はじめに
みなさんDNNは活用しているでしょうか。最近は様々なDNNフレームワークがOSSとして公開されており、DNNを簡単に始めることができるようになりました。便利な世の中になったものです。
さてTensorflowやChainer、PyTorchといった最近よく使われているDNNフレームワーク、あるいはKerasのような抽象化APIは、だいたいPythonで書くことが多いと思います。しかし学習フェーズは良いとしても、学習済みのモデルを使って何らかの予測をする場合には、Pythonの応答性能が気になります。特にカメラ映像に対して連続的に予測をしたい場合には、リアルタイム性がかなり重要になってきます。
@yukiB さんの[Python]KerasをTensorFlowから,TensorFlowをc++から叩いて実行速度を上げるによれば、同じ学習済みモデルを使っていても、C++で実行すればPythonの2割〜6割程度の実行時間で処理ができるみたいです。これはC++によるDNNを試してみるしかないでしょう。
ということで、今回はPyTorchを用いてMNISTをCNNで学習させ、その学習済みモデルをC++から使ってみたいと思います。
環境
今回検証した環境は、以下になります。利用したUbuntu18.04は、実際にはParallels Desktop上の仮想環境です。
(iMacやMacbookでcudaが使えるようになってほしいなぁ・・・)
| バージョン | |
|---|---|
| Host OS | macOS Sierra 10.12.6 |
| virtualization | Parallels Desktop for Mac Pro 14.1.3 (45485) |
| バージョン | |
|---|---|
| Guest OS | Ubuntu 18.04.2 LTS |
| miniconda3 | 4.6.14 |
| gcc | 7.4.0 |
| opencv | 4.1.0 |
| python | 3.7.1 |
| pytorch & libtorch | 1.1.0 |
ソースコード
今回のソースコードは、githubのnmatsui/libtorch_pytorch_mnistにpushしてあります。もし興味がありましたら、forkして遊んでみてください。
準備
ライブラリのインストール
C++で利用できるように、まずはOpenCVとlibTorchをインストールします。なおcudaが使えないため、libtorchはCPUバージョンをインストールします。
-
パッケージのインストール
$ sudo apt install -y build-essential cmake unzip pkg-config wget $ sudo apt install -y qt5-default libvtk6-dev zlib1g-dev libwebp-dev \ libopenexr-dev libgdal-dev libjpeg-dev libpng-dev \ libtiff-dev libtiff5-dev libv4l-dev libavcodec-dev \ libavformat-dev libswscale-dev libxine2-dev \ libxvidcore-dev libx264-dev libdc1394-22-dev \ libtheora-dev libvorbis-dev libgtk-3-dev libtbb-dev \ libatlas-base-dev libopencore-amrnb-dev \ libopencore-amrwb-dev libeigen3-dev gfortran yasm -
OpenCV4のインストール
$ cd ${HOME} $ wget -O opencv-4.1.0.zip https://github.com/opencv/opencv/archive/4.1.0.zip $ unzip opencv-4.1.0.zip $ cd opencv-4.1.0 $ mkdir build && cd build $ cmake -DCMAKE_BUILD_TYPE=RELEASE \ -DCMAKE_INSTALL_PREFIX=/usr/local \ -DCMAKE_CXX_FLAGS=-D_GLIBCXX_USE_CXX11_ABI=0 \ -DWITH_QT=ON -DWITH_OPENGL=ON -DFORCE_VTK=ON -DWITH_TBB=ON -DWITH_GDAL=ON \ -DWITH_XINE=ON -DBUILD_EXAMPLES=ON -DENABLE_PRECOMPILED_HEADERS=OFF \ .. $ make -j4 $ sudo make install $ sudo ldconfig- Ubuntu 18.04のgcc 7.4.0でOpenCV4を普通にビルドすると、 新型のバイナリインターフェース(GNU 5.x ABI)で共有ライブラリがビルドされるようです。libTorchは旧型のバイナリインタフェース(GNU 4.x ABI)でビルドされているらしいので、OpenCVとlibTorchを同時にlinkするとldがこけます。
