はじめに
IBM Cloud Pak for Data as a Service(以下CP4DaaS)のNotebookから機械学習モデルを作成・管理することを想定します。データ加工、モデル作成の処理は別々のNotebookを作成し、それらをMLOpsのパイプラインで連携して実行する処理を踏まえて開発します。この場合、学習データや作成したモデルなど入出力ファイルが登場しますが、MLOpsの観点では、それらのファイルが意図した場所に保管され、複数のNotebookによる処理から参照可能な状態でバージョン管理される必要があります。そのようなファイルの管理を通して、機械学習の実験の再現性やトレーサビリティが担保されるようになるためです。
この記事では、このようなMLOpsの要件を踏まえて、Notebookが処理するデータ入出力を整理します。ここで想定する処理は以下の通りです。
【処理のポイント】
・Notebookはデータ加工とモデル作成の2つ
・1~12の処理はパイプラインを使って自動化が可能。
・1~12の処理のうち、この例ではNotebookからは2~11が実行される。その間にデータ加工・モデル作成と保存が実行される。
・加工済みファイルの実態はIBM Cloud Object Storage(以下COS)に保管されるが、明示的にはCP4DaaSのデプロイメントスペース上で管理される。
・Notebookは別々だが、デプロイメントスペースを介して入出力データを一元管理する。

前提
Notebookを実行するための準備として、IBM CloudのGUI画面から以下の設定をします。
- IBM Cloud API Keyを作成
- Watson Studioでプロジェクトを作成(例:Telco_Customer_Churn)
- Watson Studioでデプロイメントスペースを作成(例:pipelines_deployment_space)
- IBM CloudObjectStorageの任意のバケットを作成(例:pipeline-bucket1)
- デプロイメントスペースにバケットの接続を定義(例:pipeline-bucket11-connection)
- 以下のデータセットを分析対象データとして取り扱います。これをデプロイメントスペースに資産として登録しておきます。
- ファイル名:Telco_Customer_Churn.csv
- ファイル形式:csv
Notebookの書き方
セットアップ
1. 環境/資格情報の登録
はじめに環境情報と資格情報を設定します。
# credential情報、idの登録
CLOUD_API_KEY = "<IBM Cloud API Keyを記載>"
IAM_URL="https://iam.ng.bluemix.net/oidc/token"
SPACE_ID = '<デプロイメントスペースのGUID。CP4DaaSのGUIからデプロイメントスペースを開き、「管理」タブに表示された"Space GUID">'
IBM CloudObjectStorageの情報も登録します。
COS_API_KEY_ID = "<IBM CloudObjectStorageの「サービス資格情報」のapikey>"
COS_RESOURCE_CRN = "<IBM CloudObjectStorageの「サービス資格情報」のresource_instance_id>"
COS_ENDPOINT = "https://s3.direct.us-south.cloud-object-storage.appdomain.cloud" #icosの画面でバケット>対象のバケットを選択し、「構成」で「エンドポイント」の「ダイレクト」にあるURL
BUCKET_NAME = "pipeline-bucket11"
データ・ファイル等、今回使う変数名を定義します。
