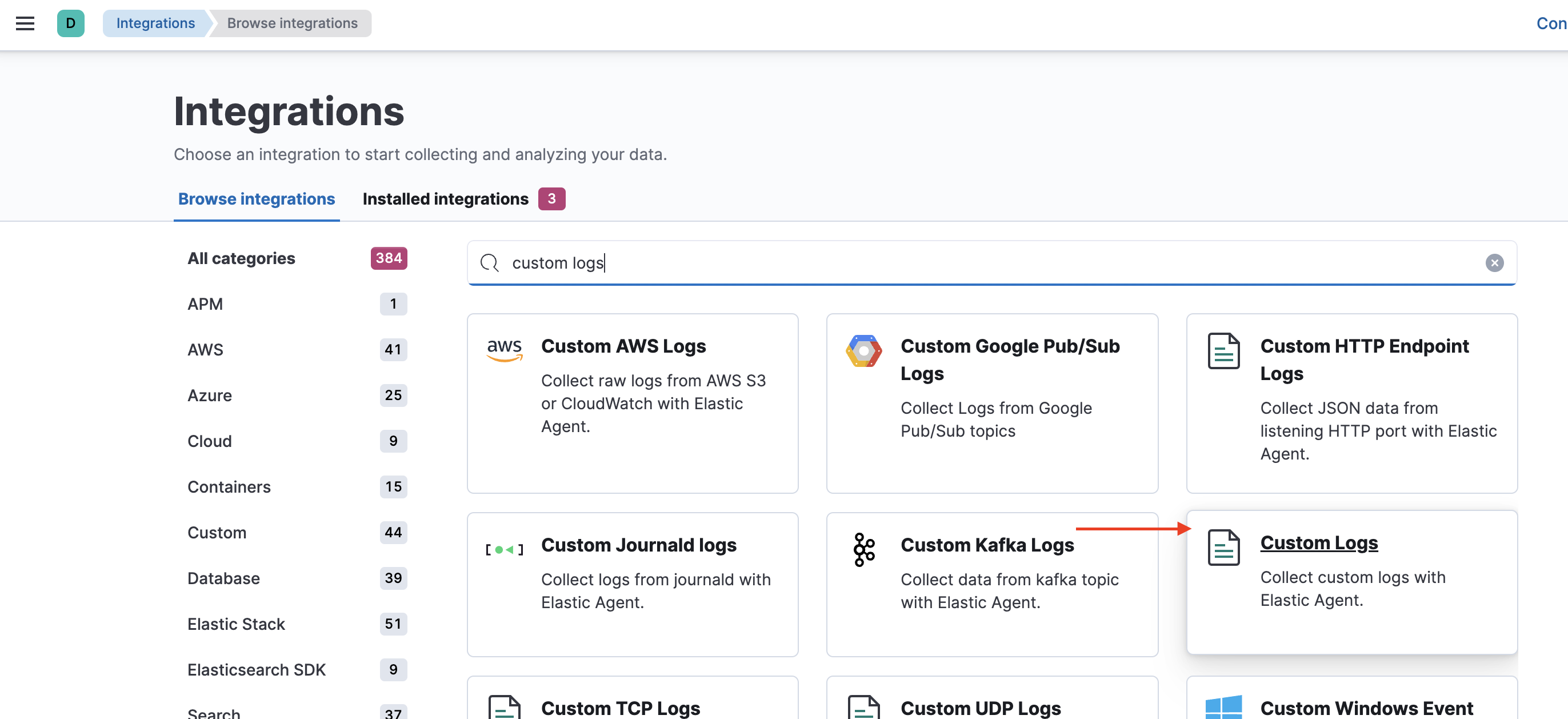
今回は/tmp/test.logに書き込まれるログを集めるように設定しました。
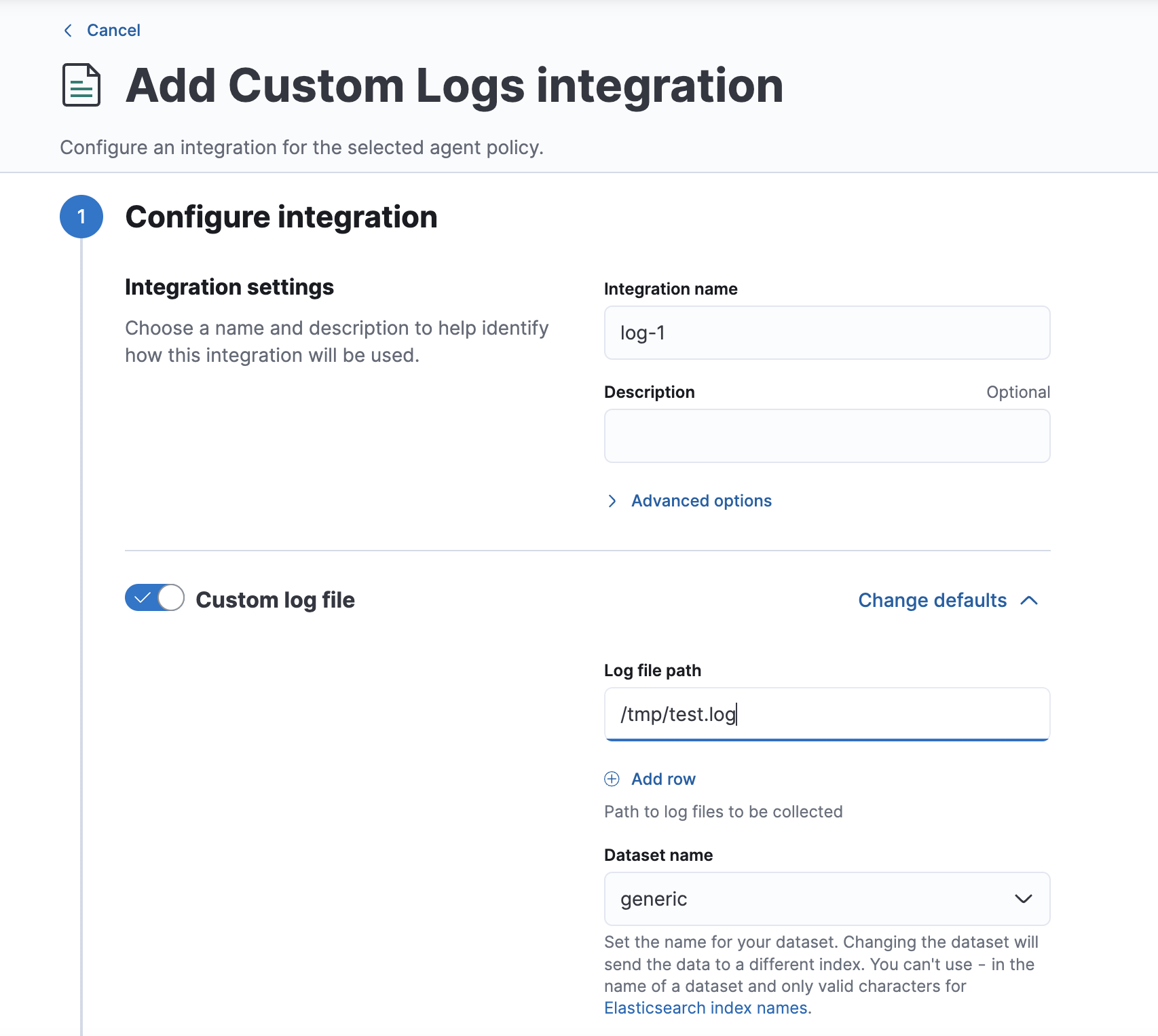
表示されるインストールコマンドのURLとトークンをコピーして..