- そのため、OpenCVのMakefile生成時に
-DCMAKE_CXX_FLAGS=-D_GLIBCXX_USE_CXX11_ABI=0を指定して、GNU 4.x ABI互換でOpenCV4をビルドします。- これに気づくまで1日かかりました。。。
-
libTorchのインストール
$ cd ${HOME} $ wget -O libtorch-1.1.zip https://download.pytorch.org/libtorch/cpu/libtorch-shared-with-deps-latest.zip $ unzip libtorch-1.1.zip $ sudo cp -r libtorch/include/* /usr/local/include/ $ sudo cp -r libtorch/lib/* /usr/local/lib/ $ sudo cp -r libtorch/share/* /usr/local/share/ $ sudo ldconfig- pytorchのリポジトリに含まれる
tools/build_libtorch.pyを使ってlibtorchをソースコードからビルドすることもできます。
* https://github.com/pytorch/pytorch/issues/14620
- pytorchのリポジトリに含まれる
C++プログラムのビルド
-
ソースコードのダウンロード
$ cd ${HOME} $ git clone https://github.com/nmatsui/libtorch_pytorch_mnist.git -
C++プログラムのビルド
$ cd ${HOME}/libtorch_pytorch_mnist/libtorch $ mkdir build && cd build $ cmake .. $ make $ cp pimage/predict_image .. $ cp pcamera/predict_camera ..- この段階で
makeに失敗した場合、おそらくOpenCVとlibtorchの共有ライブラリが上手くリンクできないのだと思われます。もし古いOpenCVなどがインストールされているならば、削除してみると上手くいくかもしれません。
- この段階で
MNISTの学習(Python)
ライブラリのインストールが成功したら、MNISTの教師データを用いて学習させます。学習部分はPythonで書いています。
-
condaを用いてPython仮想環境を準備$ cd ${HOME}/libtorch_pytorch_mnist/pytorch $ conda env create --file conda-linux.yaml $ conda activate pytorch_mnist -
学習を行う
$ ./train.py --epochs 12 ../models/mnist_py.pt ../data- 1つ目の引数は学習済みモデルを保存するファイル名、2つ目の引数はダウンロードしてきたMNISTの学習データとテストデータを格納するルートディレクトリです。
- オプションでepochを12回に指定しています。学習時に指定できるその他のオプションは、
./train.py --helpで確認してください。
Test set: Average loss: 0.050700, Accuracy: 9847/10000 (98.47%)- 学習が終わると、↑のようにテストデータを評価した際のAverage lossとAccuracyが表示されます。
今回使用したモデルは、次のようになります。
class MnistCNNModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.pool = nn.MaxPool2d(2, 2)
self.dropout1 = nn.Dropout2d()
self.fc1 = nn.Linear(12 * 12 * 64, 128)
self.dropout2 = nn.Dropout2d()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = self.dropout1(x)
x = x.view(-1, 12 * 12 * 64)
x = F.relu(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