DATA_FILE_NAME="Telco_Customer_Churn.csv"
PROCESSED_TRAINING_DATA_FILE_NAME="Telco_Customer_Churn_Processed_Train.csv"
PROCESSED_TEST_DATA_FILE_NAME="Telco_Customer_Churn_Processed_Test.csv"
MODEL_NAME = 'telco_churn_model'
2. 前提のインストールとインポート
※pip install処理は、今回はNotebookのコードで記載する。ただし、導入済みの「環境」を用意することで省略可能。
!pip install -U ibm-watson-machine-learning | tail -n 1
!pip install -U ibm-watson-studio-pipelines| tail -n 1
必要なインポート処理を実行。
import os, json
import numpy as np
import pandas as pd
import warnings
from ibm_watson_machine_learning import APIClient
warnings.filterwarnings('ignore')
3. Watson Machine LearningのAPIを使うための共通処理
ファイル入出力には、主にWatson Machine LearningのAPIを使います。
Watson Machine Learningのクレデンシャル情報。上記のIBM Cloud API Keyを使います。
WML_CREDENTIALS = {
"url": "https://us-south.ml.cloud.ibm.com",
"apikey": CLOUD_API_KEY
}
Watson Machine Learning クライアントの準備をします。
wml_client = APIClient(WML_CREDENTIALS)
wml_client.set.default_space(SPACE_ID)
4. 入力ファイルの資産ID取得
「前提」でデプロイメントスペースに資産として保管した入力ファイル(CSV)をNotebookから使えるようにするために、資産IDを取得します。
wml_client.data_assets.list()
該当するものをasset_idとして登録します
asset_id = '<ひとつ前の手順で取得したデータ資産のIDを記載>'
データ入出力
Notebookで機械学習モデル作成のために必要となりそうなデータの入出力処理パターンとして以下を取り上げます。

- 入力データをPandasのデータフレームに格納
- 加工済みデータをcsvファイルとしてIBM CloudObjectStorageとデプロイメントスペースに保管
- 学習データとテストデータをデプロイメントスペースから取得してPandasのデータフレームに格納
- モデルを作成してデプロイメントスペースの資産に登録
1. Notebook1で入力データをPandasのデータフレームに格納
「前提」でデプロイメントスペースに資産として保管し、「セットアップ4.」で資産IDを取得した入力ファイル(CSV)を、Pandasのデータフレームに格納します。
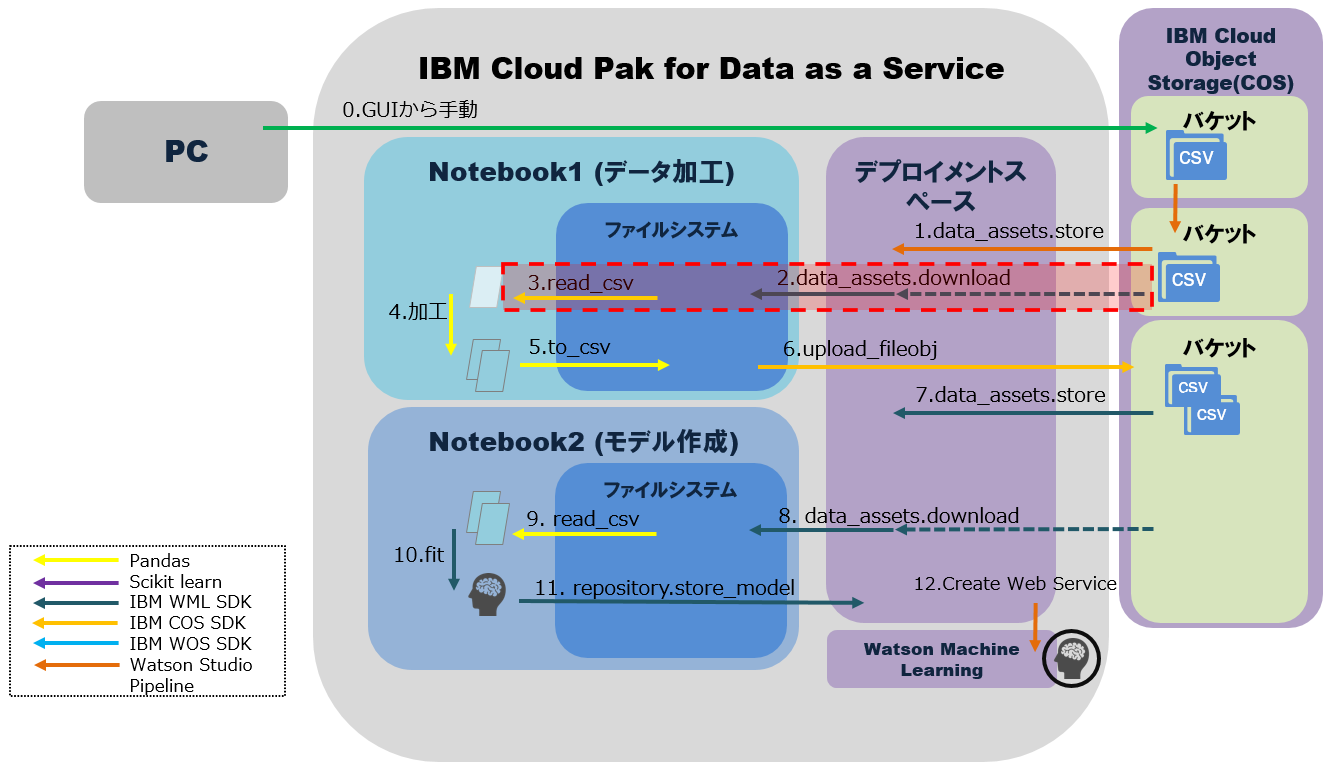
DATA_FILE_NAME='Telco_Customer_Churn.csv'
wml_client.data_assets.download(asset_uid=asset_id, filename=DATA_FILE_NAME)
df = pd.read_csv(DATA_FILE_NAME)
2. Notebook1で加工したデータをcsvファイルとしてIBM CloudObjectStorageとデプロイメントスペースに保管
