こんにちは!
私は、株式投資とプログラミングを勉強している35歳です。
今回、株価の周期性を利用したSARIMAモデルを活用して私が各財務指標上有力と見る(現状株式市場はかなりネガティブですが・・・)日本製鉄、日本マイクロニクスについて以下の事項の分析を行いました。
①過去約5年の各月の終値から2022年1月〜10月までの株価動向の予測と答え合わせ。
②これから2023年12月までの株価を予測。
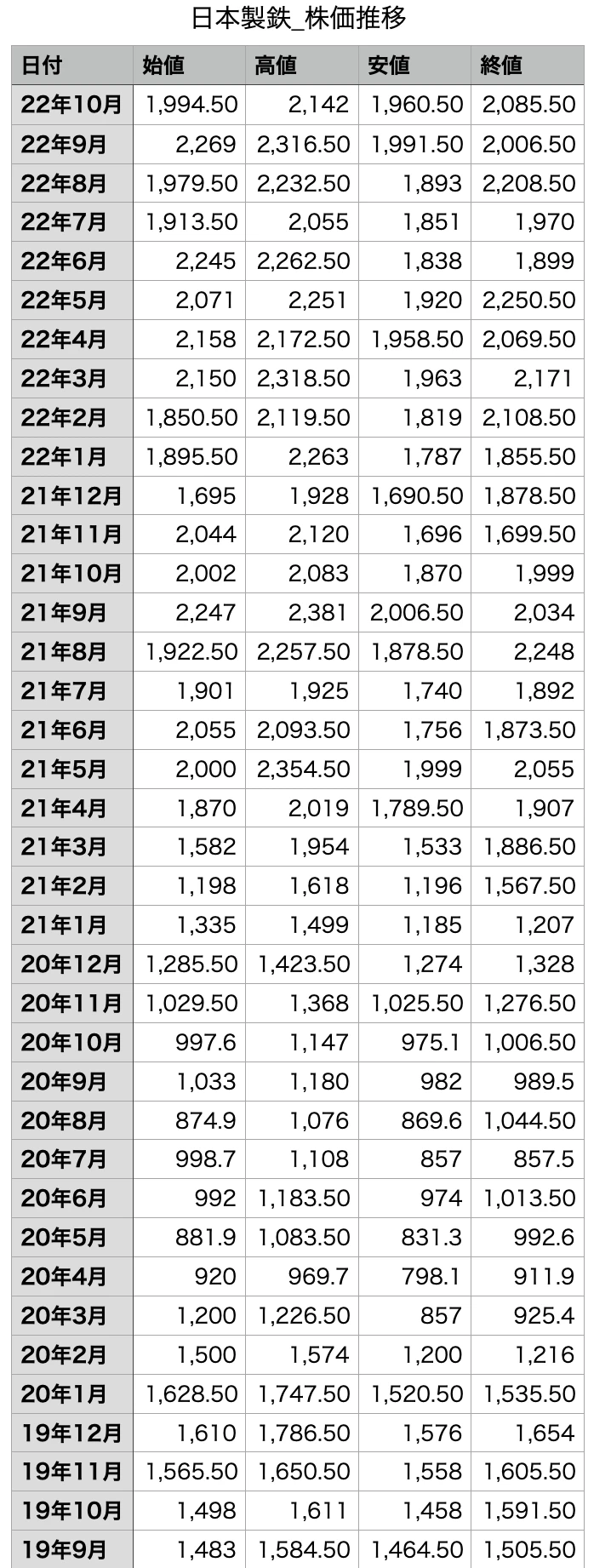
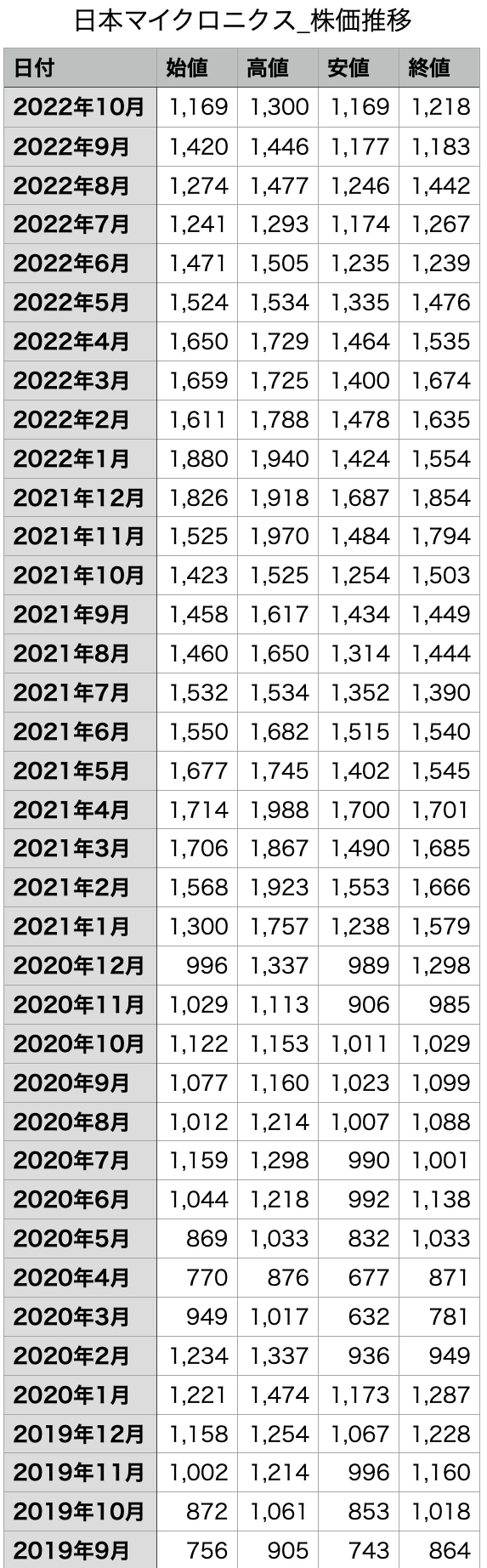
尚、両社の株価はY!ファイナンスのサイトから取得し、csvファイルに加工しました。
ファイルの内容はこのようなものです。
1.データの読み込み
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
stock_nittetu = pd.read_csv("/content/日本製鉄_株価推移.csv",encoding="shift_jis")
stock_micro = pd.read_csv("/content/日本マイクロニクス_株価推移.csv",encoding="shift_jis")
2.日付整備
日付をSARIMAモデルに適用させるため、「22年10月」という形になっているものを、「2022-10-1」という形に変換し、さらにそれをインデックス化、昇順に直します。
import datetime as dt
stock_nittetu["日付"]= pd.to_datetime(stock_nittetu["日付"],format="%y年%m月")
stock_micro["日付"]= pd.to_datetime(stock_micro["日付"],format="%Y年%m月")
#日付をdatetime型に変換
#尚、練習のために、敢えて元データの日付を日本製鉄の方は「22年10月」として、変換時"%y年%m月"というようにyを小文字に、日本マイクロニクスの方は「2022年10月」として、変換時"%Y年%m月")というようにYを大文字にしている。
stock_nittetu=stock_nittetu.set_index("日付")
stock_micro=stock_micro.set_index("日付")
#datetime型にした日付をインデックス化
