はじめに
これはPython Kyushu 2018 で登壇した内容を簡潔にまとめたものです。
初学者向けの人工知能入門となっております、あらかじめご了承ください。
また、たまに専門用語など出て来ます。わからない単語は積極的にググってください!よろしくお願いします(笑)
本内容は slide share にもまとめてあるため、ぜひ一見して見てください。
また、本投稿で紹介されているコードのソースはこちらです。
目次
- 人工知能とは
- Artificial Neural Network (ANN) とは
- Keras で実装
1. 人工知能とは

主に上記なような人工知能を機械学習と呼びます。人工知能とは広義であり、たくさんの意味を含んでいます。今回は、機械学習よりの話をしていけたらと考えています。
ざっくり気概学習を説明すると下記のようになります。


新垣結衣はかわいいですね(笑)
上記は、たくさんのデータから自主的に規則性を見つけ出し、新しいデータに対して既存との類似度を分析する例です。
このようにデータをもとに学習し、成長するシステムのことを機械学習するシステムと呼びます。
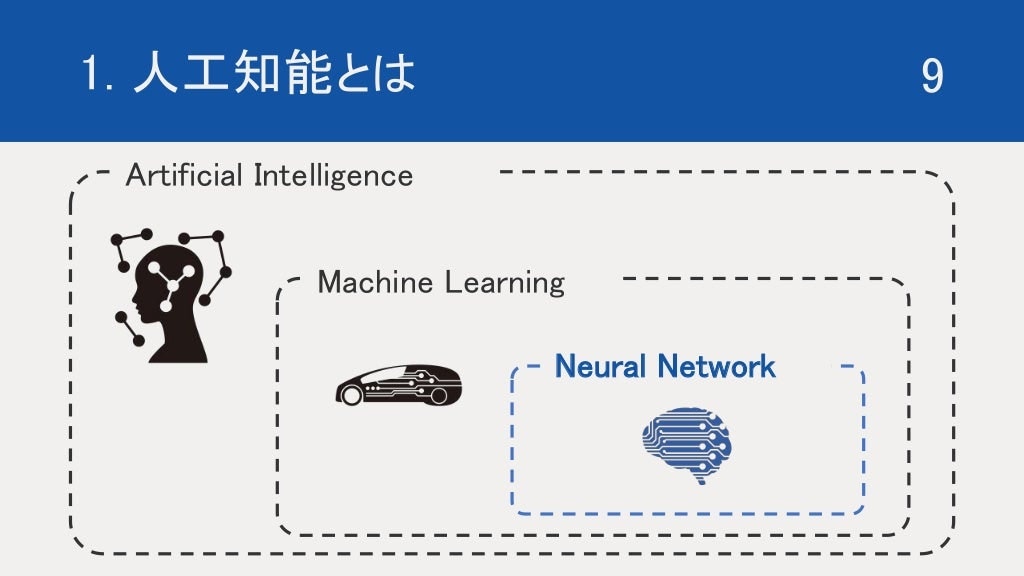
しかしながら、機械学習も広義であり、たくさんのアプローチがあります。
今回は、機械学習の中でも最近注目されている 人工ニューラルネットワーク に焦点をあてて、説明していきます。
2. Artificial Nenural Network (ANN) とは
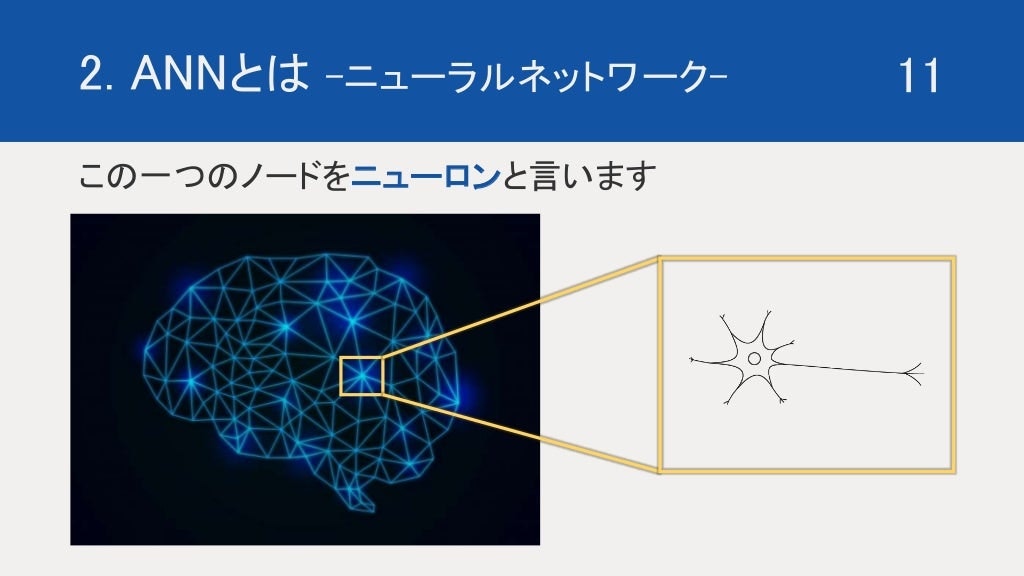
ニューラルネットワーク とは、脳神経回路のことです。このネットワークの一つ一つのノードをニューロンといいます。
ちなみに、このニューロン同士を繋ぐ導線を シナプス といいます。
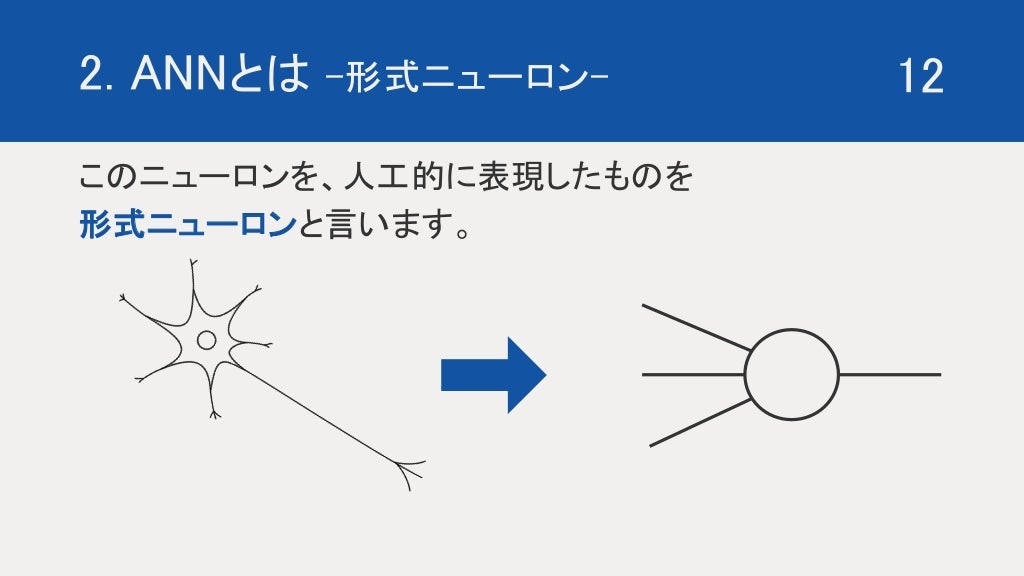
このニューロンを機械的に表現したものを、形式ニューロンであったり、単純パーセプトロンなどと言ったりします。
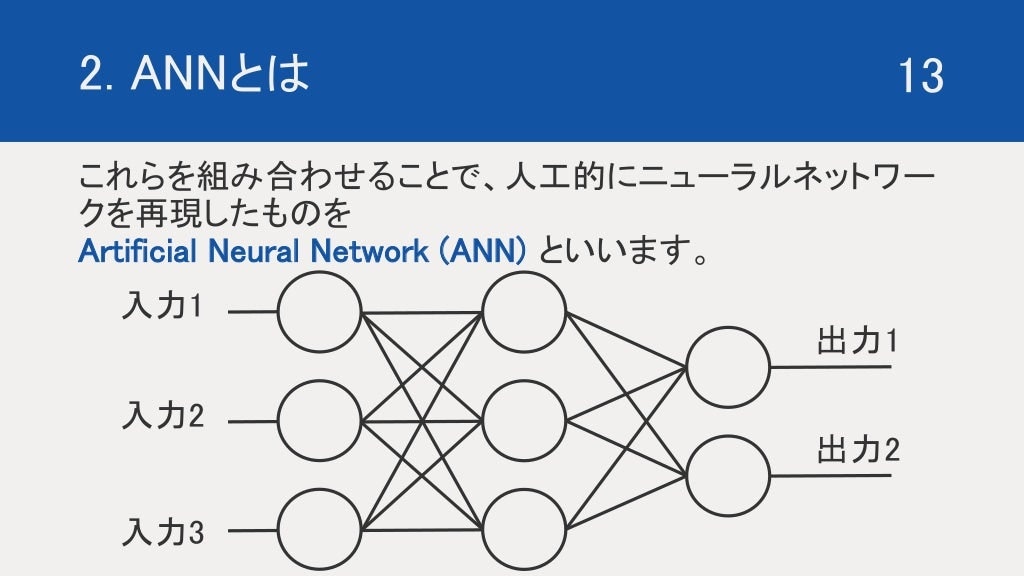
この形式ニューロンをネットワーク上につなげ、擬似的にニューラルネットワーク を表現したものを Artificial Neural Network (ANN) と言います。