今回はElastic Agentをコンテナ上で起動させるので、docker-compose.ymlが読み込む.envにインストールのパラメータを貼り付けします。
# Version of Elastic products
STACK_VERSION=8.14.0
PROJECT=elastic-agent-fleet
FLEET_URL=<設定してください>
FLEET_ENROLLMENT_TOKEN=<設定してください>
version: "3.0"
services:
elastic-agent:
hostname: ${PROJECT}-elastic-agent
image: docker.elastic.co/beats/elastic-agent:${STACK_VERSION}
restart: always
environment:
- FLEET_ENROLL=1
- FLEET_URL=${FLEET_URL}
- FLEET_ENROLLMENT_TOKEN=${FLEET_ENROLLMENT_TOKEN}
コンテナを起動して、以下のようにエンロールが成功したら疎通できています。

Elastic Agentのステータスを監視しましょう
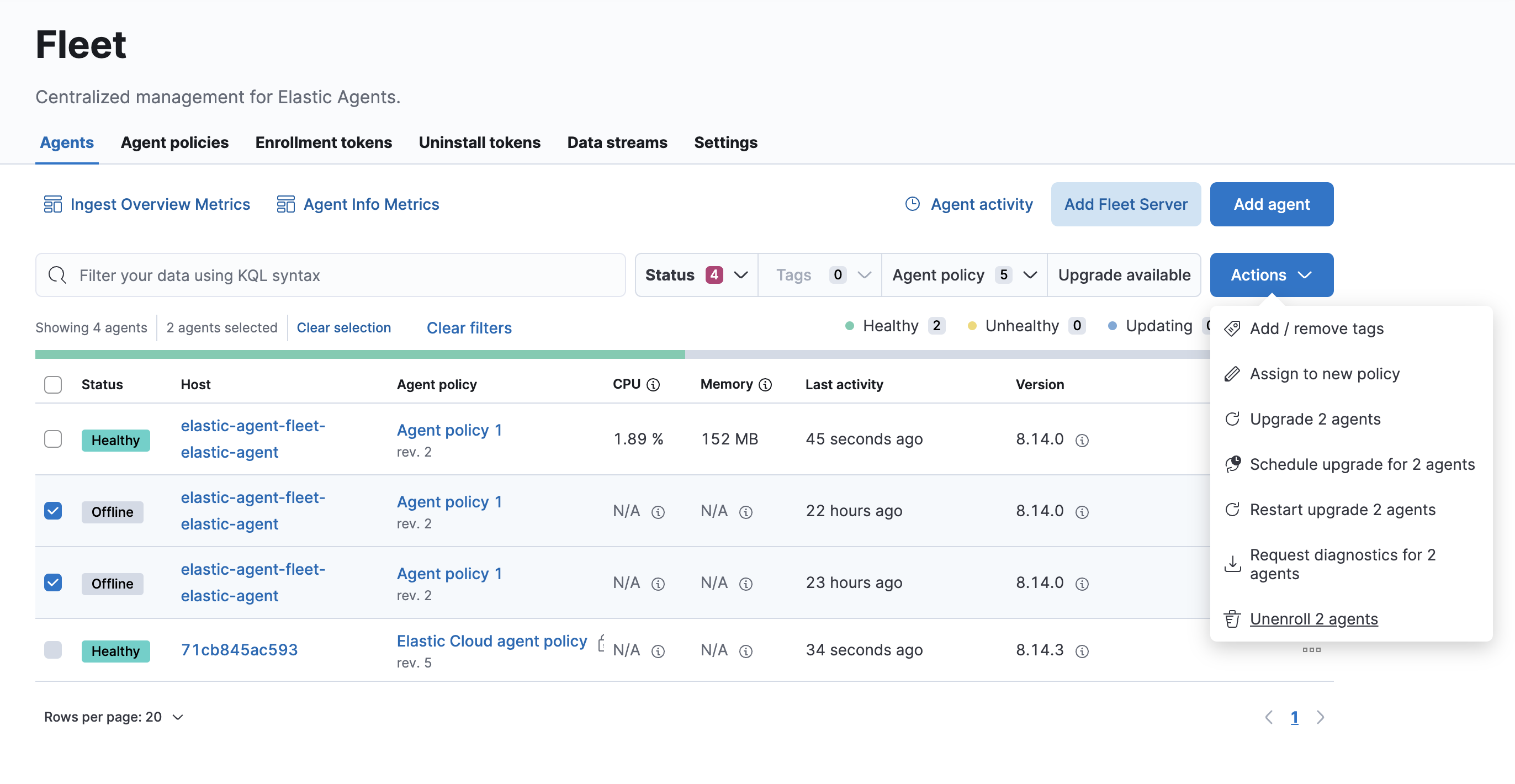
Fleet画面のAgent一覧で接続できたエージェントを確認します。

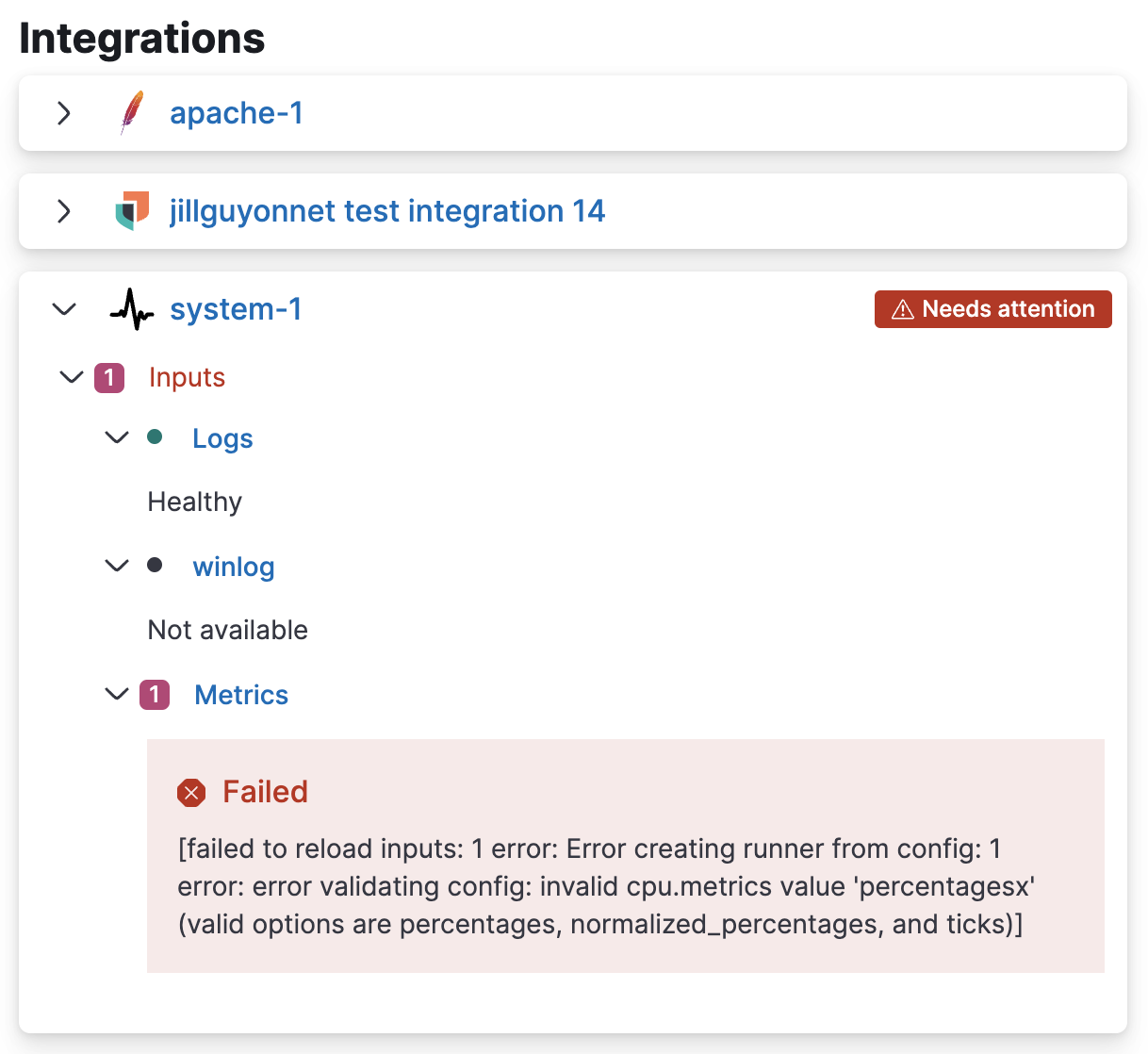
ここの各Status値については、ドキュメントに記載がありますが、運用時の監視という観点では以下2つのステータスに気をつけます。
