この記事は ただの集団 Advent Calendar 2020 の1日目の記事です。
はじめに
- 膨大なWebの世界から必要なデータを抽出するクローラーの需要は高まってきているが、いざ開発を始めようとすると開発に関する情報は意外なほど少ない。専門書やWeb記事も少なく学会や勉強会の開催情報もあまり見当たらない。GoogleもSEOの技術情報は多く発信しているがクローリングに関しては控えめだ。
- おそらくWebクローリング自体に明文化されたルールが少なくグレーな部分が多く情報がシェアされ辛いのが要因の一つだと思う。例えばクローリング対象サイトにどのくらい間隔を開けてアクセスするかなどは明文化されたルールがなく自主性に任せられていて度が過ぎるとアタックとみなされてしまう難しい世界だ。
- そこで最新のクローラーの動向を追うにはどうすれば良いかと考えたところ、世の中にあるクローラーのツールやサービスなどが参考になりそうなのだったので実際に触って機能を見てみる。
クローラーサービス
Octoparse
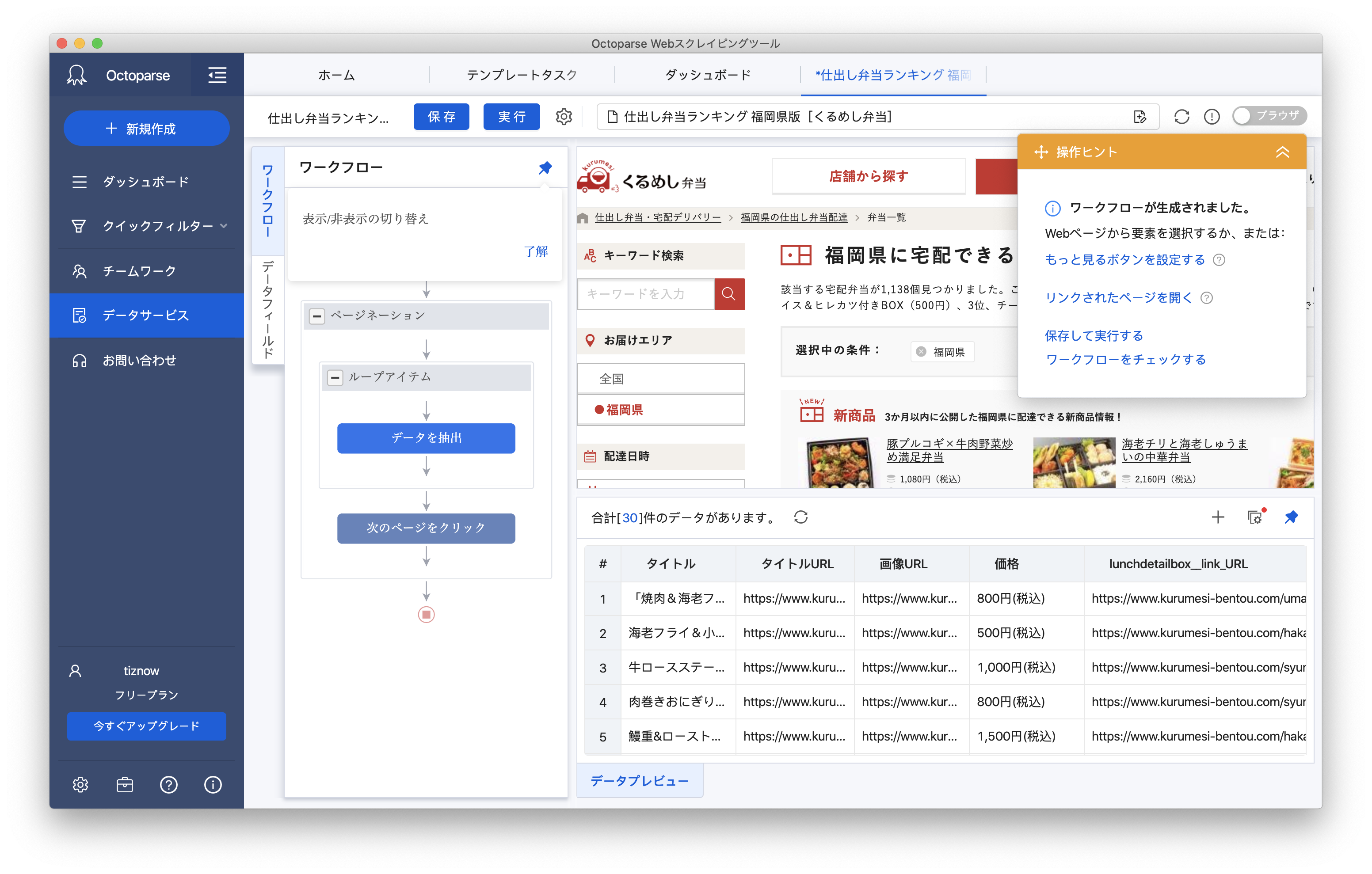
- 料金: 無料 ~ $167/月 or Enterprise
- ツールやサイトが日本語だったので国産かと思ったがアメリカ製。
- SPAサイトも対応。
- クローリングしたいサイトのURLを入力するだけで構造化データを解析して抽出できる。そこからワークフローを作ることでカスタマイズしたクローリングが可能。
- 自分で1からワークフローを作らなくてもAmazonやTwitterなど有名なサイトはテンプレートが用意されていて用途に応じてサクッとクローリングができる。
- 取得したデータはCSV・TSVを初めとして様々なフォーマットで取得可能。
- 有料版にすることでできること
- タスク数や並列度の増加
- 定期実行
- IPローテーション
- APIを通しての操作
ParseHub
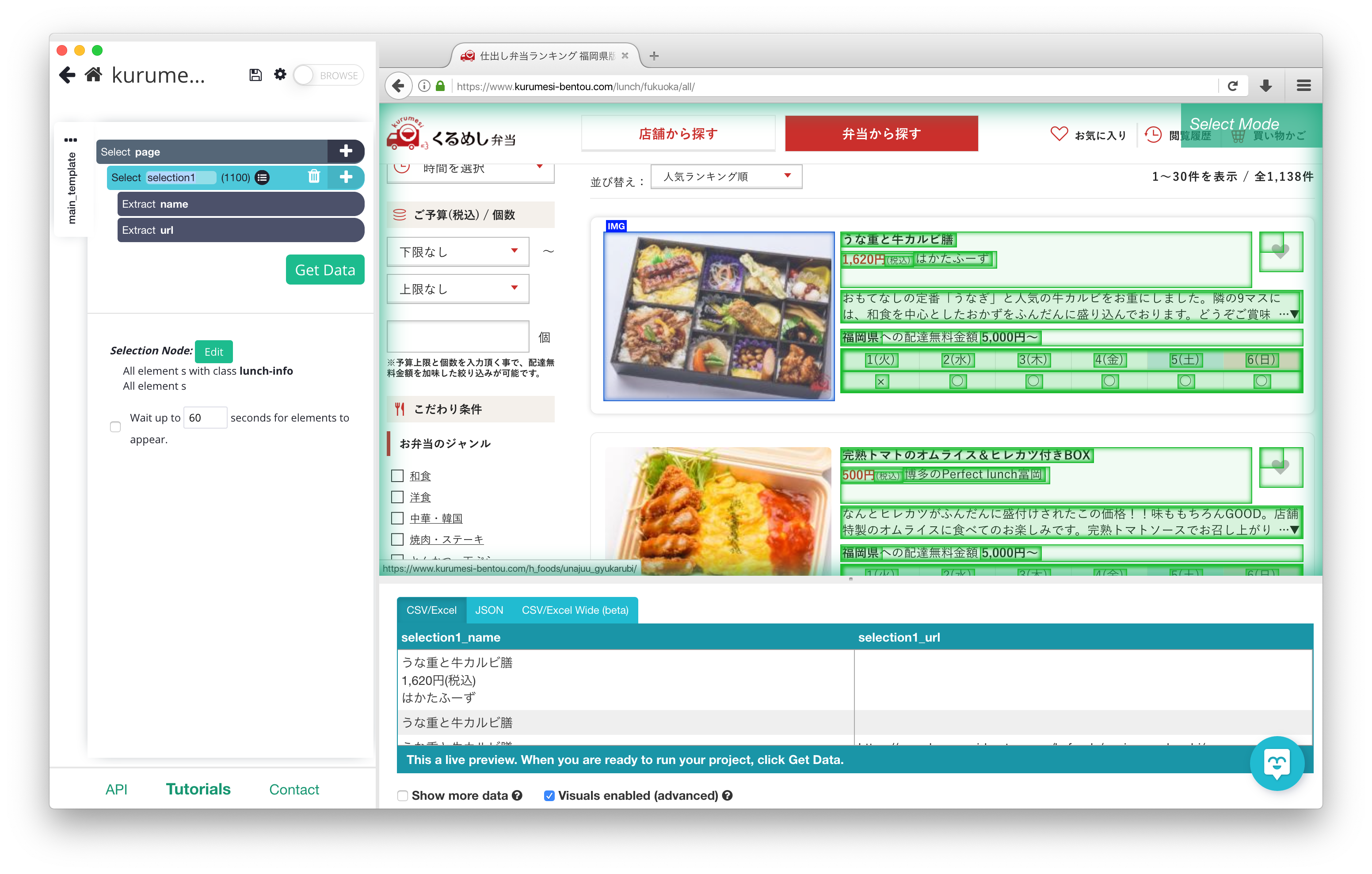
- 料金: 無料 ~ $499/月 or Enterprise
- カナダ製。
- SPAサイトも対応。