データはIBM CloudObjectStorageに保存され、デプロイメントスペースからそれを参照します。

import ibm_boto3
from ibm_botocore.client import Config, ClientError
cos_client = ibm_boto3.resource("s3",
ibm_api_key_id=COS_API_KEY_ID,
ibm_service_instance_id=COS_RESOURCE_CRN,
ibm_auth_endpoint="https://iam.bluemix.net/oidc/token",
config=Config(signature_version="oauth"),
endpoint_url=COS_ENDPOINT
)
学習データ、テストデータが格納されたデータフレームである"train"と"test"を、それぞれcsvにエクスポート
train.to_csv(PROCESSED_TRAINING_DATA_FILE_NAME,index=False)
test.to_csv(PROCESSED_TEST_DATA_FILE_NAME,index=False)
エクスポートしたcsvファイルをIBM CloudObjectStorageにアップロード
with open(PROCESSED_TRAINING_DATA_FILE_NAME, "rb") as file_data:
cos_client.Object(BUCKET_NAME, PROCESSED_TRAINING_DATA_FILE_NAME).upload_fileobj(
Fileobj=file_data
)
with open(PROCESSED_TEST_DATA_FILE_NAME, "rb") as file_data:
cos_client.Object(BUCKET_NAME, PROCESSED_TEST_DATA_FILE_NAME).upload_fileobj(
Fileobj=file_data
)
以下のコマンドを使って「接続」(例:pipeline-bucket11-connection)の資産IDを取得。
wml_client.connections.list()
取得した「接続」(pipeline-bucket11-connection)の資産IDを指定して、csvファイルをIBM CloudObjectStorageからデプロイメントスペースにコピー
metadata = {
wml_client.data_assets.ConfigurationMetaNames.NAME: 'Telco_Customer_Churn_Processed_Train',
wml_client.data_assets.ConfigurationMetaNames.DESCRIPTION: 'sample description',
wml_client.data_assets.ConfigurationMetaNames.CONNECTION_ID: '<上記「接続」の資産ID>',
wml_client.data_assets.ConfigurationMetaNames.DATA_CONTENT_NAME: '/pipeline-bucket11/Telco_Customer_Churn_Processed_Train.csv'
}
asset_details = wml_client.data_assets.store(meta_props=metadata)
metadata = {
wml_client.data_assets.ConfigurationMetaNames.NAME: 'Telco_Customer_Churn_Processed_Test',
