はじめに
こんにちは、GxPの森下です!
この記事はグロースエクスパートナーズ Advent Calendar 2023の24日目の記事です。
社内でデータ分析やAIに関する勉強会を行っており、その中でLLMを扱う方法に興味を持ち、学んだことをまとめました。
環境
- OS : Windows11
- CPU : 12th Gen Intel(R) Core(TM) i5-1235U
- RAM : 32.0 GB
- Python : 3.10
- LlamaIndex : 0.9.16
- llama-cpp-python : 0.2.20
llama.cppとllama-cpp-pythonについて
通常、LLMを動かす場合、GPUが必要になるかと思いますが、llama.cppを使用することで、量子化されたLLMをCPUでもLLMを動かすことが出来るようになります。ただ、llama.cppはC/C++で記述されているためそのままではPythonで扱うことはできません。そこで、llama-cpp-pythonを使用することでPythonバインディングを行うことができ、Pythonでも使用できるようになります。この記事では、llama.cppやllama-cpp-pythonの基本的な使用方法や注意すべき点について説明します。
準備
今回は以下のものを使用します。
- CMake (Visual Studio 2022)
- Miniconda3
- llama.cpp (LlamaIndex)
- llama-cpp-python
- RAG (LlamaIndex)
- DeepL API
CMakeのインストール
今回必要となるCMakeのインストール方法を2種類紹介します。
- CMakeの公式サイトからインストール
- Visual Studio 2022でCMakeをインストール
※以下のいずれかのインストールを行わない場合、llama-cpp-pythonのインストール時にCMakeに関するエラーが表示され、インストールすることが出来ません。
CMakeの公式サイトからインストール
公式サイトの右上にあるDOWNLOADからGet the Softwareの画面に遷移し、以下のBinary distributionsにあるmsiファイルを選択し、ダウンロード後、実行します。

実行後、基本的にはそのままNextボタンをクリックし、進めていきますが、以下のInstall Optionsの選択画面では、Add CMake to the system PATH for the current userを選択します。
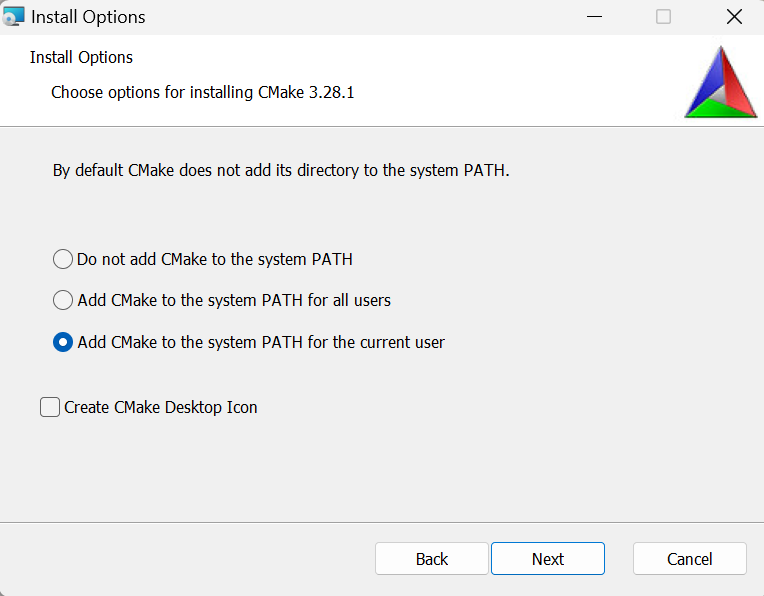
インストール後、以下のコマンドでCMakeのバージョンを確認することが出来ます。
cmake --version
Visual Studio 2022でCMakeをインストール
Visual Studio 2022をインストールする際に「C++によるデスクトップ開発」にチェックを入れ、インストールします。
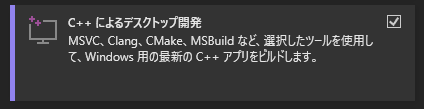