- Unhealthy ... このドキュメントには、Elastic Agentが内部で起動する子プロセスのFilebeatやMetricbeatからの応答がないときはUnhealthyとなるとあります。
- Offline ... Elastic Agentを停止したり、Elastic Agentからのネットワークを遮断したりすると、Offlineになります。
また、個別のエージェントのリンクをクリックすると、Integrationの設定に問題があったかを確認できるようになっています。(下のサンプルはView details for an agent
より)
Offlineに対する監視アラートの設定
以下のドキュメントに書かれている方法で、Elastic Agentのステータスに応じてアラートをあげるようにすることができます。
Offline監視アラート通知設定方法
https://www.elastic.co/guide/en/fleet/8.14/monitor-elastic-agent.html#fleet-alerting-example
こちら簡単に説明すると、metricsにfleet.agents.offlineというフィールドにOfflineのエージェントのカウントがあるので、そのカウントを監視しましょうという話です。
その前に、下の画像のようにOfflineで放置されている、もう使っていないElastic Agentのデータが残っていたら、先にこれらをUnenrollしましょう。そうしないと、これらが引っかかってアラートが上がってしまいます。
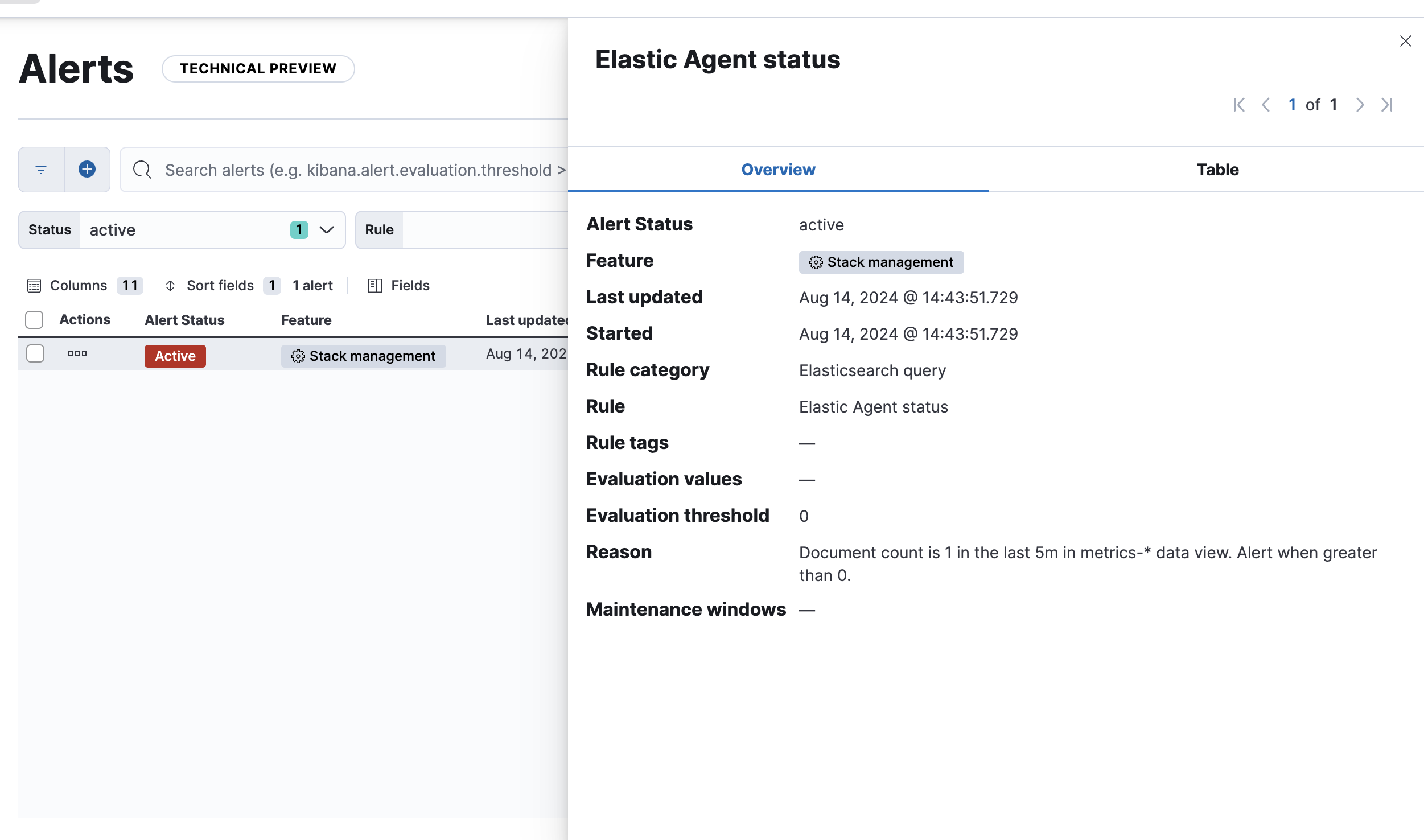
監視アラートのテスト
では、実際にElastic Agentのホストのネットワークを遮断してみました。この時の時刻は14:35でした。