それでは次に、形式ニューロンについて、詳しく説明していきたいと思います。
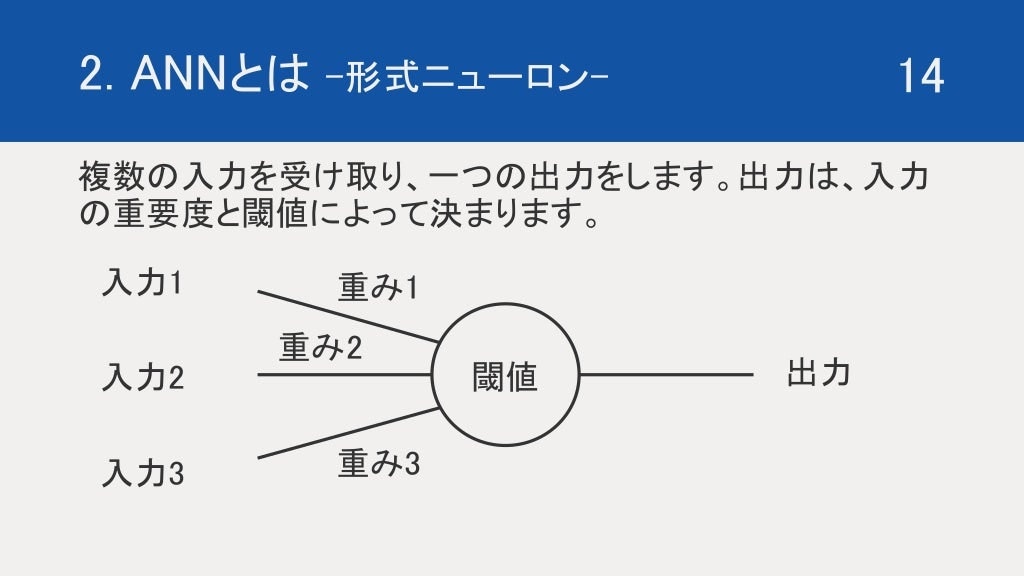
コードで表すのであれば下記のような処理をします。
sum = 0
for i in range(3):
sum += input[i] * weight[i]
if sum >= Threshold:
output = 1
else:
output = 0
※input は入力、weight は重さ、Threshold は閾値、output は出力を表しています。
少しわかりにくいので、仮想通貨を始めるどうかの決断を例に紹介したいと思います。
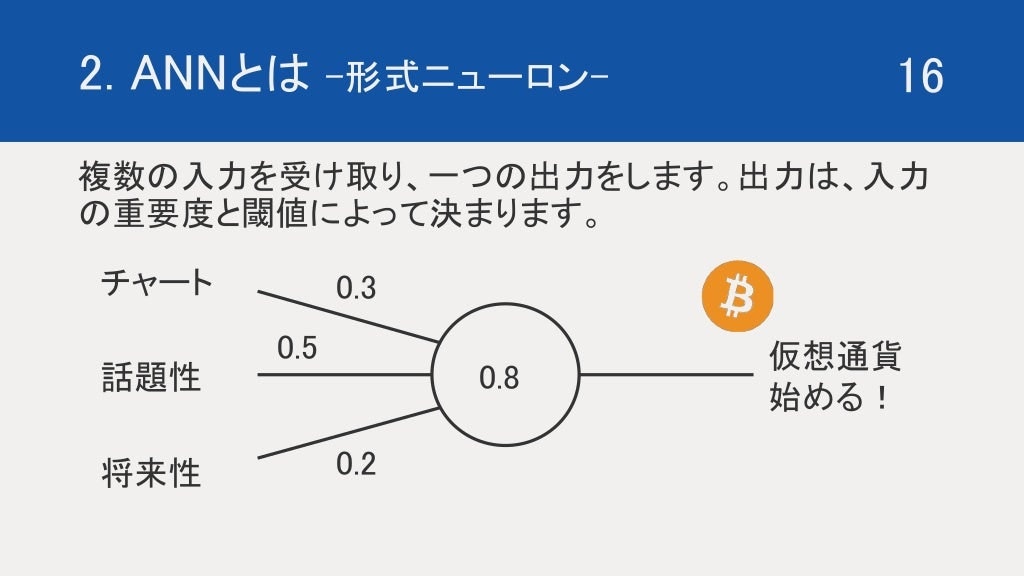
仮想通貨を始める要因をチャート、話題性、将来性、三つと仮定します。
それぞれの始めるまでの重要性を、30%、50%、20%とします。
はじめるかどうかは、モチベーションが80%を超えたらとします。
この場合、話題性があったとしても、チャートと将来性が微妙であれば、sum = 0.5 < Threshold = 0.8 となり、仮想通貨を始めようとなりません。
話題性と昭和異性があったとしても、チャートがよくなければ、sum = 0.7 < Threshold = 0.8 となり、仮想通貨を始めようとはなりません。
チャートと話題性がそろって初めて、sum = 0.8 >= Threshold = 0.8 となり、仮想通貨を始めようとなります。
このように仮想通貨を始めるかどうかを、形式ニューロンで表現することができます。
このような意思決定のアルゴリズムをたくさん、複雑に非線形に組み合わせることによって、いろいろなシステムを表現できるようになります。
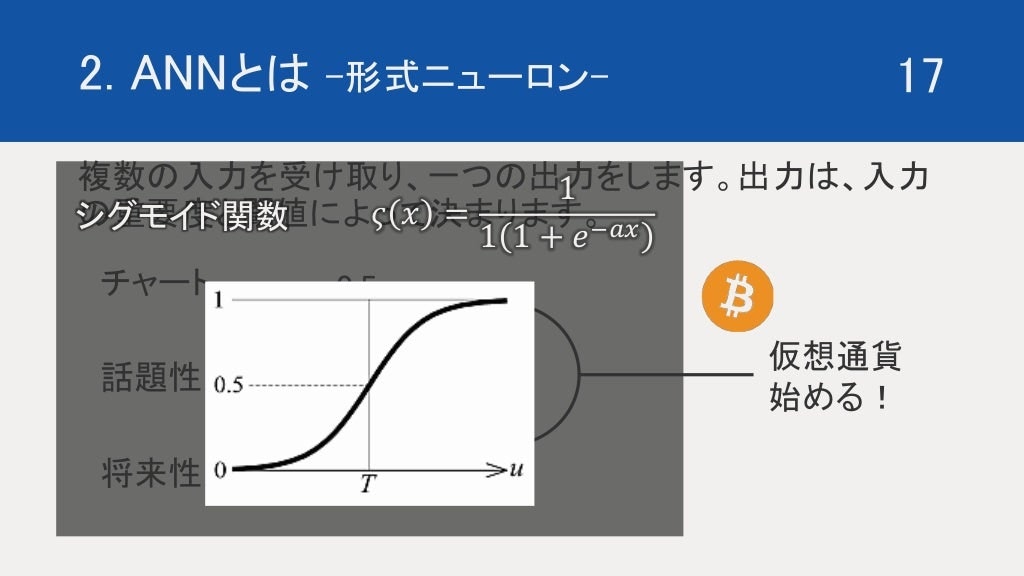
ここで、しかしながら、将来性のみが期待できる場合と、将来性と話題性がある場合での、仮想通貨を始めないという決断では、モチベーションが違います。しかし出力が0, 1 のみになると、その微妙なニュアンスを表現する音ができません。
それを表現するために導入されるのが活性化関数です。
ここでは、一般的な活性化関数であるシグモイド関数を紹介したいと思います。
シグモイド関数は、分母に指数関数の逆関数を持つことによって、0-1 の間の無限に撮り続けます。