すでにVisual Studio 2022がインストールされている場合は、Visual Studio Installerをパソコン内で検索し、変更をクリック、「C++によるデスクトップ開発」にチェックを入れ変更をクリックし、インストールを行います。
Miniconda3での環境構築
作業を進めて行く上で自分のPCの環境を汚したくないので、仮想環境を使用していきます。仮想環境の選択肢としては、pyenvやAnaconda、Miniconda3があると思います。その中で今回は、Miniconda3を使用していきます。以下にその手順を示します。
インストール
上記のサイトのLatest Miniconda installer linksと記載されている箇所の少し下にあるMiniconda3 Windows 64-bitをダウンロードします。
基本的にNextボタンを押し続ければいいですが、保存されるディレクトリはどこなのかだけ確認しておいてください。
環境変数の設定
以下の例では、インストールの際に<ユーザー名>の直下にMiniconda3がインストールされたことを示しています。インストールした際に別のディレクトリになってしまっている場合は、以下の内容を読み換えて考えてください。
Users/ユーザー/<ユーザー名>/miniconda3
# 例:Users/ユーザー/n.morishita/miniconda3
Users/ユーザー/<ユーザー名>/miniconda3/condabin
# 例:Users/ユーザー/n.morishita/miniconda3/condabin
上記のpathを環境変数に設定していきます。手順は以下の通りとなっています。
設定 > システム> バージョン情報 > システムの環境設定 > 環境変数 > システム環境変数の「Path」をダブルクリック > 新規 > 上記のPathをそれぞれ追加
環境変数の設定ができたら、コマンドプロンプトで以下のコマンドを入力して確認してみてください。設定がうまく行っていたら仮想環境一覧 (デフォルトではbaseのみ) が表示されるはずです。condaコマンドが認識されないエラーが出る場合はもう一度設定を確認してみてください。
conda info -e
※bashを使用する場合は、別途設定を行う必要があるので、上記のコマンドはコマンドプロンプトで確認を行ってください。bashの設定については後述します。
仮想環境の作成
仮想環境を作成する場合は、仮想環境名とPythonのバージョンを指定します。Pythonのバージョンを指定しない場合はローカルと同じバージョンのものになります。
conda create -n <仮想環境名> python==3.10
# 例:conda create -n sample-name python==3.10
仮想環境作成後、以下でPythonのバージョンも併せて確認してみてください。
Pythonのバージョンの確認
python -V
※Vは大文字なので注意してください。
仮想環境のactivate/deactivate
activate