アラートが上がったのは、約8分後でした。
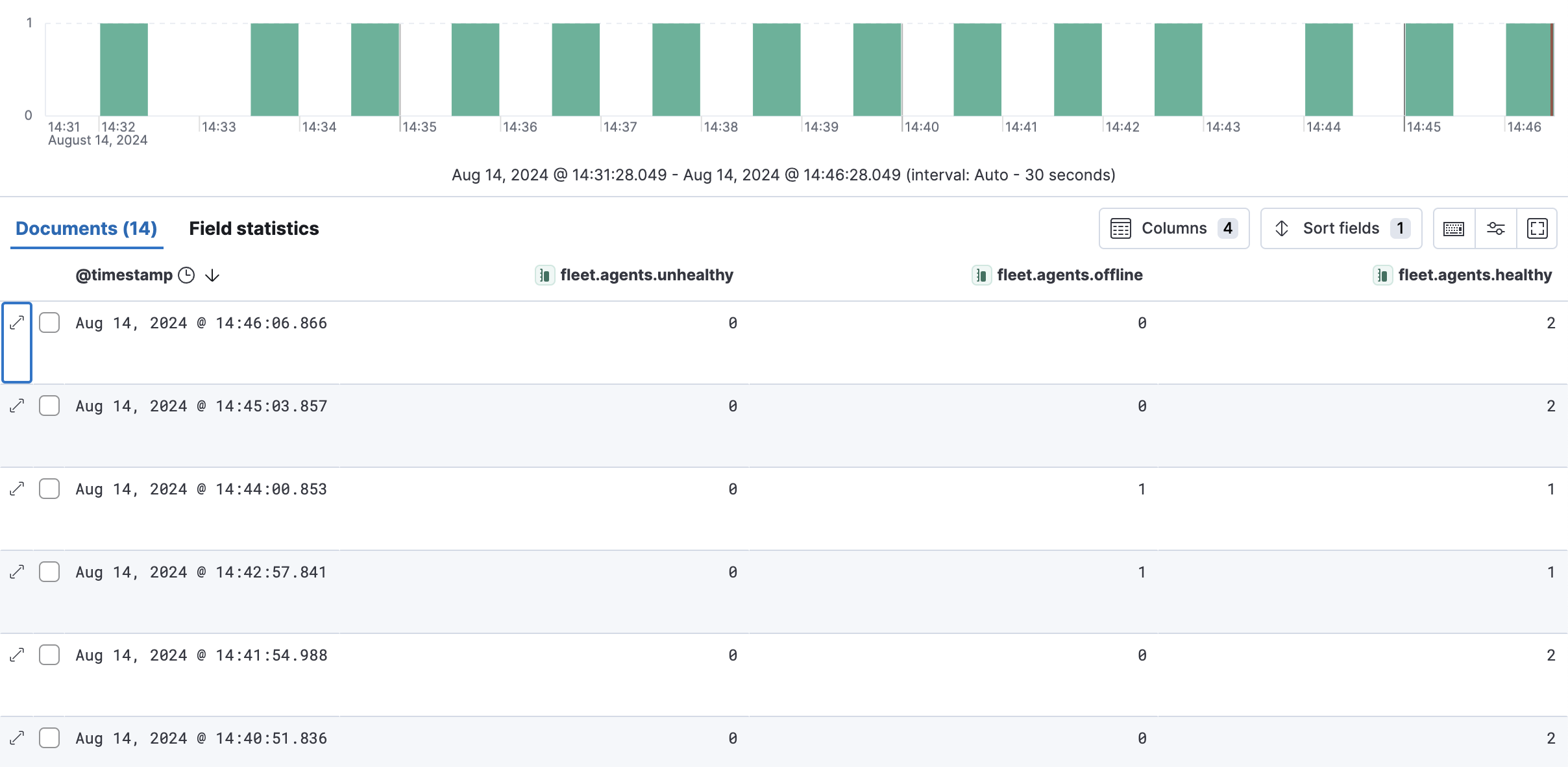
Discoverで監視対象のメトリクスを確認するとこのように1分おきでステータスがログされていますが、Offlineかどうかの検知は即座ではないようです。
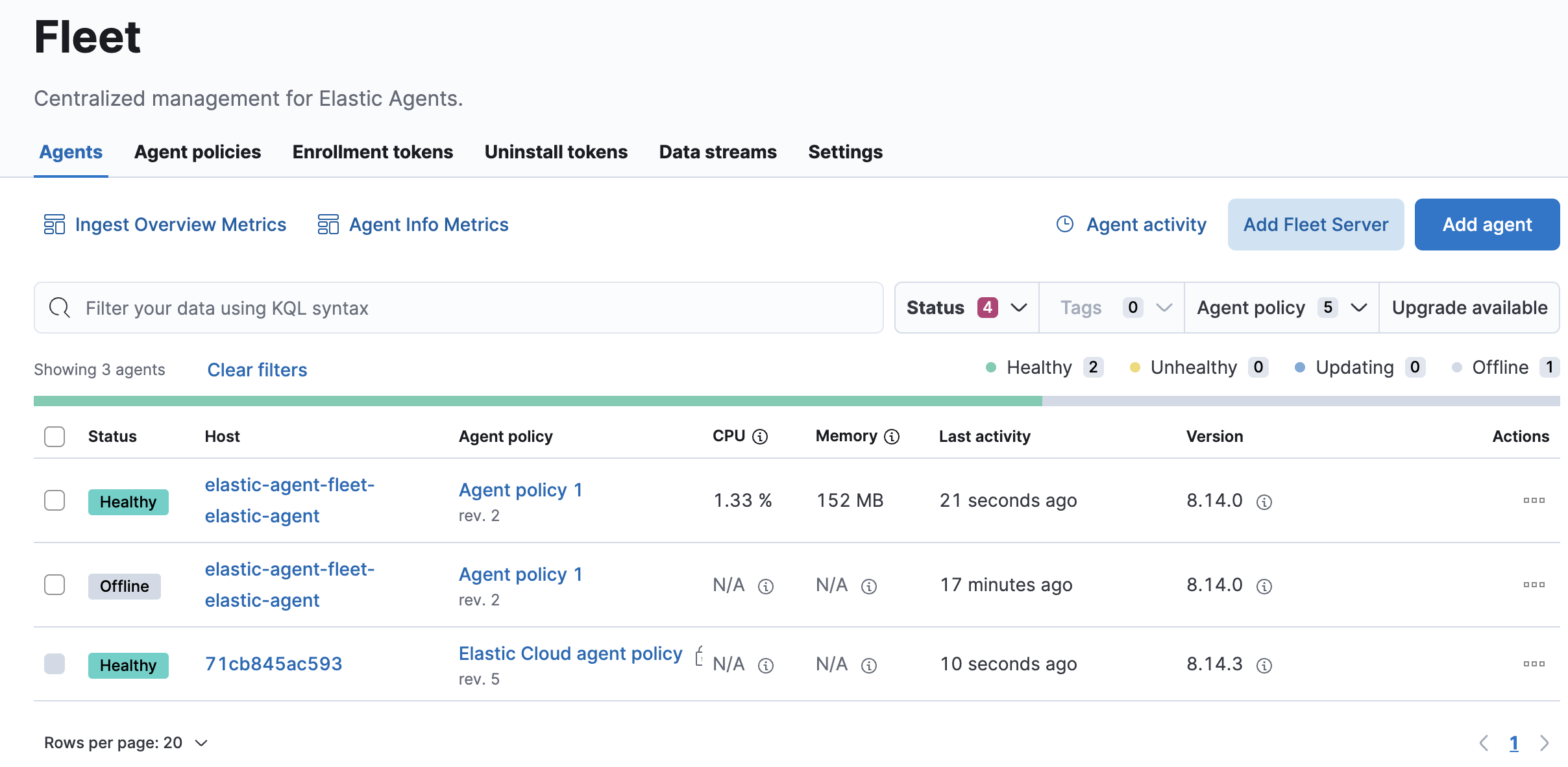
もう一つテストとして、Elastic Agentのシャットダウンをしました。時間は14:48です。アラートが上がったのは、14:54でした。
[補足]
コンテナ上で動いているElastic Agentは、揮発性ボリュームの上でシャットダウン後に新たなコンテナで起動すると、別のAgentとして認識され、Offlineは残ってしまいます。コンテナでElastic Agentを動かす際はそのインストールボリュームが永続するようにしておく必要があります。
Elastic Agentのメトリクスを使って細かく状態確認してみましょう
先ほどはAgentの状態監視でしたが、別の問題として集めるべきデータを全て集められているのか?というのも気になるところです。
それにはElastic Agentが発する稼働メトリクスを見て、データ収集状況を評価していくことになりますので、そちらを紹介します。
Fleetから特定のElastic Agentを選択して、下の画面のView more agent metricsでこのエージェントの稼働情報を確認します。
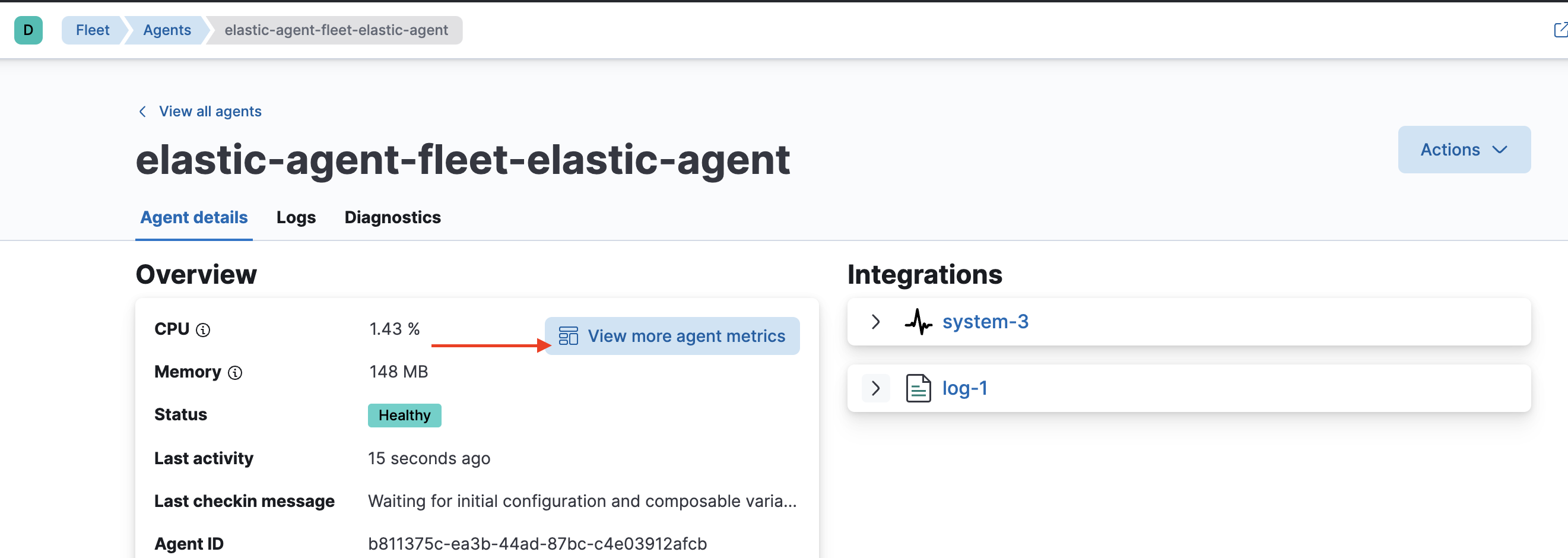
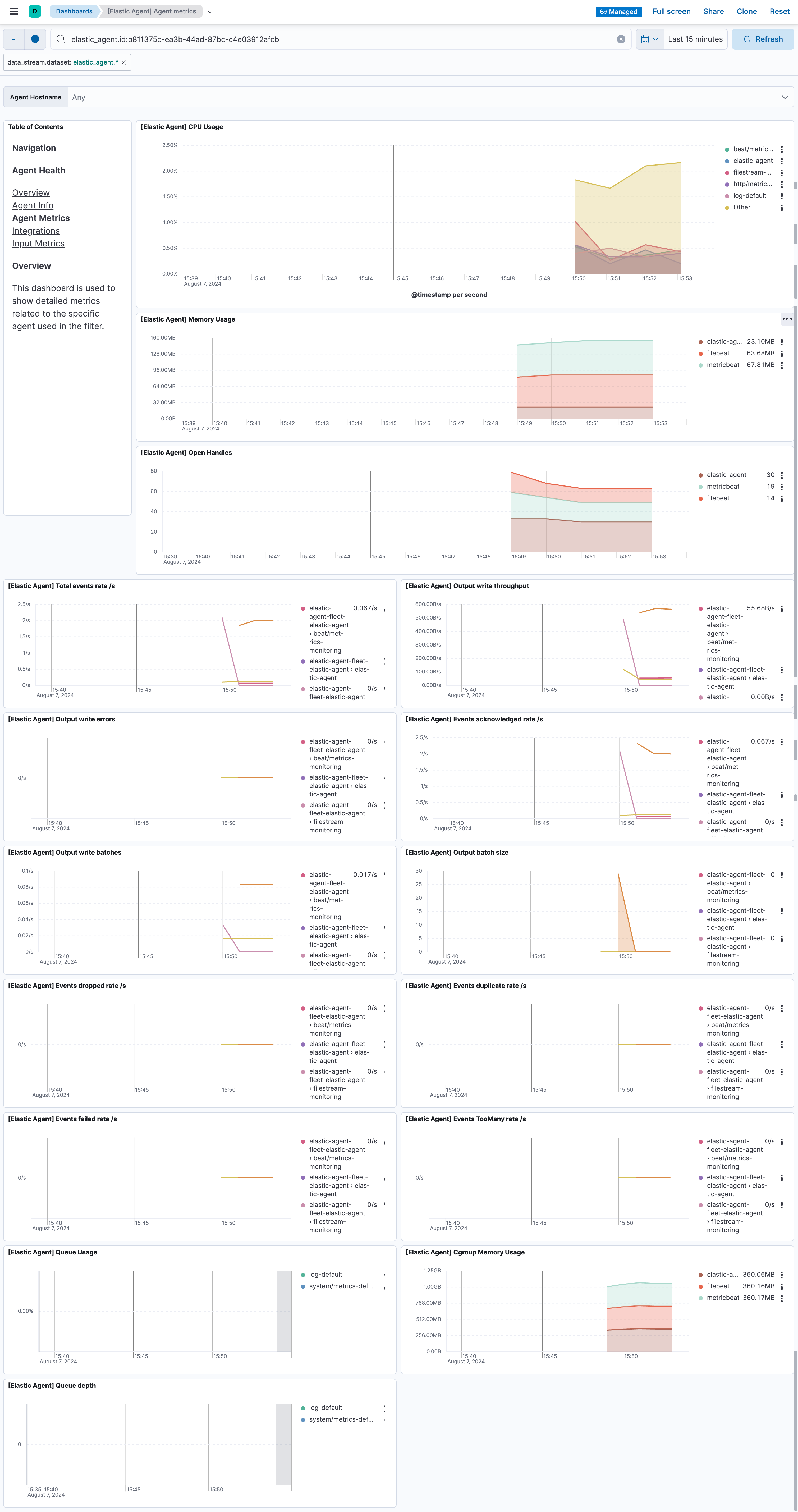
このように色々な情報が確認できますね。どれを見るべきかは後ほど...