stock_nittetu=stock_nittetu.sort_index()
stock_micro=stock_micro.sort_index()
#降順に並んでいるデータを昇順に変換
3.終値の取得とDataFrame型への変換
#データには「始値」「高値」「安値」「終値」の4種類があるため、ここでは終値ベースで予測。
stock_nittetu_end = stock_nittetu.loc[:,"終値"]
stock_nittetu_end = pd.DataFrame(stock_nittetu_end)
stock_micro_end = stock_micro.loc[:,"終値"]
stock_micro_end = pd.DataFrame(stock_micro_end)
4.データ数値の整備
stock_nittetu_end=stock_nittetu_end.replace(",","",regex=True)
stock_micro_end=stock_micro_end.replace(",","",regex=True)
#各数値の千円単位のカンマを消す
stock_nittetu_end["終値"]=stock_nittetu_end["終値"].astype(float)
stock_micro_end["終値"]=stock_micro_end["終値"].astype(float)
#float型に変換
5.パラメーターの最適化
PythonにはSARIMAモデルのパラメーター、(p, d, q) (sp, sd, sq, s)を自動で最も適切にしてくれる機能がないため、情報量規準(今回の場合は BIC(ベイズ情報量基準))によってどの値が最も適切なのか調べるプログラムを書く。
#各パラメーターがそれぞれ、0〜2の場合についてのSARIMAモデルのBICを計算し、最もBICが小さくなった場合を表示。
#BICの場合は この値が低ければ低いほどパラメーターの値は適切であるため。
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
print("error")
continue
return parameters[np.argmin(BICs)]
best_params_nittetu = selectparameter(stock_nittetu_end, 12)
best_params_micro = selectparameter(stock_micro_end, 12)