conda activate <仮想環境名>
# 例:conda activate sample-name
※仮想環境名を指定しない場合は、デフォルトで用意されているbaseになります。
※作業を開始する際は、必ず仮想環境をactivateしていることを確認してください。
deactivate
conda deactivate
bashでcondaコマンドを使用するための設定
# 一時的で良い場合
. "C:/Users/n.morishita/miniconda3/etc/profile.d/conda.sh"
# 今後も使用したい場合
echo ". C:/Users/n.morishita/miniconda3/etc/profile.d/conda.sh" >> ~/.bash_profile
※各pathをコピーした直後は、\になっていると思うので、これを/に変える必要があります。
こちらもcondaコマンドが実行できるか確認してみてください。
llama.cpp
llama.cppはLangchainとLlamaIndexのそれぞれにあり、内容も若干異なります。
ここでは、LlamaIndexのllama.cppを使用します。
※LlamaIndexの公式ドキュメントにはlatest版とstable版があるので、stable版を見るのが良いかと思います。
インストール
pip install llama-index
llama-cpp-python
インストール
pip install llama-cpp-python
※llama-cpp-pythonをインストールする前にC++のコンパイラをインストールしておく必要があります。コンパイラがインストールされていない場合は、CMakeに関するエラーが表示されます。
使用するモデル
LLMのモデル自体は複数あり、LlamaIndexとの互換性については以下に記載されています。
今回は、Llama-2-13B-chatを使用します。
llama-cpp-pythonでは、使用するモデルの形式が指定されており、llama-cpp-pythonの使用するバージョンによって異なります。
0.1.79以降の場合は、GGUF形式を使用し、それより前の場合はGGML形式を使用します。
自分が使用しているllama-cpp-pythonのバージョンは以下のコマンドで確認することが出来ます。
pip freeze | grep llama_cpp_python
※コマンドプロンプトの場合、grepコマンドは使用出来ないと思いますので、pip freezeだけ使用すると確認することが出来ます。
今回使用するllama-cpp-pythonのバージョンは0.2.20なので、GGUF形式を使用します。
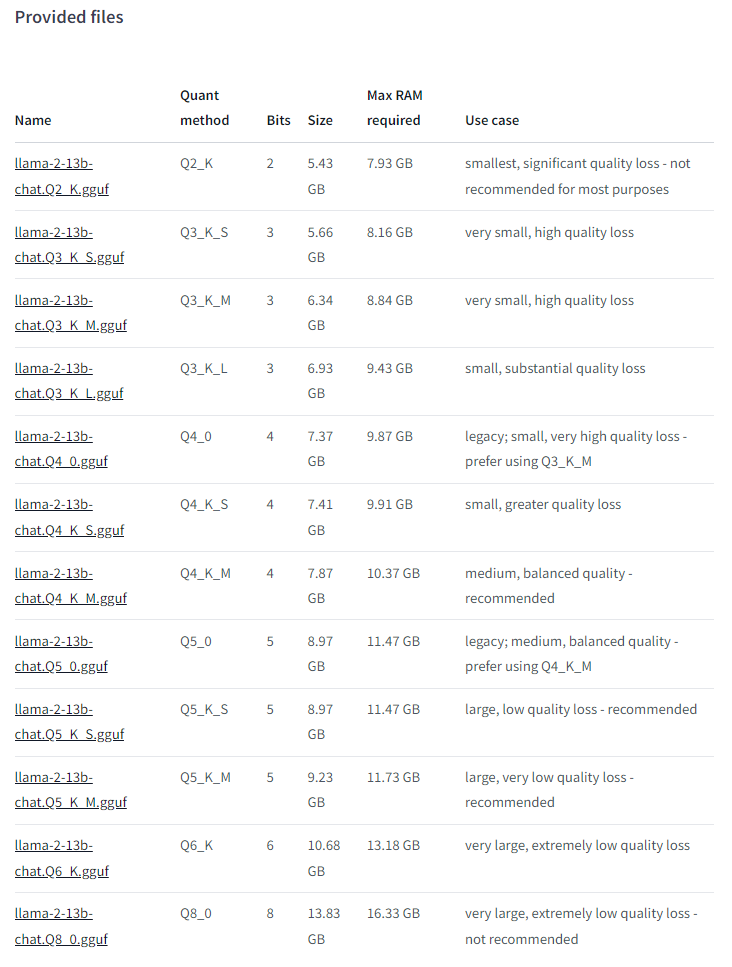
量子化されたモデルの選び方
上記のサイトに以下のようにモデルを量子化したものが複数用意されています。Max RAM requiredが自分のパソコンのスペック以下のものかつ、Use caseがrecommendedのものを使用します。