ここで、Elastic Agentが動いているコンテナに入り、ログをファイルに書き込みます。今回のElastic Agentはこのログを収集するように設定されています。
このようにDiscoverではログが取れているのが見えています。
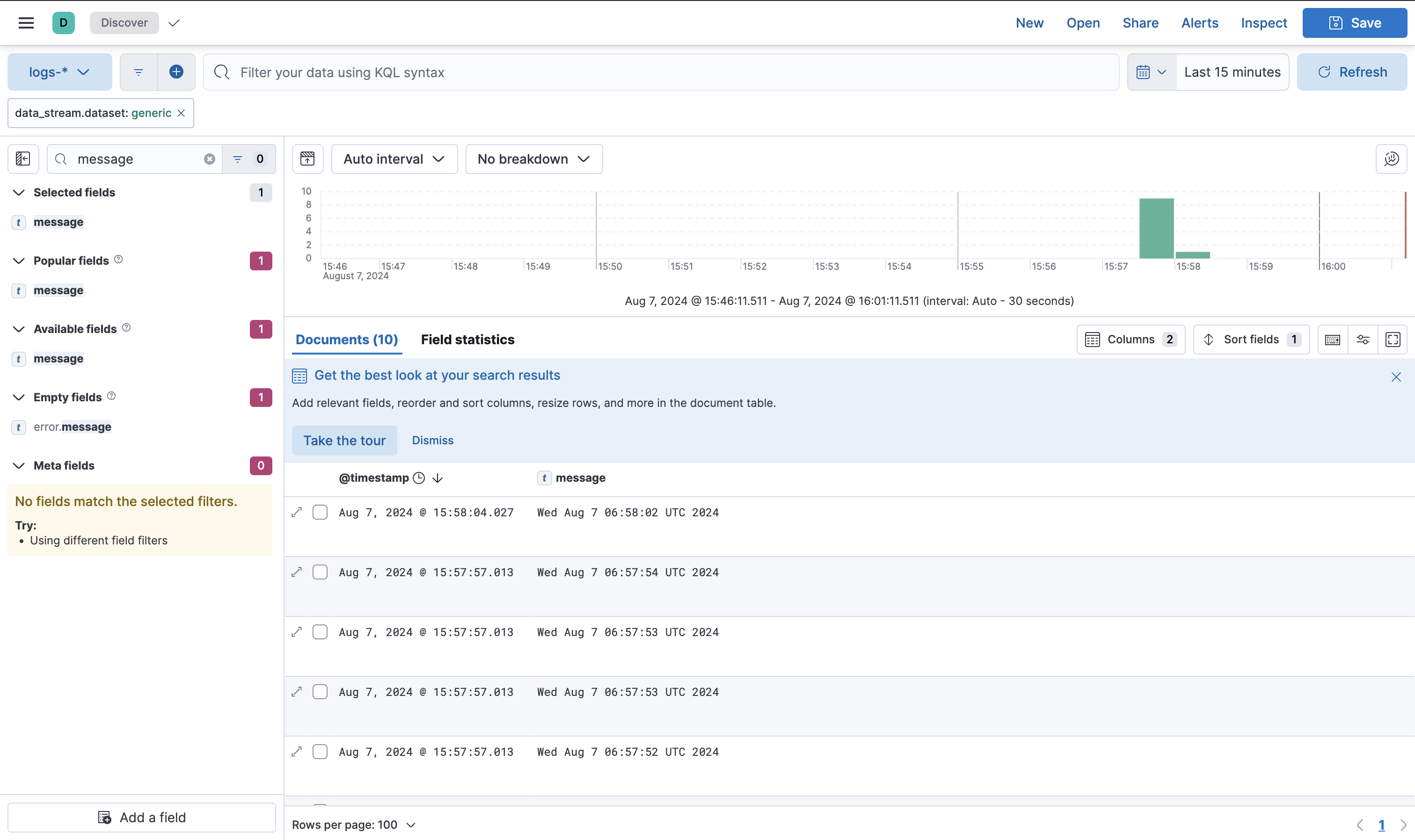
次に、無限ループでログ書き込みさせます。2件のログの書き込みと1秒のスリープをループして実行するようにしておきます。

Elastic AgentはAgentの稼働情報など、今回着目しているログの収集以外にも色々なデータを集めているため、フィルタリングしないと単一の収集の状況を可視化しづらいです。今回はcomponent.idでIntegrationの情報による絞り込みでフィルタかけました。これで今回のCustom Logsのログ収集状況だけ見ることができます。
このようにCustom Logsインテグレーションで集めているログに関する稼働情報が出ました。
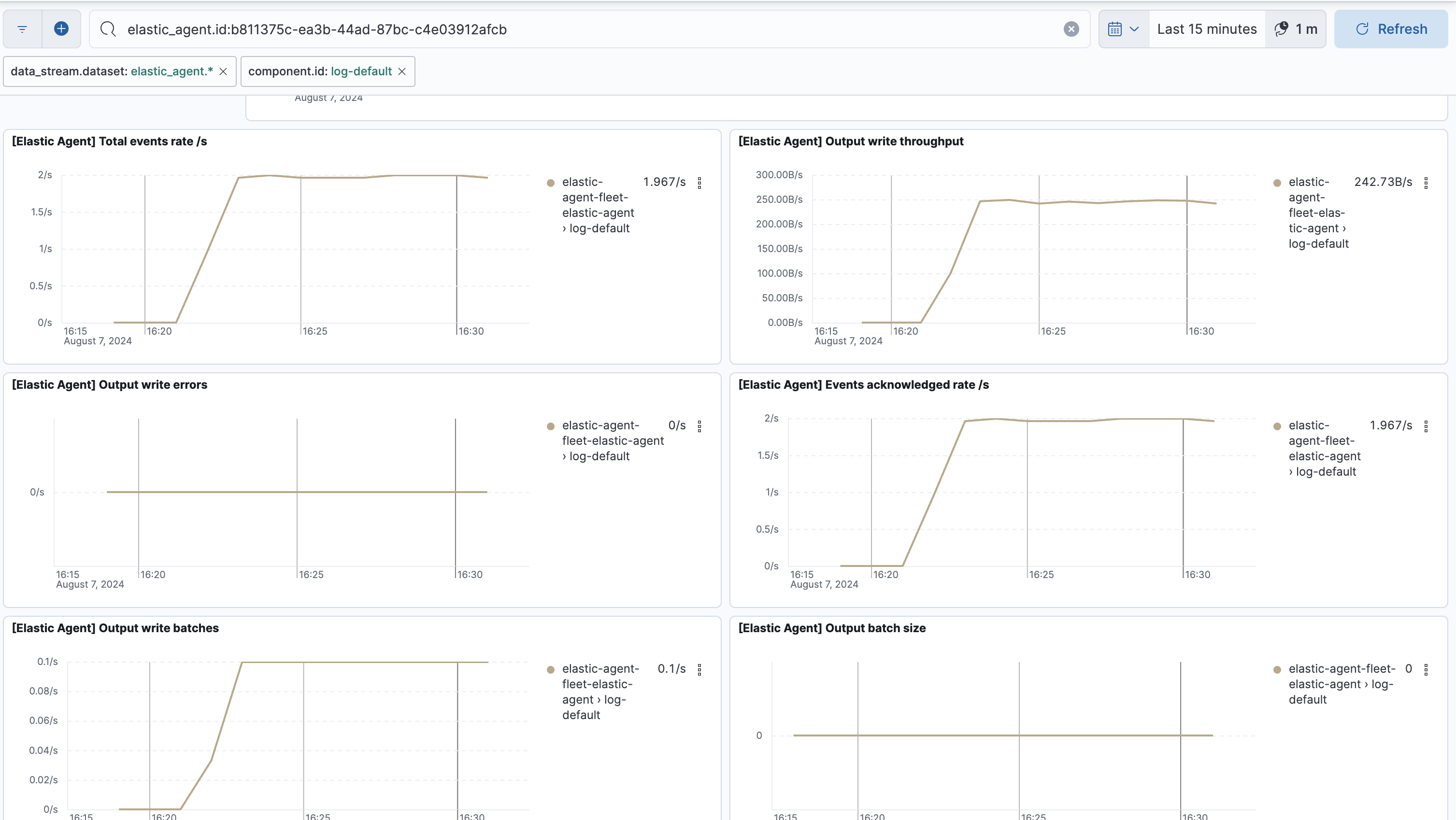
- [Elastic Agent] Total events rate/s ... Elasticsearchへのログの送信件数。2件/秒が検知されています。今回のログ書き込みのタイミングと一致しています。
- [Elastic Agent] Events acknowledged rate/s ... 送信されたログのうち、Elasticsearchが正常に受け取っている数。こちらも2件/秒。