wml_client.data_assets.ConfigurationMetaNames.DESCRIPTION: 'sample description',
wml_client.data_assets.ConfigurationMetaNames.CONNECTION_ID: '<上記「接続」の資産ID>',
wml_client.data_assets.ConfigurationMetaNames.DATA_CONTENT_NAME: '/pipeline-bucket11/Telco_Customer_Churn_Processed_Test.csv'
}
asset_details = wml_client.data_assets.store(meta_props=metadata)
3. Notebook2でモデル作成に使う学習データとテストデータをデプロイメントスペースから取得してPandasのデータフレームに格納
以下のコマンドを使って「接続」(Telco_Customer_Churn_Processed_Train, Telco_Customer_Churn_Processed_Test)の資産IDを取得。
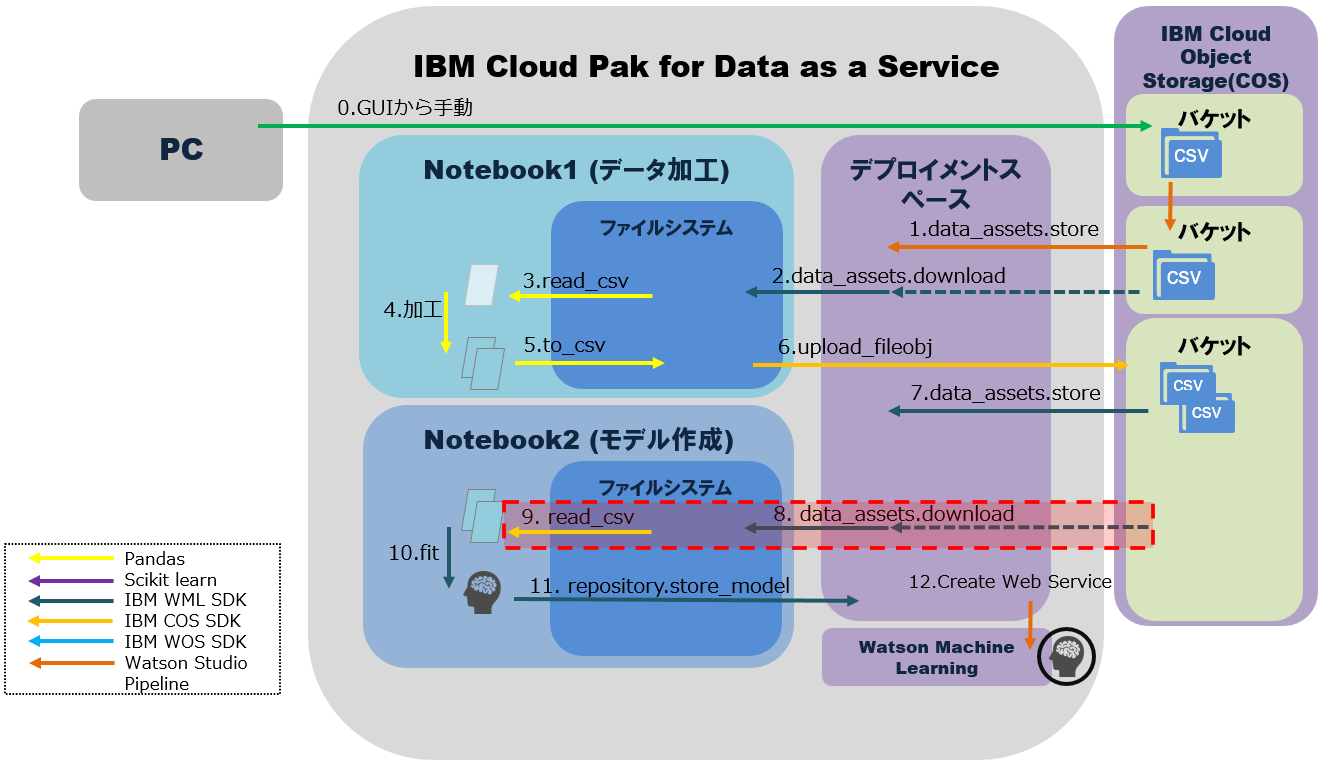
wml_client.connections.list()
取得した「接続」の資産IDを指定して、変数定義。
asset_id_train = '<上記接続"Telco_Customer_Churn_Processed_Train"の資産ID>'
asset_id_test = '<上記接続"Telco_Customer_Churn_Processed_Test"の資産ID>'
デプロイメントスペースの資産を指定して、学習データとテストデータのパスを取得。
PROCESSED_TRAINING_DATA_FILE_NAME="Telco_Customer_Churn_Processed_Train.csv"
PROCESSED_TEST_DATA_FILE_NAME="Telco_Customer_Churn_Processed_Test.csv"
TRAINING_DATA_ASSET_CPD_PATH = 'cpd:///spaces/{}/assets/{}'.format(SPACE_ID, asset_id_train)
TEST_DATA_ASSET_CPD_PATH = 'cpd:///spaces/{}/assets/{}'.format(SPACE_ID, asset_id_test)
デプロイメントスペースから学習データとテストデータをダウンロード。
wml_client.data_assets.download(asset_uid=asset_id_train, filename=PROCESSED_TRAINING_DATA_FILE_NAME)
wml_client.data_assets.download(asset_uid=asset_id_test, filename=PROCESSED_TEST_DATA_FILE_NAME)
学習データとテストデータをデータフレーム"train", "test"に格納。
train = pd.read_csv(PROCESSED_TRAINING_DATA_FILE_NAME)
test = pd.read_csv(PROCESSED_TEST_DATA_FILE_NAME)
4. Notebook2でモデルを作成してデプロイメントスペースの資産に登録
機械学習のモデル作成用にデータ分割をする(X:説明変数、y:目的変数)。ここで、CHURNは目的変数の名前。
y_train = train.pop('CHURN')
X_train = train
y_test = test.pop('CHURN')
X_test = test