選択したモデルは、上部にあるFile and versionsのタブから選択し、ダウンロードすることが出来ます。
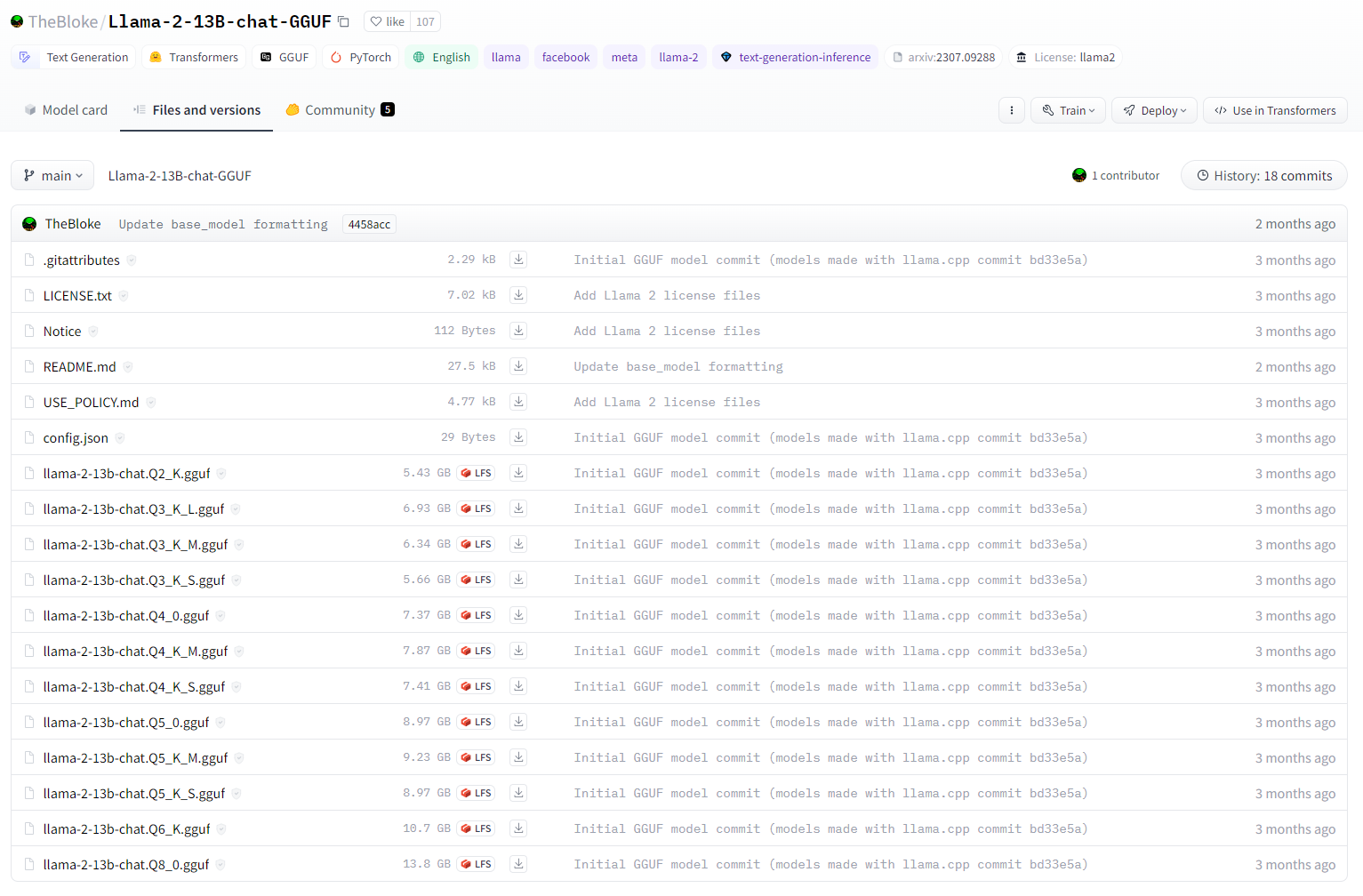
今回は、llama-2-13b-chat.Q4_0.ggufを使用します。
ちなみに、Google Colabを使用してLLMを動かす場合はGPUは16GBのため、Max Ram requiredが16GB以下のものを選ぶ必要があります。
llama.cppの基本的な使い方
from llama_index.llms import LlamaCPP
from llama_index.llms.llama_utils import (
messages_to_prompt,
completion_to_prompt,
)
model_url = "https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/resolve/main/llama-2-13b-chat.Q4_0.gguf"
# model_urlとmodel_pathを両方ともNoneにすると、自動でllama-2-13B-chatが選択されます
llm = LlamaCPP(
# You can pass in the URL to a GGML/GGUF model to download it automatically
model_url=model_url,
# optionally, you can set the path to a pre-downloaded model instead of model_url
model_path=None,
temperature=0.1,
max_new_tokens=256,
# llama2 has a context window of 4096 tokens, but we set it lower to allow for some wiggle room
context_window=3900,
# kwargs to pass to __call__()
generate_kwargs={},
# kwargs to pass to __init__()
# set to at least 1 to use GPU
model_kwargs={"n_gpu_layers": 1},
# transform inputs into Llama2 format
messages_to_prompt=messages_to_prompt,
completion_to_prompt=completion_to_prompt,
verbose=True,
)
response = llm.complete("Hello! Can you tell me a poem about cats and dogs?")
print(response.text)
# 応答をストリーミングする場合
response_iter = llm.stream_complete("Can you write me a poem about fast cars?")