簡潔にいうのであれば、マイナス極限が0であり、プラス極限が1になるのですが、結局は0,1 にはならないので実質全ての数を0,1 の間で表現ができます。
いままで、0 or 1 を表現する関数をステップ関数というのですが、このシグモイド関数の係数 a を無限にするとステップ関数になります。ここから分かるように、シグモイド関数はステップ関数を付帯しており、より多くを表現できるような関数です。
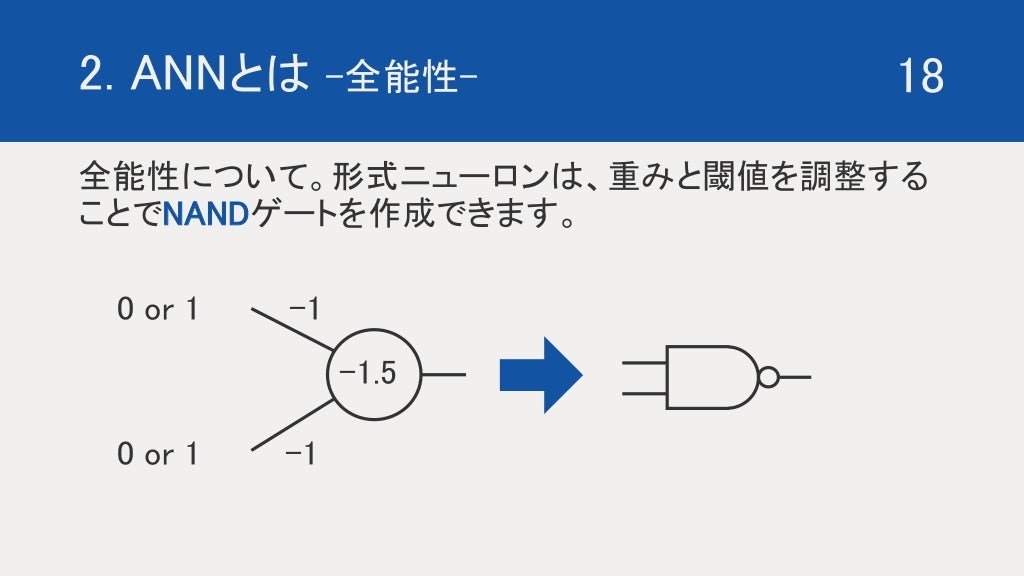
次は、ANN の全能性についてなのですが、形式ニューロンを上記のように設定すると、NAND ゲートを作ることができます。NAND をつくることができれば、実質なんでも回路を表現することができることから直感的に全能性が分かると思います。
たぶん正式な証明ではないので、なんとなく全能性あるっぽいと理解するための補助だと思ってください(笑)
3. Keras で実装

ここでは、Colab と TensorFlow の簡単なライブラリ Keras を使って、モデルを構築していきたいと思います。
Colaboratory(Colab) は、 Google 版 jupyter notebook です。
TensorFlow は Google が提供している、NN の Python API です。

ここでは、新垣結衣、有村架純、本田翼を識別するシステムを作っていきたいと思います。
3.1 画像処理

画像データは、マイクロソフトの Azure, Bing Web Search API を使って集めました。
一週間は無料で使えるので、ぜひみなさまも試してみてください。
使い方は、割愛させていただきます(笑)

この ipy は ipynb をさしています(笑)
新しいpython file は、右クリックから colaboratory を選択すると作れます。
そのあとに、タブのランタイムをクリック、モードの変更を選択し、Python3への変更と、GPUモードへの変更を行います。
最初に各ライブラリを import します。
import glob
import cv2
import numpy as np
import matplotlib.pyplot as plt
import random
import tensorflow as tf
import os
import keras