- URLを入力した後で抽出したい箇所をいくつかクリックすると機械学習で勝手にクローリングを開始してデータを抽出する。
- 有料版にすることでできること
- クローリングページやプロジェクトの上限増加
- データ保持期間延長
- 取得した画像のDropBoxやS3へのアップロード
- IPローテーション
- 定期実行
Dexi.io
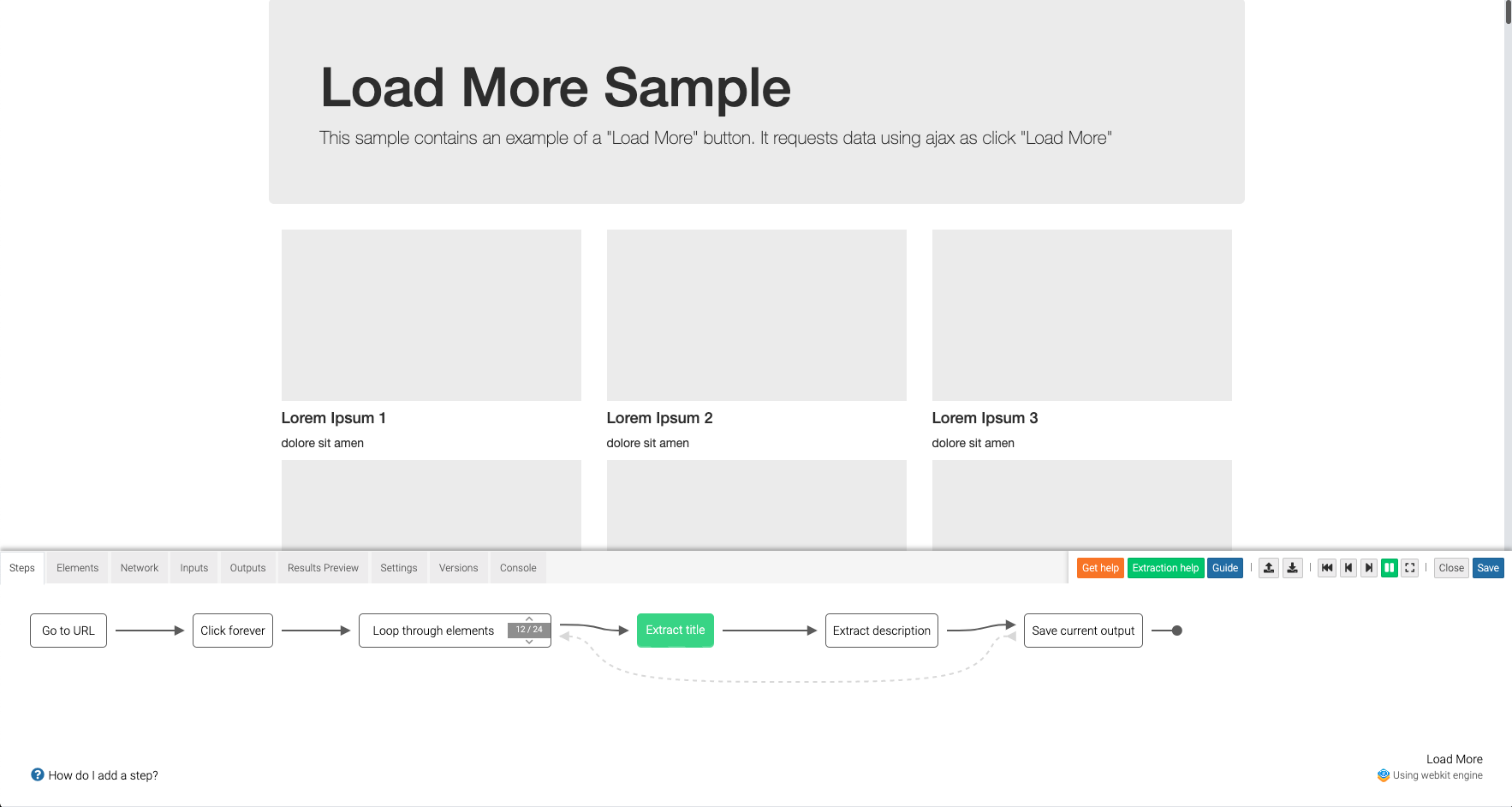
- 無料 ~ $625/月 or Enterprise
- イギリス製。
- SPAサイトも対応。
- Extractor、Crawler、Pipesなどのパーツを繋げて自由にクローラーをカスタマイズして作れる。カスタマイズ性が非常に高そうだが、1から自分で組み立てるので最初に動かせるようになるまで結構大変。
- 有料版にすることでできること
- 多くのアプリとインテグレーションできる。
- ライブサポートが付く。
今回触れなかったサービス・ツール
- 良さそうだが無料版なし、カード入力必須、フリーメールでアカウント作成ができない、アカウント作成にコンタクトが必要、などで動かすまでが大変そうで断念したサービス。
- クライアントツールのみ提供で自分のローカル環境のIPからアクセスしないといけないツール。そもそもクローラーツールはWebアクセスを許可しないといけないためアンチウイルスソフトと相性が悪く、信頼できないソフトはあまりインストールしたくない。
まとめ
- 調べてみると思った以上にサービスやツール量が多く需要の高さが窺えた。おそらく探せばまだまだ数はありそう。ただしほぼ海外製。
- 一方でアカウント登録はほぼ必須であり、エンタープライズ向けのサービスが多く、気軽に使えるものは少ない。
- 気軽に無料で試すのであればOctoparseとParseHubはURLを入力するだけですぐ使えて操作が直感的でかつ高機能。
- SPAサイト対応は今や標準。
- 機械学習やAIの活用ももはや標準。
- 一般的な用途であればスクラッチで作らなくても何かのサービスを使ったり連携したりで事足りそう。
- 今後も動向はウォッチしていきたい。