for response in response_iter:
print(response.delta, end="", flush=True)
model_urlには、使用するモデルのdownloadからリンクをコピーしてくるか、モデルのURLのblobをresolveに変換することで使用できます。以下に例を示します。
変換前:https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/blob/main/llama-2-13b-chat.Q4_0.gguf
変換後:https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/resolve/main/llama-2-13b-chat.Q4_0.gguf
※当然ですが、仮想環境に入った後にエディタを開き上記コードを記述してください。仮想環境に入るのを忘れている場合、モジュールが見つからない旨のエラーが表示されます。
RAG
RAGについて
RAGは、データをベクトル化し、Vector Storeに保存します。このVector Storeに対し、Queryを行い関連性の高いデータを抽出し、そのデータとプロンプトを合わせてLLMに送ることで、特定の質問に対する回答の精度を上げることが出来るようになります。
LlamaIndexを用いたRAG
まず、全体像をつかむために概要について説明します。
LlamaIndexでのRAGの流れとしては、以下の順で行います。
- Documentの作成
- Nodeの作成 (※ServiceContextの作成)
- Indexの作成
- StoreにIndexを保存
- Queryを実行
構成は以下のような内容になります。
from llama_index import SimpleDirectoryReader, VectorStoreIndex, ServiceContext
from llama_index.text_splitter import SentenceSplitter
# Documentの作成
documents = SimpleDirectoryReader("./data").load_data()
# Nodeの作成
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
# ServiceContextの作成
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
# indexの作成
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
# Indexを保存
index.storage_context.persist(persist_dir="<persist_dir>")
# Queryを実行
query_engine = index.as_query_engine()
response = query_engine.query(
"Write an email to the user given their background information."
)
print(response)
LlamaIndex v0.10以降ではServiceContextの使用は非推奨になっており、以下の方法を使用するように記載されています。
- index作成用のembeddingsモデルやquery/response用のLLMなど、関連するパラメータはモジュールに直接渡す。
- グローバル設定を定義できるようにし、これを一度定義すれば、ダウンストリームコードでカスタムパラメータを指定する必要がない。
具体的な使用方法などは、こちらを参考にしてみてください。
Documentの作成
回答に必要なデータを読み込み、ドキュメントの作成を行います。
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
ここでは、様々なデータを読み込むことができ、読み込めるファイルの種類やその読み込み方法については以下のLlama Hubに記載されています。
例として、PDFとWebサイトを読み込む例を以下に記述します。
from pathlib import Path
from llama_index import download_loader
PDFReader = download_loader("PDFReader")
loader = PDFReader()
documents = loader.load_data(file=Path('./article.pdf'))
- Webサイト
from llama_index import download_loader
SimpleWebPageReader = download_loader("SimpleWebPageReader")
loader = SimpleWebPageReader()
documents = loader.load_data(urls=['https://google.com'])
Documentのカスタマイズ
Documentを作成するときに、メタデータを付与することが出来ます。メタデータを付与することで回答の際にフィルタリングすることが出来ます。また、Documentに追加されたメタデータは、それぞれのDocumentから作成されたNodeにコピーされます。
document = Document(
text="text",
metadata={"filename": "<doc_file_name>", "category": "<category>"},
)
Nodeの作成 (ServiceContextの作成)
Nodeとは、Documentのchunkのことであり、Nodeに変換することで回答の精度を上げることが出来ます。
※chunkとは、大きなテキストを小さなセグメントに分割する方法です。これにより、ノイズを減らし、意味的に適切なものを抽出することが出来るようになります。
from llama_index import SimpleDirectoryReader, VectorStoreIndex, ServiceContext
from llama_index.text_splitter import SentenceSplitter
documents = SimpleDirectoryReader("./data").load_data()
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
※ここではSimpleNodeParserを使用しており、この引数のデフォルトはchunk_sizeが1024、chunk_overlapが20になっています。chunk_overlapとは、chunkに分割した際にoverlap (後ろのchunkに前のchunkの末尾を付け加える) する文字数を指定しています。これにより、chunkに分割したことによる文脈の断裂を緩和することができます。