#年毎の周期を確認したので、周期は12とする
6.SARIMAモデルを用いた予測
SARIMA_stock_nittetu = sm.tsa.statespace.SARIMAX(stock_nittetu_end, order=best_params[0], seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()
SARIMA_stock_micro = sm.tsa.statespace.SARIMAX(stock_micro_end, order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()
#predに予測データを代入する(2022年10月から2023年9月の株価を予測)。
pred = SARIMA_stock_nittetu.predict('2022-1', '2023-12')
pred = SARIMA_stock_micro.predict('2022-1', '2023-12')
#predデータの可視化
plt.plot(stock_nittetu_end)
plt.plot(pred, "r")
plt.show()
plt.plot(stock_micro_end)
plt.plot(pred, "r")
plt.show()
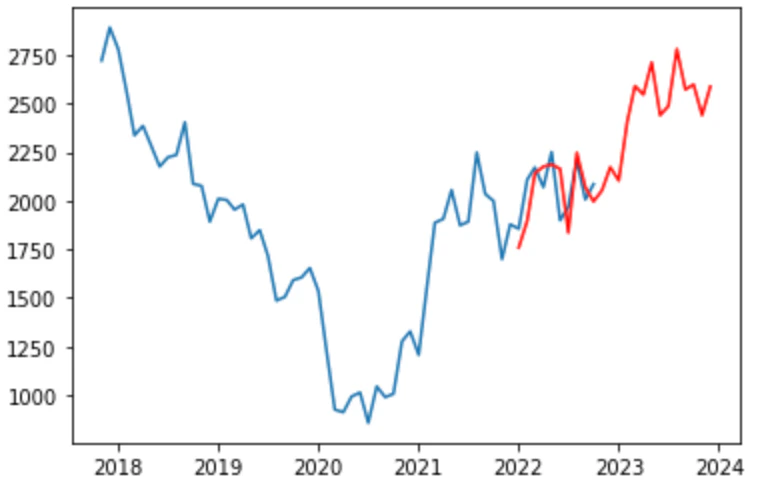
<日本製鐵_株価予測>
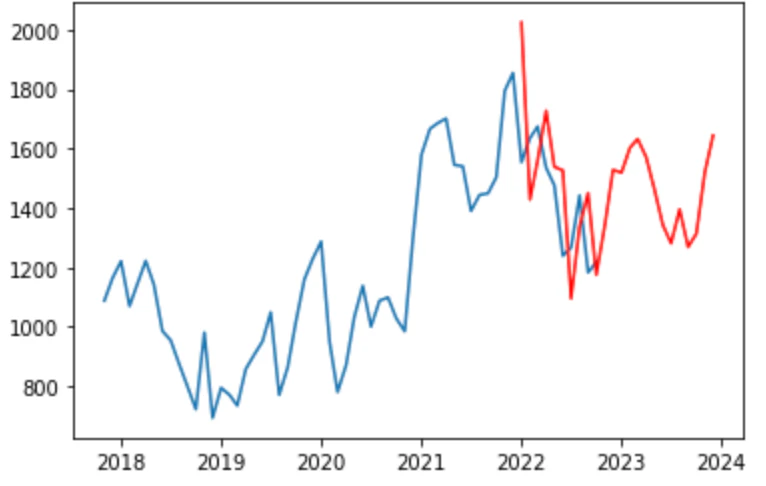
<日本マイクロニクス_株価予測>
7.結果と予測精度について
①いずれの株価も、2022年1月から2022年10月までは実際の株価推移(青グラフ)と類似した動きを予測(赤グラフ)しており、まずまずの予測精度であることがわかる。
傾向としては、予測の方が若干後追いした動きになっている。
②これから2023年いっぱいの動きは、日本製鉄については上昇傾向、日本マイクロニクスについては動きはありながらも横ばいと予測している。
今回は周期性を活用して株価予測を行った。いずれの株価も2022年1月から2022年10月までの動きは概ね合致しており、とても驚いた。
しかし今後については、特に日本製鉄の株価は昨今アメリカの景気後退懸念から株価がこのように素直に上がるとも思えない。
そのため、今後は感情分析も織り交ぜた株価分析を行なっていきたい!