from keras.utils import np_utils
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.preprocessing.image import array_to_img, img_to_array, list_pictures, load_img
from sklearn.model_selection import train_test_split
glob と os はパスを簡単に取得できるライブラリです。
numpy は、簡単に配列の処理ができるようになるライブラリです。
cv2, matplotlib は、画像処理や図などをプロットするのに使うライブラリです。
randam は、乱数をつくるライブラリです。
あとは Keras の中でも機能をピックアップして import していきます。
次に、!を使って、unixコマンドを打ち込みます。
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
次にGoogle drive との連携を行なっていきます。
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
上記のコマンドを打つと、リンクがでてきて、そのリンクをクリックすると Google アカウントの選択画面になり、その後 drive と連携しますか?と出てくるので、許可をおすと ID が出てきます。 それをコピーし、Colabに戻り、現れる入力画面にペーストすると、また新しくURLができくるので同様の処理を行います。
ディレクトリを用意し、drive の中身をdrive にマウントします。
!mkdir -p drive
!google-drive-ocamlfuse drive
!ls drive/"Colab Notebooks"/imgs
その後、上記のコマンドを実行することで drive を Colab にマウントすることができます。
!mkdir -p drive
は、drive というディレクトリを新規作成しています。
!google-drive-ocamlfuse drive
で drive のディレクトリに driveをマウントしています。
!ls data_path
は、data_path の中身を確認しています。