- [Elastic Agent] Output write batches ... ログの送信はいくつかのイベントをまとめたバッチ毎に送信されるので、そのバッチの件数。0.1/秒ということで、10秒に1回のペースでログはElasticsearchにバッチ送信されています。queue.mem.flush.timeoutの値がデフォルト10sなので、仕様通りの送信間隔です。
この辺りのパラメータの詳細は以下のドキュメントで確認できます。
https://www.elastic.co/guide/en/beats/filebeat/current/understand-filebeat-logs.html
https://www.elastic.co/guide/en/beats/metricbeat/current/exported-fields-beat.html
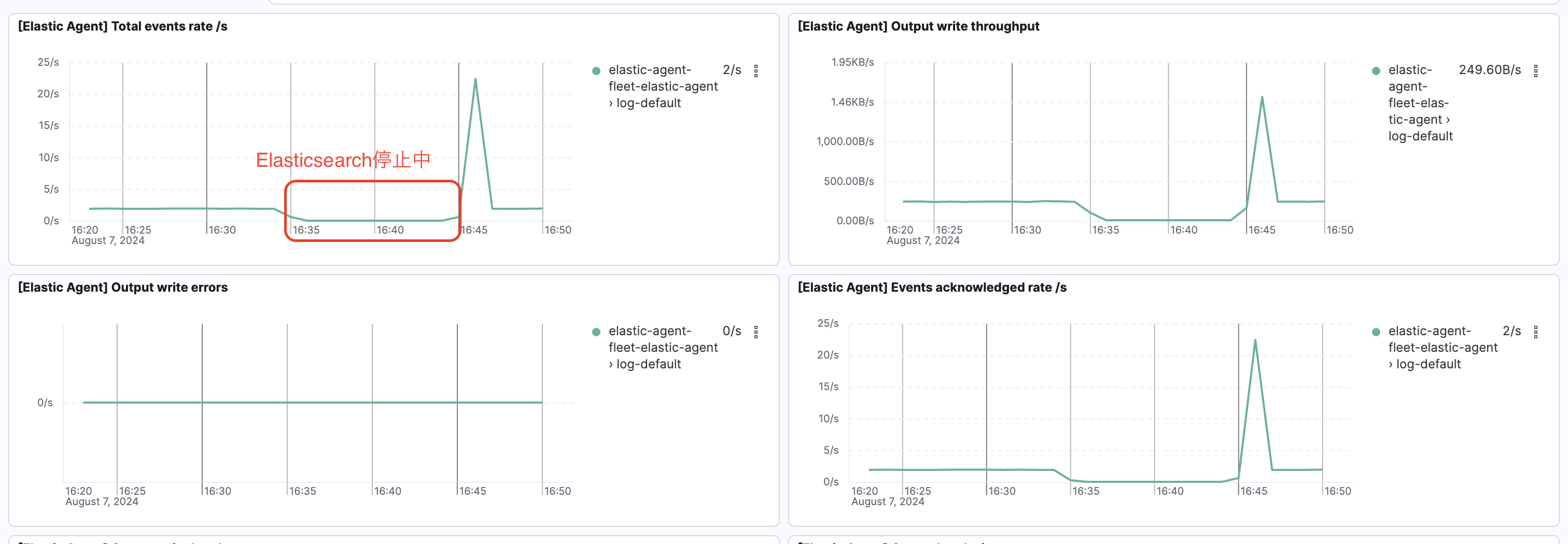
テスト: Elasticsearch側のイベント受信を停止してみる
Elastic CloudのElasticsearch側イベントの受信を停止してみました。

結果、受信停止期間はイベントの送信もゼロと出ています。
別途Integrationsのダッシュボード画面で、[Elastic Agent] Events per Integrationというのがありました。こちらはElasticsearchの受信停止期間中は凹んでいませんでした。
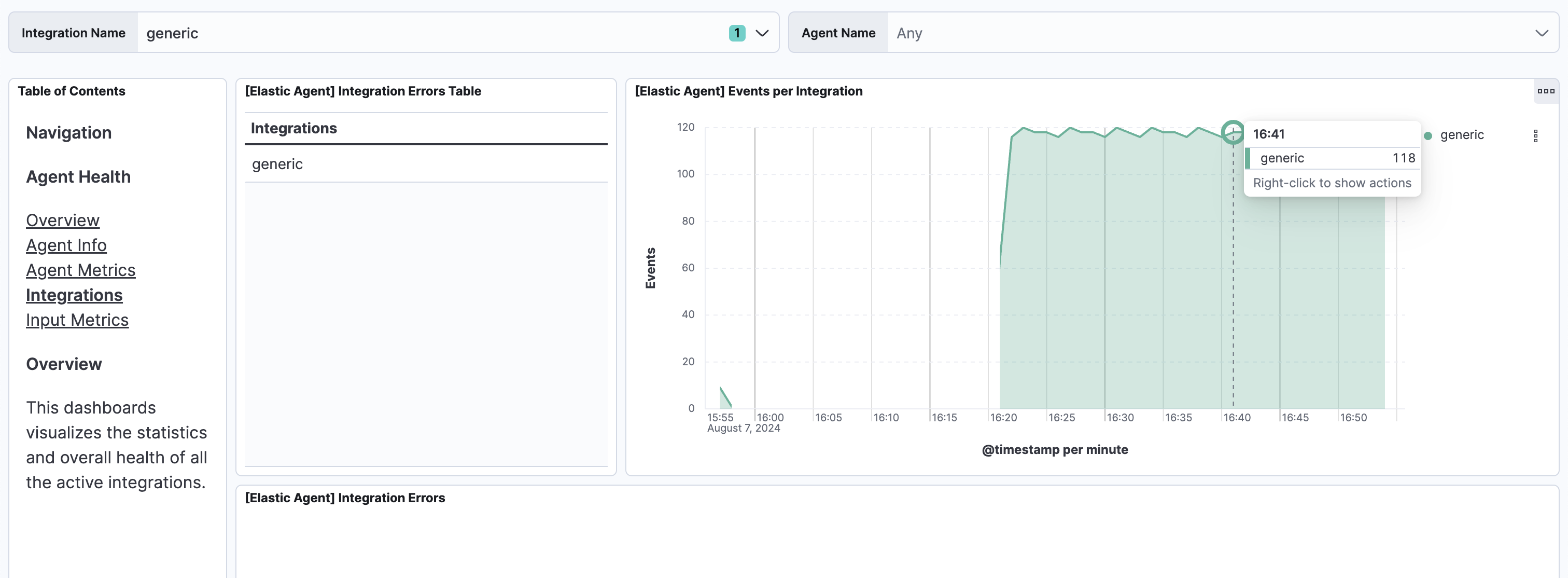
Discoverでこのデータの詳細を詳しく見ると、先どのデータの時間の元となる@timestampの値はログがファイルに書き込まれた時間を表しています。event.ingestedはElasticsearchがログを受信した時間で、Elasticsearchの受信を再開後に受信していることがわかります。