Node Parserの詳細やchunkサイズについては以下を参考にしてみてください。
※ServiceContextは、Index作成やQueryの段階で使用されるオブジェクトの設定を行うためのものです。引数には、llm、embed_model、text_splitter、prompt_helperを指定できます。
embed_modelに何も指定しなかった場合、OpenAIのモデルを使用するため、OpenAIのAPIキーが必要になります。embed_model="local"とすることで、ローカルのモデルを指定することが出来ます。その場合、hugging faceのモデルを使用することになり、以下のものをインストールする必要があります。
pip install transformers torch
Indexの作成
IndexとはDocumentオブジェクトで構成されるデータ構造であり、Indexに変換することでLLMによるQueryを可能にします。Nodeは以下のようにしてIndexに変換することが出来ます。
LlamaIndexには複数のIndexのタイプが存在しますが、ここでは最も一般的なVectorStoreIndexについて説明します。VectorStoreIndexはDocumentをNodeに分割し、すべてのNodeのテキストのVector embeddingsを作成することで、LLMによるQueryを可能にします。
Vector embeddingsは、テキストの意味を数値的に表現したものであり、これに対しQueryを行うことで単純なキーワードの一致ではなく、意味が関連しているものを検索出来るようになります。Embeddingsを行うモデルには多くの種類がありますが、LlamaIndexでは、OpenAIがデフォルトで使用しているものと同じtext-embedding-ada-002をデフォルトで使用しています。
from llama_index import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
また、以下のようにNodeオブジェクトのリストに対してIndexを構築することも出来ます。
from llama_index import VectorStoreIndex
index = VectorStoreIndex(nodes)
StoreにIndexを保存
Indexを再度作成する場合、時間などが無駄になってしまいます。そこで、ここでは作成したIndexを保存する方法について説明します。
以下のようにpersistメソッドを使用することで、指定された場所<persist_dir>に保存することが可能です。
index.storage_context.persist(persist_dir="<persist_dir>")
保存したIndexをロードする際は、以下のように記述します。
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="<persist_dir>")
# load index
index = load_index_from_storage(storage_context)
Queryの実行
Indexが作成出来たらQueryを実行出来るようになっているはずです。ここでは説明しませんが、LlamaIndexでは以下のように簡単にQueryを実行出来るだけでなく、Queryをより細かく制御出来るlow-level composition APIも存在しています。
query_engine = index.as_query_engine()
response = query_engine.query(
"Write an email to the user given their background information."
)
print(response)
回答をstreamさせたい場合は、公式ドキュメントにも記載されていますが、index.as_query_engine(streaming=True)とすることで、可能になります。
Queryには、以下の3つの段階が含まれています。
- Retrieval : Queryに最も関連性がドキュメントをIndexから見つけて返すことです。
- Postprocessing : 取得されたNodeが変換されたり、フィルタリングされることです。
- Response synthesis : Queryと最も関連性が高いデータ、プロンプトが結合され、LLMに送られ、回答が生成されることです。
詳しくは、公式ドキュメントを参考にしてください。
DeepL API
上記のQueryに日本語を使用した場合でも英語で回答が生成されます。また、無理やり日本語を生成するようにQueryに書き込んでもうまくいきませんでした。なので、英語の回答を日本語に翻訳するためにDeepLのAPIを使用します。
使用するためには、ヘッダーにあるAPIから「無料で登録する」を選択し、DeepL API Freeの「無料で登録する」を選択するとDeepLアカウントの登録画面に遷移します。メールアドレスを登録後、個人情報の登録をし、完了となります。
※個人情報の登録では、APIの不正利用を防ぐためにクレジットカードの入力が必要となりますので、事前にご用意ください。
APIキーの取得
APIキーの場所が少し分かりにくいのですが、以下の手順で取得できます。
- 右上のハンバーガーメニューから下の方にある「アカウント」を選択
- 以下の画像の「アカウント」を選択

- 選択後、下にスクロールすると「DeepL APIで使用する認証キー」があるので、そこから取得可能
APIキーを環境変数に設定
setx DEEPL_API_KEY “<yourkey>”
上記のコマンドで「ユーザー環境変数」に設定されます。
※環境変数を設定後、PCを再起動しないとos.getenv()で環境変数を取得しようとしてもNoneになってしまうので注意してください。
APIキーの取り扱いについては、OpenAIのBest Practices for API Key Safetyが参考になると思うので、こちらも併せて見てみてください。
インストールと使用方法
公式ドキュメントにも記載されていますが、以下のように使用します。
インストール
pip install --upgrade deepl
使用方法
import deepl
auth_key = "f63c02c5-f056-..." # Replace with your key
translator = deepl.Translator(auth_key)
result = translator.translate_text("Hello, world!", target_lang="FR")
print(result.text) # "Bonjour, le monde !"