ここから取り込んだ画像の処理を行なっていきます。
画像を読み込んで numpy 配列に変換する関数を作ります。
glob でパスを取得し、パスの長さ分 OpenCv を使い画像を配列データとして、取り込んでいきます。
np.array で、リストを numpy 配列に変化しています。
def load_pic(data_path):
# goodファイルのパスの読み込み
path_list = glob.glob('drive/Colab Notebooks/imgs/' + data_path + '/*')
# 画像読み込み用のリストの用意
file_list = [None for i in range(len(path_list))]
# 画像の読み込み
for i in range(len(path_list)):
file_list[i] = cv2.imread(path_list[i])
#bgrからrgbへの変換(openCVでは一般的にBGR)
file_list[i] = cv2.cvtColor(file_list[i], cv2.COLOR_BGR2RGB)
# size を 56*56にサイズ変更
file_list[i] = cv2.resize(file_list[i], (56, 56))
file_np = np.array(file_list)
return file_np
上記のコマンドを使い、ディレクトリごとに画像データを取り込んでいきます。
aragaki = load_pic("aragaki")
arimura = load_pic("arimura")
honda = load_pic("honda")
読み込みが終わったら、配列を結合し、ラベリングを行なっていきます
# merge
X = np.concatenate([aragaki,arimura,honda])
# ラベル作成
Y = np.zeros([len(X)])
Y[len(aragaki):] = 1
Y[len(aragaki)+len(arimura):] = 2
新垣結衣が0、有村架純が1、本田翼が3 になるようにラベリングしています。
# 画素値を0から1の範囲に変換
X_ = X.astype('float32')
X_ = X_ / 255.0