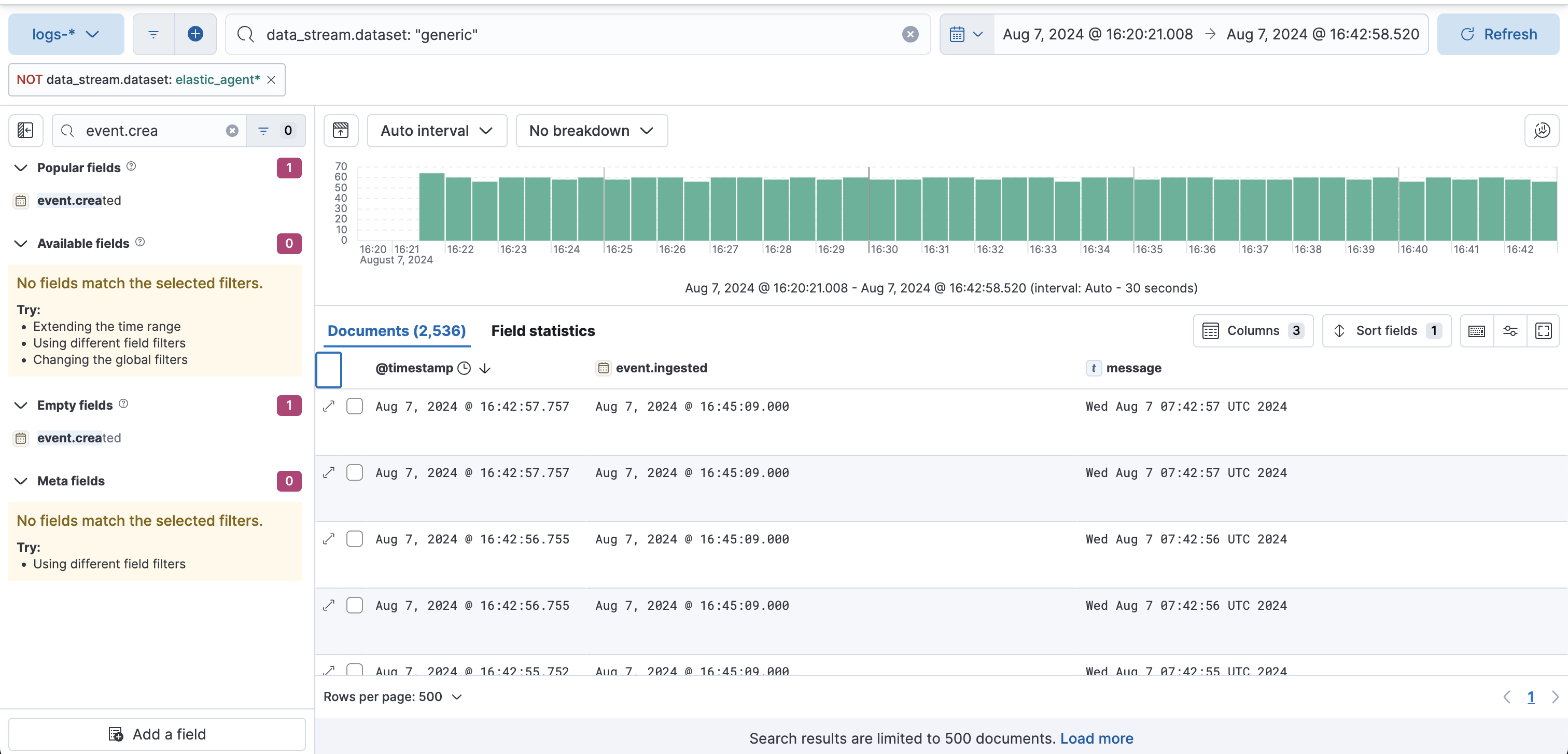
16:45にElasticsearchの受信を再開したところで、エージェント側で溜まっていたログを一気に受信したスパイクが見えますね。
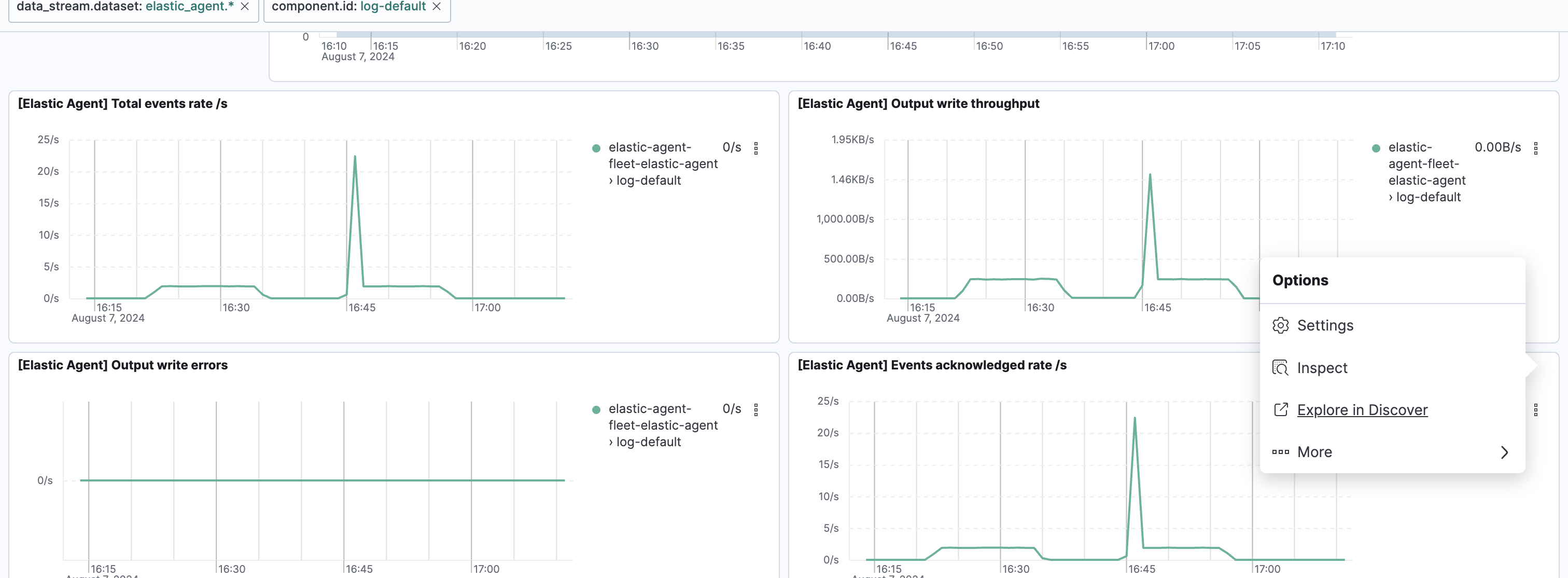
テスト: Elasticsearchでインジェスト時にエラーさせた場合
logs-generic@customという名前でIngest Pipelineを作ると、今回のCustom
Logインテグレーションに対するログの加工処理をElasticsearch側で定義できます。ここで、わざとエラーを起こす処理を入れてみます。
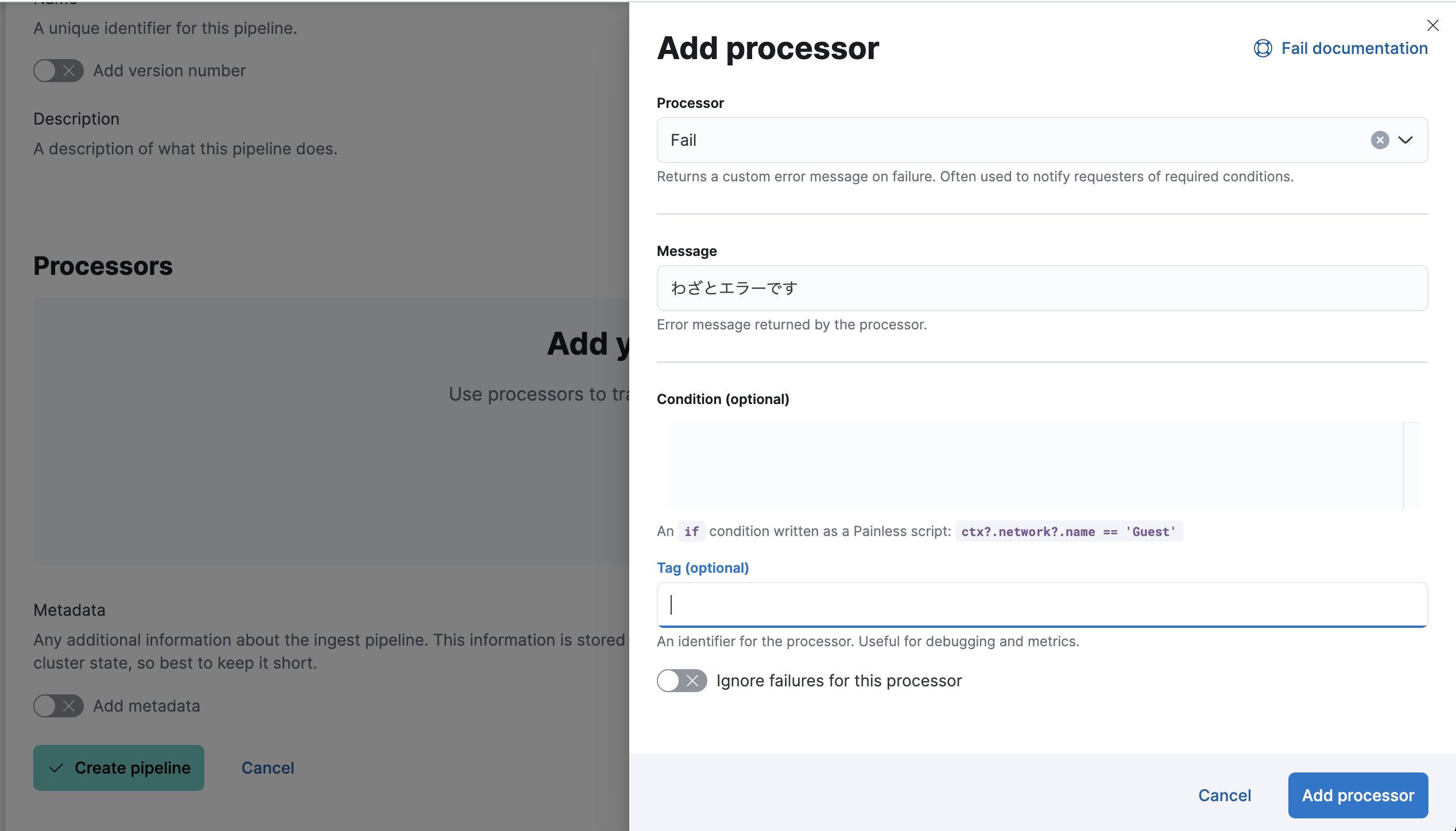
結果、この時のデータです。

- [Elastic Agent] Events failed rate/s ... Elasticsearchが受信でエラーを返していることがわかります。
- [Elastic Agent] Total events rate/sとOutput write batches ... エラー期間中も、エージェントからの送信が起こり続け、リトライの分、通常より送信も多いことがわかります。
- [Elastic Agent] Events acknowledged rate/s ... Elasticsearchが受信を正常に処理できた数です。エラー期間中はこの値がゼロになります。また、エラーからの復旧直後はエージェントからリトライされ続けていたイベントが受信されたため、スパイクがあるのがわかります。
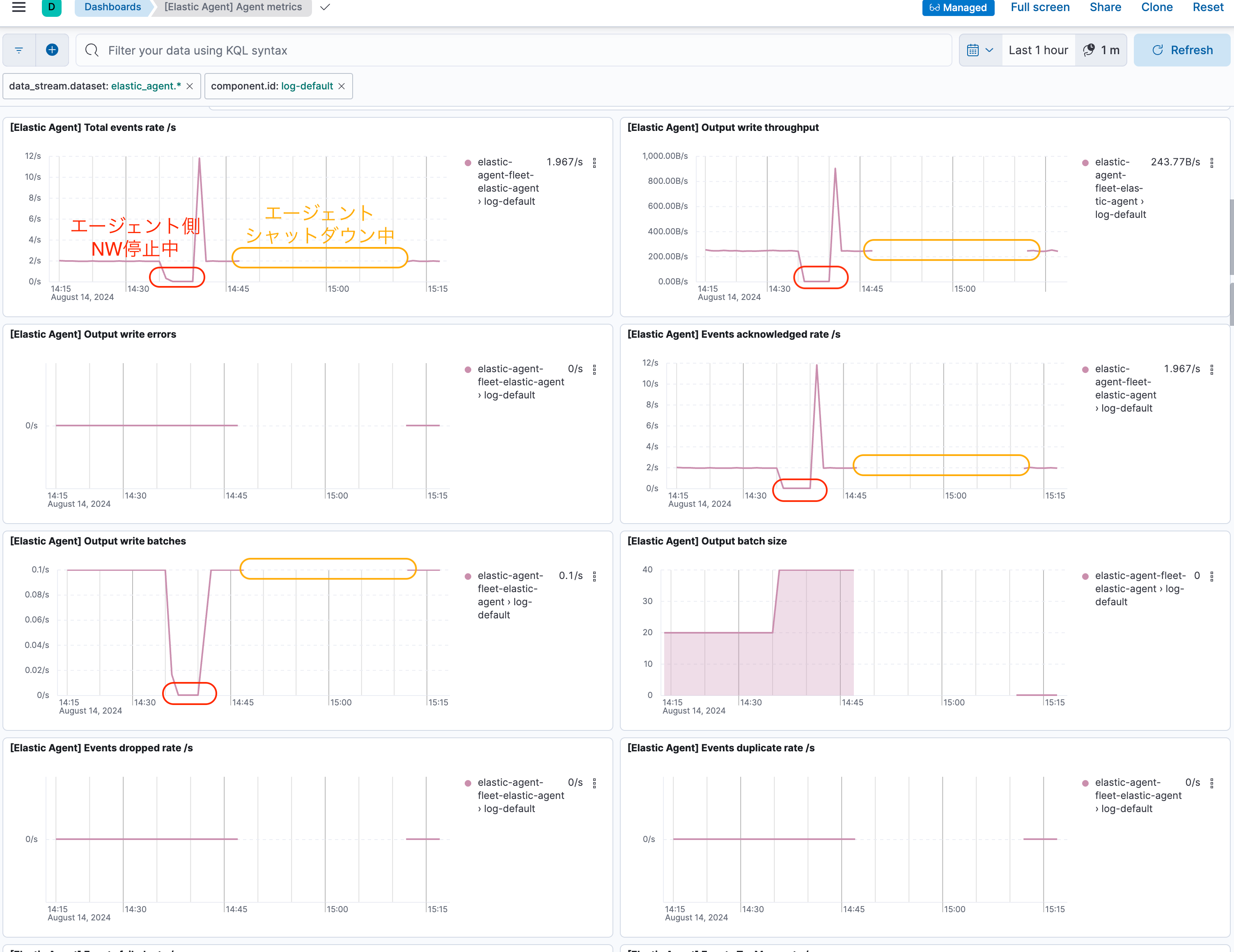
Elastic AgentがOfflineになった時のメトリクス状況