一部の言語でのみ指定出来るformalityというオプションがあり、指定可能な言語では、formality="more"を指定するとフォーマルで丁寧な言葉遣いになるようですが、現時点で日本語には対応していないようなので、こちらは使用しません。
実際に動かしてみる
以下の例では、Webサイトの内容を読み込ませ、その内容を元に回答を生成し、日本語でその結果を出力させます。
インストール
pip install llama-index llama-cpp-python transformers torch
embeddings.pyの実行は1回のみで大丈夫です。
実行後、指定したディレクトリpersist_indexの配下に4つのファイルが作成されます。
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.text_splitter import SentenceSplitter
from llama_index.llms import LlamaCPP
from llama_index.llms.llama_utils import (
messages_to_prompt,
completion_to_prompt,
)
# LLMの設定
model_url = "https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/resolve/main/llama-2-13b-chat.Q4_0.gguf"
llm = LlamaCPP(
model_url=model_url,
model_path=None,
temperature=0.1,
max_new_tokens=256,
context_window=3900,
generate_kwargs={},
model_kwargs={"n_gpu_layers": 1},
messages_to_prompt=messages_to_prompt,
completion_to_prompt=completion_to_prompt,
verbose=True,
)
SimpleWebPageReader = download_loader("SimpleWebPageReader")
loader = SimpleWebPageReader()
# Documentの作成 (GxPのG+WEBのサイトを使用)
documents = loader.load_data(urls=['https://www.gxp-group.co.jp/gplus/'])
# Nodeの作成
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
# ServiceContextの作成
service_context = ServiceContext.from_defaults(text_splitter=text_splitter, embed_model="local", llm=llm)
# indexの作成
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
# Indexを保存
index.storage_context.persist(persist_dir="./persist_index")
import deepl
import os
class DeepLClass():
def __init__(self):
self.auth_key = os.getenv('DEEPL_API_KEY')
self.translator = deepl.Translator(self.auth_key)
def translate(self, text, lang):
result = self.translator.translate_text(text, target_lang=lang)
return result.text
from llama_index import ServiceContext, StorageContext, load_index_from_storage
from llama_index.llms import LlamaCPP
from llama_index.llms.llama_utils import (
messages_to_prompt,
completion_to_prompt,
)
from llama_index.text_splitter import SentenceSplitter
import translator.deepl_api as dla
# storage contextの再構築
storage_context = StorageContext.from_defaults(persist_dir="./persist_index")
# LLMの設定
model_url = "https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/resolve/main/llama-2-13b-chat.Q4_0.gguf"
llm = LlamaCPP(
model_url=model_url,
model_path=None,
temperature=0.1,
max_new_tokens=256,
context_window=3900,
generate_kwargs={},
model_kwargs={"n_gpu_layers": 1},
messages_to_prompt=messages_to_prompt,
completion_to_prompt=completion_to_prompt,
verbose=True,
)
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
# ServiceContextの作成
service_context = ServiceContext.from_defaults(text_splitter=text_splitter, embed_model="local", llm=llm)
# 保存したindexの読み込み
index = load_index_from_storage(storage_context, service_context=service_context)
query_engine = index.as_query_engine()
response = query_engine.query("グロースエクスパートナーズ株式会社の「G+WEB」で紹介されている内容について、新しいものから3つ教えてください。")
deepl = dla.DeepLClass()
translate_res = deepl.translate(str(response), "JA")
print(translate_res)
上記のmain.pyを実行後、以下の回答が生成されました。
内容も概ね合っていそうなので、RAGが成功しているのが確認出来ました。また、ServiceContextの引数にtext_splitterを指定した方が、回答の生成速度が上がるようです。
-
指定しないで生成したもの (およそ35分)

-
指定して生成したもの (およそ16分)

ローカルのCPUでLLMを動かすのは、学ぶには良いかもしれませんが、回答の生成までかなり時間がかかってしまうので、実用的ではなさそうです。(PCのスペックにもよるのかもしれませんが。)
さいごに
最後までご覧いただきありがとうございました。
LLMを学びたいけど、請求が怖くてなかなか手を出せない人やLlamaIndexを用いたRAGについて学びたい人の役に立てれば幸いです。