# クラスの形式を変換
Y_ = np_utils.to_categorical(Y, 3)
# 学習用データとテストデータ
X_train, X_test, Y_train, Y_test = train_test_split(X_, Y_, test_size=0.33, random_state=111)
今回、one-hot形式でモデルを組んでいきたいため、Y ラベルを one-hot形式に変換します。
上記ではコメントアウトになっていますが、# を消してください(笑)
その後、train と test にデータを分割します。 size は test データのサイズを指定しています。
random_state は、乱数のシード値です。
3.2 Convolution Neural Network (CNN) の説明
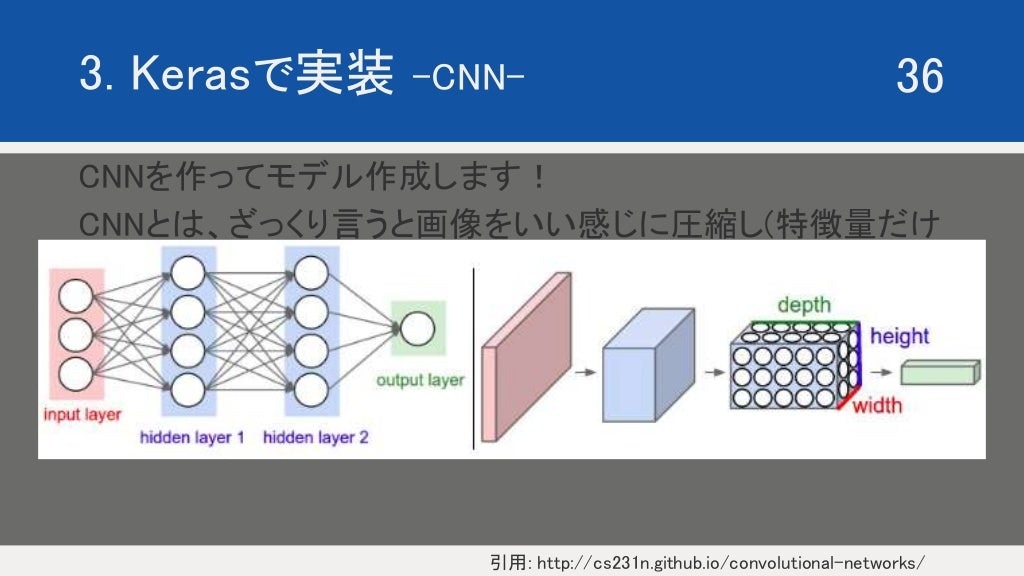
CNN は上記のようにニューラルネットワーク を組んでいきます。
畳み込み積分をしていく際に、かける行列の大きさとstep の幅によってちょっとずつ圧縮されていきます。その代わりに何回も繰り返し計算するため、奥行きはどんどん出来上がっていきます。

ざっくり CNN の構造を層ごとにみていくと、上記のようになります。
conv層、活性化層、プーリング層が人セットになり、それが三回繰り返されています。
FC とあるのは、Fully Connected の略です。全結合層といい、最後にまとめる層です。
最後に、softmax 関数などをかますことで、確率に変換します。
こちらに超わかりやすい cnn の説明がありますので、参考にまでに!
※上記の写真は、上記の サイト から引用しています。
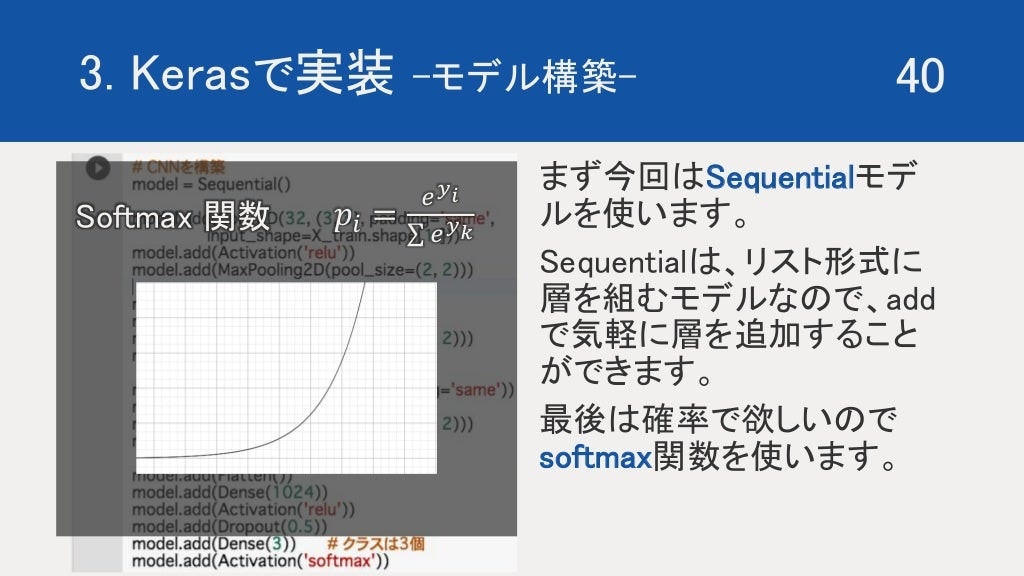
今回は、Sequentialモデルを使用します。
Sequentialモデルは、リスト形式に層を定義していくモデルなので、add 関数を使って、気軽に層を足していくことができます。
最後は、確率で出力して欲しいので softmax 関数を使用します。
3.3 モデル構築と実行
# CNNを構築
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(3)) # クラスは3個
model.add(Activation('softmax'))