Offlineのアラート監視を仕掛けた時はアラート検知までに数分のラグが出ていましたが、メトリクスを確認すると正確にいつからログデータが上がって来なくなっていたかを確認できます。
Appendix
Input Metricsのダッシュボードでは、Input毎の数値というのが確認できますが、ここのFilestream Inputsは、今回のCustom Logsインテグレーションが使うInputのタイプとは違うので、この数値は使えません。では、何に使っているのかというと、Elastic Agent自身のログの収集に使われているため、1が立っています。いずれCustom Logsインテグレーションも内部で使用されるInputタイプがLog InputからFilestream Inputに移行されるはずなので、その時になったらここの数値も使えるはずです。
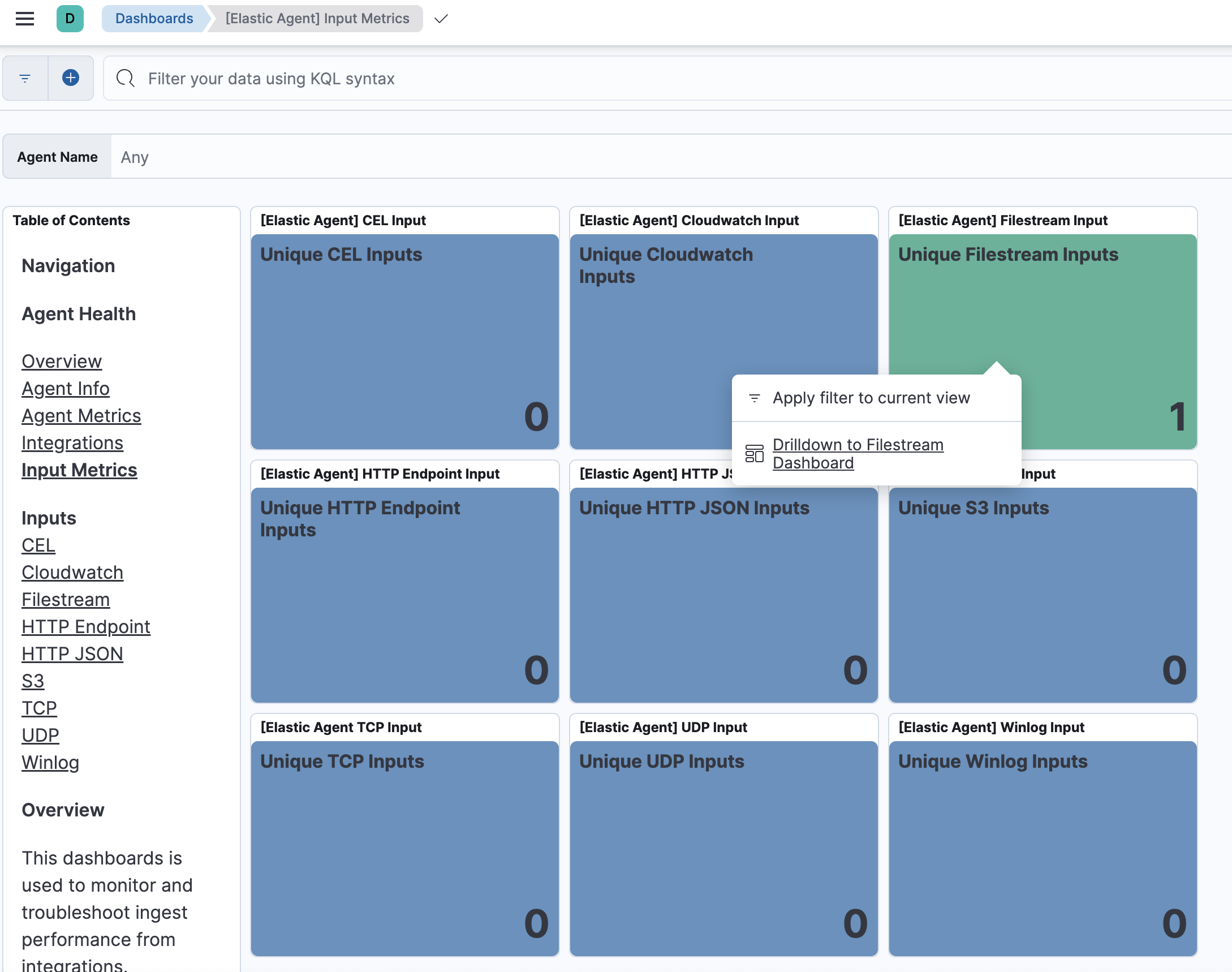
Input MetricsだとInput毎の稼働情報がこのように見やすいので助かるのですが。
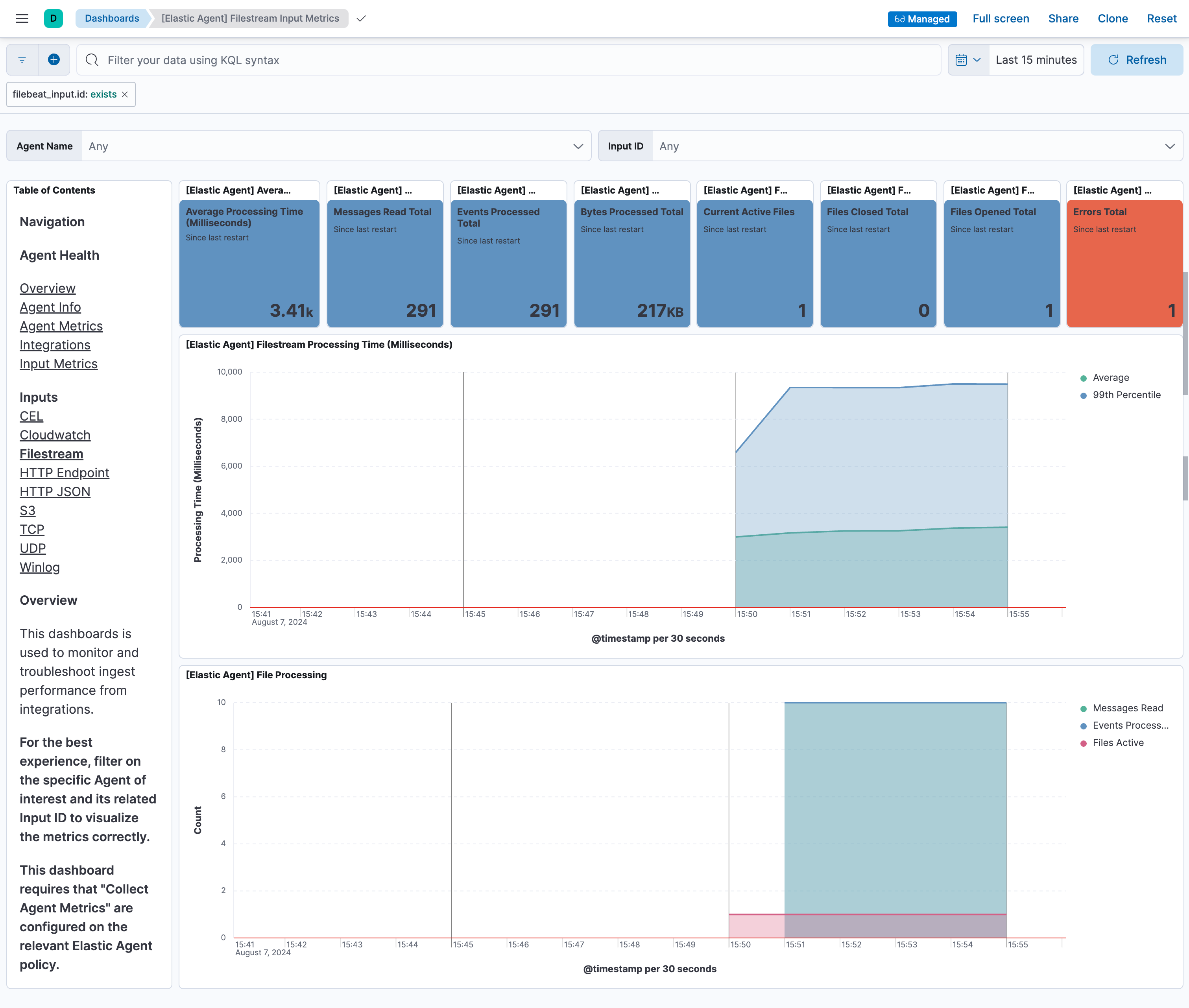
Input ID毎の絞り込みも簡単にできます。

おわり
ご紹介したようにElastic Agentの監視は、監視したい観点によっては、どのメトリクスをどう評価するかは様々な状況があり、一筋縄ではいきません。
まずはElatic Agentのステータスに対する監視を仕掛け、次のより細かい監視は一定期間の状態を確認してから、精度の良い監視ルールが作れそうかを見極めて設定していきましょう。
また、大前提として、本番クラスタは開発・検証クラスタとは別にしておき、ゴミデータのないクリーンな状態を保持することも重要です。