scikit-learnのRandom Forestを使って、モデルを作成。モデル名は model_class。
from sklearn.ensemble import RandomForestClassifier
model_class = RandomForestClassifier(n_estimators=10, max_depth=12)
model_class.fit(X_train, y_train)
モデルをプロジェクトに登録し、デプロイメントスペースの資産に保管。
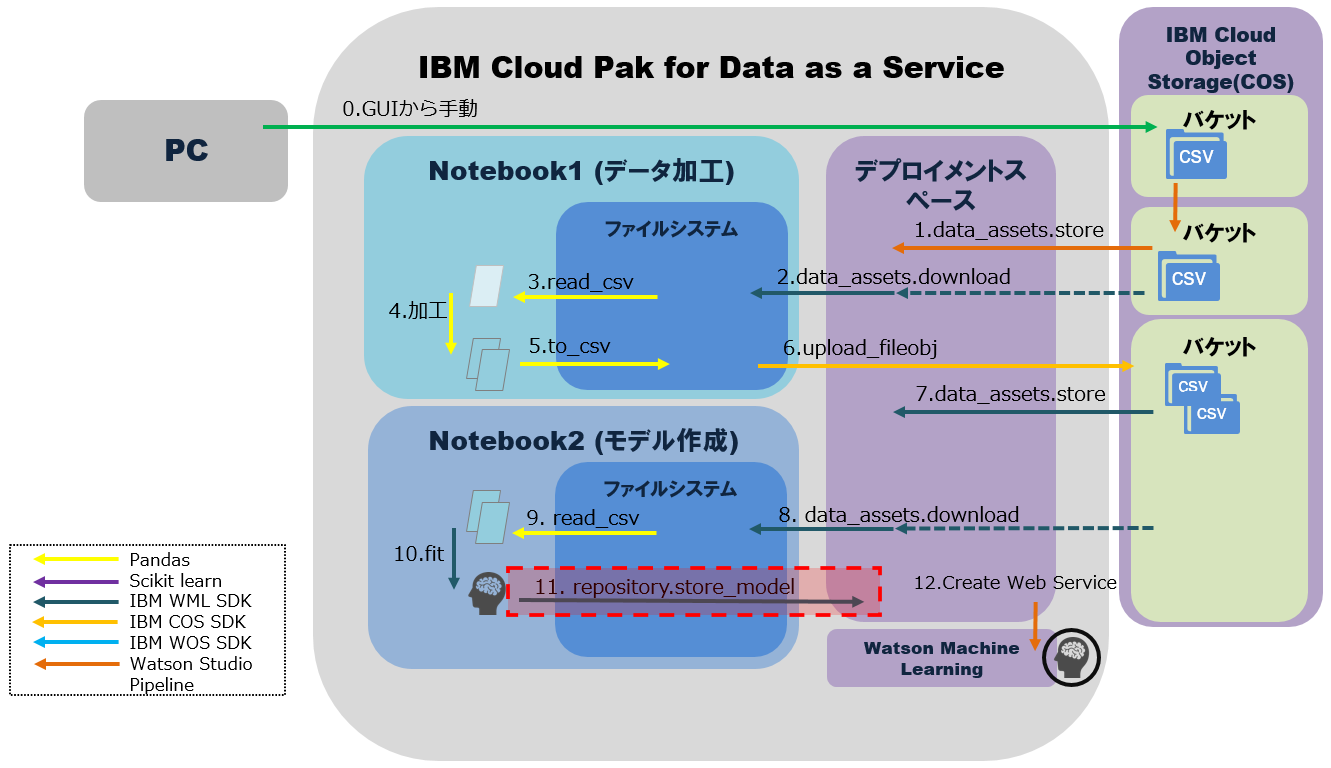
models = wml_client.repository.get_model_details()['resources']
model_id = next((m['metadata']['id'] for m in models if m['metadata']['name'] == MODEL_NAME), None)
software_spec_uid = wml_client.software_specifications.get_id_by_name("default_py3.7_opence")
print("Software Specification ID: {}".format(software_spec_uid))
model_props = {
wml_client._models.ConfigurationMetaNames.NAME:"{}".format(MODEL_NAME),
wml_client._models.ConfigurationMetaNames.TYPE: "scikit-learn_0.23",
wml_client._models.ConfigurationMetaNames.SOFTWARE_SPEC_UID: software_spec_uid,
wml_client._models.ConfigurationMetaNames.LABEL_FIELD: "CHURN",
}
print("Storing model ...")
published_model_details = wml_client.repository.store_model(
model=model_class,
meta_props=model_props,
training_data=X_train,
training_target=y_train
)
model_uid = wml_client.repository.get_model_uid(published_model_details)
print("Done")
print("Model ID: {}".format(model_uid))
new_model_revision = wml_client.repository.create_model_revision(model_uid)
print(json.dumps(new_model_revision, indent=2))
rev_id = new_model_revision['metadata'].get('rev')
print(rev_id)
デプロイメントスペースの資産に登録されたモデル一覧を確認
wml_client.repository.list_models()
おわりに
CP4DaaS上のNotebookで行う機械学習に必要なデータ入出力の手順について記載しました。この手順では、デプロイメントスペースの資産IDを取得しながら進める前提となっています。資産を再作成してIDが変更した場合にはIDの再取得が必要になり、再作成が繰り返し発生するケースでは作業負荷が増えるという問題があります。
よりスムーズなパイプラインの実装にするために資産IDを自動取得することでこれを回避する方法については、記事を改めて記載したいと思います。