MaxPooling というのは、プーリング手法の一つです。エリアに分け、そのエリア内で一番起きなものを特徴量として選び圧縮していく方法です。

次は、モデルをコンパイルしていきます。
# optimizer には adam を指定
adam = keras.optimizers.Adam(lr=1e-3)
model.compile(loss='categorical_crossentropy',
optimizer=adam,
metrics=['accuracy'])
今回最適関数に Adaptive moment estimation (Adam) を使用します。
最適化関数は、重さとバイアスの最適化を行う際に収束するように誘導する処理だと思ってください。
次は、実際に学習させていきましょう。 fit を使うと学習を開始します。
history = model.fit(X_train, Y_train, batch_size=BATCH_SIZE, epochs=MAX_EPOCH,
validation_data = (X_test, Y_test), verbose = 1)
実行には、10 - 15 分程度時間がかかりますので、余裕を持って行いましょう(笑)
学習が終わったら、結果を matplotlib を使って出力していきます。
学習の遷移は、historyにdictonary形式に格納されているので、keyを呼び出すことでアクセスできます。
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['acc', 'val_acc'], loc='lower right')
plt.show()

今回、GPU ということで調子に乗り 10,000 回も回してしまいました(笑)
めちゃめちゃ時間がかかったので、おすすめは 1,500 回です(笑)
よい子のみんなは、1,500 回程度回しましょう(笑)
次は、学習したモデルを使って、予測を行なっていきます。model.predict で予測できます。
predict = model.predict( np_data_list )
data_list には、予測にかけたいnumpy.arrayを入れます。
今回は、X_test を入れてみましょう !
予測結果は、確率で帰ってきます。出力は三つあり、それぞれの人物である確率を出力してくれます。