基本的に「KerasサンプルのMNIST CNNモデル keras/examples/mnist_cnn.py」をそのまま持ってきてますが、最適化関数はPyTorchのサンプル(pytorch/examples/mnist/main.py)をそのまま持ってきたため、AdaDeltaではなくてMomentum SDGになってます(train.py)。
学習済みモデルを使った手書き数字の認識(Python)
lossとAccuracyは悪くないので、それなりにうまく学習できているはずです。
ではこの学習済みモデルが上手く機能するかどうか、Pythonで書いた手書き数字画像の認識プログラムを動かしてみます。適当に作ったテスト用の画像を digit_images ディレクトリに入れておきましたので、それを認識してみましょう。
-
手書き数字の画像を認識する(Python)
$ cd ${HOME}/libtorch_pytorch_mnist/pytorch $ ./predict.py ../models/mnist_py.pt ../digit_images/2.png label: 2 (prob: 0.998020)- 1つ目の引数は学習済みモデルのファイル名、2つ目の引数は予測する手書き数字の画像ファイル名です。
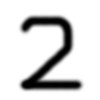
PyTorchに予測させた画像は、↑です。ちゃんと「2」と認識しました。
学習済みモデルを使った手書き数字の認識(C++)
学習したモデルはきちんと動作しそうなので、次はC++で手書き文字認識をしてみましょう。
学習済みモデルの変換(Python)
PyTorchのマニュアル LOADING A PYTORCH MODEL IN C++ を見ると、Python(PyTorch)で学習したモデルをC++で読むための公式の手順が書かれています。PyTorch素晴らしい。
-
PyTorchのモデルをTorch Scriptへ変換する
$ cd ${HOME}/libtorch_pytorch_mnist/pytorch $ ./convert_model.py ../models/mnist_py.pt ../models/mnist_cpp.pt- 1つ目の引数は学習済みモデルのファイル名、2つ目の引数は変換するC++用のモデルファイル名です。
変換済みモデルを使った手書き数字の認識(C++)
では、ビルドしておいたC++プログラムを使って、先ほどと同じ手書き数字画像を認識してみます。
-
手書き数字の画像を認識する(C++)
$ cd ${HOME}/libtorch_pytorch_mnist/libtorch $ ./predict_image ../models/mnist_cpp.pt ../digit_images/2.png label: 2 (prob: 0.993486)- 1つ目の引数はC++用に変換済みモデルのファイル名、2つ目の引数は予測する手書き数字の画像ファイル名です。
さくっと認識できました。C++の方はOSネイティブの実行ファイルのため、Pythonよりも心持ち早いと思います。が、1画像の認識程度では違いはあまりわかりません(笑
PyTorchのPython APIとlibtorchのC++ APIは、ほぼ同じようなシグネチャで作られています。Pythonの実装とほとんど同じような記述でC++の実装が書けるのは、よくできていると思います(OpenCVの画像を扱うあたりは若干異なりますが)。
USBカメラ映像の各フレームで手書き数字を連続的に認識する(C++)
最後に、USBカメラ映像の各フレームで、リアルタイムに手書き数字の認識をしてみましょう。
本来であれば、各フレームをキューにバッファリングしてCPUコアごとに分散処理させ、間に合わない場合にはイイカンジに間引くような仕組みを作り込むべきですが、今回はシンプルに全てシングルスレッド上でDNNを回しています。
-
USBカメラのキャプチャを開始する
$ cd ${HOME}/libtorch_pytorch_mnist/libtorch $ ./predict_camera ../models/mnist_cpp.pt 4 0.9- 1つ目の引数はC++用に変換済みモデルのファイル名、2つ目の引数はUSBカメラのデバイスIDです。
- 3つ目の引数は「認識できた」と判定するためのしきい値です。上記の場合、0.9以上の確率で分類された際に「認識できた」とみなします。
-
USBカメラの映像で、指定された位置の手書き文字を認識する。
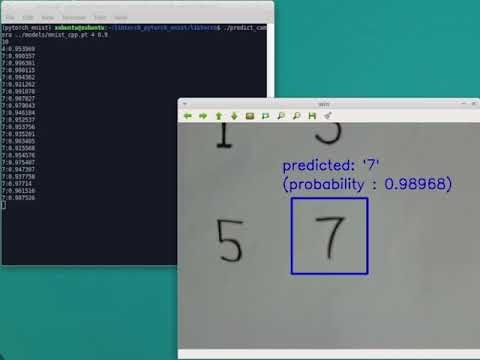
(youtubeで動画が再生されます)
今回のUSBカメラは10~15FPSぐらいで動作させていますが、ほぼ遅延無く手書き数字認識ができているようです。
まとめ
ということで、pythonで学習したPyTorchのDNNモデルをC++から利用することができました。今後はちゃんとGPUも使い、より複雑なモデルをC++で動作させてみたいところです。