つまり 0-1 の間を返してくれるので、それをもっとわかりやすくするために、one-hot 形式と対応させるように、strのリストを作ります。
# カテゴリの作成
category = ["新垣結衣","有村架純","本田翼"]
for文でpredictの中身を一個ずつ処理します。
出力は確率ですのでargmaxをとり、確率も出力できるようにします。
次に予測結果をプロットしていくのですが、Colab では、そのままplot すると羅線が入ってしまうので、羅線を削除する関数を定義します。
def clearLabel(ax_):
ax_.tick_params(labelbottom="off",bottom="off")
ax_.tick_params(labelleft="off",left="off")
ax_.set_xticklabels([])
ax_.axis('off')
return ax_
このれclearLabel 関数をうまく使いながら、予測結果を図と対応させながらプロットしていきます。
for (i, pre) in enumerate(predict):
y = pre.argmax()
y_ = Y_test[i].argmax()
print("予測 :{0} {1}% ".format(category[y], round(pre[y]*100)) )
print("正解: ", category[y_])
fix, ax = plt.subplots(dpi=30)
clearLabel(ax)
plt.imshow(X_test[i])
plt.show()
これをそのまま行うと、テストデータ(350くらい)すべてプロットされるので、おすすめは if 関数をいれて、 i == 10 くらいで break を入れてあげるといい感じになります(笑)
if i == 10:
break
また、確率は めちゃめちゃ小数点を取ることがあるので、round 関数を使って丸めます。

以上です!
いかがでしたでしょうか?
結構拙い説明だったり、わかりずらいこともあると思いますので、気軽にコメントに質問など書いてください(^-^)
また間違いもあると思います。「ここ間違ってるで」などのご意見も絶賛募集していますので、どしどしコメントくださいお願いしまーす!
以上。新垣結衣かわいいよね ブログでした!笑